User management in Django admin is a tricky subject. If you enforce too many permissions, then you might interfere with day-to-day operations. If you allow for permissions to be granted freely without supervision, then you put your system at risk.
Django provides a good authentication framework with tight integration to Django admin. Out of the box, Django admin does not enforce special restrictions on the user admin. This can lead to dangerous scenarios that might compromise your system.
Did you know staff users that manage other users in the admin can edit their own permissions? Did you know they can also make themselves superusers? There is nothing in Django admin that prevents that, so it’s up to you!
By the end of this tutorial, you’ll know how to protect your system:
- Protect against permission escalation by preventing users from editing their own permissions
- Keep permissions tidy and maintainable by only forcing users to manage permissions only using groups
- Prevent permissions from leaking through custom actions by explicitly enforcing the necessary permissions
Follow Along:
To follow along with this tutorial, it’s best to setup a small project to play with. If you aren’t sure how to do that, then check out Get Started With Django.
This tutorial also assumes a basic understanding of user management in Django. If you aren’t familiar with that, then check out the official documentation.
Model Permissions
Permissions are tricky. If you don’t set permissions, then you put your system at risk of intruders, data leaks, and human errors. If you abuse permissions or use them too much, then you risk interfering with day-to-day operations.
Django comes with a built-in authentication system. The authentication system includes users, groups, and permissions.
When a model is created, Django will automatically create four default permissions for the following actions:
add: Users with this permission can add an instance of the model.delete: Users with this permission can delete an instance of the model.change: Users with this permission can update an instance of the model.view: Users with this permission can view instances of this model. This permission was a much anticipated one, and it was finally added in Django 2.1.
Permission names follow a very specific naming convention: <app>.<action>_<modelname>.
Let’s break that down:
<app> is the name of the app. For example, the User model is imported from the auth app (django.contrib.auth).<action> is one of the actions above (add, delete, change, or view).<modelname> is the name of the model, in all lowercase letters.
Knowing this naming convention can help you manage permissions more easily. For example, the name of the permission to change a user is auth.change_user.
How to Check Permissions
Model permissions are granted to users or groups. To check if a user has a certain permission, you can do the following:
>>>>>> fromdjango.contrib.auth.modelsimportUser>>> u=User.objects.create_user(username='haki')>>> u.has_perm('auth.change_user')False It’s worth mentioning that .has_perm() will always return True for active superuser, even if the permission doesn’t really exist:
>>>>>> fromdjango.contrib.auth.modelsimportUser>>> superuser=User.objects.create_superuser(... username='superhaki',... email='me@hakibenita.com',... password='secret',)>>> superuser.has_perm('does.not.exist')True As you can see, when you’re checking permissions for a superuser, the permissions are not really being checked.
How to Enforce Permissions
Django models don’t enforce permissions themselves. The only place permissions are enforced out of the box by default is Django Admin.
The reason models don’t enforce permissions is that, normally, the model is unaware of the user performing the action. In Django apps, the user is usually obtained from the request. This is why, most of the time, permissions are enforced at the view layer.
For example, to prevent a user without view permissions on the User model from accessing a view that shows user information, do the following:
fromdjango.core.exceptionsimportPermissionDenieddefusers_list_view(request):ifnotrequest.user.has_perm('auth.view_user'):raisePermissionDenied()If the user making the request logged in and was authenticated, then request.user will hold an instance of User. If the user did not login, then request.user will be an instance of AnonymousUser. This is a special object used by Django to indicate an unauthenticated user. Using has_perm on AnonymousUser will always return False.
If the user making the request doesn’t have the view_user permission, then you raise a PermissionDenied exception, and a response with status 403 is returned to the client.
To make it easier to enforce permissions in views, Django provides a shortcut decorator called permission_required that does the same thing:
fromdjango.contrib.auth.decoratorsimportpermission_required@permission_required('auth.view_user')defusers_list_view(request):passTo enforce permissions in templates, you can access the current user permissions through a special template variable called perms. For example, if you want to show a delete button only to users with delete permission, then do the following:
{%ifperms.auth.delete_user%}<button>Delete user!</button>{%endif%}Some popular third party apps such as the Django rest framework also provide useful integration with Django model permissions.
Django Admin and Model Permissions
Django admin has a very tight integration with the built-in authentication system, and model permissions in particular. Out of the box, Django admin is enforcing model permissions:
- If the user has no permissions on a model, then they won’t be able to see it or access it in the admin.
- If the user has view and change permissions on a model, then they will be able to view and update instances, but they won’t be able to add new instances or delete existing ones.
With proper permissions in place, admin users are less likely to make mistakes, and intruders will have a harder time causing harm.
Implement Custom Business Roles in Django Admin
One of the most vulnerable places in every app is the authentication system. In Django apps, this is the User model. So, to better protect your app, you are going to start with the User model.
First, you need to take control over the User model admin page. Django already comes with a very nice admin page to manage users. To take advantage of that great work, you are going to extend the built-in User admin model.
Setup: A Custom User Admin
To provide a custom admin for the User model, you need to unregister the existing model admin provided by Django, and register one of your own:
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin# Unregister the provided model adminadmin.site.unregister(User)# Register out own model admin, based on the default UserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):pass
Your CustomUserAdmin is extending Django’s UserAdmin. You did that so you can take advantage of all the work already done by the Django developers.
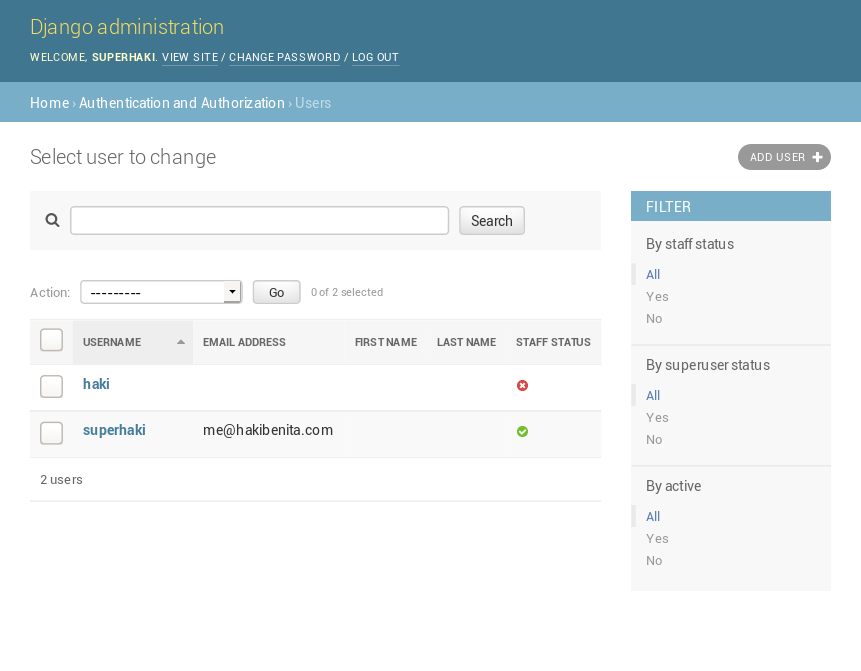
At this point, if you log into your Django admin at http://127.0.0.1:8000/admin/auth/user, you should see the user admin unchanged:
![Django bare boned user admin]()
By extending UserAdmin, you are able to use all the built-in features provided by Django admin.
Prevent Update of Fields
Unattended admin forms are a prime candidate for horrible mistakes. A staff user can easily update a model instance through the admin in a way the app does not expect. Most of the time, the user won’t even notice something is wrong. Such mistakes are usually very hard to track down and fix.
To prevent such mistakes from happening, you can prevent admin users from modifying certain fields in the model.
If you want to prevent any user, including superusers, from updating a field, you can mark the field as read only. For example, the field date_joined is set when a user registers. This information should never be changed by any user, so you mark it as read only:
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):readonly_fields=['date_joined',]
When a field is added to readonly_fields, it will not be editable in the admin default change form. When a field is marked as read only, Django will render the input element as disabled.
But, what if you want to prevent only some users from updating a field?
Conditionally Prevent Update of Fields
Sometimes it’s useful to update fields directly in the admin. But you don’t want to let any user do it: you want to allow only superusers to do it.
Let’s say you want to prevent non-superusers from changing a user’s username. To do that, you need to modify the change form generated by Django, and disable the username field based on the current user:
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):defget_form(self,request,obj=None,**kwargs):form=super().get_form(request,obj,**kwargs)is_superuser=request.user.is_superuserifnotis_superuser:form.base_fields['username'].disabled=Truereturnform
Let’s break it down:
- To make adjustments to the form, you override
get_form(). This function is used by Django to generate a default change form for a model. - To conditionally disable the field, you first fetch the default form generated by Django, and then if the user is not a superuser, disable the username field.
Now, when a non-superuser tries to edit a user, the username field will be disabled. Any attempt to modify the username through Django Admin will fail. When a superuser tries to edit the user, the username field will be editable and behave as expected.
Prevent Non-Superusers From Granting Superuser Rights
Superuser is a very strong permission that should not be granted lightly. However, any user with a change permission on the User model can make any user a superuser, including themselves. This goes against the whole purpose of the permission system, so you want to close this hole.
Based on the previous example, to prevent non-superusers from making themselves superusers, you add the following restriction:
fromtypingimportSetfromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):defget_form(self,request,obj=None,**kwargs):form=super().get_form(request,obj,**kwargs)is_superuser=request.user.is_superuserdisabled_fields=set()# type: Set[str]ifnotis_superuser:disabled_fields|={'username','is_superuser',}forfindisabled_fields:iffinform.base_fields:form.base_fields[f].disabled=TruereturnformIn addition to the previous example, you made the following additions:
You initialized an empty set disabled_fields that will hold the fields to disable. set is a data structure that holds unique values. It makes sense to use a set in this case, because you only need to disable a field once. The operator |= is used to perform an in-place OR update. For more information about sets, check out Sets in Python.
Next, if the user is a superuser, you add two fields to the set (username from the previous example, and is_superuser). They will prevent non-superusers from making themselves superusers.
Lastly, you iterate over the fields in the set, mark all of them as disabled, and return the form.
Django User Admin Two-Step Form
When you create a new user in Django admin, you go through a two-step form. In the first form, you fill in the username and password. In the second form, you update the rest of the fields.
This two-step process is unique to the User model. To accommodate this unique process, you must verify that the field exists before you try to disable it. Otherwise, you might get a KeyError. This is not necessary if you customize other model admins.
For more information about KeyError, check out Python KeyError Exceptions and How to Handle Them.
Grant Permissions Only Using Groups
The way permissions are managed is very specific to each team, product, and company. I found that it’s easier to manage permissions in groups. In my own projects, I create groups for support, content editors, analysts, and so on. I found that managing permissions at the user level can be a real hassle. When new models are added, or when business requirements change, it’s tedious to update each individual user.
To manage permissions only using groups, you need to prevent users from granting permissions to specific users. Instead, you want to only allow associating users to groups. To do that, disable the field user_permissions for all non-superusers:
fromtypingimportSetfromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):defget_form(self,request,obj=None,**kwargs):form=super().get_form(request,obj,**kwargs)is_superuser=request.user.is_superuserdisabled_fields=set()# type: Set[str]ifnotis_superuser:disabled_fields|={'username','is_superuser','user_permissions',}forfindisabled_fields:iffinform.base_fields:form.base_fields[f].disabled=TruereturnformYou used the exact same technique as in the previous sections to implement another business rule. In the next sections, you’re going to implement more complex business rules to protect your system.
Prevent Non-Superusers From Editing Their Own Permissions
Strong users are often a weak spot. They possess strong permissions, and the potential damage they can cause is significant. To prevent permission escalation in case of intrusion, you can prevent users from editing their own permissions:
fromtypingimportSetfromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):defget_form(self,request,obj=None,**kwargs):form=super().get_form(request,obj,**kwargs)is_superuser=request.user.is_superuserdisabled_fields=set()# type: Set[str]ifnotis_superuser:disabled_fields|={'username','is_superuser','user_permissions',}# Prevent non-superusers from editing their own permissionsif(notis_superuserandobjisnotNoneandobj==request.user):disabled_fields|={'is_staff','is_superuser','groups','user_permissions',}forfindisabled_fields:iffinform.base_fields:form.base_fields[f].disabled=TruereturnformThe argument obj is the instance of the object you are currently operating on:
- When
obj is None, the form is used to create a new user. - When
obj is not None, the form is used to edit an existing user.
To check if the user making the request is operating on themselves, you compare request.user with obj. Because this is the user admin, obj is either an instance of User, or None. When the user making the request, request.user, is equal to obj, then it means that the user is updating themselves. In this case, you disable all sensitive fields that can be used to gain permissions.
The ability to customize the form based on the object is very useful. It can be used to implement elaborate business roles.
Override Permissions
It can sometimes be useful to completely override the permissions in Django admin. A common scenario is when you use permissions in other places, and you don’t want staff users to make changes in the admin.
Django uses hooks for the four built-in permissions. Internally, the hooks use the current user’s permissions to make a decision. You can override these hooks, and provide a different decision.
To prevent staff users from deleting a model instance, regardless of their permissions, you can do the following:
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):defhas_delete_permission(self,request,obj=None):returnFalse
Just like with get_form(), obj is the instance you currently operate on:
- When
obj is None, the user requested the list view. - When
obj is not None, the user requested the change view of a specific instance.
Having the instance of the object in this hook is very useful for implementing object-level permissions for different types of actions. Here are other use cases:
- Preventing changes during business hours
- Implementing object-level permissions
Restrict Access to Custom Actions
Custom admin actions require special attention. Django is not familiar with them, so it can’t restrict access to them by default. A custom action will be accessible to any admin user with any permission on the model.
To illustrate, add a handy admin action to mark multiple users as active:
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):actions=['activate_users',]defactivate_users(self,request,queryset):cnt=queryset.filter(is_active=False).update(is_active=True)self.message_user(request,'Activated {} users.'.format(cnt))activate_users.short_description='Activate Users'# type: ignoreUsing this action, a staff user can mark one or more users, and activate them all at once. This is useful in all sorts of cases, such as if you had a bug in the registration process and needed to activate users in bulk.
This action updates user information, so you want only users with change permissions to be able to use it.
Django admin uses an internal function to get actions. To hide activate_users() from users without change permission, override get_actions():
fromdjango.contribimportadminfromdjango.contrib.auth.modelsimportUserfromdjango.contrib.auth.adminimportUserAdmin@admin.register(User)classCustomUserAdmin(UserAdmin):actions=['activate_users',]defactivate_users(self,request,queryset):assertrequest.user.has_perm('auth.change_user')cnt=queryset.filter(is_active=False).update(is_active=True)self.message_user(request,'Activated {} users.'.format(cnt))activate_users.short_description='Activate Users'# type: ignoredefget_actions(self,request):actions=super().get_actions(request)ifnotrequest.user.has_perm('auth.change_user'):delactions['activate_users']returnactionsget_actions() returns an OrderedDict. The key is the name of the action, and the value is the action function. To adjust the return value, you override the function, fetch the original value, and depending on the user permissions, remove the custom action activate_users from the dict. To be on the safe side, you assert the user permission in the action as well.
For staff users without change_user() permissions, the action activate_users will not appear in the actions dropdown.
Conclusion
Django admin is a great tool for managing a Django project. Many teams rely on it to stay productive in managing day-to-day operations. If you use Django admin to perform operations on models, then it’s important to be aware of permissions. The techniques described in this article are useful for any model admin, not just the User model.
In this tutorial, you protected your system by making the following adjustments in Django Admin:
- You protected against permission escalation by preventing users from editing their own permissions.
- You kept permissions tidy and maintainable by only forcing users to manage permissions only using groups.
- You prevented permissions from leaking through custom actions by explicitly enforcing the necessary permissions.
Your User model admin is now much safer than when you started!
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]