I built a McKenna QuoteBot, deployed it on a Raspberry Pi, and in the process learned about OOP in Python, Error Handling, and running headless Raspberry Pi's!
↧
Codementor: I played and learned and built a McKenna Reddit Bot in Python #raspberrypi
↧
Anarcat: October 2018 report: LTS, Monkeysphere, Flatpak, Kubernetes, CD archival and calendar project
Debian Long Term Support (LTS)
This is my monthly Debian LTS report.
GnuTLS
As discussed last month, one of the options to resolve the pending GnuTLS security issues was to backport the latest 3.3.x series (3.3.30), an update proposed then uploaded as DLA-1560-1. I after a suggestion, I've included an explicit NEWS.Debian item warning people about the upgrade, a warning also included in the advisory itself.
The most important change is probably dropping SSLv3, RC4, HMAC-SHA384 and HMAC-SHA256 from the list of algorithms, which could impact interoperability. Considering how old RC4 and SSLv3 are, however, this should be a welcome change. As for the HMAC changes, those are mandatory to fix the targeted vulnerabilities (CVE-2018-10844, CVE-2018-10845, CVE-2018-10846).
Xen
Xen updates had been idle for a while in LTS, so I bit the bullet and made a first discovery of the pending vulnerabilities. I sent the result to the folks over at Credativ who maintain the 4.4 branch and they came back with a set of proposed updates which I briefly review. Unfortunately, the patches were too deep for me: all I was able to do was to confirm consistency with upstream patches.
I also brought up a discussion regarding the viability of Xen in LTS, especially regarding the "speculative execution" vulnerabilities (XSA-254 and related). My understanding is upstream Xen fixes are not (yet?) complete, but apparently that is incorrect as Peter Dreuw is "condident in the Xen project to provide a solution for these issues". I nevertheless consider, like RedHat that the simpler KVM implementation might provide more adequate protection against those kind of attacks and LTS users should seriously consider switching to KVM for hosing untrusted virtual machines, even if only because that code is actually mainline in the kernel while Xen is unlikely to ever be. It might be, as Dreuw said, simpler to upgrade to stretch than switch virtualization systems...
When all is said and done, however, Linux and KVM are patches in Jessie at the time of writing, while Xen is not (yet).
Enigmail
I spent a significant amount of time working on Enigmail this month again, this time specifically working on reviewing the stretch proposed update to gnupg from Daniel Kahn Gillmor (dkg). I did not publicly share the code review as we were concerned it would block the stable update, which seemed to be in jeopardy when I started working on the issue. Thankfully, the update went through but it means it might impose extra work on leaf packages. Monkeysphere, in particular, might fail to build from source (FTBFS) after the gnupg update lands.
In my tests, however, it seems that packages using GPG can deal with the update correctly. I tested Monkeysphere, Password Store, git-remote-gcrypt and Enigmail, all of which passed a summary smoke test. I have tried to summarize my findings on the mailing list. Basically our options for the LTS update are:
pretend Enigmail works without changing GnuPG, possibly introducing security issues
ship a backport of GnuPG and Enigmail through jessie-sloppy-backports
package OpenPGP.js and backport all the way down to jessie
remove Enigmail from jessie
backport the required GnuPG patchset from stretch to jessie
So far I've taken that last step as my favorite approach...
Firefox / Thunderbird and finding work
... which brings us to the Firefox and Thunderbird updates. I was assuming those were going ahead, but the status of those updates currently seems unclear. This is a symptom of a larger problem in the LTS work organization: some packages can stay "claimed" for a long time without an obvious status update.
We discussed ways of improving on this process and, basically, I will try to be more proactive in taking over packages from others and reaching out to others to see if they need help.
A note on GnuPG
As an aside to the Enigmail / GnuPG review, I was struck by the ... peculiarities in the GnuPG code during my review. I discovered that GnuPG, instead of using the standard resolver, implements its own internal full-stack DNS server, complete with UDP packet parsing. That's 12 000 lines of code right there. There are also abstraction leaks like using "1" and "0" as boolean values inside functions (as opposed to passing an integer and converting as string on output).
A major change in the proposed patchset are changes to the
--with-colons batch output, which GnuPG consumers (like GPGME) are
supposed to use to interoperate with GnuPG. Having written such a
parser myself, I can witness to how difficult parsing those data
structures is. Normally, you should always be using GPGME instead of
parsing those directly, but unfortunately GPGME does not do everything
GPG does: signing operations and keyring management, for example, has
long been considered out of scope, so users are force to parse that
output.
Long story short, GPG consumers still use --with-colons directly
(and that includes Enigmail) because they have to. In this case,
critical components were missing from that output (e.g. knowing which
key signed which UID) so they were added in the patch. That's what
breaks the Monkeysphere test suite, which doesn't expect a specific
field to be present. Later versions of the protocol specification
have been updated (by dkg) to clarify that might happen, but obviously
some have missed the notice, as it came a bit late.
In any case, the review did not make me confident in the software architecture or implementation of the GnuPG program.
autopkgtest testing
As part of our LTS work, we often run tests to make sure everything is in order. Starting with Jessie, we are now seeing packages with autopkgtest enabled, so I started meddling with that program. One of the ideas I was hoping to implement was to unify my virtualization systems. Right now I'm using:
- Vagrant and Virtualbox for disposable VMs
- Docker for some services
- libvirt and KVM for other
- schroot for building packages (through sbuild)
Because sbuild can talk with autopkgtest, and autopkgtest can talk with qemu (which can use KVM images), I figured I could get rid of schroot. Unfortunately, I met a few snags;
- #911977: how do we correctly guess the VM name in autopkgtest?
- #911963: qemu build fails with
proxy_cmd: parameter not set(fixed and provided a patch) - #911979: fails on chown in autopkgtest-qemu backend
- #911981: qemu server warns about missing CPU features
So I gave up on that approach. But I did get autopkgtest working and documented the process in my quick Debian development guide.
Oh, and I also got sucked down into wiki stylesheet (#864925) after battling with the SystemBuildTools page.
Spamassassin followup
Last month I agreed we could backport the latest upstream version of SpamAssassin (a recurring pattern). After getting the go from the maintainer, I got a test package uploaded but the actual upload will need to wait for the stretch update (#912198) to land to avoid a versioning conflict.
Salt Stack
My first impression of Salt was not exactly impressive. The CVE-2017-7893 issue was rather unclear: first upstream fixed the issue, but reverted the default flag which would enable signature forging after it was discovered this would break compatibility with older clients.
But even worse, the 2014 version of Salt shipped in Jessie did not have master signing in the first place, which means there was simply no way to protect from master impersonation, a worrisome concept. But I assumed this was expected behavior and triaged this away from jessie, and tried to forgot about the horrors I had seen.
phpLDAPadmin with sunweaver
I looked next at the phpLDAPadmin (or PHPLDAPadmin?) vulnerabilities, but could not reproduce the issue using the provided proof of concept. I have also audited the code and it seems pretty clear the code is protected against such an attack, as was explained by another DD in #902186. So I asked Mitre for rejection, and uploaded DLA-1561-1 to fix the other issue (CVE-2017-11107). Meanwhile the original security researcher acknowledged the security issue was a "false positive", although only in a private email.
I almost did a NMU for the package but the security team requested to wait, and marked the package as grave so it gets kicked out of buster instead. I at least submitted the patch, originally provided by Ubuntu folks, upstream.
Smarty3
Finally, I worked on the smart3 package. I confirmed the package
in jessie is not vulnerable, because Smarty hadn't yet had the
brilliant idea of "optimizing"realpath by rewriting it with
new security vulnerabilities. Indeed, the CVE-2018-13982proof of content and CVE-2018-16831proof of
content both fail in jessie.
I have tried to audit the patch shipped with stretch to make sure it fixed the security issue in question (without introducing new ones of course) abandoned parsing the stretch patch because this regex gave me a headache:
'%^(?<root>(?:<span class="createlink"><a href="/ikiwiki.cgi?do=create&from=blog%2F2018-11-01-report&page=%3Aalpha%3A" rel="nofollow">?</a>:alpha:</span>:[\\\\]|/|[\\\\]{2}<span class="createlink"><a href="/ikiwiki.cgi?do=create&from=blog%2F2018-11-01-report&page=%3Aalpha%3A" rel="nofollow">?</a>:alpha:</span>+|<span class="createlink"><a href="/ikiwiki.cgi?do=create&from=blog%2F2018-11-01-report&page=%3Aprint%3A" rel="nofollow">?</a>:print:</span>{2,}:[/]{2}|[\\\\])?)(?<path>(?:<span class="createlink"><a href="/ikiwiki.cgi?do=create&from=blog%2F2018-11-01-report&page=%3Aprint%3A" rel="nofollow">?</a>:print:</span>*))$%u',
"who is supporting our users?"
I finally participated in a discussion regarding concerns about support of cloud images for LTS releases. I proposed that, like other parts of Debian, responsibility of those images would shift to the LTS team when official support is complete. Cloud images fall in that weird space (ie. "Installing Debian") which is not traditionally covered by the LTS team.
Hopefully that will become the policy, but only time will tell how this will play out.
Other free software work
irssi sandbox
I had been uncomfortable running irssi as my main user on my server for a while. It's a constantly running network server, sometimes connecting to shady servers too. So it made sense to run this as a separate user and, while I'm there, start it automatically on boot.
I created the following file in /etc/systemd/system/irssi@.service,
based on this gist:
[Unit]
Description=IRC screen session
After=network.target
[Service]
Type=forking
User=%i
ExecStart=/usr/bin/screen -dmS irssi irssi
ExecStop=/usr/bin/screen -S irssi -X stuff '/quit\n'
NoNewPrivileges=true
[Install]
WantedBy=multi-user.target
A whole apparmor/selinux/systemd profile could be written for irssi of
course, but I figured I would start with
NoNewPrivileges. Unfortunately, that line breaks screen, which is
sgid utmp which is some sort of "new privilege". So I'm running
this as a vanilla service. To enable, simply enable the service with
the right username, previously created with adduser:
systemctl enable irssi@foo.service
systemctl start irssi@foo.service
Then I join the session by logging in as the foo user, which can be
configured in .ssh/config as a convenience host:
Host irc.anarc.at
Hostname shell.anarc.at
User foo
IdentityFile ~/.ssh/id_ed25519_irc
# using command= in authorized_keys until we're all on buster
#RemoteCommand screen -x
RequestTTY force
Then the ssh irc.anarc.at command rejoins the screen session.
Monkeysphere revival
Monkeysphere was in bad shape in Debian buster. The bit rotten test suite was failing and the package was about to be removed from the next Debian release. I filed and worked on many critical bugs (Debian bug #909700, Debian bug #908228, Debian bug #902367, Debian bug #902320, Debian bug #902318, Debian bug #899060, Debian bug #883015) but the final fix came from another user. I was also welcome on the Debian packaging team which should allow me to make a new release next time we have similar issues, which was a blocker this time round.
Unfortunately, I had to abandon the Monkeysphere FreeBSD port. I had simply forgotten about that commitment and, since I do not run FreeBSD anywhere anymore, it made little sense to keep on doing so, especially since most of the recent updates were done by others anyways.
Calendar project
I've been working on a photography project since the beginning of the year. Each month, I pick the best picture out of my various shoots and will collect those in a 2019 calendar. I documented my work in the photo page, but most of my work in October was around finding a proper tool to layout the calendar itself. I settled on wallcalendar, a beautiful LaTeX template, because the author was very responsive to my feature request.
I also figured out which events to include in the calendar and a way to generate moon phases (now part of the undertime package) for the local timezone. I still have to figure out which other astronomical events to include. I had no response from the local Planetarium but (as always) good feedback from NASA folks which pointed me at useful resources to top up the calendar.
Kubernetes
I got deeper into Kubernetes work by helping friends setup a cluster and share knowledge on how to setup and manage the platforms. This led me to fix a bug in Kubespray, the install / upgrade tool we're using to manage Kubernetes. To get the pull request accepted, I had to go through the insanely byzantine CLA process of the CNCF, which was incredibly frustrating, especially since it was basically a one-line change. I also provided a code review of the Nextcloud helm chart and reviewed the python-hvac ITP, one of the dependencies of Kubespray.
As I get more familiar with Kubernetes, it does seem like it can solve real problems especially for shared hosting providers. I do still feel it's overly complex and over-engineered. It's difficult to learn and moving too fast, but Docker and containers are such a convenient way to standardize shipping applications that it's hard to deny this new trend does solve a problem that we have to fix right now.
CD archival
As part of my work on archiving my CD collection, I contributed threepullrequests to fix issues I was having with the project, mostly regarding corner cases but also improvements on the Dockerfile. At my suggestion, upstream also enabled automatic builds for the Docker image which should make it easier to install and deploy.
I still wish to write an article on this, to continue my series on archives, which could happen in November if I can find the time...
Flatpak conversion
After reading a convincing benchmark I decided to give Flatpak another try and ended up converting all my Snap packages to Flatpak.
Flatpak has many advantages:
it's decentralized: like APT or F-Droid repositories, anyone can host their own (there is only one Snap repository, managed by Canonical)
it's faster: the above benchmarks hinted at this, but I could also confirm Signal starts and runs faster under Flatpak than Snap
it's standardizing: many of the work Flatpak is doing to make sense of how to containerize desktop applications is being standardized (and even adopted by Snap)
Much of this was spurred by the breakage of Zotero in Debian (Debian bug #864827) due to the Firefox upgrade. I made a wiki page to tell our users how to install Zotero in Debian considering Zotero might take a while to be packaged back in Debian (Debian bug #871502).
Debian work
Without my LTS hat, I worked on the following packages:
- integrate a NMU for libotr into a new upload which also did the usual housekeeping
- contributed a patch (in Debian bug #911418) to fix a startup error in rapid-photo-downloader
- investigated possible fixes for odd behaviors and limitations of apt-show-version (in Debian bug #783781 and Debian bug #827337)
Other work
Usual miscellaneous:
- Git-annexfeature request and bugreports on Nextcloud integration
- Sigal + git-annex integration documentation
- Failed to convince GhostText to do proper releases
- Failed to resolve a namingconflict between two packages
named
yq, which both try to be the "jqof YAML" - Filed a bug regarding an impossible to fix deprecation notice in Feedparser (public service announcement: if you deprecate an API, make sure there's a way to use the new one properly without having warnings)
- I made small changes to the theme of this site to improve the print version and contributed a patch upstream to fix this as well
- Some housekeeping on feed2exec: fix the test suite which seems to bitrot on itself
- Review and update Koumbit's pre-receive-enforce-gpg-signatures
git hook to check OpenPGP signatures on git repositories, to
support running it as an
updatehook.
↧
↧
Catalin George Festila: Python Qt5 - QtSql with QSQLITE example.
Today I will show you how to deal with QtSql and QSQLITE and show a table into an MDI (Multiple Document Interface) application.
First I create tree scripts named:
Let's see this python scripts:
First is PyQt5_connection.py:
![]()
First I create tree scripts named:
- PyQt5_connection.py - create a memory database and add value into table;
- PyQt5_view.py - create a model for the table;
- PyQt5_show.py - show the MDI application with the model table database;
Let's see this python scripts:
First is PyQt5_connection.py:
from PyQt5 import QtWidgets, QtSql
from PyQt5.QtSql import *
def createConnection():
db = QtSql.QSqlDatabase.addDatabase("QSQLITE")
db.setDatabaseName(":memory:")
if not db.open():
QtWidgets.QMessageBox.critical(None, "Cannot open memory database",
"Unable to establish a database connection.\n\n"
"Click Cancel to exit.", QtWidgets.QMessageBox.Cancel)
return False
query = QtSql.QSqlQuery()
#print (os.listdir("."))
query.exec("DROP TABLE IF EXISTS Websites")
query.exec("CREATE TABLE Websites (ID INTEGER PRIMARY KEY NOT NULL, " + "website VARCHAR(20))")
query.exec("INSERT INTO Websites (website) VALUES('python-catalin.blogspot.com')")
query.exec("INSERT INTO Websites (website) VALUES('catalin-festila.blogspot.com')")
query.exec("INSERT INTO Websites (website) VALUES('free-tutorials.org')")
query.exec("INSERT INTO Websites (website) VALUES('graphic-3d.blogspot.com')")
query.exec("INSERT INTO Websites (website) VALUES('pygame-catalin.blogspot.com')")
return Truefrom PyQt5 import QtWidgets, QtSql
from PyQt5 import QtWidgets, QtSql
class WebsitesWidget(QtWidgets.QWidget):
def __init__(self, parent=None):
super(WebsitesWidget, self).__init__(parent)
# this layout_box can be used if you need more widgets
# I used just one named WebsitesWidget
layout_box = QtWidgets.QVBoxLayout(self)
#
my_view = QtWidgets.QTableView()
# put viwe in layout_box area
layout_box.addWidget(my_view)
# create a table model
my_model = QtSql.QSqlTableModel(self)
my_model.setTable("Websites")
my_model.select()
#show the view with model
my_view.setModel(my_model)
my_view.setItemDelegate(QtSql.QSqlRelationalDelegate(my_view))from PyQt5 import QtWidgets, QtSql
from PyQt5_connection import createConnection
# this will import any classes from PyQt5_view script
from PyQt5_view import WebsitesWidget
class MainWindow(QtWidgets.QMainWindow):
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.MDI = QtWidgets.QMdiArea()
self.setCentralWidget(self.MDI)
SubWindow1 = QtWidgets.QMdiSubWindow()
SubWindow1.setWidget(WebsitesWidget())
self.MDI.addSubWindow(SubWindow1)
SubWindow1.show()
# you can add more widgest
#SubWindow2 = QtWidgets.QMdiSubWindow()
if __name__ == '__main__':
import sys
app = QtWidgets.QApplication(sys.argv)
if not createConnection():
print("not connect")
sys.exit(-1)
w = MainWindow()
w.show()
sys.exit(app.exec_())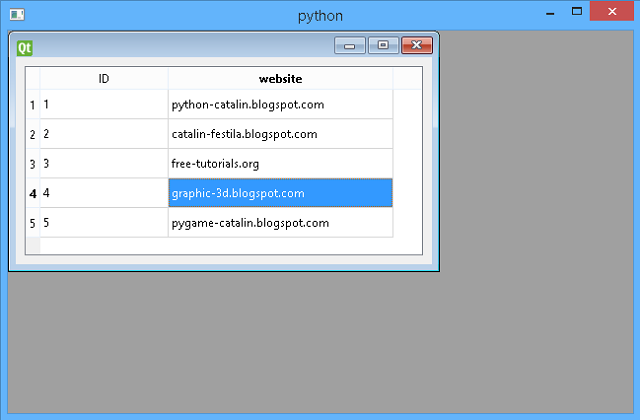
↧
eGenix.com: Python Meeting Düsseldorf - 2018-11-07
The following text is in German, since we're announcing a regional user group meeting in Düsseldorf, Germany.
Ankündigung
Das nächste Python Meeting Düsseldorf findet an folgendem Termin statt:
07.11.2018, 18:00 Uhr
Raum 1, 2.OG im Bürgerhaus Stadtteilzentrum Bilk
Düsseldorfer Arcaden, Bachstr. 145, 40217 Düsseldorf
Neuigkeiten
Bereits angemeldete Vorträge
Charlie Clark"Context Managers and Generators"
Marc-André Lemburg
"The History of Unicode in Python"
Jens Diemer
"Django for Runners"
Ilya Kamenschchikov
"Object Detection Using TensorFlow"
Sowie einige Buchrezensionen.
Weitere Vorträge können gerne noch angemeldet werden. Bei Interesse, bitte unter info@pyddf.de melden.
Startzeit und Ort
Wir treffen uns um 18:00 Uhr im Bürgerhaus in den Düsseldorfer Arcaden.
Das Bürgerhaus teilt sich den Eingang mit dem Schwimmbad und befindet
sich an der Seite der Tiefgarageneinfahrt der Düsseldorfer Arcaden.
Über dem Eingang steht ein großes "Schwimm’ in Bilk" Logo. Hinter der Tür
direkt links zu den zwei Aufzügen, dann in den 2. Stock hochfahren. Der
Eingang zum Raum 1 liegt direkt links, wenn man aus dem Aufzug kommt.
>>> Eingang in Google Street View
Einleitung
Das Python Meeting Düsseldorf ist eine regelmäßige Veranstaltung in Düsseldorf, die sich an Python Begeisterte aus der Region wendet.
Einen guten Überblick über die Vorträge bietet unser PyDDF YouTube-Kanal, auf dem wir Videos der Vorträge nach den Meetings veröffentlichen.Veranstaltet wird das Meeting von der eGenix.com GmbH, Langenfeld, in Zusammenarbeit mit Clark Consulting & Research, Düsseldorf:
Programm
Das Python Meeting Düsseldorf nutzt eine Mischung aus (Lightning) Talks und offener Diskussion.
Vorträge können vorher angemeldet werden, oder auch spontan während des Treffens eingebracht werden. Ein Beamer mit XGA Auflösung steht zur Verfügung.(Lightning) Talk Anmeldung bitte formlos per EMail an info@pyddf.de
Kostenbeteiligung
Das Python Meeting Düsseldorf wird von Python Nutzern für Python Nutzer veranstaltet.
Da Tagungsraum, Beamer, Internet und Getränke Kosten produzieren, bitten wir die Teilnehmer um einen Beitrag in Höhe von EUR 10,00 inkl. 19% Mwst. Schüler und Studenten zahlen EUR 5,00 inkl. 19% Mwst.
Wir möchten alle Teilnehmer bitten, den Betrag in bar mitzubringen.
Anmeldung
Da wir nur für ca. 20 Personen Sitzplätze haben, möchten wir bitten,
sich per EMail anzumelden. Damit wird keine Verpflichtung eingegangen.
Es erleichtert uns allerdings die Planung.
Meeting Anmeldung bitte formlos per EMail an info@pyddf.de
Weitere Informationen
Weitere Informationen finden Sie auf der Webseite des Meetings:
http://pyddf.de/
Viel Spaß !
Marc-Andre Lemburg, eGenix.com
↧
Weekly Python StackOverflow Report: (cl) stackoverflow python report
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2018-11-03 15:57:59 GMT
- What is a Pythonic way of doing the following transformation on a list of dicts? - [22/8]
- How to add count for each unique val in list - [12/4]
- List comprehension to extract multiple fields from list of tuples - [11/4]
- Pandas: compare list objects in Series - [8/4]
- Numpy custom Cumsum function with upper/lower limits? - [8/2]
- What is the guarantee made by itertools.combinations? - [8/1]
- Why is random number generator tf.random_uniform in tensorflow much faster than the numpy equivalent - [7/2]
- mean from pandas and numpy differ - [7/0]
- How to capitalize first letter in strings that may contain numbers - [6/13]
- operator precedence of floor division and division - [6/7]
↧
↧
PyBites: PyBites Twitter Digest - Issue 35, 2018
Mike Kennedy interviewed by Real Python!
🐍🎤 @mkennedy is the host of the most popular Python podcast, @TalkPython as well as a co-host on the @pythonbytes p… https://t.co/fMRTc1ndeP
— Real Python (@realpython) October 30, 2018
A great guide on some more advanced features of Git
Submitted by @Erik
6 min read on how to become a #Git expert from @adityasridhar18 on @freeCodeCamp#GitHub#linux#python#html#css…https://t.co/ltCAryssOa
— SingleMind (@SingleMind) November 01, 2018
Digital Ocean Developer Trends in the Cloud
Submitted by @dgjustice
🗞 After 20 years, #JavaScript continues to dominate the #OpenSource development scene. By writing all of our softw… https://t.co/uhRFyvEs01
— Lisk (@LiskHQ) November 02, 2018
How to make a Roguelike (cool!!)
Submitted by @Erik
How to make a roguelike (from someone who's made a bunch of 'em) https://t.co/Ab6VZg8TpVhttps://t.co/j9tJxsN5ex
— Gamasutra (@gamasutra) October 30, 2018
Set up Python for Machine Learning on Windows
🐍 Setting Up Python for Machine Learning on Windows In this step-by-step tutorial, you’ll cover the basics of sett… https://t.co/uCy2LelkQk
— Real Python (@realpython) November 03, 2018
Tutorial on JSON Data in Python
New Tutorial: JSON Data in Python! In this tutorial, you'll learn about different ways to use #JSON in #Python.…https://t.co/wRF54qUpr1
— DataCamp (@DataCamp) November 02, 2018
And another Datacamp tutorial: Linear Regression in Python
New Tutorial: Essentials of Linear Regression in Python! Learn what formulates a regression problem and how a… https://t.co/MUCJ3p6o17
— DataCamp (@DataCamp) November 02, 2018
Code.org #HourOfCode is here!
#HourOfCode is here! We’re excited to share more than 140 NEW tutorials and a brand new @Minecraft activity! Read m… https://t.co/iI7FkXioAc
— Code.org (@codeorg) November 01, 2018
You can now prioritise your notifications in Github!
Starting today, you can prioritize your notifications Save it now, read it later 🔖 https://t.co/oilRzTuMxj
— GitHub (@github) November 02, 2018
Python for Earth Scientists
Python for Earth Scientists https://t.co/dmXOjjxO3P
— Scientific Python (@SciPyTip) November 02, 2018
Sign up to the PSF Newsletter
We’re launching our first newsletter this month! If you’d like to be informed about important community news, you c… https://t.co/Yw6wypy0pU
— Python Software (@ThePSF) November 02, 2018
Super Potato Bruh: A game developed in Python with PyGame with a website created using Flask!
Super Potato Bruh is now on Steam! Retweet for a chance to win a Steam key! >> https://t.co/ZJrhmxbGSp<< Those o… https://t.co/PMYwaIzNu5
— DaFluffyPotato (@DaFluffyPotato) October 20, 2018
Visual Studio Code extension: Neuron
Data Science in Visual Studio Code using Neuron, a new VS Code extension https://t.co/UGHoCJqUHH by @lee_stott
— Python LibHunt (@PythonLibHunt) October 31, 2018
An introduction to Unix
An introduction to Unix https://t.co/ivw6vGUV03https://t.co/QvEGcIWS2z
— Full Stack Python (@fullstackpython) October 31, 2018
Interesting write up on teaching with Comics
when does teaching with comics work well? https://t.co/0qgWR5BXHl
— 🔎Julia Evans🔍 (@b0rk) October 28, 2018
scenes from distributed systems https://t.co/Ju4oXY7dOv
— 🔎Julia Evans🔍 (@b0rk) October 28, 2018
>>>frompybitesimportBob,JulianKeepCalmandCodeinPython!↧
Codementor: Monitoring a Dockerized Celery Cluster with Flower
↧
Catalin George Festila: Python Qt5 - QtSql with QtOpenGL example.
Today I will show you how to deal with QtOpenGL.
Let's make a test to see what is this:
You need to kknow how to use OpenGL API.
You can see the result of this example:
![]()
This is the source code for my example:
Let's make a test to see what is this:
>>> import PyQt5
>>> from PyQt5.QtOpenGL import *
>>> dir(PyQt5.QtOpenGL)
['QGL', 'QGLContext', 'QGLFormat', 'QGLWidget', '__doc__', '__file__', '__loader
__', '__name__', '__package__', '__spec__']You need to kknow how to use OpenGL API.
You can see the result of this example:

This is the source code for my example:
import sys
import math
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QColor
from PyQt5.QtWidgets import QApplication, QMessageBox
from PyQt5.QtOpenGL import QGL, QGLFormat, QGLWidget
try:
from OpenGL import GL
except ImportError:
app = QApplication(sys.argv)
QMessageBox.critical(None, "OpenGL samplebuffers",
"PyOpenGL must be installed to run this example.")
sys.exit(1)
# use to create OpenGL content
class GLWidget(QGLWidget):
GL_MULTISAMPLE = 0x809D
# rotation to 0
rot = 0.0
def __init__(self, parent):
super(GLWidget, self).__init__(QGLFormat(QGL.SampleBuffers), parent)
self.list_ = []
self.startTimer(40)
self.setWindowTitle("OpenGL with sample buffers")
def initializeGL(self):
GL.glMatrixMode(GL.GL_PROJECTION)
GL.glLoadIdentity()
GL.glOrtho( -.5, .5, .5, -.5, -1000, 1000)
GL.glMatrixMode(GL.GL_MODELVIEW)
GL.glLoadIdentity()
GL.glClearColor(1.0, 1.0, 1.0, 1.0)
self.makeObject()
def resizeGL(self, w, h):
GL.glViewport(0, 0, w, h)
def paintGL(self):
GL.glClear(GL.GL_COLOR_BUFFER_BIT | GL.GL_DEPTH_BUFFER_BIT)
GL.glMatrixMode(GL.GL_MODELVIEW)
GL.glPushMatrix()
GL.glEnable(GLWidget.GL_MULTISAMPLE)
GL.glTranslatef( -0.25, -0.10, 0.0)
GL.glScalef(0.75, 1.15, 0.0)
GL.glRotatef(GLWidget.rot, 0.0, 0.0, 1.0)
GL.glCallList(self.list_)
GL.glPopMatrix()
GL.glPushMatrix()
GL.glDisable(GLWidget.GL_MULTISAMPLE)
GL.glTranslatef(0.25, -0.10, 0.0)
GL.glScalef(0.75, 1.15, 0.0)
GL.glRotatef(GLWidget.rot, 0.0, 0.0, 1.0)
GL.glCallList(self.list_)
GL.glPopMatrix()
GLWidget.rot += 0.2
self.qglColor(Qt.black)
self.renderText(-0.35, 0.4, 0.0, "Multisampling enabled")
self.renderText(0.15, 0.4, 0.0, "Multisampling disabled")
def timerEvent(self, event):
self.update()
# create one object
def makeObject(self):
x1 = +0.05
y1 = +0.25
x2 = +0.15
y2 = +0.21
x3 = -0.25
y3 = +0.2
x4 = -0.1
y4 = +0.2
x5 = +0.25
y5 = -0.05
self.list_ = GL.glGenLists(1)
GL.glNewList(self.list_, GL.GL_COMPILE)
self.qglColor(Qt.blue)
self.geometry(GL.GL_POLYGON, x1, y1, x2, y2, x3, y3, x4, y4, x5, y5)
GL.glEndList()
# create geometry of object depend of render - GL_POLYGON
# used five points
def geometry(self, primitive, x1, y1, x2, y2, x3, y3, x4, y4, x5, y5):
GL.glBegin(primitive)
GL.glVertex2d(x1, y1)
GL.glVertex2d(x2, y2)
GL.glVertex2d(x3, y3)
GL.glVertex2d(x4, y4)
GL.glVertex2d(x5, y5)
GL.glEnd()
# start the application
if __name__ == '__main__':
app = QApplication(sys.argv)
my_format = QGLFormat.defaultFormat()
my_format.setSampleBuffers(True)
QGLFormat.setDefaultFormat(my_format)
if not QGLFormat.hasOpenGL():
QMessageBox.information(None, "OpenGL using samplebuffers",
"This system does not support OpenGL.")
sys.exit(0)
widget = GLWidget(None)
if not widget.format().sampleBuffers():
QMessageBox.information(None, "OpenGL using samplebuffers",
"This system does not have sample buffer support.")
sys.exit(0)
widget.resize(640, 480)
widget.show()
sys.exit(app.exec_())↧
Simple is Better Than Complex: Django Authentication Video Tutorial
In this tutorial series, we are going to explore Django’s authentication system by implementing sign up, login, logout, password change, password reset and protected views from non-authenticated users. This tutorial is organized in 7 videos, one for each topic, ranging from 4 min to 15 min each.
Setup
Starting a Django project from scratch, creating a virtual environment and an initial Django app. After that, we are going to setup the templates and create an initial view to start working on the authentication.
If you are already familiar with Django, you can skip this video and jump to the Sign Up tutorial below.
Sign Up
First thing we are going to do is implement a sign up view using the built-in UserCreationForm. In this video you
are also going to get some insights on basic Django form processing.
Login
In this video tutorial we are going to first include the built-in Django auth URLs to our project and proceed to implement the login view.
Logout
In this tutorial we are going to include Django logout and also start playing with conditional templates, displaying different content depending if the user is authenticated or not.
Password Change
Next The password change is a view where an authenticated user can change their password.
Password Reset
This tutorial is perhaps the most complicated one, because it involves several views and also sending emails. In this video tutorial you are going to learn how to use the default implementation of the password reset process and how to change the email messages.
Protecting Views
After implementing the whole authentication system, this video gives you an overview on how to protect some views from
non authenticated users by using the @login_required decorator and also using class-based views mixins.
Conclusions
If you want to learn more about Django authentication and some extra stuff related to it, like how to use Bootstrap to make your auth forms look good, or how to write unit tests for your auth-related views, you can read the forth part of my beginners guide to Django: A Complete Beginner’s Guide to Django - Part 4 - Authentication.
Of course the official documentation is the best source of information: Using the Django authentication system
The code used in this tutorial: github.com/sibtc/django-auth-tutorial-example
This was my first time recording this kind of content, so your feedback is highly appreciated. Please let me know what you think!
And don’t forget to subscribe to my YouTube channel! I will post exclusive Django tutorials there. So stay tuned! :-)
↧
↧
Andrea Grandi: Why I mentor on Exercism.io
Exercism (https://exercism.io) is a platform that has been created to help people improving their coding skills, thanks to the volunteers mentoring the students. There are tracks for almost all the popular languages and each track has coding tests that the students can download, solve offline using their preferred editor, and test the solution against the provided unit tests. Once the solution is ready to be reviewed (or even if it's not complete but the student needs help), it can be submitted to the website and it will go in a queue where the first available mentor will pick it and start mentoring.
The service is free to use for all the students and the mentors are all volunteers (this doesn't mean that the platform doesn't have any costs. If you are curious about the resources needed to keep the platform alive, you can give a look at this answer on Reddit.
When I found out about the platform, I decided to use it (as student) to improve my Go coding skills. I must say that I've been learning a lot from the mentors and some of them are putting a lot of effort to give you all the possible advices to improve your coding style. In a single exercise once, I learnt at least five things about Go I didn't know before!
I've been a Python developer (professionally) for the last 5 years, but I've never considered myself an "expert". I decided to give it a try with mentoring, because I felt I wanted to give something back to the community, so I registered as mentor too and started mentoring in the Python track.
The first surprise has been that mentoring other students, I was probably learning more than how much I was teaching. First of all, once you already know how to solve a problem, it's always interesting to look at other possible solutions. I've found sometimes that students were providing better (more concise and readable) solutions than mine. Last but not least, before advising someone about conding style or a more idiomatic solution, I always double check things from different sources. There is nothing wrong making mistakes, especially if you are learning... but it would be damaging for the student if I was teaching them something wrong, so I need to be sure about what I say. This of course makes me study, even the basic things, again and again and at the end of the day, my skills are better too.
Once you join the mentors group, you are invited to a private Slack where you can count on the help of other mentors (we have channels for each track/language) or ask questions. So, if you are not sure about something, you can always ask around.
If my story and experience convinced you, Exercism is looking for more mentors! The more we have available, the less time the students have to wait in a queue to be mentored. You can find all the instructions at this address https://mentoring.exercism.io
↧
Codementor: Python Style Guide - Complete
This style guide aims to document my preferred style for writing Python code.
↧
Peter Bengtsson: How to JSON schema validate 10x (or 100x) faster in Python
This is perhaps insanely obvious but it was a measurement I had to do and it might help you too if you use python-jsonschema a lot too.
I have this project which has a migration script that needs to transfer about 1M records from one PostgreSQL database, transform it a bit, validate it, and store it in another PostgreSQL database. The validation step was done like this:
fromjsonschemaimportvalidate...withopen(os.path.join(settings.BASE_DIR,"schema.yaml"))asf:SCHEMA=yaml.load(f)["schema"]...classBuild(models.Model):...@classmethoddefvalidate_build(cls,build):validate(build,SCHEMA)That works fine when you have a slow trickle of these coming in with many seconds or minutes apart. But when you have to do about 1M of them, the speed overhead starts to really matter. Granted, in this context, it's just a migration which is hopefully only done once but it helps that it doesn't take too long since it makes it easier to not have any downtime.
What about python-fastjsonschema?
The name python-fastjsonschema just sounds very appealing but I'm just not sure how mature it is or what the subtle differences are between that and the more established python-jsonschema which I was already using.
It has two ways of using it either...
fastjsonschema.validate(schema,data)...or...
validator=fastjsonschema.compile(schema)validator(data)That got me thinking, why don't I just do that with regular python-jsonschema!
All you need to do is crack open the validate function and you can now re-used one instance for multiple pieces of data:
fromjsonschema.validatorsimportvalidator_forklass=validator_for(schema)klass.check_schema(schema)# optionalinstance=klass(SCHEMA)instance.validate(data)I rewrote my projects code to this:
fromjsonschemaimportvalidate...withopen(os.path.join(settings.BASE_DIR,"schema.yaml"))asf:SCHEMA=yaml.load(f)["schema"]_validator_class=validator_for(SCHEMA)_validator_class.check_schema(SCHEMA)validator=_validator_class(SCHEMA)...classBuild(models.Model):...@classmethoddefvalidate_build(cls,build):validator.validate(build)How do they compare, performance-wise?
Let this simple benchmark code speak for itself:
frombuildhub.main.modelsimportBuild,SCHEMAimportfastjsonschemafromjsonschemaimportvalidate,ValidationErrorfromjsonschema.validatorsimportvalidator_fordeff1(qs):forbuildinqs:validate(build.build,SCHEMA)deff2(qs):validator=validator_for(SCHEMA)forbuildinqs:validate(build.build,SCHEMA,cls=validator)deff3(qs):cls=validator_for(SCHEMA)cls.check_schema(SCHEMA)instance=cls(SCHEMA)forbuildinqs:instance.validate(build.build)deff4(qs):forbuildinqs:fastjsonschema.validate(SCHEMA,build.build)deff5(qs):validator=fastjsonschema.compile(SCHEMA)forbuildinqs:validator(build.build)# Reportingimporttimeimportstatisticsimportrandomfunctions=f1,f2,f3,f4,f5times={f.__name__:[]forfinfunctions}for_inrange(3):qs=list(Build.objects.all().order_by("?")[:1000])forfuncinfunctions:t0=time.time()func(qs)t1=time.time()times[func.__name__].append((t1-t0)*1000)deff(ms):returnf"{ms:.1f}ms"forname,numbersintimes.items():print("FUNCTION:",name,"Used",len(numbers),"times")print("\tBEST ",f(min(numbers)))print("\tMEDIAN",f(statistics.median(numbers)))print("\tMEAN ",f(statistics.mean(numbers)))print("\tSTDEV ",f(statistics.stdev(numbers)))Basically, 3 times for each of the alternative implementations, do a validation on a JSON blob (technically a Python dict) that is around 1KB in size.
The results:
FUNCTION: f1 Used 3 times
BEST 1247.9ms
MEDIAN 1309.0ms
MEAN 1330.0ms
STDEV 94.5ms
FUNCTION: f2 Used 3 times
BEST 1266.3ms
MEDIAN 1267.5ms
MEAN 1301.1ms
STDEV 59.2ms
FUNCTION: f3 Used 3 times
BEST 125.5ms
MEDIAN 131.1ms
MEAN 133.9ms
STDEV 10.1ms
FUNCTION: f4 Used 3 times
BEST 2032.3ms
MEDIAN 2033.4ms
MEAN 2143.9ms
STDEV 192.3ms
FUNCTION: f5 Used 3 times
BEST 16.7ms
MEDIAN 17.1ms
MEAN 21.0ms
STDEV 7.1msBasically, if you use python-jsonschema and create a reusable instance it's 10 times faster than the "default way". And if you do the same but with python-fastjsonscham it's 100 times faster.
By the way, in version f5 it validated 1,000 1KB records in 16.7ms. That's insanely fast!
↧
Codementor: Building a neighbour matrix with python
From maths formula to python implementation with python: a neighbours matrix.
↧
↧
Django Weblog: DSF Individual membership - call for implementation proposals
The DSF wishes to put in place a system for the nomination, approval and accession of Individual Members.
The DSF wants to expand its membership, not just in number, but also in diversity. The current mechanisms in place for bringing on new members are not wholly satisfactory.
The DSF seeks proposals to design and implement a system to improve the membership nomination system. A budget of USD$5,000 - USD$8,000 has been made available.
Proposals including a timeline and budget should be forwarded to the DSF Board.
Basic requirements
This process and its implementation will include:
- a web-based system for gathering nominations
- a mechanism allowing members to comment
- a system to record formal votes of DSF members
- a system by which the DSF Board can give final approval
- a system to ease the administration burden of adding new users
Exactly how all these parts are implemented is open to proposal.
Principles of DSF individual membership
The process and its implementation must be in line with four principles:
- Membership follows service: Individual Members are appointed by the DSF in recognition of their service to the Django community
- Membership represents belonging: Membership should represent belonging rather than merely joining. It signifies welcoming of an individual into a group.
- Membership should empower: Becoming a member should enable the individual to help take charge of the direction of our community, and act within it with more confidence, knowing that their thoughts and ideas will have value in the eyes of others, and that their initiatives are likely to find support. Above all, it should affirm to them their right to participate, take action and disagree.
- Becoming a member should be meaningful: If membership represents a place in the community rather than simply an administrative or legal entitlement, then becoming a member should have some meaning attached to it.
Membership process
The process therefore needs to:
not just allow, but also encourage, nominations that clearly explain the service the individual has made to the community, and the value of that service.
A mechanism needs to be created by which existing members can be alerted of nominations that are made (e.g. via the DSF email list, or to individual mailboxes, or some other way).
encourage and allow existing members to respond in ways that will stand as a record within the DSF (e.g. on its email list), and will in turn help show the nominee why they belong
All responses and expressions of approval should be visible to newly-elected members, so that they can see that they are valued and welcomed by individuals who have taken the trouble to say so.
give new members, some of whom may be less confident of their place in the community than others, reasons to feel that they are entitled to act as members of the community
The process should reflect the new members’ achievements and contributions back to them at the same time as sharing them with the community, to help make clear to them that they (and their opinions and activities) are positively valued.
give new and existing members the sense that it is a matter of significance to be elected to the DSF membership
New members should feel proud about their nomination and accession, and understand what it means (it should not leave them feeling unsure or baffled about its significance).
Implementation
Engagement of existing members
At present, the DSF membership does not do a very consistent job of nominating new members. The system should prompt and remind members to think of potential nominees (e.g. an automated monthly message).
Self-nomination
The system should allow non-members to nominate themselves, as well as being nominated by others.
In doing so it should make it easy for those people to provide the right kind of information about what they do, so that a person reading it, who doesn’t yet know them, will be in a position to make an informed judgement (and ultimately, an enthusiastic endorsement) of them.
Successfully eliciting this information in a form that fulfills this need is not easy.
In order to avoid creating two tiers of DSF member (those who were enthusiastically nominated, seconded and welcomed by others, and those who had to nominate themselves, with little response or enthusiasm from others) the self-nomination process must make it possible for self-nominated members to enjoy the same kind of reception. Ways to achieve this could include:
- guiding self-nominees to write strong descriptions and proposals for themselves (e.g. providing an example of a good self-nomination)
- automatically circulating their names to the membership, so that an existing member who knows them, or may know someone who knows them, is promoted to “sponsor” the nomination
- advising a self-nominee to contact an existing member they may know, who could sponsor them (this will be especially important for self-nominees with fewer connections)
Ultimately, a self-nominee deserves to be welcomed with the same kind of warmth that other nominees receive, and the system must find ways to overcome the natural difficulties in achieving this.
Administration
As far as possible, the system should reduce the burden of managing nominations. A single interface, as part of the Django Project website, should:
- prompt and encourage nominations
- accept nominations
- allow voting and positive comments
- share comments with the membership in a way that encourages further engagement
- allow the DSF board to approve a nomination
- when approved, add the nominee to the Django Project website, DSF email list or other forum, etc
- automate some basics of induction/welcome for new members
- automate a public announcement of their accession on Twitter
Negative flags
Only positive endorsements of a nominee should be circulated by the system amongst the DSF membership. Members however should be able to raise a flag if they have a concern about a particular nomination. This will be referred to the DSF Board, to be dealt with appropriately.
Proposals
Proposals for implementing a system should be forwarded to the DSF Board.
Please include as much detail as you feel able to in an initial proposal. Your proposal should include:
- a timeline for implementation
- a budget
The Board will also welcome questions and requests for clarification.
↧
Ned Batchelder: Careful with negative assertions
A cautionary tale about testing that things are unequal...
We had a test that was kind of like this:
def test_thing():
data = "I am the data"
self.assertNotEqual(
modify_another_way(change_the_thing(data)),
data
)
But someone refactored the test oh-so-slightly, like this:
def test_thing():
data = "I am the data"
modified = modify_another_way(change_the_thing(data)),
self.assertNotEqual(
modified,
data
)
Now the test isn’t testing what it should be testing, and will pass even if change_the_thing and modify_another_way both return their argument unchanged. (I’ll explain why below.)
Negative tests (asserting that two things are unequal) is really tricky, because there are infinite things unequal to your value. Your assertion could pass because you accidentally have a different one of those unequal values than you thought.
Better would be to know what unequal value you are producing, and test that you have produced that value, with an equality assertion. Then if something unexpectedly shifts out from under you, you will find out.
Why the test was broken: the refactorer left the trailing comma on the “modified =” line, so “modified” is a 1-element tuple. The comparison is now between a tuple and a string, which are always unequal, even if the first element of the tuple is the same as the string.
↧
Mike Driscoll: PyDev of the Week: Bernat Gabor
This week we welcome Bernat Gabor (@gjbernat) as our PyDev of the Week! Bernat is a core developer of the tox automation project. You can check out his Github to see what other open source projects he is a part of. Let’s take a few moments to learn more about Bernat!

Can you tell us a little about yourself (hobbies, education, etc.):
I was born and raised in Transylvania, Romania. I’ve got into computer science starting with my high school studies, and there was no going back on it ever since. I’ve done my BSc studies at Sapientia – Hungarian University of Transylvania and then followed up with my master studies at Budapest University of Technology and Economics. Parallel with doing the master studies I’ve started working at Gravity R&D (a company that provides a recommendation engine under the Software-as-a-Service model), where I’ve been for almost five years. I now live in London, UK having reallocated here over two years ago and have been working ever since at Bloomberg LP.
Why did you start using Python?
I’ve started using Python six years ago, while I was working at Gravity R&D. To provide excellent recommendations with the most critical pre-requisite is to have quality learning dataset. While exploring what’s the best way to collect data I’ve stumbled upon this language called Python which came with batteries included and allowed me to quickly alter/improve data collection (compared to the other languages used at the company at that time – Java/Groovy).
What other programming languages do you know and which is your favourite?
I know C/C++, C#, Java, Groovy, JavaScript, SQL and Python. To a lesser degree, I’m familiar with Julia, R, Assembly and VHDL. Python is the favourite.
What projects are you working on now?
tox is the main one. At the moment I have issues/pull requests open to mypy and looking into pip too. I’ve had some previous encounters with pytest, readthedocs.org.
Which Python libraries are your favourite (core or 3rd party)?
argparse. It’s still the most feature rich and straightforward command line argument define/parser library I’ve seen out there.
How did you get started with tox?
At my workplace, I needed to provide support for both Python 2 and 3 for a project. I’ve looked around what are my options in trying to do this, and what tools mainstream open source projects use for this. I quickly stumbled upon tox and found a few improvement opportunities once I started using it. I’ve opened a few PRs for it, and after a while, I saw myself as one of the main contributors. Becoming a maintainer was a natural evolution of taking ownership of all the changes I’ve been making.
Do you have any advice for others who would like to contribute to open source?
Start with something small and always communicate with the maintainers before you make a change. Be open and try to understand their pieces of advice.
Is there anything else you’d like to say?
Be respectful when interacting with any open-source project. We must always remember that all of mostly does it in our free time with no compensation; and maintainers have to juggle around with tons of constraints when accepting features.
Thanks for doing the interview!
↧
Tryton News: Translations updated every months
@ced wrote:
Tryton uses pootle to manage and collaborate on translating it into many languages.
We have setup a monthly task that update the terms on the server with the last development version. This allows translators to work during the full 6 months between the releases instead of just the last month.
We hope that it will ease and smooth the translator job and so attract new translators and new languages.If you want to help translating, you can make suggestion directly and once you mastering it, you can contact the language administrator to grant more access.
If your language is not yet supported by Tryton and you want to contribute, please fill an request.

Posts: 1
Participants: 1
↧
↧
Bhishan Bhandari: Basic File Operations – Golang
One of the most basic task when working on a server is the ability to effectively operate with the files and file system. Like many languages, Golang has convenient methods to work with files. The intentions of this post is to host a minimalist set of examples on working with files using Golang. Creating an […]
The post Basic File Operations – Golang appeared first on The Tara Nights.
↧
Julien Danjou: The Best flake8 Extensions for your Python Project
In the last blog post about coding style, we dissected what the state of the art was regarding coding style check in Python.
As we've seen, Flake8 is a wrapper around several tools and is extensible via plugins: meaning that you can add your own checks. I'm a heavy user of Flake8 and relies on a few plugins to extend the check coverage of common programming mistakes in Python. Here's the list of the one I can't work without. As a bonus, you'll find at the end of this post, a sample of my go-to tox.ini file.
flake8-import-order
The name is quite explicit: this extension checks the order of your import statements at the beginning of your files. By default, it uses a style that I enjoy, which looks like:
import os
import sys
import requests
import yaml
import myproject
from myproject.utils import somemodule
The builtin modules are grouped as the first ones. Then comes a group for each third-party modules that are imported. Finally, the last group manages the modules of the current project. I find this way of organizing modules import quite clear and easy to read.
To make sure flake8-import-order knows about the name of your project module name, you need to specify it in tox.ini with the application-import-names option.
If you beg to differ, you can use any of the other styles that flake8-import-order offers by default by setting the import-order-style option. You can obviously provide your own style.
flake8-blind-except
The flake8-blind-except extension checks that no except statement is used without specifying an exception type. The following excerpt is, therefore, considered invalid:
try:
do_something()
except:
pass
Using except without any exception type specified is considered bad practice as it might catch unwanted exceptions. It forces the developer to think about what kind of errors might happen and should really be caught.
In the rare case any exception should be caught, it's still possible to use except Exception anyway.
flake8-builtins
The flake8-builtins plugin checks that there is no name collision between your code and the Python builtin variables.
For example, this code would trigger an error:
def first(list):
return list[0]
As list is a builtin in Python (to create a list!), shadowing its definition by using list as the name of a parameter in a function signature would trigger a warning from flake8-builtins.
While the code is valid, it's a bad habit to override Python builtins functions. It might lead to tricky; in the above example, if you ever need to call list(), you won't be able to.
flake8-logging-format
This module is handy as it is still slapping my fingers once in a while. When using the logging module, it prevents from writing this kind of code:
mylogger.info("Hello %s" % mystring)
While this works, it's suboptimal as it forces the string interpolation. If the logger is configured to print only messages with a logging level of warning or above, doing a string interpolation here is pointless.
Therefore, one should instead write:
mylogger.info("Hello %s", mystring)
Same goes if you use format to do any formatting.
Be aware that contrary to other flake8 modules, this one does not enable the check by default. You'll need to add enable-extensions=G in your tox.ini file.
flake8-docstrings
The flake8-docstrings module checks the content of your Python docstrings for respect of the PEP 257. This PEP is full of small details about formatting your docstrings the right way, which is something you wouldn't be able to do without such a tool. A simple example would be:
class Foobar:
"""A foobar"""
While this seems valid, there is a missing point at the end of the docstring.
Trust me, especially if you are writing a library that is consumed by other developers, this is a must-have.
flake8-rst-docstrings
This extension is a good complement to flake8-docstrings: it checks that the content of your docstrings is valid RST. It's a no-brainer, so I'd install it without question. Again, if your project exports a documented API that is built with Sphinx, this is a must-have.
My standard tox.ini
Here's the standard tox.ini excerpt that I use in most of my projects. You can copy paste it and use
[testenv:pep8]
deps = flake8
flake8-import-order
flake8-blind-except
flake8-builtins
flake8-docstrings
flake8-rst-docstrings
flake8-logging-format
commands = flake8
[flake8]
exclude = .tox
# If you need to ignore some error codes in the whole source code
# you can write them here
# ignore = D100,D101
show-source = true
enable-extensions=G
application-import-names = <myprojectname>
Before disabling an error code for your entire, remember that you can force flake8 to ignore a particular instance of the error by adding the # noqa tag at the end of the line.
If you have any flake8 extension that you think is useful, please let me know in the comment section!
↧
Codementor: Top Data Science Hacks
Top tips and tricks for data science enthusiast to make more productive use of time & make difficult data science tasks simpilier.
↧