![Asynchronous Python for Web Development]()
Asynchronous programming is well suited for tasks that include reading and writing files frequently or sending data back and forth from a server. Asynchronous programs perform I/O operations in a non-blocking fashion, meaning that they can perform other tasks while waiting for data to return from a client rather than waiting idly, wasting resources and time.
Python, like many other languages, suffers from not being asynchronous by default. Fortunately, rapid changes in the IT world allow us to write asynchronous code even using languages that weren't originally meant to do so. Over the years, the demands for speed are exceeding hardware capabilities and companies around the world have come together with the Reactive Manifesto in order to deal with this issue.
The non-blocking behavior of asynchronous programs can result in significant performance benefits in the context of a web application, helping to address the issue of developing reactive apps.
Cooked into Python 3 are some powerful tools for writing asynchronous applications. In this article, we'll be covering some of these tools, especially as they relate to web development.
We'll be developing a simple reactive aiohttp based app to display the current relevant sky coordinates of planets from the Solar System, given the geographic coordinates of the user. You can find the app here, and the source code here.
We'll end up by discussing how to prepare the app to deploy to Heroku.
Introduction to Asynchronous Python
For those familiar with writing traditional Python code, making the jump to asynchronous code can be conceptually a little tricky. Asynchronous code in Python relies on coroutines, which in conjunction with an event loop allow for writing code that can appear to be doing more than one thing at a time.
Coroutines can be thought of as functions that have points in code where they give program control back to the calling context. These "yield" points allow for pausing and resuming coroutine execution, in addition to exchanging data between contexts.
The event loop decides what chunk of code runs at any given moment - it is responsible for pausing, resuming, and communicating between coroutines. This means that parts of different coroutines might end up executing in an order other than the one in which they were scheduled. This idea of running different chunks of code out of order is called concurrency.
Thinking about concurrency in the context of making HTTP requests can be elucidating. Imagine wanting to make many independent requests to a server. For example, we might want to query a website to get statistics about all the sports players in a given season.
We could make each request sequentially. However, with every request, we can imagine that out code might spend some time waiting around for a request to get delivered to the server, and for the response to be sent back.
Sometimes, these operations can take even multiple seconds. The application may experience network lag due to a high number of users, or simply due to the speed limits of the given server.
What if our code could do other things while waiting around for a response from the server? Moreover, what if it would only go back to processing a given request once response data arrived? We could make many requests in quick succession if we didn't have to wait for each individual request to finish before proceeding to the next in the list.
Coroutines with an event loop allow us to write code that behaves in exactly this manner.
asyncio
asyncio, part of the Python standard library, provides an event loop and a set of tools for controlling it. With asyncio we can schedule coroutines for execution, and create new coroutines (really asyncio.Task objects, using the parlance of asyncio) that will only finish executing once constituent coroutines finish executing.
Unlike other asynchronous programming languages, Python does not force us to use the event loop that ships with the language. As Brett Cannon points out, Python coroutines constitute an asynchronous API, with which we can use any event loop. Projects exist that implement a completely different event loop, like curio, or allow for dropping in a different event loop policy for asyncio (the event loop policy is what manages the event loop "behind the scenes"), like uvloop.
Let's take a look at a code snippet that runs two coroutines concurrently, each one printing out a message after one second:
# example1.py
import asyncio
async def wait_around(n, name):
for i in range(n):
print(f"{name}: iteration {i}")
await asyncio.sleep(1.0)
async def main():
await asyncio.gather(*[
wait_around(2, "coroutine 0"), wait_around(5, "coroutine 1")
])
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
me@local:~$ time python example1.py
coroutine 1: iteration 0
coroutine 0: iteration 0
coroutine 1: iteration 1
coroutine 0: iteration 1
coroutine 1: iteration 2
coroutine 1: iteration 3
coroutine 1: iteration 4
real 0m5.138s
user 0m0.111s
sys 0m0.019s
This code executes in roughly 5 seconds, as the asyncio.sleep coroutine establishes points at which the event loop can jump to executing other code. Moreover, we've told the event loop to schedule both wait_around instances for concurrent execution with the asyncio.gather function.
asyncio.gather takes a list of "awaitables" (ie, coroutines, or asyncio.Task objects) and returns a single asyncio.Task object that only finishes when all its constituent tasks/coroutines are finished. The last two lines are asyncio boilerplate for running a given coroutine until its finished executing.
Coroutines, unlike functions, won't start executing immediately after they're invoked. The await keyword is what tells the event loop to schedule a coroutine for execution.
If we take out the await in front of asyncio.sleep, the program finishes (almost) instantly, as we haven't told the event loop to actually execute the coroutine, which in this case tells the coroutine to pause for a set amount of time.
With a grasp of what asynchronous Python code looks like, let's move on to asynchronous web development.
Installing aiohttp
aiohttp is a Python library for making asynchronous HTTP requests. In addition, it provides a framework for putting together the server part of a web application. Using Python 3.5+ and pip, we can install aiohttp:
pip install --user aiohttp
Client-Side: Making Requests
The following examples show how to we can download the HTML content of the "example.com" website using aiohttp:
# example2_basic_aiohttp_request.py
import asyncio
import aiohttp
async def make_request():
url = "https://example.com"
print(f"making request to {url}")
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
if resp.status == 200:
print(await resp.text())
loop = asyncio.get_event_loop()
loop.run_until_complete(make_request())
A few things to emphasize:
- Much like with
await asyncio.sleep we must use await with resp.text() in order to get the HTML content of the page. If we left it out, our program's output would be something like the following:
me@local:~$ python example2_basic_aiohttp_request.py
<coroutine object ClientResponse.text at 0x7fe64e574ba0>
async with is a context manager that works with coroutines instead of functions. In both cases in which it gets used, we can imagine that internally, aiohttp is closing down connections to servers or otherwise freeing up resources.
aiohttp.ClientSession has methods that correspond to HTTP verbs. In the same
way that session.get is making a GET request, session.post would make a POST request.
This example by itself offers no performance advantage over making synchronous HTTP requests. The real beauty of client-side aiohttp lies in making multiple concurrent requests:
# example3_multiple_aiohttp_request.py
import asyncio
import aiohttp
async def make_request(session, req_n):
url = "https://example.com"
print(f"making request {req_n} to {url}")
async with session.get(url) as resp:
if resp.status == 200:
await resp.text()
async def main():
n_requests = 100
async with aiohttp.ClientSession() as session:
await asyncio.gather(
*[make_request(session, i) for i in range(n_requests)]
)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
Instead of making each request sequentially, we ask asyncio to do them concurrently, with asycio.gather.
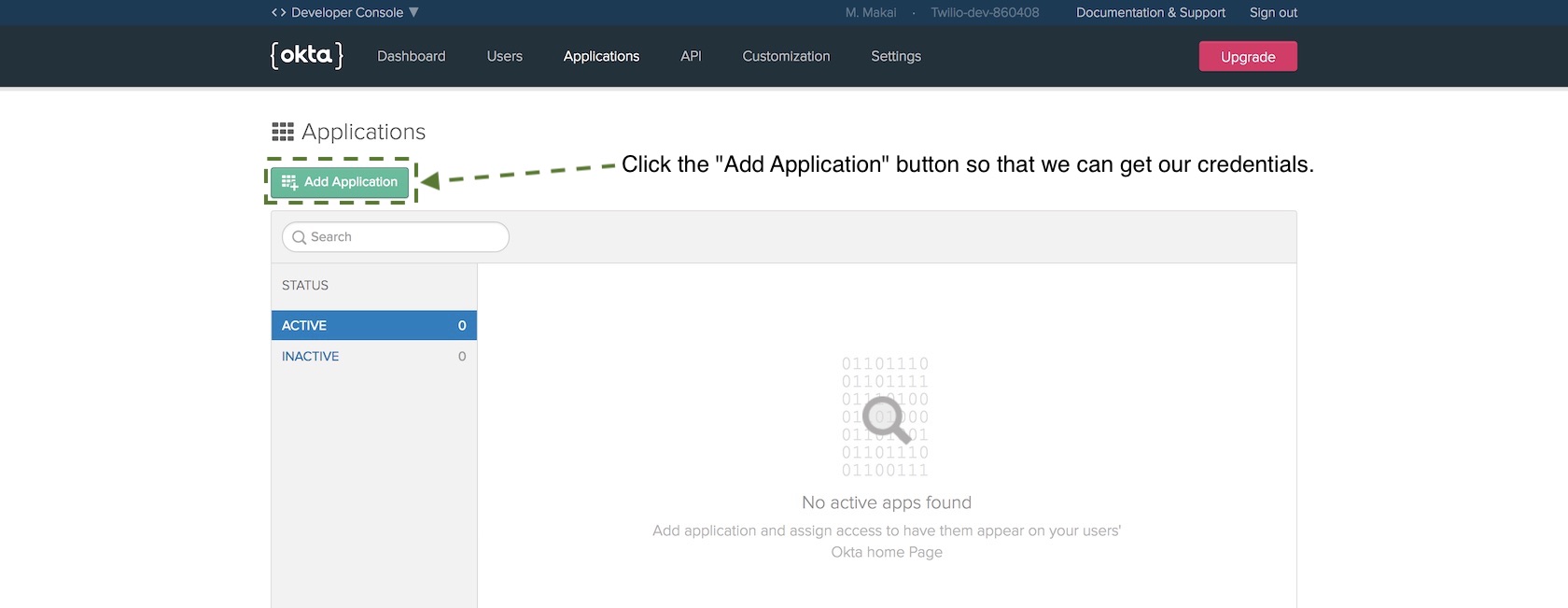
PlanetTracker Web App
Through the course of this section, I intend to demonstrate how to put together an app that reports the current coordinates of planets in the sky at the user's location (ephemerides).
The user supplies his or her location with the web Geolocation API, which does the work for us.
I'll end up by showing how to set up a Procfile in order to deploy the app on Heroku. If you plan on following along as I work through putting the app together, you should do the following, assuming you have Python 3.6 and pip installed:
me@local:~$ mkdir planettracker && cd planettracker
me@local:~/planettracker$ pip install --user pipenv
me@local:~/planettracker$ pipenv --python=3
Planet Ephemerides with PyEphem
An astronomical object's ephemeris is its current position in the sky at a given location and time on Earth. PyEphem is a Python library that allows for precisely calculating ephemerides.
It is especially well suited to the task at hand, as it has common astronomical objects cooked into the library. First, let's install PyEphem:
me@local:~/planettracker$ pipenv install ephem
Getting the current coordinates of Mars is as simple as using an instance of the Observer class to compute its coordinates:
import ephem
import math
convert = math.pi / 180.
mars = ephem.Mars()
greenwich = ephem.Observer()
greenwich.lat = "51.4769"
greenwich.lon = "-0.0005"
mars.compute(observer)
az_deg, alt_deg = mars.az*convert, mars.alt*convert
print(f"Mars' current azimuth and elevation: {az_deg:.2f} {alt_deg:.2f}")
In order to make getting planet ephemerides easier, let's set up a class PlanetTracker with a method that returns a given planet's current azimith and altitude, in degrees (PyEphem defaults to using radians, not degrees, to represent angles internally):
# planet_tracker.py
import math
import ephem
class PlanetTracker(ephem.Observer):
def __init__(self):
super(PlanetTracker, self).__init__()
self.planets = {
"mercury": ephem.Mercury(),
"venus": ephem.Venus(),
"mars": ephem.Mars(),
"jupiter": ephem.Jupiter(),
"saturn": ephem.Saturn(),
"uranus": ephem.Uranus(),
"neptune": ephem.Neptune()
}
def calc_planet(self, planet_name, when=None):
convert = 180./math.pi
if when is None:
when = ephem.now()
self.date = when
if planet_name in self.planets:
planet = self.planets[planet_name]
planet.compute(self)
return {
"az": float(planet.az)*convert,
"alt": float(planet.alt)*convert,
"name": planet_name
}
else:
raise KeyError(f"Couldn't find {planet_name} in planets dict")
Now we can get anyone of the seven other planets in the solar system quite easily:
from planet_tracker import PlanetTracker
tracker = PlanetTracker()
tracker.lat = "51.4769"
tracker.lon = "-0.0005"
tracker.calc_planet("mars")
Running this piece of code would yield:
{'az': 92.90019644871396, 'alt': -23.146670983905302, 'name': 'mars'}
Server-Side aiohttp: HTTP Routes
Given some latitude and longitude, we can easily get a planet's current ephemeris, in degrees. Now let's set up an aiohttp route to allow a client to get a planet's ephemeris given the user's geolocation.
Before we can start writing code, we have to think about what HTTP verbs we want to associate with each of these tasks. It makes sense to use POST for the first task, as we're setting the observer's geographic coordinates. Given that we're getting ephemerides, it makes sense to use GET for the second task:
# aiohttp_app.py
from aiohttp import web
from planet_tracker import PlanetTracker
@routes.get("/planets/{name}")
async def get_planet_ephmeris(request):
planet_name = request.match_info['name']
data = request.query
try:
geo_location_data = {
"lon": str(data["lon"]),
"lat": str(data["lat"]),
"elevation": float(data["elevation"])
}
except KeyError as err:
# default to Greenwich Observatory
geo_location_data = {
"lon": "-0.0005",
"lat": "51.4769",
"elevation": 0.0,
}
print(f"get_planet_ephmeris: {planet_name}, {geo_location_data}")
tracker = PlanetTracker()
tracker.lon = geo_location_data["lon"]
tracker.lat = geo_location_data["lat"]
tracker.elevation = geo_location_data["elevation"]
planet_data = tracker.calc_planet(planet_name)
return web.json_response(planet_data)
app = web.Application()
app.add_routes(routes)
web.run_app(app, host="localhost", port=8000)
Here, the route.get decorator indicates that we want the get_planet_ephmeris coroutine to be the handler for a variable GET route.
Before we run this, let's install aiohttp with pipenv:
me@local:~/planettracker$ pipenv install aiohttp
Now we can run our app:
me@local:~/planettracker$ pipenv run python aiohttp_app.py
When we run this, we can point our browser to our different routes to see the data our server returns. If I put localhost:8000/planets/mars into my browser's address bar, I should see some response like the following:
{"az": 98.72414165963292, "alt": -18.720718647020792, "name": "mars"}
This is the same as issuing the following curl command:
me@local:~$ curl localhost:8000/planets/mars
{"az": 98.72414165963292, "alt": -18.720718647020792, "name": "mars"}
If you're not familiar with curl, it is a convenient command-line tool for, among other things, testing your HTTP routes.
We can supply a GET URL to curl:
me@local:~$ curl localhost:8000/planets/mars
{"az": 98.72414165963292, "alt": -18.720718647020792, "name": "mars"}
This gives us Mars' ephemeris at the Greenwich Observatory in the UK.
We can encode coordinates in the URL of the GET request so we can get Mars' ephemeris at other locations (note the quotes around the URL):
me@local:~$ curl "localhost:8000/planets/mars?lon=145.051&lat=-39.754&elevation=0"
{"az": 102.30273048280189, "alt": 11.690380174890928, "name": "mars"
curl can also be used to make POST requests as well:
me@local:~$ curl --header "Content-Type: application/x-www-form-urlencoded" --data "lat=48.93&lon=2.45&elevation=0" localhost:8000/geo_location
{"lon": "2.45", "lat": "48.93", "elevation": 0.0}
Note that by providing the --data field, curl automatically assumes we're making a POST request.
Before we move on, I should note that the web.run_app function runs our app in a blocking manner. This is decidedly not what we're looking to accomplish!
To run it concurrently, we have to add a little more code:
# aiohttp_app.py
import asyncio
...
# web.run_app(app)
async def start_app():
runner = web.AppRunner(app)
await runner.setup()
site = web.TCPSite(
runner, parsed.host, parsed.port)
await site.start()
print(f"Serving up app on {parsed.host}:{parsed.port}")
return runner, site
loop = asyncio.get_event_loop()
runner, site = loop.run_until_complete(start_async_app())
try:
loop.run_forever()
except KeyboardInterrupt as err:
loop.run_until_complete(runner.cleanup())
Note the presence of loop.run_forever instead of the call to loop.run_until_complete that we saw earlier. Instead of executing a set number of coroutines, we want our program to start a server that will handle requests until we exit with ctrl+c, at which point it will gracefully shutdown the server.
HTML/JavaScript Client
aiohttp allows us to serve up HTML and JavaScript files. Using aiohttp for serving "static" assets like CSS and JavaScript is discouraged, but for the purposes of this app, it shouldn't be an issue.
Let's add a few lines to our aiohttp_app.py file to serve up an HTML file that references a JavaScript file:
# aiohttp_app.py
...
@routes.get('/')
async def hello(request):
return web.FileResponse("./index.html")
app = web.Application()
app.add_routes(routes)
app.router.add_static("/", "./")
...
The hello coroutine is setting up a GET route at localhost:8000/ that serves up the contents of index.html, located in the same directory from which we run our server.
The app.router.add_static line is setting up a route at localhost:8000/ to serve up files in the same directory from which we run our server. This means that our browser will be able to find the JavaScript file we reference in index.html.
Note: In production, it makes sense to move HTML, CSS and JS files into a separate directory that gets served up on its own. This makes it so the curious user cannot access our server code.
The HTML file is quite simple:
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Planet Tracker</title>
</head>
<body>
<div id="app">
<label id="lon">Longitude: <input type="text"/></label><br/>
<label id="lat">Latitude: <input type="text"/></label><br/>
<label id="elevation">Elevation: <input type="text"/></label><br/>
</div>
<script src="/app.js"></script>
</body>
Though, the JavaScript file is a little more involved:
var App = function() {
this.planetNames = [
"mercury",
"venus",
"mars",
"jupiter",
"saturn",
"uranus",
"neptune"
]
this.geoLocationIds = [
"lon",
"lat",
"elevation"
]
this.keyUpInterval = 500
this.keyUpTimer = null
this.planetDisplayCreated = false
this.updateInterval = 2000 // update very second and a half
this.updateTimer = null
this.geoLocation = null
this.init = function() {
this.getGeoLocation().then((position) => {
var coords = this.processCoordinates(position)
this.geoLocation = coords
this.initGeoLocationDisplay()
this.updateGeoLocationDisplay()
return this.getPlanetEphemerides()
}).then((planetData) => {
this.createPlanetDisplay()
this.updatePlanetDisplay(planetData)
}).then(() => {
return this.initUpdateTimer()
})
}
this.update = function() {
if (this.planetDisplayCreated) {
this.getPlanetEphemerides().then((planetData) => {
this.updatePlanetDisplay(planetData)
})
}
}
this.get = function(url, data) {
var request = new XMLHttpRequest()
if (data !== undefined) {
url += `?${data}`
}
// console.log(`get: ${url}`)
request.open("GET", url, true)
return new Promise((resolve, reject) => {
request.send()
request.onreadystatechange = function(){
if (this.readyState === XMLHttpRequest.DONE && this.status === 200) {
resolve(this)
}
}
request.onerror = reject
})
}
this.processCoordinates = function(position) {
var coordMap = {
'longitude': 'lon',
'latitude': 'lat',
'altitude': 'elevation'
}
var coords = Object.keys(coordMap).reduce((obj, name) => {
var coord = position.coords[name]
if (coord === null || isNaN(coord)) {
coord = 0.0
}
obj[coordMap[name]] = coord
return obj
}, {})
return coords
}
this.coordDataUrl = function (coords) {
postUrl = Object.keys(coords).map((c) => {
return `${c}=${coords[c]}`
})
return postUrl
}
this.getGeoLocation = function() {
return new Promise((resolve, reject) => {
navigator.geolocation.getCurrentPosition(resolve)
})
}
this.getPlanetEphemeris = function(planetName) {
var postUrlArr = this.coordDataUrl(this.geoLocation)
return this.get(`/planets/${planetName}`, postUrlArr.join("&")).then((req) => {
return JSON.parse(req.response)
})
}
this.getPlanetEphemerides = function() {
return Promise.all(
this.planetNames.map((name) => {
return this.getPlanetEphemeris(name)
})
)
}
this.createPlanetDisplay = function() {
var div = document.getElementById("app")
var table = document.createElement("table")
var header = document.createElement("tr")
var headerNames = ["Name", "Azimuth", "Altitude"]
headerNames.forEach((headerName) => {
var headerElement = document.createElement("th")
headerElement.textContent = headerName
header.appendChild(headerElement)
})
table.appendChild(header)
this.planetNames.forEach((name) => {
var planetRow = document.createElement("tr")
headerNames.forEach((headerName) => {
planetRow.appendChild(
document.createElement("td")
)
})
planetRow.setAttribute("id", name)
table.appendChild(planetRow)
})
div.appendChild(table)
this.planetDisplayCreated = true
}
this.updatePlanetDisplay = function(planetData) {
planetData.forEach((d) => {
var content = [d.name, d.az, d.alt]
var planetRow = document.getElementById(d.name)
planetRow.childNodes.forEach((node, idx) => {
var contentFloat = parseFloat(content[idx])
if (isNaN(contentFloat)) {
node.textContent = content[idx]
} else {
node.textContent = contentFloat.toFixed(2)
}
})
})
}
this.initGeoLocationDisplay = function() {
this.geoLocationIds.forEach((id) => {
var node = document.getElementById(id)
node.childNodes[1].onkeyup = this.onGeoLocationKeyUp()
})
var appNode = document.getElementById("app")
var resetLocationButton = document.createElement("button")
resetLocationButton.setAttribute("id", "reset-location")
resetLocationButton.onclick = this.onResetLocationClick()
resetLocationButton.textContent = "Reset Geo Location"
appNode.appendChild(resetLocationButton)
}
this.updateGeoLocationDisplay = function() {
Object.keys(this.geoLocation).forEach((id) => {
var node = document.getElementById(id)
node.childNodes[1].value = parseFloat(
this.geoLocation[id]
).toFixed(2)
})
}
this.getDisplayedGeoLocation = function() {
var displayedGeoLocation = this.geoLocationIds.reduce((val, id) => {
var node = document.getElementById(id)
var nodeVal = parseFloat(node.childNodes[1].value)
val[id] = nodeVal
if (isNaN(nodeVal)) {
val.valid = false
}
return val
}, {valid: true})
return displayedGeoLocation
}
this.onGeoLocationKeyUp = function() {
return (evt) => {
// console.log(evt.key, evt.code)
var currentTime = new Date()
if (this.keyUpTimer !== null){
clearTimeout(this.keyUpTimer)
}
this.keyUpTimer = setTimeout(() => {
var displayedGeoLocation = this.getDisplayedGeoLocation()
if (displayedGeoLocation.valid) {
delete displayedGeoLocation.valid
this.geoLocation = displayedGeoLocation
console.log("Using user supplied geo location")
}
}, this.keyUpInterval)
}
}
this.onResetLocationClick = function() {
return (evt) => {
console.log("Geo location reset clicked")
this.getGeoLocation().then((coords) => {
this.geoLocation = this.processCoordinates(coords)
this.updateGeoLocationDisplay()
})
}
}
this.initUpdateTimer = function () {
if (this.updateTimer !== null) {
clearInterval(this.updateTimer)
}
this.updateTimer = setInterval(
this.update.bind(this),
this.updateInterval
)
return this.updateTimer
}
this.testPerformance = function(n) {
var t0 = performance.now()
var promises = []
for (var i=0; i<n; i++) {
promises.push(this.getPlanetEphemeris("mars"))
}
Promise.all(promises).then(() => {
var delta = (performance.now() - t0)/1000
console.log(`Took ${delta.toFixed(4)} seconds to do ${n} requests`)
})
}
}
var app
document.addEventListener("DOMContentLoaded", (evt) => {
app = new App()
app.init()
})
This app will periodically (every 2 seconds) update and display planet ephemerides. We can supply our own geo coordinates, or let the Web Geolocation API determine our current location. The app updates the geolocation if the user stops typing for a half a second or more.
While this is not a JavaScript tutorial, I think it's useful to understand what different parts of the script are doing:
createPlanetDisplay is dynamically creating HTML elements and binding them to the Document Object Model (DOM)updatePlanetDisplay takes data received from the server and populates the elements created by createPlanetDisplayget makes a GET request to the server. The XMLHttpRequest object allows this to be done without reloading the page.post makes a POST request to the server. Like with get this is done without reloading the page.getGeoLocation uses the Web Geolocation API to get the user's current geographic coordinates. This must be fulfilled "in a secure context" (ie we must be using HTTPSnotHTTP).getPlanetEphemeris and getPlanetEphemerides make GET requests to the server to get ephemeris for a specific planet and to get ephemerides for all planets, respectively.testPerformance makes n requests to the server, and determines how long it takes.
Primer on Deploying to Heroku
Heroku is a service for easily deploying web applications. Heroku takes care of configuring web-facing components of an application, like configuring reverse proxies or worrying about load balancing. For applications handling few requests and a small number of users, Heroku is a great free hosting service.
Deploying Python applications to Heroku has become very easy in recent years. At its core, we have to create two files that list our application's dependencies and tell Heroku how to run our application.
A Pipfile takes care of the former, while a Procfile takes care of the latter. A Pipfile is maintained by using pipenv - we add to our Pipfile (and Pipfile.lock) every time we install a dependency.
In order to run our app on Heroku, we have to add one more dependency:
me@local:~/planettracker$ pipenv install gunicorn
We can create our own Procfile, adding the following line to it:
web: gunicorn aiohttp_app:app --worker-class aiohttp.GunicornWebWorker
Basically this is telling Heroku to use Gunicorn to run our app, using the special aiohttp web worker.
Before you can deploy to Heroku, you'll need to start tracking the app with Git:
me@local:~/planettracker$ git init
me@local:~/planettracker$ git add .
me@local:~/planettracker$ git commit -m "first commit"
Now you can follow the instructions on the Heroku devcenter here for deploying your app. Note that you can skip the "Prepare the App" step of this tutorial, as you already have a git tracked app.
Once your application is deployed, you can navigate to the chosen Heroku URL in your browser and view the app, which will look something like this:
![Asynchronous Python for Web Development]()
Conclusion
In this article, we dived into what asynchronous web development in Python looks like - it's advantages and uses. Afterwards, we built a simple reactive aiohttp based app that dynamically displays the current relevant sky coordinates of planets from the Solar System, given the geographic coordinates of the user.
Upon building the application, we've prepped it for deployment on Heroku.
As mentioned before, you can find both the source code and application demo if needed.
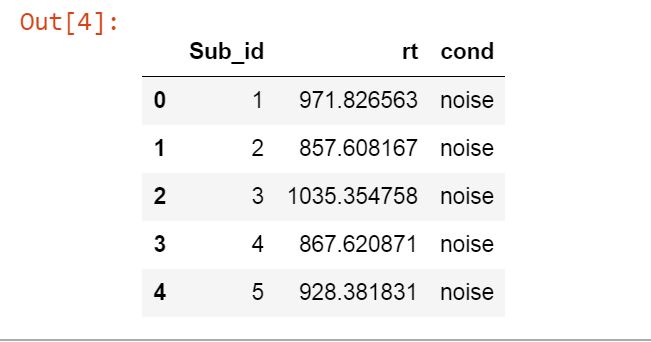 First 5 rows of the Pandas dataframe.
First 5 rows of the Pandas dataframe.
 Output: ANOVA table
Output: ANOVA table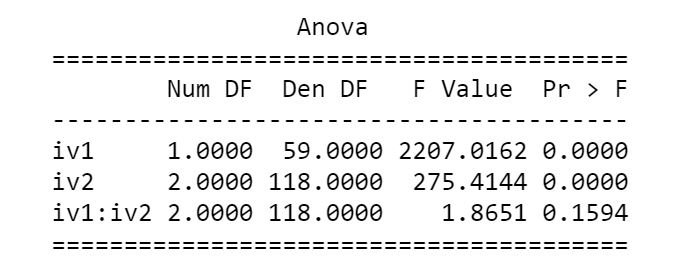 ANOVA Table Statmodels
ANOVA Table Statmodels












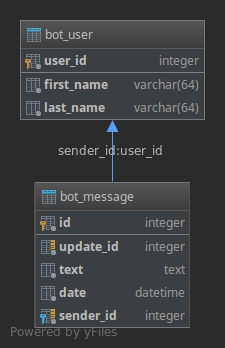
 Attention: It might happen that messages reach your bot multiple times (for example, if Telegram could not clearly confirm the message was delivered). It might also happen, that messages arrive at your hook in any order. The later is the reason why dropping messages of a lower
Attention: It might happen that messages reach your bot multiple times (for example, if Telegram could not clearly confirm the message was delivered). It might also happen, that messages arrive at your hook in any order. The later is the reason why dropping messages of a lower 

 :
:

 Enjoy coding!
Enjoy coding!