In python, sets are container objects that are used to store unique immutable objects. In this article, we will discuss disjoint sets in python. We will also discuss different approaches to check for disjoint sets in python.
What are Disjoint Sets?
Two sets are said to be disjoint if they don’t have any common element. If there exists any common element between two given sets, they will not be disjoint sets.
Suppose that we have set A, set B, and set C as shown below.
A = {1, 2, 3, 4, 5, 6, 7, 8}
B = {2, 4, 6, 8, 10, 12}
C = {10, 20, 30, 40, 50}
Here, you can observe that set A and set B have some common elements i.e. 2,4, 6, and 8. Hence, they are not disjoint sets. On the other hand, set A and set C have no common elements. Hence, set A and set C will be called disjoint sets.
How to Check For Disjoint Sets in Python?
To check for disjoint sets, we just have to check if there exists any common element in the given sets. If there are common elements among the two sets, the sets will not be disjoint sets. Otherwise, they will be considered disjoint sets.
To implement this logic, we will declare a variable isDisjoint and initialize it to True assuming that both the sets are disjoint sets. After that, we will traverse one of the input sets using a for loop. While traversing, we will check for each element in the set if it exists in another set or not. If we find any element in the first set that belongs to the second set, we will assign the value False to the isDisjoint variable denoting that the sets are not disjoint sets.
If there are no common elements between the input sets, the isDisjoint variable will remain True after execution of the for loop. Hence, denoting that the sets are disjoint sets.
def checkDisjoint(set1, set2):
isDisjoint = True
for element in set1:
if element in set2:
isDisjoint = False
break
return isDisjoint
A = {1, 2, 3, 4, 5, 6, 7, 8}
B = {2, 4, 6, 8, 10, 12}
C = {10, 20, 30, 40, 50}
print("Set {} is: {}".format("A", A))
print("Set {} is: {}".format("B", B))
print("Set {} is: {}".format("C", C))
print("Set A and B are disjoint:", checkDisjoint(A, B))
print("Set A and C are disjoint:", checkDisjoint(A, C))
print("Set B and C are disjoint:", checkDisjoint(B, C))
Output:
Set A is: {1, 2, 3, 4, 5, 6, 7, 8}
Set B is: {2, 4, 6, 8, 10, 12}
Set C is: {40, 10, 50, 20, 30}
Set A and B are disjoint: False
Set A and C are disjoint: True
Set B and C are disjoint: False
Suggested Reading: Chat Application in Python
Check For Disjoint Sets Using The isdisjoint() Method
Instead of the approach discussed above, we can use the isdisjoint() method to check for disjoint sets in python. The isdisjoint() method, when invoked on a set, takes another set as an input argument. After execution,it returns True if the sets are disjoint sets. Otherwise, it returns False. You can observe this in the following example.
A = {1, 2, 3, 4, 5, 6, 7, 8}
B = {2, 4, 6, 8, 10, 12}
C = {10, 20, 30, 40, 50}
print("Set {} is: {}".format("A", A))
print("Set {} is: {}".format("B", B))
print("Set {} is: {}".format("C", C))
print("Set A and B are disjoint:", A.isdisjoint(B))
print("Set A and C are disjoint:", A.isdisjoint(C))
print("Set B and C are disjoint:", B.isdisjoint(C))
Output:
Set A is: {1, 2, 3, 4, 5, 6, 7, 8}
Set B is: {2, 4, 6, 8, 10, 12}
Set C is: {40, 10, 50, 20, 30}
Set A and B are disjoint: False
Set A and C are disjoint: True
Set B and C are disjoint: False
Conclusion
In this article, we have discussed two ways to check for disjoint sets in python. To learn more about sets, you can read this article on set comprehension in python. You might also like this article on list comprehension in python.
The post Check For Disjoint Sets in Python appeared first on PythonForBeginners.com.
 Python Music Player
Python Music Player
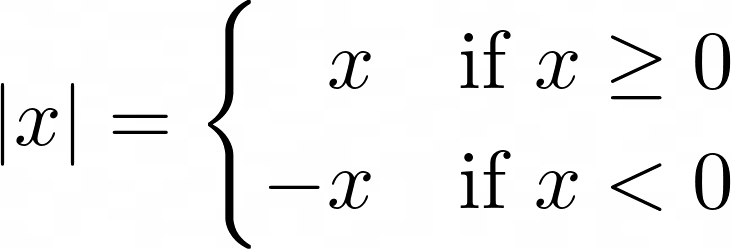 Absolute Value Defined as a Piecewise Function
Absolute Value Defined as a Piecewise Function
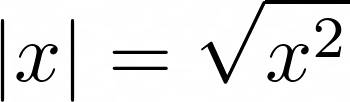 Absolute Value Defined Algebraically
Absolute Value Defined Algebraically
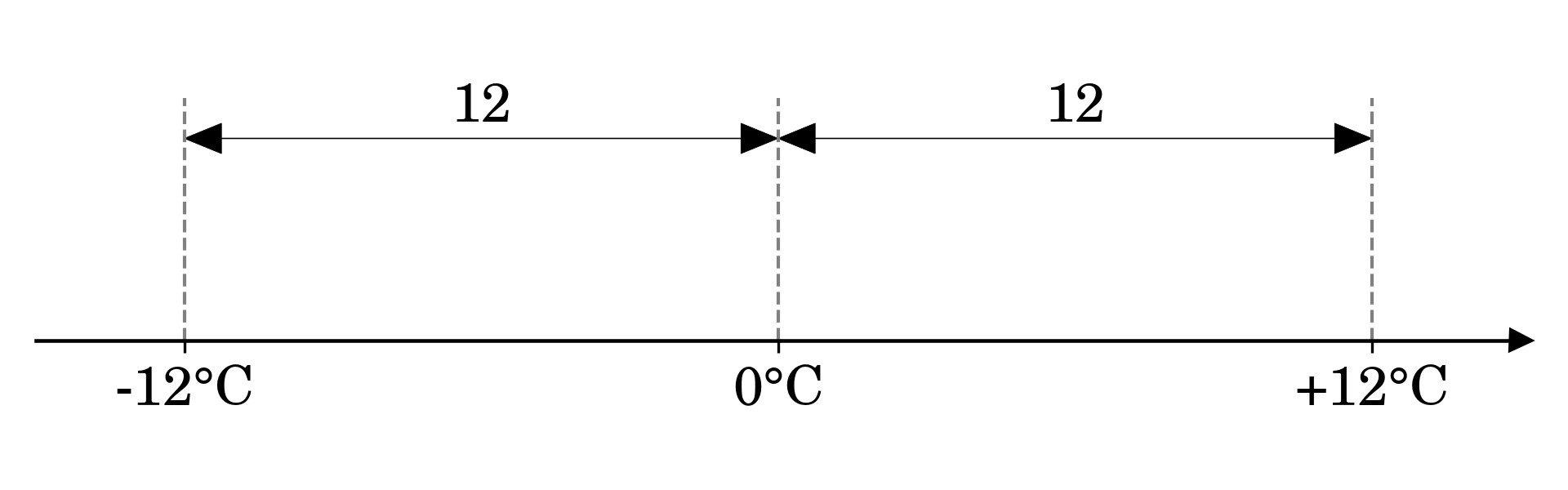
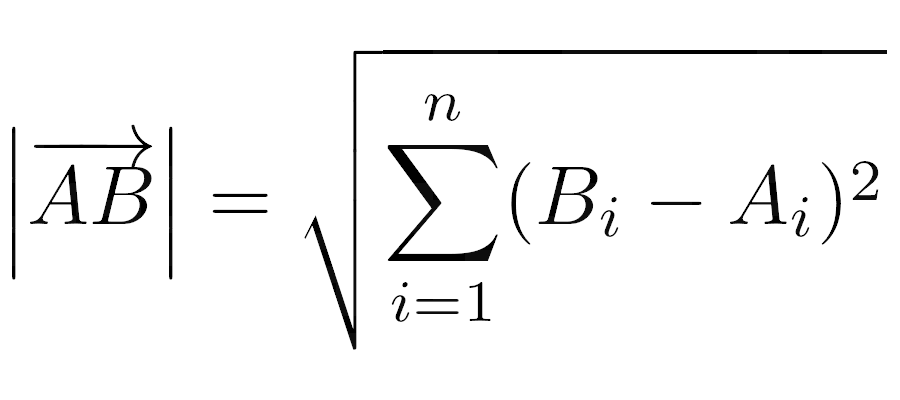 The Length of a Bound Vector as a Euclidean Norm
The Length of a Bound Vector as a Euclidean Norm





![Midge Ure – A Man of Two Worlds (2026) [Official Digital Download 24bit/96kHz]](http://imghd.xyz/images/2026/05/09/zvc67e2mth34l_600.jpg)


