↧
Python Bytes: #159 Brian's PR is merged, the src will flow
↧
Codementor: Developer Tools & Frameworks for a Python Developer - Reading Time: 3 Mins
A list of developer tools & framework that is useful for any aspiring Python developer.
↧
↧
Philip Semanchuk: Mailing lists for my Python IPC packages
My package sysv_ipc celebrates its 11th birthday tomorrow, so I thought I would give it a mailing list as a gift. I didn’t want its sibling posix_ipc to get jealous, so I created one for that too.
You can read/join the sysv_ipc group here: https://groups.io/g/python-sysv-ipc
You can read/join the posix_ipc group here: https://groups.io/g/python-posix-ipc
↧
Janusworx: #100DaysOfCode, Day 014 – Classes, List Comprehensions and Generators
Did a video session again today, since I came back late from the doc.
Watched videos about building a small d&d game, using classes.
This was fun :)
Working on the challenge will be exciting.
And then some more on list comprehensions and generators.
I had one aha, about tools as I watched this.
The instructor used a regular expression to process a list and that little line, cut down his code by lots.
That made me realise that programming is simply picking up the right tool for the job, and that there are a plethora, to do the work you need to do. One is not necessarily better than the other, just that some are better suited to the job at hand, than others.
Revised how list comprehensions and generators work.
And like a dork, I just realised that the operative thing is comprehension. You write in a comprehensive way to build some sort of collection. A list comprehension to write lists, a dictionary comprehension to build a dictionary, a generator comprehension to … well, you get the idea :)
This is all I got for today.
Will work more tomorrow.
↧
Robin Wilson: Automatically downloading nursery photos from ParentZone using Selenium
My son goes to a nursery part-time, and the nursery uses a system called ParentZone from Connect Childcare to send information between us (his parents) and nursery. Primarily, this is used to send us updates on the boring details of the day (what he’s had to eat, nappy changes and so on), and to send ‘observations’ which include photographs of what he’s been doing at nursery. The interfaces include a web app (pictured below) and a mobile app:

I wanted to be able to download all of these photos easily to keep them in my (enormous) set of photos of my son, without manually downloading each one. So, I wrote a script to do this, with the help of Selenium.
If you want to jump straight to the script, then have a look at the ParentZonePhotoDownloader Github repository. The script is documented and has a nice command-line interface. For more details on how I created it, read on…
Selenium is a browser automation tool that allows you to control pretty-much everything a browser does through code, while also accessing the underlying HTML that the browser is displaying. This makes it the perfect choice for scraping websites that have a lot of Javascript – like the ParentZone website.
To get Selenium working you need to install a ‘webdriver’ that will connect to a particular web browser and do the actual controlling of the browser. I’ve chosen to use chromedriver to control Google Chrome. See the Getting Started guide to see how to install chromedriver – but it’s basically as simple as downloading a binary file and putting it in your PATH.
My script starts off fairly simply, by creating an instance of the Chrome webdriver, and navigating to the ParentZone homepage:
driver = webdriver.Chrome()
driver.get("https://www.parentzone.me/")The next line: driver.implicitly_wait(10) tells Selenium to wait up to 10 seconds for elements to appear before giving up and giving an error. This is useful for sites that might be slightly slow to load (eg. those with large pictures).
We then fill in the email address and password in the login form:
email_field = driver.find_element_by_xpath('//*[@id="login"]/fieldset/div[1]/input')
email_field.clear()
email_field.send_keys(email)Here we’re selecting the email address field using it’s XPath, which is a sort of query language for selecting nodes from an XML document (or, by extension, an HTML document – as HTML is a form of XML). I have some basic knowledge of XPath, but usually I just copy the expressions I need from the Chrome Dev Tools window. To do this, select the right element in Dev Tools, then right click on the element’s HTML code and choose ‘Copy->Copy XPath’:
We then clear the field, and fake the typing of the email string that we took as a command-line argument.
We then repeat the same thing for the password field, and then just send the ‘Enter’ key to submit the field (easier than finding the right submit button and fake-clicking it).
Once we’ve logged in and gone to the correct page (the ‘timeline’ page) we want to narrow down the page to just show ‘Observations’ (as these are usually the only posts that have photographs). We do this by selecting a dropdown, and then choosing an option from the dropdown box:
dropdown = Select(driver.find_element_by_xpath('//*[@id="filter"]/div[2]/div[4]/div/div[1]/select'))
dropdown.select_by_value('7')I found the right value (7) to set this to by reading the HTML code where the options were defined, which included this line: <option value="7">Observation</option>.
We then click the ‘Submit’ button:
submit_button = driver.find_element_by_id('submit-filter')
submit_button.click()Now we get to the bit that had me stuck for a while… The page has ‘infinite scrolling’ – that is, as you scroll down, more posts ‘magically’ appear. We need to scroll right down to the bottom so that we have all of the observations before we try to download them.
I tried using various complicated Javascript functions, but none of them seemed to work – so I settled on a naive way to do it. I simply send the ‘End’ key (which scrolls to the end of the page), wait a few seconds, and then count the number of photos on the page (in this case, elements with the class img-responsive, which is used for photos from observations). When this number stops increasing, I know I’ve reached the point where there are no more pictures to load.
The code that does this is fairly easy to understand:
html = driver.find_element_by_tag_name('html')
old_n_photos = 0
while True:
# Scroll
html.send_keys(Keys.END)
time.sleep(3)
# Get all photos
media_elements = driver.find_elements_by_class_name('img-responsive')
n_photos = len(media_elements)
if n_photos > old_n_photos:
old_n_photos = n_photos
else:
breakWe’ve now got a page with all the photos on it, so we just need to extract them. In fact, we’ve already got a list of all of these photo elements in media_elements, so we just iterate through this and grab some details for each image. Specifically, we get the image URL with element.get_attribute('src'), and then extract the unique image ID from that URL. We then choose the filename to save the file as based on the type of element that was used to display it on the web page (the element.tag_name). If it was a <img> tag then it’s an image, if it was a <video> tag then it was a video.
We then download the image/video file from the website using the requests library (that is, not through Selenium, but separately, just using the URL obtained through Selenium):
# For each image that we've found
for element in media_elements:
image_url = element.get_attribute('src')
image_id = image_url.split("&d=")[-1]
# Deal with file extension based on tag used to display the media
if element.tag_name == 'img':
extension = 'jpg'
elif element.tag_name == 'video':
extension = 'mp4'
image_output_path = os.path.join(output_folder,
f'{image_id}.{extension}')
# Only download and save the file if it doesn't already exist
if not os.path.exists(image_output_path):
r = requests.get(image_url, allow_redirects=True)
open(image_output_path, 'wb').write(r.content)Putting this all together into a command-line script was made much easier by the click library. Adding the following decorators to the top of the main function creates a whole command-line interface automatically – even including prompts to specify parameters that weren’t specified on the command-line:
@click.command()
@click.option('--email', help='Email address used to log in to ParentZone',
prompt='Email address used to log in to ParentZone')
@click.option('--password', help='Password used to log in to ParentZone',
prompt='Password used to log in to ParentZone')
@click.option('--output_folder', help='Output folder',
default='./output')So, that’s it. Less than 100 lines in total for a very useful script that saves me a lot of tedious downloading. The full script is available on Github
↧
↧
Zato Blog: Auto-generating API specifications as OpenAPI, WSDL and Sphinx
This article presents a workflow for auto-generation of API specifications for your Zato services - if you need to share your APIs with partners, external or internal, this is how it can be done.
Sample services
Let's consider the services below - they represent a subset of a hypothetical API of a telecommunication company. In this case, they are to do with pre-paid cards. Deploy them on your servers in a module called api.py.
Note that their implementation is omitted, we only deal with their I/O, as it is expressed using SimpleIO.
What we would like to have, and what we will achieve here, is a website with static HTML describing the services in terms of a formal API specification.
# -*- coding: utf-8 -*-# Zatofromzato.server.serviceimportInt,Service# #####################################################################classRechargeCard(Service):""" Recharges a pre-paid card. Amount must not be less than 1 and it cannot be greater than 10000."""classSimpleIO:input_required='number',Int('amount')output_required=Int('status')defhandle(self):pass# #####################################################################classGetCurrentBalance(Service):""" Returns current balance of a pre-paid card."""classSimpleIO:input_required=Int('number')output_required=Int('status')output_optional='balance'defhandle(self):pass# #####################################################################Docstrings and SimpleIO
In the sample services, observe that:
Documentation is added as docstrings - this is something that services, being simply Python classes, will have anyway
One of the services has a multi-line docstring whereas the other one's is single-line, this will be of significance later on
SimpleIO definitions use both string types and integers
Command line usage
To generate API specifications, command zato apispec is used. This is part of the CLI that Zato ships with.
Typically, only well-chosen services should be documented publicly, and the main two options the command has are --include and --exclude.
Both accept a comma-separated list of shell-like glob patterns that indicate which services should or should not be documented.
For instance, if the code above is saved in api.py, the command to output their API specification is:
zato apispec /path/to/server \
--dir /path/to/output/directory \
--include api.*
Next, we can navigate to the directory just created and type the command below to build HTML.
cd /path/to/output/directory
make html
OpenAPI, WSDL and Sphinx
The result of the commands is as below - OpenAPI and WSDL files are in the menu column to the left.
Also, note that in the main index only the very first line of a docstring is used but upon opening a sub-page for each service its full docstring is used.


Branding and customisation
While the result is self-contained and it can be already used as-is, there is still room for more.
Given that the output is generated using Sphinx, it is possible to customise it as needed, for instance, by applying custom CSS or other branding information, such as the logo of a company exposing a given API.
All of the files used for generation of HTML are stored in config directories of each server - if the path to a server is /path/to/server then the full path to Sphinx templates is in /path/to/server/config/repo/static/sphinxdoc/apispec.
Summary
That is everything - generating static documentation is a matter of just a single command. The output can be fully customised while the resulting OpenAPI and WSDL artifacts can be given to partners to let third-parties automatically generate API clients for your Zato services.
↧
Stack Abuse: Tensorflow 2.0: Solving Classification and Regression Problems
After much hype, Google finally released TensorFlow 2.0 which is the latest version of Google's flagship deep learning platform. A lot of long-awaited features have been introduced in TensorFlow 2.0. This article very briefly covers how you can develop simple classification and regression models using TensorFlow 2.0.
Classification with Tensorflow 2.0
If you have ever worked with Keras library, you are in for a treat. TensorFlow 2.0 now uses Keras API as its default library for training classification and regression models. Before TensorFlow 2.0, one of the major criticisms that the earlier versions of TensorFlow had to face stemmed from the complexity of model creation. Previously you need to stitch graphs, sessions and placeholders together in order to create even a simple logistic regression model. With TensorFlow 2.0, creating classification and regression models have become a piece of cake.
So without further ado, let's develop a classification model with TensorFlow.
The Dataset
The dataset for the classification example can be downloaded freely from this link. Download the file in CSV format. If you open the downloaded CSV file, you will see that the file doesn't contain any headers. The detail of the columns is available at UCI machine learning repository. I will recommend that you read the dataset information in detail from the download link. I will briefly summarize the dataset in this section.
The dataset basically consists of 7 columns:
- price (the buying price of the car)
- maint ( the maintenance cost)
- doors (number of doors)
- persons (the seating capacity)
- lug_capacity (the luggage capacity)
- safety (how safe is the car)
- output (the condition of the car)
Given the first 6 columns, the task is to predict the value for the 7th column i.e. the output. The output column can have one of the three values i.e. "unacc" (unacceptable), "acc" (acceptable), good, and very good.
Importing Libraries
Before we import the dataset into our application, we need to import the required libraries.
import pandas as pd
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style="darkgrid")
Before we proceed, I want you to make sure that you have the latest version of TensorFlow i.e. TensorFlow 2.0. You can check your TensorFlow version with the following command:
print(tf.__version__)
If you do not have TensorFlow 2.0 installed, you can upgrade to the latest version via the following command:
$ pip install --upgrade tensorflow
Importing the Dataset
The following script imports the dataset. Change the path to your CSV data file according.
cols = ['price', 'maint', 'doors', 'persons', 'lug_capacity', 'safety','output']
cars = pd.read_csv(r'/content/drive/My Drive/datasets/car_dataset.csv', names=cols, header=None)
Since the CSV file doesn't contain column headers by default, we passed a list of column headers to the pd.read_csv() method.
Let's now see the first 5 rows of the dataset via the head() method.
cars.head()
Output:

You can see the 7 columns in the dataset.
Data Analysis and Preprocessing
Let's briefly analyze the dataset by plotting a pie chart that shows the distribution of the output. The following script increases the default plot size.
plot_size = plt.rcParams["figure.figsize"]
plot_size [0] = 8
plot_size [1] = 6
plt.rcParams["figure.figsize"] = plot_size
And the following script plots the pie chart showing the output distribution.
cars.output.value_counts().plot(kind='pie', autopct='%0.05f%%', colors=['lightblue', 'lightgreen', 'orange', 'pink'], explode=(0.05, 0.05, 0.05,0.05))
Output:
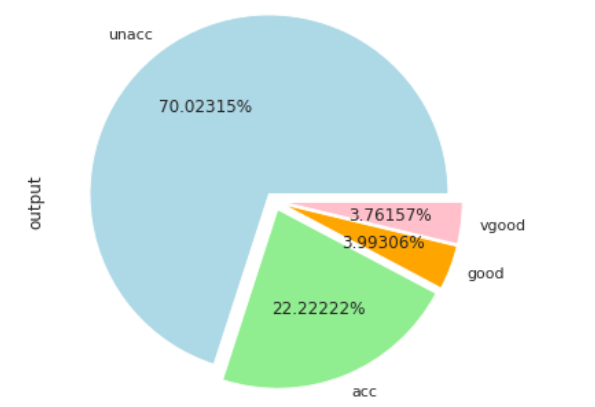
The output shows that majority of cars (70%) are in unacceptable condition while 20% cars are in acceptable conditions. The ratio of cars in good and very good condition is very low.
All the columns in our dataset are categorical. Deep learning is based on statistical algorithms and statistical algorithms work with numbers. Therefore, we need to convert the categorical information into numeric columns. There are various approaches to do that but one of the most common approach is one-hot encoding. In one-hot encoding, for each unique value in the categorical column, a new column is created. For the rows in the actual column where the unique value existed, a 1 is added to the corresponding row of the column created for that particular value. This might sound complex but the following example will make it clear.
The following script converts categorical columns into numeric columns:
price = pd.get_dummies(cars.price, prefix='price')
maint = pd.get_dummies(cars.maint, prefix='maint')
doors = pd.get_dummies(cars.doors, prefix='doors')
persons = pd.get_dummies(cars.persons, prefix='persons')
lug_capacity = pd.get_dummies(cars.lug_capacity, prefix='lug_capacity')
safety = pd.get_dummies(cars.safety, prefix='safety')
labels = pd.get_dummies(cars.output, prefix='condition')
To create our feature set, we can merge the first six columns horizontally:
X = pd.concat([price, maint, doors, persons, lug_capacity, safety] , axis=1)
Let's see how our label column looks now:
labels.head()
Output:
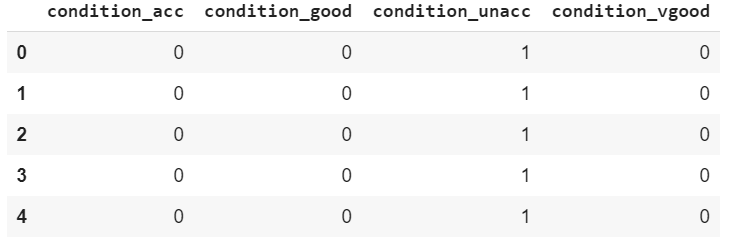
The label column is basically a one-hot encoded version of the output column that we had in our dataset. The output column had four unique values: unacc, acc, good and very good. In the one-hot encoded label dataset, you can see four columns, one for each of the unique values in the output column. You can see 1 in the column for the unique value that originally existed in that row. For instance, in the first five rows of the output column, the column value was unacc. In the labels column, you can see 1 in the first five rows of the condition_unacc column.
Let's now convert our labels into a numpy array since deep learning models in TensorFlow accept numpy array as input.
y = labels.values
The final step before we can train our TensorFlow 2.0 classification model is to divide the dataset into training and test sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
Model Training
To train the model, let's import the TensorFlow 2.0 classes. Execute the following script:
from tensorflow.keras.layers import Input, Dense, Activation,Dropout
from tensorflow.keras.models import Model
As I said earlier, TensorFlow 2.0 uses the Keras API for training the model. In the script above we basically import Input, Dense, Activation, and Dropout classes from tensorflow.keras.layers module. Similarly, we also import the Model class from the tensorflow.keras.models module.
The next step is to create our classification model:
input_layer = Input(shape=(X.shape[1],))
dense_layer_1 = Dense(15, activation='relu')(input_layer)
dense_layer_2 = Dense(10, activation='relu')(dense_layer_1)
output = Dense(y.shape[1], activation='softmax')(dense_layer_2)
model = Model(inputs=input_layer, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
As can be seen from the script, the model contains three dense layers. The first two dense layers contain 15 and 10 nodes, respectively with relu activation function. The final dense layer contain 4 nodes (y.shape[1] == 4) and softmax activation function since this is a classification task. The model is trained using categorical_crossentropy loss function and adam optimizer. The evaluation metric is accuracy.
The following script shows the model summary:
print(model.summary())
Output:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 21)] 0
_________________________________________________________________
dense (Dense) (None, 15) 330
_________________________________________________________________
dense_1 (Dense) (None, 10) 160
_________________________________________________________________
dense_2 (Dense) (None, 4) 44
=================================================================
Total params: 534
Trainable params: 534
Non-trainable params: 0
_________________________________________________________________
None
Finally, to train the model execute the following script:
history = model.fit(X_train, y_train, batch_size=8, epochs=50, verbose=1, validation_split=0.2)
The model will be trained for 50 epochs but here for the sake of space, the result of only last 5 epochs is displayed:
Epoch 45/50
1105/1105 [==============================] - 0s 219us/sample - loss: 0.0114 - acc: 1.0000 - val_loss: 0.0606 - val_acc: 0.9856
Epoch 46/50
1105/1105 [==============================] - 0s 212us/sample - loss: 0.0113 - acc: 1.0000 - val_loss: 0.0497 - val_acc: 0.9856
Epoch 47/50
1105/1105 [==============================] - 0s 219us/sample - loss: 0.0102 - acc: 1.0000 - val_loss: 0.0517 - val_acc: 0.9856
Epoch 48/50
1105/1105 [==============================] - 0s 218us/sample - loss: 0.0091 - acc: 1.0000 - val_loss: 0.0536 - val_acc: 0.9856
Epoch 49/50
1105/1105 [==============================] - 0s 213us/sample - loss: 0.0095 - acc: 1.0000 - val_loss: 0.0513 - val_acc: 0.9819
Epoch 50/50
1105/1105 [==============================] - 0s 209us/sample - loss: 0.0080 - acc: 1.0000 - val_loss: 0.0536 - val_acc: 0.9856
By the end of the 50th epoch, we have training accuracy of 100% while validation accuracy of 98.56%, which is impressive.
Let's finally evaluate the performance of our classification model on the test set:
score = model.evaluate(X_test, y_test, verbose=1)
print("Test Score:", score[0])
print("Test Accuracy:", score[1])
Here is the output:
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
346/346 [==============================] - 0s 55us/sample - loss: 0.0605 - acc: 0.9740
Test Score: 0.06045335989359314
Test Accuracy: 0.9739884
Our model achieves an accuracy of 97.39% on the test set. Though it is slightly less than the training accuracy of 100%, it is still very good given the fact that we randomly chose the number of layers and the nodes. You can add more layers to the model with more nodes and see if you can get better results on the validation and test sets.
Regression with TensorFlow 2.0
In regression problem, the goal is to predict a continuous value. In this section, you will see how to solve a regression problem with TensorFlow 2.0
The Dataset
The dataset for this problem can be downloaded freely from this link. Download the CSV file.
The following script imports the dataset. Do not forget to change the path to your own CSV datafile.
petrol_cons = pd.read_csv(r'/content/drive/My Drive/datasets/petrol_consumption.csv')
Let's print the first five rows of the dataset via the head() function:
petrol_cons.head()
Output:
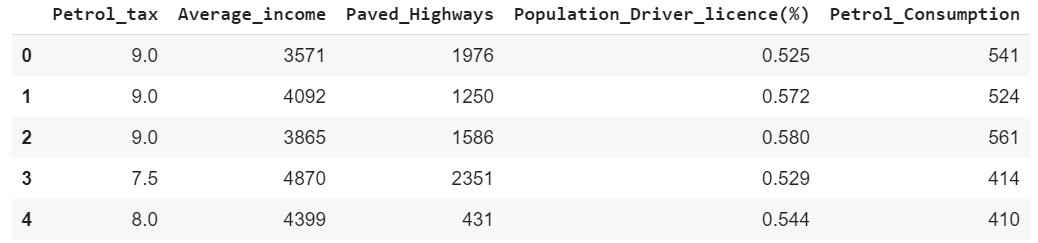
You can see that there are five columns in the dataset. The regression model will be trained on the first four columns, i.e. Petrol_tax, Average_income, Paved_Highways, and Population_Driver_License(%). The value for the last column i.e. Petrol_Consumption will be predicted. As you can see that there is no discrete value for the output column, rather the predicted value can be any continuous value.
Data Preprocessing
In the data preprocessing step we will simply split the data into features and labels, followed by dividing the data into test and training sets. Finally the data will be normalized. For regression problems in general, and for regression problems with deep learning, it is highly recommended that you normalize your dataset. Finally, since all the columns are numeric, here we do not need to perform one-hot encoding of the columns.
X = petrol_cons.iloc[:, 0:4].values
y = petrol_cons.iloc[:, 4].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
In the above script, in the feature set X, the first four columns of the dataset are included. In the label set y, only the 5th column is included. Next, the data set is divided into training and test size via the train_test_split method of the sklearn.model_selection module. The value for the test_size attribute is 0.2 which means that the test set will contain 20% of the original data and the training set will consist of the remaining 80% of the original dataset. Finally, the StandardScaler class from the sklearn.preprocessing module is used to scale the dataset.
Model Training
The next step is to train our model. This is process is quite similar to training the classification. The only change will be in the loss function and the number of nodes in the output dense layer. Since now we are predicting a single continuous value, the output layer will only have 1 node.
input_layer = Input(shape=(X.shape[1],))
dense_layer_1 = Dense(100, activation='relu')(input_layer)
dense_layer_2 = Dense(50, activation='relu')(dense_layer_1)
dense_layer_3 = Dense(25, activation='relu')(dense_layer_2)
output = Dense(1)(dense_layer_3)
model = Model(inputs=input_layer, outputs=output)
model.compile(loss="mean_squared_error" , optimizer="adam", metrics=["mean_squared_error"])
Our model consists of four dense layers with 100, 50, 25, and 1 node, respectively. For regression problems, one of the most commonly used loss functions is mean_squared_error. The following script prints the summary of the model:
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 4)] 0
_________________________________________________________________
dense_10 (Dense) (None, 100) 500
_________________________________________________________________
dense_11 (Dense) (None, 50) 5050
_________________________________________________________________
dense_12 (Dense) (None, 25) 1275
_________________________________________________________________
dense_13 (Dense) (None, 1) 26
=================================================================
Total params: 6,851
Trainable params: 6,851
Non-trainable params: 0
Finally, we can train the model with the following script:
history = model.fit(X_train, y_train, batch_size=2, epochs=100, verbose=1, validation_split=0.2)
Here is the result from the last 5 training epochs:
Epoch 96/100
30/30 [==============================] - 0s 2ms/sample - loss: 510.3316 - mean_squared_error: 510.3317 - val_loss: 10383.5234 - val_mean_squared_error: 10383.5234
Epoch 97/100
30/30 [==============================] - 0s 2ms/sample - loss: 523.3454 - mean_squared_error: 523.3453 - val_loss: 10488.3036 - val_mean_squared_error: 10488.3037
Epoch 98/100
30/30 [==============================] - 0s 2ms/sample - loss: 514.8281 - mean_squared_error: 514.8281 - val_loss: 10379.5087 - val_mean_squared_error: 10379.5088
Epoch 99/100
30/30 [==============================] - 0s 2ms/sample - loss: 504.0919 - mean_squared_error: 504.0919 - val_loss: 10301.3304 - val_mean_squared_error: 10301.3311
Epoch 100/100
30/30 [==============================] - 0s 2ms/sample - loss: 532.7809 - mean_squared_error: 532.7809 - val_loss: 10325.1699 - val_mean_squared_error: 10325.1709
To evaluate the performance of a regression model on test set, one of the most commonly used metrics is root mean squared error. We can find mean squared error between the predicted and actual values via the mean_squared_error class of the sklearn.metrics module. We can then take square root of the resultant mean squared error. Look at the following script:
from sklearn.metrics import mean_squared_error
from math import sqrt
pred_train = model.predict(X_train)
print(np.sqrt(mean_squared_error(y_train,pred_train)))
pred = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test,pred)))
The output shows the mean squared error for both the training and test sets. The results show that model performance is better on the training set since the root mean squared error value for training set is less. Our model is overfitting. The reason is obvious, we only had 48 records in the dataset. Try to train regression models with a larger dataset to get better results.
50.43599665058207
84.31961060849562
Conclusion
TensorFlow 2.0 is the latest version of Google's TensorFlow library for deep learning. This article briefly covers how to create classification and regression models with TensorFlow 2.0. To have a hands on experience, I would suggest that you practice the examples given in this article and try to create simple regression and classification models with TensorFlow 2.0 using some other datasets.
↧
Real Python: Beautiful Soup: Build a Web Scraper With Python
The incredible amount of data on the Internet is a rich resource for any field of research or personal interest. To effectively harvest that data, you’ll need to become skilled at web scraping. The Python libraries requests and Beautiful Soup are powerful tools for the job. If you like to learn with hands-on examples and you have a basic understanding of Python and HTML, then this tutorial is for you.
In this tutorial, you’ll learn how to:
- Use
requestsand Beautiful Soup for scraping and parsing data from the Web - Walk through a web scraping pipeline from start to finish
- Build a script that fetches job offers from the Web and displays relevant information in your console
This is a powerful project because you’ll be able to apply the same process and the same tools to any static website out there on the World Wide Web. You can download the source code for the project and all examples in this tutorial by clicking on the link below:
Get Sample Code:Click here get the sample code you'll use for the project and examples in this tutorial.
Let’s get started!
What Is Web Scraping?
Web scraping is the process of gathering information from the Internet. Even copy-pasting the lyrics of your favorite song is a form of web scraping! However, the words “web scraping” usually refer to a process that involves automation. Some websites don’t like it when automatic scrapers gather their data, while others don’t mind.
If you’re scraping a page respectfully for educational purposes, then you’re unlikely to have any problems. Still, it’s a good idea to do some research on your own and make sure that you’re not violating any Terms of Service before you start a large-scale project. To learn more about the legal aspects of web scraping, check out Legal Perspectives on Scraping Data From The Modern Web.
Why Scrape the Web?
Say you’re a surfer (both online and in real life) and you’re looking for employment. However, you’re not looking for just any job. With a surfer’s mindset, you’re waiting for the perfect opportunity to roll your way!
There’s a job site that you like that offers exactly the kinds of jobs you’re looking for. Unfortunately, a new position only pops up once in a blue moon. You think about checking up on it every day, but that doesn’t sound like the most fun and productive way to spend your time.
Thankfully, the world offers other ways to apply that surfer’s mindset! Instead of looking at the job site every day, you can use Python to help automate the repetitive parts of your job search. Automated web scraping can be a solution to speed up the data collection process. You write your code once and it will get the information you want many times and from many pages.
In contrast, when you try to get the information you want manually, you might spend a lot of time clicking, scrolling, and searching. This is especially true if you need large amounts of data from websites that are regularly updated with new content. Manual web scraping can take a lot of time and repetition.
There’s so much information on the Web, and new information is constantly added. Something among all that data is likely of interest to you, and much of it is just out there for the taking. Whether you’re actually on the job hunt, gathering data to support your grassroots organization, or are finally looking to get all the lyrics from your favorite artist downloaded to your computer, automated web scraping can help you accomplish your goals.
Challenges of Web Scraping
The Web has grown organically out of many sources. It combines a ton of different technologies, styles, and personalities, and it continues to grow to this day. In other words, the Web is kind of a hot mess! This can lead to a few challenges you’ll see when you try web scraping.
One challenge is variety. Every website is different. While you’ll encounter general structures that tend to repeat themselves, each website is unique and will need its own personal treatment if you want to extract the information that’s relevant to you.
Another challenge is durability. Websites constantly change. Say you’ve built a shiny new web scraper that automatically cherry-picks precisely what you want from your resource of interest. The first time you run your script, it works flawlessly. But when you run the same script only a short while later, you run into a discouraging and lengthy stack of tracebacks!
This is a realistic scenario, as many websites are in active development. Once the site’s structure has changed, your scraper might not be able to navigate the sitemap correctly or find the relevant information. The good news is that many changes to websites are small and incremental, so you’ll likely be able to update your scraper with only minimal adjustments.
However, keep in mind that because the internet is dynamic, the scrapers you’ll build will probably require constant maintenance. You can set up continuous integration to run scraping tests periodically to ensure that your main script doesn’t break without your knowledge.
APIs: An Alternative to Web Scraping
Some website providers offer Application Programming Interfaces (APIs) that allow you to access their data in a predefined manner. With APIs, you can avoid parsing HTML and instead access the data directly using formats like JSON and XML. HTML is primarily a way to visually present content to users.
When you use an API, the process is generally more stable than gathering the data through web scraping. That’s because APIs are made to be consumed by programs, rather than by human eyes. If the design of a website changes, then it doesn’t mean that the structure of the API has changed.
However, APIs can change as well. Both the challenges of variety and durability apply to APIs just as they do to websites. Additionally, it’s much harder to inspect the structure of an API by yourself if the provided documentation is lacking in quality.
The approach and tools you need to gather information using APIs are outside the scope of this tutorial. To learn more about it, check out API Integration in Python.
Scraping the Monster Job Site
In this tutorial, you’ll build a web scraper that fetches Software Developer job listings from the Monster job aggregator site. Your web scraper will parse the HTML to pick out the relevant pieces of information and filter that content for specific words.
You can scrape any site on the Internet that you can look at, but the difficulty of doing so depends on the site. This tutorial offers you an introduction to web scraping to help you understand the overall process. Then, you can apply this same process for every website you’ll want to scrape.
Part 1: Inspect Your Data Source
The first step is to head over to the site you want to scrape using your favorite browser. You’ll need to understand the site structure to extract the information you’re interested in.
Explore the Website
Click through the site and interact with it just like any normal user would. For example, you could search for Software Developer jobs in Australia using the site’s native search interface:
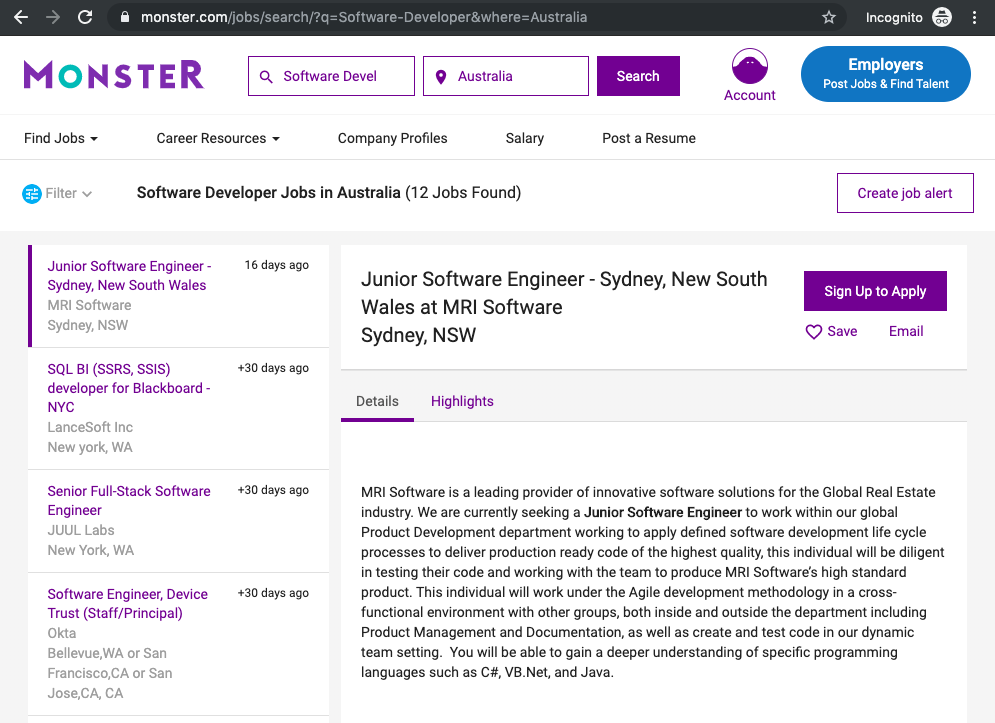
You can see that there’s a list of jobs returned on the left side, and there are more detailed descriptions about the selected job on the right side. When you click on any of the jobs on the left, the content on the right changes. You can also see that when you interact with the website, the URL in your browser’s address bar also changes.
Decipher the Information in URLs
A lot of information can be encoded in a URL. Your web scraping journey will be much easier if you first become familiar with how URLs work and what they’re made of. Try to pick apart the URL of the site you’re currently on:
https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia
You can deconstruct the above URL into two main parts:
- The base URL represents the path to the search functionality of the website. In the example above, the base URL is
https://www.monster.com/jobs/search/. - The query parameters represent additional values that can be declared on the page. In the example above, the query parameters are
?q=Software-Developer&where=Australia.
Any job you’ll search for on this website will use the same base URL. However, the query parameters will change depending on what you’re looking for. You can think of them as query strings that get sent to the database to retrieve specific records.
Query parameters generally consist of three things:
- Start: The beginning of the query parameters is denoted by a question mark (
?). - Information: The pieces of information constituting one query parameter are encoded in key-value pairs, where related keys and values are joined together by an equals sign (
key=value). - Separator: Every URL can have multiple query parameters, which are separated from each other by an ampersand (
&).
Equipped with this information, you can pick apart the URL’s query parameters into two key-value pairs:
q=Software-Developerselects the type of job you’re looking for.where=Australiaselects the location you’re looking for.
Try to change the search parameters and observe how that affects your URL. Go ahead and enter new values in the search bar up top:
 Change these values to observe the changes in the URL.
Change these values to observe the changes in the URL.
Next, try to change the values directly in your URL. See what happens when you paste the following URL into your browser’s address bar:
https://www.monster.com/jobs/search/?q=Programmer&where=New-York
You’ll notice that changes in the search box of the site are directly reflected in the URL’s query parameters and vice versa. If you change either of them, then you’ll see different results on the website. When you explore URLs, you can get information on how to retrieve data from the website’s server.
Inspect the Site Using Developer Tools
Next, you’ll want to learn more about how the data is structured for display. You’ll need to understand the page structure to pick what you want from the HTML response that you’ll collect in one of the upcoming steps.
Developer tools can help you understand the structure of a website. All modern browsers come with developer tools installed. In this tutorial, you’ll see how to work with the developer tools in Chrome. The process will be very similar to other modern browsers.
In Chrome, you can open up the developer tools through the menu View → Developer → Developer Tools. You can also access them by right-clicking on the page and selecting the Inspect option, or by using a keyboard shortcut.
Developer tools allow you to interactively explore the site’s DOM to better understand the source that you’re working with. To dig into your page’s DOM, select the Elements tab in developer tools. You’ll see a structure with clickable HTML elements. You can expand, collapse, and even edit elements right in your browser:
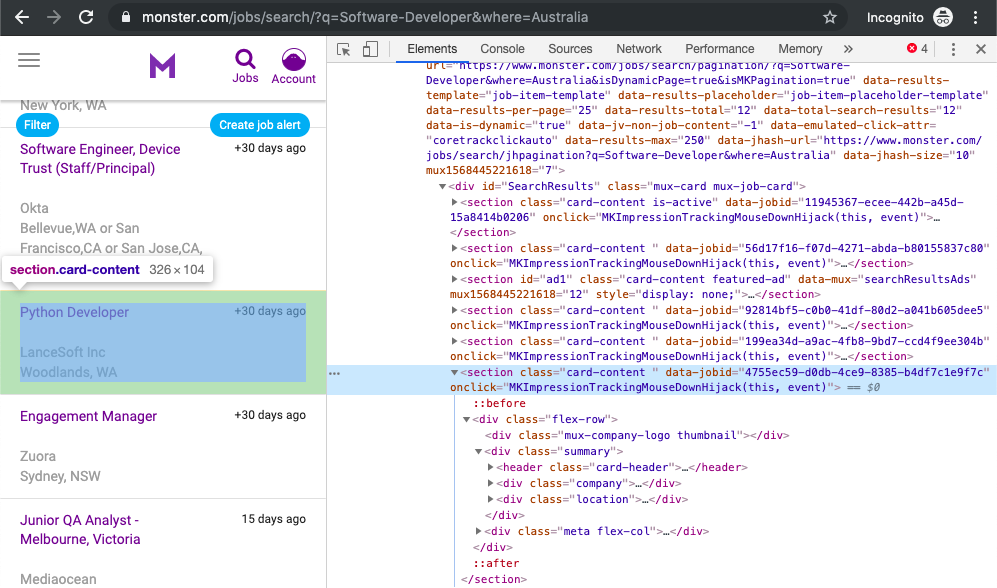 The HTML on the right represents the structure of the page you can see on the left.
The HTML on the right represents the structure of the page you can see on the left.
You can think of the text displayed in your browser as the HTML structure of that page. If you’re interested, then you can read more about the difference between the DOM and HTML on CSS-TRICKS.
When you right-click elements on the page, you can select Inspect to zoom to their location in the DOM. You can also hover over the HTML text on your right and see the corresponding elements light up on the page.
Task: Find a single job posting. What HTML element is it wrapped in, and what other HTML elements does it contain?
Play around and explore! The more you get to know the page you’re working with, the easier it will be to scrape it. However, don’t get too overwhelmed with all that HTML text. You’ll use the power of programming to step through this maze and cherry-pick only the interesting parts with Beautiful Soup.
Part 2: Scrape HTML Content From a Page
Now that you have an idea of what you’re working with, it’s time to get started using Python. First, you’ll want to get the site’s HTML code into your Python script so that you can interact with it. For this task, you’ll use Python’s requests library. Type the following in your terminal to install it:
$ pip3 install requests
Then open up a new file in your favorite text editor. All you need to retrieve the HTML are a few lines of code:
importrequestsURL='https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia'page=requests.get(URL)This code performs an HTTP request to the given URL. It retrieves the HTML data that the server sends back and stores that data in a Python object.
If you take a look at the downloaded content, then you’ll notice that it looks very similar to the HTML you were inspecting earlier with developer tools. To improve the structure of how the HTML is displayed in your console output, you can print the object’s .content attribute with pprint().
Static Websites
The website you’re scraping in this tutorial serves static HTML content. In this scenario, the server that hosts the site sends back HTML documents that already contain all the data you’ll get to see as a user.
When you inspected the page with developer tools earlier on, you discovered that a job posting consists of the following long and messy-looking HTML:
<sectionclass="card-content"data-jobid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c"onclick="MKImpressionTrackingMouseDownHijack(this, event)"><divclass="flex-row"><divclass="mux-company-logo thumbnail"></div><divclass="summary"><headerclass="card-header"><h2class="title"><adata-bypass="true"data-m_impr_a_placement_id="JSR2CW"data-m_impr_j_cid="4"data-m_impr_j_coc=""data-m_impr_j_jawsid="371676273"data-m_impr_j_jobid="0"data-m_impr_j_jpm="2"data-m_impr_j_jpt="3"data-m_impr_j_lat="30.1882"data-m_impr_j_lid="619"data-m_impr_j_long="-95.6732"data-m_impr_j_occid="11838"data-m_impr_j_p="3"data-m_impr_j_postingid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c"data-m_impr_j_pvc="4496dab8-a60c-4f02-a2d1-6213320e7213"data-m_impr_s_t="t"data-m_impr_uuid="0b620778-73c7-4550-9db5-df4efad23538"href="https://job-openings.monster.com/python-developer-woodlands-wa-us-lancesoft-inc/4755ec59-d0db-4ce9-8385-b4df7c1e9f7c"onclick="clickJobTitle('plid=619&pcid=4&poccid=11838','Software Developer',''); clickJobTitleSiteCat('{"events.event48":"true","eVar25":"Python Developer","eVar66":"Monster","eVar67":"JSR2CW","eVar26":"_LanceSoft Inc","eVar31":"Woodlands_WA_","prop24":"2019-07-02T12:00","eVar53":"1500127001001","eVar50":"Aggregated","eVar74":"regular"}')">Python Developer
</a></h2></header><divclass="company"><spanclass="name">LanceSoft Inc</span><ulclass="list-inline"></ul></div><divclass="location"><spanclass="name">
Woodlands, WA
</span></div></div><divclass="meta flex-col"><timedatetime="2017-05-26T12:00">2 days ago</time><spanclass="mux-tooltip applied-only"data-mux="tooltip"title="Applied"><iaria-hidden="true"class="icon icon-applied"></i><spanclass="sr-only">Applied</span></span><spanclass="mux-tooltip saved-only"data-mux="tooltip"title="Saved"><iaria-hidden="true"class="icon icon-saved"></i><spanclass="sr-only">Saved</span></span></div></div></section>It can be difficult to wrap your head around such a long block of HTML code. To make it easier to read, you can use an HTML formatter to automatically clean it up a little more. Good readability helps you better understand the structure of any code block. While it may or may not help to improve the formatting of the HTML, it’s always worth a try.
Note: Keep in mind that every website will look different. That’s why it’s necessary to inspect and understand the structure of the site you’re currently working with before moving forward.
The HTML above definitely has a few confusing parts in it. For example, you can scroll to the right to see the large number of attributes that the <a> element has. Luckily, the class names on the elements that you’re interested in are relatively straightforward:
class="title": the title of the job postingclass="company": the company that offers the positionclass="location": the location where you’d be working
In case you ever get lost in a large pile of HTML, remember that you can always go back to your browser and use developer tools to further explore the HTML structure interactively.
By now, you’ve successfully harnessed the power and user-friendly design of Python’s requests library. With only a few lines of code, you managed to scrape the static HTML content from the web and make it available for further processing.
However, there are a few more challenging situations you might encounter when you’re scraping websites. Before you begin using Beautiful Soup to pick the relevant information from the HTML that you just scraped, take a quick look at two of these situations.
Hidden Websites
Some pages contain information that’s hidden behind a login. That means you’ll need an account to be able to see (and scrape) anything from the page. The process to make an HTTP request from your Python script is different than how you access a page from your browser. That means that just because you can log in to the page through your browser, that doesn’t mean you’ll be able to scrape it with your Python script.
However, there are some advanced techniques that you can use with the requests to access the content behind logins. These techniques will allow you to log in to websites while making the HTTP request from within your script.
Dynamic Websites
Static sites are easier to work with because the server sends you an HTML page that already contains all the information as a response. You can parse an HTML response with Beautiful Soup and begin to pick out the relevant data.
On the other hand, with a dynamic website the server might not send back any HTML at all. Instead, you’ll receive JavaScript code as a response. This will look completely different from what you saw when you inspected the page with your browser’s developer tools.
Note: To offload work from the server to the clients’ machines, many modern websites avoid crunching numbers on their servers whenever possible. Instead, they’ll send JavaScript code that your browser will execute locally to produce the desired HTML.
As mentioned before, what happens in the browser is not related to what happens in your script. Your browser will diligently execute the JavaScript code it receives back from a server and create the DOM and HTML for you locally. However, doing a request to a dynamic website in your Python script will not provide you with the HTML page content.
When you use requests, you’ll only receive what the server sends back. In the case of a dynamic website, you’ll end up with some JavaScript code, which you won’t be able to parse using Beautiful Soup. The only way to go from the JavaScript code to the content you’re interested in is to execute the code, just like your browser does. The requests library can’t do that for you, but there are other solutions that can.
For example, requests-html is a project created by the author of the requests library that allows you to easily render JavaScript using syntax that’s similar to the syntax in requests. It also includes capabilities for parsing the data by using Beautiful Soup under the hood.
Note: Another popular choice for scraping dynamic content is Selenium. You can think of Selenium as a slimmed-down browser that executes the JavaScript code for you before passing on the rendered HTML response to your script.
You won’t go deeper into scraping dynamically-generated content in this tutorial. For now, it’s enough for you to remember that you’ll need to look into the above-mentioned options if the page you’re interested in is generated in your browser dynamically.
Part 3: Parse HTML Code With Beautiful Soup
You’ve successfully scraped some HTML from the Internet, but when you look at it now, it just seems like a huge mess. There are tons of HTML elements here and there, thousands of attributes scattered around—and wasn’t there some JavaScript mixed in as well? It’s time to parse this lengthy code response with Beautiful Soup to make it more accessible and pick out the data that you’re interested in.
Beautiful Soup is a Python library for parsing structured data. It allows you to interact with HTML in a similar way to how you would interact with a web page using developer tools. Beautiful Soup exposes a couple of intuitive functions you can use to explore the HTML you received. To get started, use your terminal to install the Beautiful Soup library:
$ pip3 install beautifulsoup4
Then, import the library and create a Beautiful Soup object:
importrequestsfrombs4importBeautifulSoupURL='https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia'page=requests.get(URL)soup=BeautifulSoup(page.content,'html.parser')When you add the two highlighted lines of code, you’re creating a Beautiful Soup object that takes the HTML content you scraped earlier as its input. When you instantiate the object, you also instruct Beautiful Soup to use the appropriate parser.
Find Elements by ID
In an HTML web page, every element can have an id attribute assigned. As the name already suggests, that id attribute makes the element uniquely identifiable on the page. You can begin to parse your page by selecting a specific element by its ID.
Switch back to developer tools and identify the HTML object that contains all of the job postings. Explore by hovering over parts of the page and using right-click to Inspect.
Note: Keep in mind that it’s helpful to periodically switch back to your browser and interactively explore the page using developer tools. This helps you learn how to find the exact elements you’re looking for.
At the time of this writing, the element you’re looking for is a <div> with an id attribute that has the value "ResultsContainer". It has a couple of other attributes as well, but below is the gist of what you’re looking for:
<divid="ResultsContainer"><!-- all the job listings --></div>Beautiful Soup allows you to find that specific element easily by its ID:
results=soup.find(id='ResultsContainer')For easier viewing, you can .prettify() any Beautiful Soup object when you print it out. If you call this method on the results variable that you just assigned above, then you should see all the HTML contained within the <div>:
print(results.prettify())When you use the element’s ID, you’re able to pick one element out from among the rest of the HTML. This allows you to work with only this specific part of the page’s HTML. It looks like the soup just got a little thinner! However, it’s still quite dense.
Find Elements by HTML Class Name
You’ve seen that every job posting is wrapped in a <section> element with the class card-content. Now you can work with your new Beautiful Soup object called results and select only the job postings. These are, after all, the parts of the HTML that you’re interested in! You can do this in one line of code:
job_elems=results.find_all('section',class_='card-content')Here, you call .find_all() on a Beautiful Soup object, which returns an iterable containing all the HTML for all the job listings displayed on that page.
Take a look at all of them:
forjob_eleminjob_elems:print(job_elem,end='\n'*2)That’s already pretty neat, but there’s still a lot of HTML! You’ve seen earlier that your page has descriptive class names on some elements. Let’s pick out only those:
forjob_eleminjob_elems:# Each job_elem is a new BeautifulSoup object.# You can use the same methods on it as you did before.title_elem=job_elem.find('h2',class_='title')company_elem=job_elem.find('div',class_='company')location_elem=job_elem.find('div',class_='location')print(title_elem)print(company_elem)print(location_elem)print()Great! You’re getting closer and closer to the data you’re actually interested in. Still, there’s a lot going on with all those HTML tags and attributes floating around:
<h2class="title"><adata-bypass="true"data-m_impr_a_placement_id="JSR2CW"data-m_impr_j_cid="4"data-m_impr_j_coc=""data-m_impr_j_jawsid="371676273"data-m_impr_j_jobid="0"data-m_impr_j_jpm="2"data-m_impr_j_jpt="3"data-m_impr_j_lat="30.1882"data-m_impr_j_lid="619"data-m_impr_j_long="-95.6732"data-m_impr_j_occid="11838"data-m_impr_j_p="3"data-m_impr_j_postingid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c"data-m_impr_j_pvc="4496dab8-a60c-4f02-a2d1-6213320e7213"data-m_impr_s_t="t"data-m_impr_uuid="0b620778-73c7-4550-9db5-df4efad23538"href="https://job-openings.monster.com/python-developer-woodlands-wa-us-lancesoft-inc/4755ec59-d0db-4ce9-8385-b4df7c1e9f7c"onclick="clickJobTitle('plid=619&pcid=4&poccid=11838','Software Developer',''); clickJobTitleSiteCat('{"events.event48":"true","eVar25":"Python Developer","eVar66":"Monster","eVar67":"JSR2CW","eVar26":"_LanceSoft Inc","eVar31":"Woodlands_WA_","prop24":"2019-07-02T12:00","eVar53":"1500127001001","eVar50":"Aggregated","eVar74":"regular"}')">Python Developer
</a></h2><divclass="company"><spanclass="name">LanceSoft Inc</span><ulclass="list-inline"></ul></div><divclass="location"><spanclass="name">
Woodlands, WA
</span></div>You’ll see how to narrow down this output in the next section.
Extract Text From HTML Elements
For now, you only want to see the title, company, and location of each job posting. And behold! Beautiful Soup has got you covered. You can add .text to a Beautiful Soup object to return only the text content of the HTML elements that the object contains:
forjob_eleminjob_elems:title_elem=job_elem.find('h2',class_='title')company_elem=job_elem.find('div',class_='company')location_elem=job_elem.find('div',class_='location')print(title_elem.text)print(company_elem.text)print(location_elem.text)print()Run the above code snippet and you’ll see the text content displayed. However, you’ll also get a lot of whitespace. Since you’re now working with Python strings, you can .strip() the superfluous whitespace. You can also apply any other familiar Python string methods to further clean up your text.
Note: The web is messy and you can’t rely on a page structure to be consistent throughout. Therefore, you’ll more often than not run into errors while parsing HTML.
When you run the above code, you might encounter an AttributeError:
AttributeError: 'NoneType' object has no attribute 'text'If that’s the case, then take a step back and inspect your previous results. Were there any items with a value of None? You might have noticed that the structure of the page is not entirely uniform. There could be an advertisement in there that displays in a different way than the normal job postings, which may return different results. For this tutorial, you can safely disregard the problematic element and skip over it while parsing the HTML:
forjob_eleminjob_elems:title_elem=job_elem.find('h2',class_='title')company_elem=job_elem.find('div',class_='company')location_elem=job_elem.find('div',class_='location')ifNonein(title_elem,company_elem,location_elem):continueprint(title_elem.text.strip())print(company_elem.text.strip())print(location_elem.text.strip())print()Feel free to explore why one of the elements is returned as None. You can use the conditional statement you wrote above to print() out and inspect the relevant element in more detail. What do you think is going on there?
After you complete the above steps try running your script again. The results finally look much better:
Python Developer
LanceSoft Inc
Woodlands, WA
Senior Engagement Manager
Zuora
Sydney, NSW
Find Elements by Class Name and Text Content
By now, you’ve cleaned up the list of jobs that you saw on the website. While that’s pretty neat already, you can make your script more useful. However, not all of the job listings seem to be developer jobs that you’d be interested in as a Python developer. So instead of printing out all of the jobs from the page, you’ll first filter them for some keywords.
You know that job titles in the page are kept within <h2> elements. To filter only for
specific ones, you can use the string argument:
python_jobs=results.find_all('h2',string='Python Developer')This code finds all <h2> elements where the contained string matches 'Python Developer' exactly. Note that you’re directly calling the method on your first results variable. If you go ahead and print() the output of the above code snippet to your console, then you might be disappointed because it will probably be empty:
[]There was definitely a job with that title in the search results, so why is it not showing up? When you use string= like you did above, your program looks for exactly that string. Any differences in capitalization or whitespace will prevent the element from matching. In the next section, you’ll find a way to make the string more general.
Pass a Function to a Beautiful Soup Method
In addition to strings, you can often pass functions as arguments to Beautiful Soup methods. You can change the previous line of code to use a function instead:
python_jobs=results.find_all('h2',string=lambdatext:'python'intext.lower())Now you’re passing an anonymous function to the string= argument. The lambda function looks at the text of each <h2> element, converts it to lowercase, and checks whether the substring 'python' is found anywhere in there. Now you’ve got a match:
>>>
>>> print(len(python_jobs))1
Your program has found a match!
Note: In case you still don’t get a match, try adapting your search string. The job offers on this page are constantly changing and there might not be a job listed that includes the substring 'python' in its title at the time that you’re working through this tutorial.
The process of finding specific elements depending on their text content is a powerful way to filter your HTML response for the information that you’re looking for. Beautiful Soup allows you to use either exact strings or functions as arguments for filtering text in Beautiful Soup objects.
Extract Attributes From HTML Elements
At this point, your Python script already scrapes the site and filters its HTML for relevant job postings. Well done! However, one thing that’s still missing is the link to apply for a job.
While you were inspecting the page, you found that the link is part of the element that has the title HTML class. The current code strips away the entire link when accessing the .text attribute of its parent element. As you’ve seen before, .text only contains the visible text content of an HTML element. Tags and attributes are not part of that. To get the actual URL, you want to extract one of those attributes instead of discarding it.
Look at the list of filtered results python_jobs that you created above. The URL is contained in the href attribute of the nested <a> tag. Start by fetching the <a> element. Then, extract the value of its href attribute using square-bracket notation:
python_jobs=results.find_all('h2',string=lambdatext:"python"intext.lower())forp_jobinpython_jobs:link=p_job.find('a')['href']print(p_job.text.strip())print(f"Apply here: {link}\n")The filtered results will only show links to job opportunities that include python in their title. You can use the same square-bracket notation to extract other HTML attributes as well. A common use case is to fetch the URL of a link, as you did above.
Building the Job Search Tool
If you’ve written the code alongside this tutorial, then you can already run your script as-is. To wrap up your journey into web scraping, you could give the code a final makeover and create a command line interface app that looks for Software Developer jobs in any location you define.
You can check out a command line app version of the code you built in this tutorial at the link below:
Get Sample Code:Click here get the sample code you'll use for the project and examples in this tutorial.
If you’re interested in learning how to adapt your script as a command line interface, then check out How to Build Command Line Interfaces in Python With argparse.
Additional Practice
Below is a list of other job boards. These linked pages also return their search results as static HTML responses. To keep practicing your new skills, you can revisit the web scraping process using any or all of the following sites:
Go through this tutorial again from the top using one of these other sites. You’ll see that the structure of each website is different and that you’ll need to re-build the code in a slightly different way to fetch the data you want. This is a great way to practice the concepts that you just learned. While it might make you sweat every so often, your coding skills will be stronger for it!
During your second attempt, you can also explore additional features of Beautiful Soup. Use the documentation as your guidebook and inspiration. Additional practice will help you become more proficient at web scraping using Python, requests, and Beautiful Soup.
Conclusion
Beautiful Soup is packed with useful functionality to parse HTML data. It’s a trusted and helpful companion for your web scraping adventures. Its documentation is comprehensive and relatively user-friendly to get started with. You’ll find that Beautiful Soup will cater to most of your parsing needs, from navigating to advanced searching through the results.
In this tutorial, you’ve learned how to scrape data from the Web using Python, requests, and Beautiful Soup. You built a script that fetches job postings from the Internet and went through the full web scraping process from start to finish.
You learned how to:
- Inspect the HTML structure of your target site with your browser’s developer tools
- Gain insight into how to decipher the data encoded in URLs
- Download the page’s HTML content using Python’s
requestslibrary - Parse the downloaded HTML with Beautiful Soup to extract relevant information
With this general pipeline in mind and powerful libraries in your toolkit, you can go out and see what other websites you can scrape! Have fun, and remember to always be respectful and use your programming skills responsibly.
You can download the source code for the sample script that you built in this tutorial by clicking on the link below:
Get Sample Code:Click here get the sample code you'll use for the project and examples in this tutorial.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
↧
Martijn Faassen: Framework Patterns
A software framework is code that calls your (application) code. That's how we distinguish a framework from a library. Libraries have aspects of frameworks so there is a gray area.
My friend Christian Theune puts it like this: a framework is a text where you fill in the blanks. The framework defines the grammar, you bring some of the words. The words are the code you bring into it.
If you as an developer use a framework, you need to tell it about your code. You need to tell the framework what to call, when. Let's call this configuring the framework.
There are many ways to configure a framework. Each approach has its own trade-offs. I will describe some of these framework configuration patterns here, with brief examples and mention of some of the trade-offs. Many frameworks use more than a single pattern. I don't claim this list is exhaustive -- there are more patterns.
The patterns I describe are generally language agnostic, though some depend on specific language features. Some of these patterns make more sense in object oriented languages. Some are easier to accomplish in one language compared to another. Some languages have rich run-time introspection abilities, and that make certain patterns a lot easier to implement. A language with a powerful macro facility will make other patterns easier to implement.
Where I give example code, I will use Python. I give some abstract code examples, and try to supply a few real-world examples as well. The examples show the framework from the perspective of the application developer.
Pattern: Callback function
The framework lets you pass in a callback function to configure its behavior.
Fictional example
This is a Form class where you can pass in a function that implements what should happen when you save the form.
fromframeworkimportFormdefmy_save(data):...applicationcodetosavethedatasomewhere...my_form=Form(save=my_save)
Real-world example: Python map
A real-world example: map is a (nano)framework that takes a (pure) function:
>>>list(map(lambdax:x*x,[1,2,3]))[1,4,9]
You can go very far with this approach. Functional languages do. If you glance at React in a certain way, it's configured with a whole bunch of callback functions called React components, along with more callback functions called event handlers.
Trade-offs
I am a big fan of this approach as the trade-offs are favorable in many circumstances. In object-oriented language this pattern is sometimes ignored because people feel they need something more complicated like pass in some fancy object or do inheritance, but I think callback functions should in fact be your first consideration.
Functions are simple to understand and implement. The contract is about as simple as it can be for code. Anything you may need to implement your function is passed in as arguments by the framework, which limits how much knowledge you need to use the framework.
Configuration of a callback function can be very dynamic in run-time - you can dynamically assemble or create functions and pass them into the framework, based on some configuration stored in a database, for instance.
Configuration with callback functions doesn't really stand out, which can be a disadvantage -- it's easier to see someone subclasses a base class or implements an interface, and language-integrated methods of configuration can stand out even more.
Sometimes you want to configure multiple related functions at once, in which case an object that implements an interface can make more sense -- I describe that pattern below.
It helps if your language has support for function closures. And of course your language needs to actually support first class functions that you can pass around -- Java for a long time did not.
Pattern: Subclassing
The framework provides a base-class which you as the application developer can subclass. You implement one or more methods that the framework will call.
Fictional example
fromframeworkimportFormBaseclassMyForm(FormBase):defsave(self,data):...applicationcodesavethedatasomewhere...
Real-world example: Django REST Framework
Many frameworks offer base classes - Django offers them, and Django REST Framework even more.
Here's an example from Django REST Framework:
classAccountViewSet(viewsets.ModelViewSet):""" A simple ViewSet for viewing and editing accounts. """queryset=Account.objects.all()serializer_class=AccountSerializerpermission_classes=[IsAccountAdminOrReadOnly]
A ModelViewSet does a lot: it implements a lot of URLs and request methods to interact with them. It automatically glues this Django's ORM so that you can create database objects.
Subclassing questions
When you subclass a class, this is what you might need to know:
- what base classes are there?
- what methods can you override?
- when you override a method, can you call other methods on self (this) or not? Is there is a particular order in which you are allowed to call these methods?
- does the base class provide an implementation of this method, or is it really empty?
- if the base class provides an implementation already, you need to know whether it's intended to be supplemented, or overridden, or both.
- if it's intended to be supplemented, you need to make sure to call this method on the superclass in your implementation.
- if you can override a method entirely, you may need to know what methods to use to to play a part in the framework -- perhaps other methods that can be overridden.
- does the base class inherit from other classes that also let you override methods? when you implement a method, can it interact with other methods on these other classes?
Trade-offs
Many object-oriented languages support inheritance as a language feature. You can make the subclasser implement multiple related methods. It seems obvious to use inheritance as a way to let applications use and configure the framework.
It's not surprising then that this design is very common for frameworks. But I try to avoid it in my own frameworks, and I often am frustrated when a framework forces me to subclass.
The reason for this is that you as the application developer have to start worrying about many of the questions above. If you're lucky they are answered by documentation, though it can still take a bit of effort to understand it. But all too often you have to guess or read the code yourself.
And then even with a well designed base class with plausible overridable methods, it can still be surprisingly hard for you to do what you actually need because the contract of the base class is just not right for your use case.
Languages like Java and TypeScript offer the framework implementer a way to give you guidance (private/protected/public, final). The framework designer can put hard limits on which methods you are allowed to override. This takes away some of these concerns, as with sufficient effort on the part of the framework designer, the language tooling can enforce the contract. Even so such an API can be complex for you to understand and difficult for the framework designer to maintain.
Many languages, such as Python, Ruby and JavaScript, don't have the tools to offer such guidance. You can subclass any base class. You can override any method. The only guidance is documentation. You may feel a bit lost as a result.
A framework tends to evolve over time to let you override more methods in more classes, and thus grows in complexity. This complexity doesn't grow just linearily as methods get added, as you have to worry about their interaction too. A framework that has to deal with a variety of subclasses that override a wide range of methods can expect less from them. Too much flexibility can make it harder for the framework to offer useful features.
Base classes also don't lend themselves very well to run-time dynamism - some languages (like Python) do let you generate a subclass dynamically with custom methods, but that kind of code is difficult to understand.
I think the disadvantages of subclassing outweigh the advantages for a framework's external API. I still sometimes use base classes internally in a library or framework -- base classes are a lightweight way to do reuse there. In this context many of the disadvantages go away: you are in control of the base class contract yourself and you presumably understand it.
I also sometimes use an otherwise empty base class to define an interface, but that's really another pattern which I discuss next.
Pattern: interfaces
The framework provides an interface that you as the application developer can implement. You implement one or more methods that the framework calls.
Fictional example
fromframeworkimportForm,IFormBackendclassMyFormBackend(IFormBackend):defload(self):...applicationcodetoloadthedatahere...defsave(self,data):...applicationcodesavethedatasomewhere...my_form=Form(MyFormBackend())
Real-world example: Python iterable/iterator
The iterable/iterator protocol in Python is an example of an interface. If you implement it, the framework (in this case the Python language) will be able to do all sorts of things with it -- print out its contents, turn it into a list, reverse it, etc.
classRandomIterable:def__iter__(self):returnselfdefnext(self):ifrandom.choice(["go","stop"])=="stop":raiseStopIterationreturn1
Faking interfaces
Many typed languages offer native support for interfaces. But what if your language doesn't do that?
In a dynamically typed language you don't really need to do anything: any object can implement any interface. It's just you don't really get a lot of guidance from the language. What if you want a bit more?
In Python you can use the standard library abc module, or zope.interface. You can also use the typing module and implement base classes and in Python 3.8, PEP-544 protocols.
But let's say you don't have all of that or don't want to bother yet as you're just prototyping. You can use a simple Python base class to describe an interface:
classIFormBackend:defload(self):"Load the data from the backend. Should return a dict with the data."raiseNotImplementedError()defsave(self,data):"Save the data dict to the backend."raiseNotImplementedError()
It doesn't do anything, which is the point - it just describes the methods that the application developer should implement. You could supply one or two with a simple default implementation, but that's it. You may be tempted to implement framework behavior on it, but that brings you into base class land.
Trade-offs
The trade-offs are quite similar to those of callback functions. This is a useful pattern to use if you want to define related functionality in a single bundle.
I go for interfaces if my framework offers a more extensive contract that an application needs to implement, especially if the application needs to maintain its own internal state.
The use of interfaces can lead to clean composition-oriented designs, where you adapt one object into another.
You can use run-time dynamism like with functions where you assemble an object that implements an interface dynamically.
Many languages offer interfaces as a language feature, and any object-oriented language can fake them. Or have too many way to do it, like Python.
Pattern: imperative registration API
You register your code with the framework in a registry object.
When you have a framework that dispatches on a wide range of inputs, and you need to plug in application specific code that handles it, you are going to need some type of registry.
What gets registered can be a callback or an object that implements an interface -- it therefore builds on those patterns.
The application developer needs to call a registration method explicitly.
Frameworks can have specific ways to configure their registries that build on top of this basic pattern -- I will elaborate on that later.
Fictional Example
fromframeworkimportform_save_registrydefsave(data):...applicationcodetosavethedatasomewhere...# we configure what save function to use for the form named 'my_form'form_save_registry.register('my_form',save)
Real-world example: Falcon web framework
A URL router such as in a web framework uses some type of registry. Here is an example from the Falcon web framework:
classQuoteResource:defon_get(self,req,resp):...usercode...api=falcon.API()api.add_route('/quote',QuoteResource())
In this example you can see two patterns go together: QuoteResource implements an (implicit) interface, and you register it with a particular route.
Application code can register handlers for a variety of routes, and the framework then uses the registry to match a request's URL with a route, and then can all into user code to generate a response.
Trade-offs
I use this pattern a lot, as it's easy to implement and good enough for many use cases. It has a minor drawback: you can't easily see that configuration is taking place when you read code. Sometimes I expose a more sophisticated configuration API on top of it: a DSL or language integrated registration or declaration, which I discuss later. But this is foundational.
Calling a method on a registry is the most simple and direct form to register things. It's easy to implement, typically based on a hash map, though you can also use other data structures, such as trees.
The registration order can matter. What happens if you make the same registration twice? Perhaps the registry rejects the second registration. Perhaps it allows it, silently overriding the previous one. There is no general system to handle this, unlike patterns which I describe later.
Registration can be done anywhere in the application which makes it possible to configure the framework dynamically. But this can also lead to complexity and the framework can offer fewer guarantees if its configuration can be updated at any moment.
In a language that supports import-time side effects, you can do your registrations during import time. That makes the declarations stand out more. This is simple to implement, but it's also difficult to control and understand the order of imports. This makes it difficult for the application developer to do overrides. Doing a lot of work during import time in general can lead to hard to predict behavior.
Pattern: convention over configuration
The framework configures itself automatically based on your use of conventions in application code. Configuration is typically driven by particular names, prefixes, and postfixes, but a framework can also inspect other aspects of the code, such as function signatures.
This is typically layered over the procedural registration pattern.
Ruby on Rails made this famous. Rails will automatically configure the database modles, views and controllers by matching up names.
Fictional example
# the framework looks for things prefixed form_save_. It hooks this# up with `myform` which is defined elsewhere in a module named `forms`defform_save_myform(data):...applicationcodetosavethedatasomewhere...
Real-world example: pytest
pytest uses convention over configuration to find tests. It looks for modules and functions prefixed by test_.
pytest also goes further and inspects the arguments to functions to figure out more things.
deftest_ehlo(smtp_connection):response,msg=smtp_connection.ehlo()assertresponse==250assert0# for demo purposes
In this example, pytest knows that test_ehlo is a test, because it is prefixed with test_. It also knows that the argument smtp_connection is a fixture and looks for one in the same module.
Django uses convention over configuration in places, for instance when it looks for the variable urlpatterns in a specially named module to figure out what URL routes an application provides.
Trade-offs
Convention over configuration can be great. It allows the user to type code and have it work without any ceremony. It can enforce useful norms that makes code easier to read -- it makes sense to prefix tests with test_ anyway, as that allows the human reader to recognize them.
I like convention over configuration in moderation, for some use cases. For more complex use cases I prefer other patterns that allow registration with minimal ceremony by using features integrated into the language, such as annotation or decorator syntax.
The more conventions a framework has, the more disadvantages show up. You have to learn the rules, their interactions, and remember them. You may sometimes accidentally invoke them even though you don't want to, just by using the wrong name. You may want to structure your application's code in a way that would be very useful, but doesn't really work with the conventions.
And what if you wanted your registrations to be dynamic, based on database state, for instance? Convention over configuration is a hindrance here, not a help. The developer may need to fall back to a different, imperative registration API, and this may be ill-defined and difficult to use.
It's harder for the framework to implement some patterns -- what if registrations need to be parameterized, for instance? That's easy with functions and objects, but here the framework may need more special naming conventions to let you influence that. That may lead the framework designer to use classes over functions, as in many languages these can have attributes with particular names.
Static type checks are of little use with convention over configuration -- I don't know of a type system that can enforce you implement various methods if you postfix your class with the name View, for instance.
If you have a language with enough run-time introspection capabilities such as Ruby, Python or JavaScript, it's pretty easy to implement convention over configuration. It's a lot harder for languages that don't offer those features, but it may still be possible with sufficient compiler magic. But those same languages are often big on being explicit, and convention over configuration's magic doesn't really fit well with that.
Pattern: metaclass based registration
When you subclass a framework-provided baseclass, it gets registered with the framework.
Some languages such as Python and Ruby offer meta-classes. These let you do two things: change the behavior of classes in fundamental ways, and do side-effects when the class is imported. You can do things during class declaration that you normally only can do during instantiation.
A framework can exploit these side-effects to do some registration.
Fictional example
fromframeworkimportFormBaseclassMyForm(FormBase):defsave(self,data):...applicationcodesavethedatasomewhere...# the framework now knows about MyForm without further action from you
Real-world example: Django
When you declare a Django model by subclassing from its Model base class, Django automatically creates a new relational database table for it.
fromdjango.dbimportmodelsclassPerson(models.Model):first_name=models.CharField(max_length=30)last_name=models.CharField(max_length=30)
Trade-offs
I rarely use these because they are so hard to reason about and because it's so easy to break assumptions for the person who subclasses them.
Meta-classes are notoriously hard to implement. If they're not implemented correctly, they can also lead to surprising behavior that you may need to deal with when you use the framework. Basic assumptions that you may have about the way a class behaves can go out of the door.
Import-time side-effects are difficult to control -- in what order does this happen?
Python has a simpler way to do side-effects for class declarations using decorators.
A base-class driven design for configuration may lead the framework designer towards meta-classes, further complicating the way the framework uses.
Many languages don't support this pattern. It can be seen as a special case of language integrated registration, discussed next.
Pattern: language integrated registration
You configure the application by using framework-provided annotations for code. Registrations happen immediately.
Many programming languages offer some syntax aid for annotating functions, classes and more with metadata. Java has annotations. Rust has attributes. Python has decorators which can be used for this purpose as well.
These annotations can be used as a way to drive configuration in a registry.
Fictional example
fromframeworkimportform_save_registry# we define and configure the function at the same time@form_save_registry.register('my_form')defsave(data):...applicationcodetosavethedatasomewhere...
Real-world example: Flask web framework
A real-world example is the @app.route decorator of the Flask web framework.
fromflaskimportFlaskapp=Flask(__name__)@app.route('/')defhello_world():return'Hello, World!'
Trade-offs
I use this method of configuring software sometimes, but I'm also aware of its limitations -- I tend to go for language integrated declaration, discussed below, which looks identical to the end user but is more predictable.
I'm warier than most about exposing this as an API to application developers, but am happy to use it inside a library or codebase, much like base classes. The ad-hoc nature of import-time side effects make me reach for more sophisticated patterns of configuration when I have to build a solid API.
This pattern is lightweight to implement at least in Python -- it's not much harder than a registry. Your mileage will vary dependent on language. Unlike convention over configuration, configuration is explicit and stands out in code, but the amount of ceremony is kept to a minimum. The configuration information is co-located with the code that is being registered.
Unlike convention over configuration, there is a natural way to parameterize registration with metadata.
In languages like Python this is implemented as a possibly significant import-time side-effect, and may have surprising import order dependencies. In a language like Rust this is done by compiler macro magic -- I think the Rocket web framework is an example, but I'm still trying to understand how it works.
Pattern: DSL-based declaration
You use a DSL (domain specific language) to configure the framework. This DSL offers some way to hook in custom code. The DSL can be an entirely custom language, but you can also leverage JSON, YAML or (shudder) XML.
You can also combine these: I've helped implement a workflow engine that's configured with JSON, and expressions in it are a subset of Python expressions with a custom parser and interpreter.
It is typically layered over some kind of imperative registration system.
Fictional example
{"form":{"name":"my_form","save":"my_module.save"}}
We have a custom language (in this case done with JSON) that lets us configure the way our system works. Here we plug in the save behavior for my_form by referring to the function save in some Python module my_module.
Real-world example: Plone CMS framework
Pyramid and Plone both are descendants of Zope, and you can use ZCML, a XML-derived configuration language with them both.
Here is some ZCML from Plone:
<configurexmlns="http://namespaces.zope.org/zope"xmlns:browser="http://namespaces.zope.org/browser"i18n_domain="my.package"><!-- override folder_contents --><configurepackage="plone.app.content.browser"><browser:pagefor="Products.CMFCore.interfaces._content.IFolderish"class="my.package.browser.foldercontents.MyFolderContentsView"name="folder_contents"template="folder_contents.pt"layer="my.package.interfaces.IMyPackageLayer"permission="cmf.ListFolderContents"/></configure></configure>
This demonstrates a feature offered by a well-designed DSL: a way to do a structured override of behavior in the framework.
Trade-offs
Custom DSLs are a very powerful tool if you actually need them, and you do need them at times. But they are also a lot more heavyweight than the other methods discussed, and that's a drawback.
A custom DSL is thorough: a framework designer can build it with very clean boundaries, with a clear grammar and hard checks to see whether code conforms to this grammar. If you build your DSL on JSON or XML, you can implement such checks pretty easily using one of the various schema implementations.
A custom DSL gives the potential for non-developers to configure application behavior. At some point in a DSL there is a need to interface with user code, but this may be abstracted away quite far. It lets non-developers reuse code implemented by developers.
A DSL can be extended with a GUI to make it even easier for non-developers to configure it.
Since code written in a DSL can be stored in a database, you can store complex configuration in a database.
A DSL can offer certain security guarantees -- you can ensure that DSL code can only reach into a limited part of your application.
A DSL can implement a declaration engine with sophisticated behavior -- for instance the general detection of configuration conflicts (you try to configure the same thing in conflicting ways in multiple places), and structured, safe overrides that are independent of code and import order. A DSL doesn't have to use such sophistication, but a framework designer that designs a DSL is naturally lead in such a direction.
A drawback of DSL-based configuration is that it is quite distant from the code that it configures. That is fine for some use cases, but overkill for others. A DSL can cause mental overhead -- the applciation developer not only needs to read the application's code but also its configuration files in order to understand the behavior of an application. For many frameworks it can be much nicer to co-locate configuration with code.
A DSL also provides little flexibility during run-time. While you could generate configuration code dynamically, that's a level of meta that's quite expensive (lots of generate/parse cycles) and it can lead to headaches for the developers trying to understand what's going on.
DSL-based configuration is also quite heavy to implement compared to many other more lightweight configuration options described.
Pattern: imperative declaration
You use a declaration engine like in a DSL, but you drive it from programming language code in an imperative way, like imperative registration. In fact, an imperative declaration system can be layered over a imperative registration system.
The difference from imperative registration is that the framework implements a deferred configuration engine, instead of making registrations immediately. Configuration commands are first collected in a separate configuration phase, and only after collection is complete are they executed, resulting in actual registrations.
Fictional example
fromframeworkimportConfigdefsave(data):...applicationcodetosavethedatasomewhere...config=Config()config.form_save('my_form',save)config.commit()
The idea here is that configuration registries are only modified when config.commit() happens, and only after the configuration has been validated.
Real-world example: Pyramid web framework
From the Pyramid web framework:
defhello_world(request):returnResponse('Hello World!')withConfigurator()asconfig:config.add_route('hello','/')config.add_view(hello_world,route_name='hello')
This looks very similar to a plain registry, but inside something else is going on: it first collects all registrations, and then generically detects whether there are conflicts, and generically applies overrides. Once the code exits the with statement, config is complete and committed.
Trade-offs
This brings some of the benefits of a configuration DSL to code. Like a DSL, the configuration system can detect conflicts (the route name 'hello' is registered twice), and it allows sophisticated override patterns that are not dependent on the vagaries of registration order or import order.
Another benefit is that configuration can be generated programmatically, so this allows for a certain amount of run-time dynamism without some the costs that a DSL would have. It is still good to avoid such dynamism as much as possible though, as it can make for very difficult to comprehend code.
The code that is configured may still not be not co-located with the configuration, but at least it's all code, instead of a whole new language.
Pattern: language integrated declaration
You configure the application by using framework-provided annotations for code. This configuration is declarative and does not immediately take place.
Language integration declaration looks like language integrated registration, but uses a configuration engine like with imperative declaration.
Fictional example
fromframeworkimportConfigconfig=Config()# we define and configure the function at the same time@config.form_save('my_form')defsave(data):...applicationcodetosavethedatasomewhere...# elsewhere before application startsconfig.commit()
Real-world example: Morepath web framework
My own Morepath web framework is configured this way.
importmorepathclassApp(morepath.App):pass@App.path(path='/hello')classHello(object):pass@App.view(model=Hello)defview_get(self,request):return"Hello world!"
Here two things happen: an instance of Hello is registered for the route /hello, and a GET view is registered for such instances. You can supply these decorators in any order in any module -- the framework will figure it out. If you subclass App, and re-register the /hello path, you have a new application with new behavior for that path, but the same view.
Trade-offs
I like this way of configuring code very much, so I built a framework for it.
This looks very similar to language-integrated registration but the behavior is declarative.
It's more explicit than convention over configuration, but still low on ceremony, like language-integrated registration. It co-locates configuration with code.
It eliminates many of the issues with the more lightweight language-integrated registration while retaining many of its benefits. It imposes a lot of structure on how configuration works, and this can lead to useful properties: conflict detection and overrides, for instance.
It's a lot more heavy-weight than just passing in a callback or object with an interface -- for many frameworks this is more than enough ceremony, and nothing beats how easy that is to implement and test.
You can't store it in a database or give it to a non-programmer: for that, use a DSL.
But if want a configuration language that's powerful and friendly, this is a good way to go.
It's a lot more difficult to implement though, which is a drawback. If you use Python, you're in luck: I've implemented a framework to help you build this, called Dectate. My Morepath web framework is built on it.
In Dectate, import-time side-effects are minimized: when the decorator is executed the parameters are stored, but registration only happens when commit() is executed. This means there is no dependence on run-time import order, and conflict detection and overrides are supported in a general way.
Conclusion
I hope this helps developers who have to deal with frameworks to understand the decisions made by these frameworks better. If you have a problem with a framework, perhaps I gave you some arguments that lets you express it better as well.
And if you design a framework -- which you should do, as larger applications need frameworks to stay coherent -- you now hopefully have some more concepts to work with to help you make better design decisions.
↧
↧
Mike Driscoll: Two New Typosquatting Libraries Found on PyPI
Two new malicious packages were found on the Python Packaging Index (PyPI) that were designed to steal GPG and SSH keys according to ZDNet. The packages were named python3-dateutil and jeIlyfish where the first “L” is actually an I. These two libraries mimicked the dateutil and jellyfish packages respectively.
The fake python3-dateutil would import the fake jeIlyfish library which housed the malicious code that would attempt to steal GPG and SSH keys. While both of these libraries have been removed from PyPI, this is just another reminder to always be sure that you are installing the right package.
For full details, check out the ZDNet article as it breaks down how the libraries work.
Related Reading
- New Malicious Python Libraries Found Targeting Linux
- Malicious Libraries Found on Python Package Index (PyPI)
The post Two New Typosquatting Libraries Found on PyPI appeared first on The Mouse Vs. The Python.
↧
Kushal Das: Podman on Debian Buster
I use podman on all of my production servers, and also inside of the Qubes system in Fedora VMs. A few days ago I saw this post and thought of trying out the steps on my Debian Buster system.
But, it seems it requires one more installation step, so I am adding the updated installation steps for Debian Buster here.
Install all build dependencies
sudo apt -y install \
gcc \
make \
cmake \
git \
btrfs-progs \
golang-go \
go-md2man \
iptables \
libassuan-dev \
libc6-dev \
libdevmapper-dev \
libglib2.0-dev \
libgpgme-dev \
libgpg-error-dev \
libostree-dev \
libprotobuf-dev \
libprotobuf-c-dev \
libseccomp-dev \
libselinux1-dev \
libsystemd-dev \
pkg-config \
runc \
uidmap \
libapparmor-dev \
libglib2.0-dev \
libcap-dev \
libseccomp-dev
Install latest Golang
Download and install latest golang and also make sure that you have a proper
$GOPATH variable. You can read more
here.
Install conmon
conmon is the OCI container runtime monitor. Install it via the following steps:
git clone https://github.com/containers/conmon
cd conmon
make
sudo make podman
sudo cp /usr/local/libexec/podman/conmon /usr/local/bin/
Install CNI plugins
git clone https://github.com/containernetworking/plugins.git $GOPATH/src/github.com/containernetworking/plugins
cd $GOPATH/src/github.com/containernetworking/plugins
./build_linux.sh
sudo mkdir -p /usr/libexec/cni
sudo cp bin/* /usr/libexec/cni
Setup the bridge
sudo mkdir -p /etc/cni/net.d
curl -qsSL https://raw.githubusercontent.com/containers/libpod/master/cni/87-podman-bridge.conflist | sudo tee /etc/cni/net.d/99-loopback.conf
Create the configuration files
Next, we need configuration files for the registries and also the policy file.
sudo mkdir -p /etc/containers
sudo curl https://raw.githubusercontent.com/projectatomic/registries/master/registries.fedora -o /etc/containers/registries.conf
sudo curl https://raw.githubusercontent.com/containers/skopeo/master/default-policy.json -o /etc/containers/policy.json
Installing slirp4netns
slirp4netns is used for user-mode networking for unprivileged network namespaces. At the time of the writing this blog post, the latest release is 0.4.2.
git clone https://github.com/rootless-containers/slirp4netns
cd slirp4netns
./autogen.sh
./configure --prefix=/usr
make
sudo make install
Installing podman
Finally we are going to install podman.
git clone https://github.com/containers/libpod/ $GOPATH/src/github.com/containers/libpod
cd $GOPATH/src/github.com/containers/libpod
make
sudo make install
Testing podman
Now you can test podman on your Debian system.
podman pull fedora:latest
podman run -it --rm /usr/bin/bash fedora:latest
↧
Python Software Foundation: Mozilla and Chan Zuckerberg Initiative to support pip
The Python Software Foundation is receiving $407,000 USD to support work on pip in 2020. Thank you to Mozilla (through its Mozilla Open Source Support Awards) and to the Chan Zuckerberg Initiative for this funding! This foundational, transformational work will release Python developers and users to concentrate on the tools they're making and using, instead of troubleshooting dependency conflicts. Specifically, CZI and Mozilla are funding user experience, communications/publicity, and testing work (including developing robust testing infrastructure) as well as core feature development and review.

![]() What we're doing with the money
What we're doing with the money
Computers need to know the right order to install pieces of software ("to install x, you need to install y first"). So, when programmers share software, we have to precisely describe those installation prerequisites, and our installation tools need to navigate tricky situations where they're getting conflicting instructions. This project will make pip, a package installer for Python, better at handling that tricky logic, and easier for people to use and troubleshoot.
Millions of people and organizations use tools written in Python, and nearly the entire ecosystem of Python software projects depends on pip. Our project will help everyone more easily install software, diagnose and fix problems, and maintain infrastructure.
The Chan Zuckerberg Initiative funding is, in particular, aimed at improving Essential Open Source Software for Science. Scientists use many tools written in Python -- many of CZI's awardees in this round are written in Python -- but, also, researchers often want to write tools and share them with each other to help science advance faster. Our work will include research and improvements so the installation process will be easier to use and understand, which will enable researchers to build better applications and compose complex toolchains more easily.
We've laid out a detailed three-phase work plan on our pip 2020 Donor-funded Roadmap wiki page. To summarize:
- Mozilla is awarding PSF a Mozilla Open Source Support Award (Track I: Foundational Technology) for $207,000, which is paying for 5 months of:
- Python development work: Reviewing and responding to open issues and pull requests, refactoring build logic, collaborating with downstream projects and users about config flags and transition schedules, working on the dependency resolver itself and fixing bugs.
- Initial user experience research and design work: Reading existing bug reports and posts about Python package management confusion, interviewing users and running user tests, developing user journey maps and workflows, and working with maintainers to write documentation and help messages and to design resolver user experience.
- CZI is giving PSF an Essential Open Source Software for Science grant for $200,000, which is paying for:
- 12 months of Python development, test infrastructure, and project maintenance: Triaging bugs and reviewing pull requests, writing test cases, testing lead developers' work, building test infrastructure, investigating and fixing bugs, and writing the raw material for documentation to help future maintainers onboard better.
- 4 months of Phase III user experience research and design work: Training maintainers in UX design, doing further user tests on the new pip, developing a checklist for developing new features, and making templates for commands, error messages, output, documentation, and config files.
- Travel for initial developer onboarding and for some contributors to attend PyCon North America.
- And both CZI and Mozilla are paying for project management (planning, testing, editing, coordinating, communicating with stakeholders, announcing, reporting to funders, and getting obstacles out of everyone's way) and PSF administrative work (recruiting and overseeing contractors, project oversight, and financial processing).
- Simply Secure is "an educational nonprofit 501(c)3 that supports practitioners in designing ethically-informed, values-driven technology that protects human rights." As experts in open source user experience, Simply Secure will bring UX research and design skills to the command-line experience of Python package management.
- Changeset Consulting, LLC, providing project management, is a returning contractor, having previously worked on the PyPI rewrite launch and improvements to PyPI's accessibility, security, and internationalization. Changeset lead Sumana Harihareswara was also the lead grantwriter for these funding proposals.
Why this and why now?
We're partway through a next-generation rewrite of pip's dependency resolver. The project ran into massive technical debt, but the refactoring is nearly finished and prototype functionality is in alpha now.We need to finish the resolver because many other packaging improvements are blocked on it, it'll fix many dependency issues for Python users, and it'll fix installation problems for conda, certbot, WebSocket, and many other projects. And we need to improve pip's UX by providing better error messages and prompts, logs, output, and reporting, consistently across features, to fit users' mental models better, make hairy problems easier to untangle, and reduce unintended data loss.
The Packaging Working Group looks for potential improvements in Python packaging and distribution that are well-scoped, have community consensus, and could be expedited through funding. In the past three years, the Packaging WG has received funding for several improvements to PyPI -- $170,000 from Mozilla, $80,000 from OTF, and $100,000 from Facebook -- and is seeking to help other packaging tools. In June, pip maintainers and Packaging Working Group members discussed the importance and difficulty of rolling out the new resolver. We worked together to write and submit proposals to Mozilla and the Chan Zuckerberg Initiative.
What's next?
This work will start by early January 2020. Day-to-day work will mostly happen in pip's GitHub repository and the Python developers' Zulip livechat. You can check for regular reports at the Python Insider blog and the Packaging category of Python's Discourse developer forum, archived at the Packaging WG's wiki page. And we'll publicize calls for volunteers, especially for user interviews and tests, on this blog, on community mailing lists, and on Twitter.The Packaging WG will continue to seek funding for future improvements in pip, manylinux, setuptools, the Python Packaging User Guide, PyPI, etc.
Thanks
This award continues our relationship with Mozilla, which supported Python packaging tools with a Mozilla Open Source Support Award in 2017 for Warehouse. Thank you, Mozilla! (MOSS has a number of types of awards, which are open to different sorts of open source/free software projects. If your project is looking for financial support, do check the MOSS website to see if you qualify.)This is new funding from the Chan Zuckerberg Initiative. This project is being made possible in part by a grant from the Chan Zuckerberg Initiative DAF, an advised fund of Silicon Valley Community Foundation. Thank you, CZI! (If your free software/open source project is used by biology researchers, check the Essential Open Source Software for Science Request for Applications and consider applying for the next round).
Thank you to the pip and PyPA maintainers, to the PSF and the Packaging WG, and to all the contributors and volunteers who work on or use Python packaging tools.
↧
Mike Driscoll: Adding Notifications to Long-Running Jupyter Notebook Cells
If you use Jupyter Notebook to run long-running processes, such as machine learning training, then you would probably like to know when the cell finishes executing. There is a neat browser plugin that you can use to help solve this issue called jupyter-notify. It will allow you to have your browser send a pop-up message when the cell finishes executing.
The notification will look something like this:

Let’s learn how you can add this notification to your Jupyter Notebook!
Installation
The first thing you need to do is install Jupyter Notebook, if you haven’t done so already. Here’s how you can do that using pip:
pip install jupyter
Once that is installed, you will need to install jupyter-notify:
pip install jupyternotify
Now that you have all the packages installed, let’s try it out!
Using Jupyter-Notify
To use jupyter-notify, you will need to run Jupyter Notebook. In a terminal, run this command: jupyter notebook
Now enter the following text in the first cell of the Notebook:
%load_ext jupyternotify
This loads the jupyter-notify extension. Run that cell. You may see your browser ask you to allow notifications from your Notebook. You will want to allow that for the notifier to work properly.
Now you need to add the following code to the next cell in the notebook:
%%notify
import time
time.sleep(10)
print('Finished!')
Your Notebook should now look like this:

Now run that second cell. It will call time.sleep() which makes the code pause execution for however many seconds you specify. In this case, you want to pause execution for 10 seconds, then print out a message that the cell is “Finished!”. When the cell finishes execution, you should see a notification pop-up like this:
If you would like to customize the message that jupyter-notify emits, then you can change the second cell to the following:
%%notify -m "The cell has finished running"
import time
time.sleep(10)
print('Finished!')
Note that the first line has changed to accept a flag and a message string. If you want, you can fire multiple messages off within the cell. Just place the %%notify -m “some message” as many times as necessary in your code.
For example, you could change the code above to this:
import time
time.sleep(10)
%notify -m "The cell finished sleeping"
print('Finished!')
%notify -m "All done!"For this code to work, you need to make sure that %notify only has one percent (%) sign instead of two as this is a line-magic in Jupyter Notebook.
Wrapping Up
The jupyter-notify package is pretty neat, but it can be easy to miss the notification if you get interrupted by a coworker. One solution you could use it py-toolbox which has a Notify object that you can use to email yourself when a function or cell completes.
Either way, there are solutions available to you if you want your Jupyter Notebook to let you know when it is finished processing.
Personally, if I had a long running process I would probably put it into a Python script file rather than a Jupyter Notebook as that makes my code easier to test and debug. But if you like using Jupyter Notebook, these packages may be the way to go!
The post Adding Notifications to Long-Running Jupyter Notebook Cells appeared first on The Mouse Vs. The Python.
↧
↧
NumFOCUS: NumFOCUS Kicks Off Year-End Fundraising with $2,500 Gift
Giving Tuesday 2019 marked the start of NumFOCUS’s year-end fundraising campaign, and this year’s effort began with a major donation from the organization’s Board President, Andy Terrel. “Today I’m pledging a gift of $2,500 to help kick off the NumFOCUS end-of-year fundraising campaign,” Terrel wrote yesterday in an e-mail to the NumFOCUS community. “I believe […]
The post NumFOCUS Kicks Off Year-End Fundraising with $2,500 Gift appeared first on NumFOCUS.
↧
S. Lott: Creating Palindromes -- if possible -- from a string of letters.
This can be an interesting exercise. I think it is something that can help people learn to code well. I found this in the LinkedIn Python community: https://www.linkedin.com/groups/25827/.
The Palindrome Problem:
Make a function that makes a palindrome out of the letters in a string and
returns -1 if this is not possible.
Convert a list of strings with the function.
Some test cases:
>>> palify('eedd')
'edde' (or 'deed')
>>> palify('wgerar')
>>> palify('uiuiqii')
'uiiqiiu' or several similar variants.
Let's not get too carried away. I like *some* of this problem.
I don't like the idea of Union[str, int] as a return type from this function. Yes, it's valid Python, but it seems like a code smell. Since the intent is to build lists, a None would be more sensible than a number; we'd have Optional[str] which seems better overall.
The solution that was posted was interesting. It did way too much work, but it was acceptable-looking Python. (It started with a big block comment with "#" on each line instead of a docstring, so... there were minor style problems, but otherwise, it was not bad.)
Here's what popped into my head, to act as a concrete response to the request for comments.
"""
Make a function that makes a palindrome out of the letters in a string and
returns -1 if this is not possible.
Convert a list of strings with the function.
Some test cases:
>>> palify('eedd')
'edde'
>>> palify('wgerar')
>>> palify('uiuiqii')
'uiiqiiu'
"""
from typing import Optional, Set
def palify(source: str) -> Optional[str]:
"""Core palindromic conversion."""
singletons: Set[str] = set()
pairs = list()
for c in source:
if c in singletons:
pairs.append(c)
singletons.remove(c)
else:
singletons.add(c)
if pairs and len(singletons) <= 1:
# presuming a single letter can't be palindromic.
return ''.join(pairs+list(singletons)+pairs[::-1])
return None
if __name__ == "__main__":
s = ['eedd', 'wgerar', 'uiuiqii']
p = list(map(palify, s))
print(f"from {s=}, we get {p=}")
The core problem statement is interesting. And the ancillary requirement is almost as interesting as the problem.
The simple-seeming "Make a palindrome out of the letters of the string" has two parts. First, there's the question of "can it even become a palindrome"? Which implies validating the source data against some set of rules. After that, we have to emit one of the many possible palindromes from the source material.
The original post had a complicated survey of the data. This was followed by an elegant way of creating a palindrome from the survey data. Since we're looking for a bunch of pairs and a singleton, I elided the more complex survey and opted to collect pairs and singletons into two separate collections.
When we've consumed the input, we will have partitioned the characters into their two pools and we can decide if the pools have the right sizes to proceed. The emission of the palindrome is a lazy assembly of the resulting data, first as a list, and then transformed to a single string.
The ancillary requirement is interesting in its own right. When a bundle of letters can't form a palindrome, that seems like a ValueError exception to me. Doing bulk transformations in the presence of ValueErrors seems wrong-ish. I already griefed about the -1 response above: it seems very bad. A None is less bad than -1. An Exception, however, seems like a more right thing to do.
Code Review Response
I think my response to the original code should be follow-up questions on why a defaultdict(int) was used to survey the data in the first place. A Counter() is a better idea, and requires less code.The survey involved trying to locate singletons -- a laudable goal. There may have been a better approach to looking for the presence of a singleton letter in the Counter values.
More fundamentally, there are few states for each letter. There are two stark algorithmic choices: a structure keyed by letter or collections of letters. I've shown the collections, and hinted at the collection. The student response used a collection.
I think this problem serves as a good discussion for algorithmic alternatives. The core problem of detecting the possibility of palindromicity for a bunch of letters is cool. There are two choices. The handling of the exceptional case (-1, None or ValueError) is another bundle of choices.
↧
Dan Yeaw: GitHub Actions: Automate Your Python Development Workflow
At GitHub Universe 2018, GitHub launched GitHub Actions in beta. Later in August 2019, GitHub announced the expansion of GitHub Actions to include Continuous Integration / Continuous Delivery (CI/CD). At Universe 2019, GitHub announced that Actions are out of beta and generally available. I spent the last few days, while I was taking some vacation during Thanksgiving, to explore GitHub Actions for automation of Python projects.
With my involvement in the Gaphor project, we have a GUI application to maintain, as well as two libraries, a diagramming widget called Gaphas, and we more recently took over maintenance of a library that enables multidispatch and events called Generic. It is important to have an efficient programming workflow to maintain these projects, so we can spend more of our open source volunteer time focusing on implementing new features and other enjoyable parts of programming, and less time doing manual and boring project maintenance.
In this blog post, I am going to give an overview of what CI/CD is, my previous experience with other CI/CD systems, how to test and deploy Python applications and libraries using GitHub Actions, and finally highlight some other Actions that can be used to automate other parts of your Python workflow.
Overview of CI/CD
Continuous Integration (CI) is the practice of frequently integrating changes to code with the existing code repository.

Continuous Delivery / Delivery (CD) then extends CI by making sure the software checked in to the master branch is always in a state to be delivered to users, and automates the deployment process.

For open source projects on GitHub or GitLab, the workflow often looks like:
- The latest development is on the mainline branch called master.
- Contributors create their own copy of the project, called a fork, and then clone their fork to their local computer and setup a development environment.
- Contributors create a local branch on their computer for a change they want to make, add tests for their changes, and make the changes.
- Once all the unit tests pass locally, they commit the changes and push them to the new branch on their fork.
- They open a Pull Request to the original repo.
- The Pull Request kicks off a build on the CI system automatically, runs formatting and other lint checks, and runs all the tests.
- Once all the tests pass, and the maintainers of the project are good with the updates, they merge the changes back to the master branch.
Either in a fixed release cadence, or occasionally, the maintainers then add a version tag to master, and kickoff the CD system to package and release a new version to users.
My Experience with other CI/CD Systems
Since most open source projects didn't want the overhead of maintaining their own local CI server using software like Jenkins, the use of cloud-based or hosted CI services became very popular over the last 7 years. The most frequently used of these was Travis CI with Circle CI a close second. Although both of these services introduced initial support for Windows over the last year, the majority of users are running tests on Linux and macOS only. It is common for projects using Travis or Circle to use another service called AppVeyor if they need to test on Windows.
I think the popularity of Travis CI and the other similar services is based on how easy they were to get going with. You would login to the service with your GitHub account, tell the service to test one of your projects, add a YAML formatted file to your repository using one of the examples, and push to the software repository (repo) to trigger your first build. Although these services are still hugely popular, 2019 was the year that they started to lose some of their momentum. In January 2019, a company called Idera bought Travis CI. In February Travis CI then laid-off a lot of their senior engineers and technical staff.
The 800-pound gorilla entered the space in 2018, when Microsoft bought GitHub in June and then rebranded their Visual Studio Team Services ecosystem and launched Azure Pipelines as a CI service in September. Like most of the popular services, it was free for open source projects. The notable features of this service was that it launched supporting Linux, macOS, and Windows, and it allowed for 10 parallel jobs. Although the other services offer parallel builds, on some platforms they are limited for open source projects, and I would often be waiting for a server called an "agent" to be available with Travis CI. Following the lay-offs at Travis CI, I was ready to explore other services to use, and Azure Pipelines was the new hot CI system.
In March 2019, I was getting ready to launch version 1.0.0 of Gaphor after spending a couple of years helping to update it to Python 3 and PyGObject. We had been using Travis CI, and we were lacking the ability to test and package the app on all three major platforms. I used this as an opportunity to learn Azure Pipelines with the goal of being able to fill this gap we had in our workflow.
My takeaways from this experience is that Azure Pipelines is lacking much of the ease of use as compared to Travis CI, but has other huge advantages including build speed and the flexibility and power to create complex cross-platform workflows. Developing a complex workflow on any of these CI systems is challenging because the feedback you receive takes a long time to get back to you. In order to create a workflow, I normally:
- Create a branch of the project I am working on
- Develop a YAML configuration based on the documentation and examples available
- Push to the branch, to kickoff the CI build
- Realize that something didn't work as expected after 10 minutes of waiting for the build to run
- Go back to step 2 and repeat, over and over again
One of my other main takeaways was that the documentation was often lacking good examples of complex workflows, and was not very clear on how to use each step. This drove even more trial and error, which requires a lot of patience as you are working on a solution. After a lot of effort, I was able to complete a configuration that tested Gaphor on Linux, macOS, and Windows. I also was able to partially get the CD to work by setting up Pipelines to add the built dmg file for macOS to a draft release when I push a new version tag. A couple of weeks ago, I was also able build and upload Python Wheel and source distribution, along with the Windows binaries built in MSYS2.
Despite the challenges getting there, the result was very good! Azure Pipelines is screaming fast, about twice as fast as Travis CI was for my complex workflows (25 minutes to 12 minutes). The tight integration that allows testing on all three major platforms was also just what I was looking for.
How to Test a Python Library using GitHub Actions
With all the background out of the way, now enters GitHub Actions. Although I was very pleased with how Azure Pipelines performs, I thought it would be nice to have something that could better mix the ease of use of Travis CI with the power Azure Pipelines provides. I hadn't made use of any Actions before trying to replace both Travis and Pipelines on the three Gaphor projects that I mentioned at the beginning of the post.
I started first with the libraries, in order to give GitHub Actions a try with some of the more straightforward workflows before jumping in to converting Gaphor itself. Both Gaphas and Generic were using Travis CI. The workflow was pretty standard for a Python package:
- Run lint using pre-commit to run Black over the code base
- Use a matrix build to test the library using Python 2.7, 3.6, 3.7, and 3.8
- Upload coverage information
To get started with GitHub Actions on a project, go to the Actions tab on the main repo:

Based on your project being made up of mostly Python, GitHub will suggest three different workflows that you can use as templates to create your own:
- Python application - test on a single Python version
- Python package - test on multiple Python versions
- Publish Python Package - publish a package to PyPI using Twine
Below is the workflow I had in mind:

I want to start with a lint job that is run, and once that has successfully completed, I want to start parallel jobs using the multiple versions of Python that my library supports.
For these libraries, the 2nd workflow was the closest for what I was looking
for, since I wanted to test on multiple versions of Python. I selected the
Set up this workflow option. GitHub then creates a new draft YAML file based
on the template that you selected, and places it in the .github/workflows
directory in your repo. At the top of the screen you can also change the name
of the YAML file from pythonpackage.yml to any filename you choose. I called
mine build.yml, since calling this type of workflow a build is the
nomenclature I am familiar with.
As a side note, the online editor that GitHub has implemented for creating Actions is quite good. It includes full autocomplete (toggled with Ctrl+Space), and it actively highlights errors in your YAML file to ensure the correct syntax for each workflow. These type of error checks are priceless due to the long feedback loop, and I actually recommend using the online editor at this point over what VSCode or Pycharm provide.
Execute on Events
The top of each workflow file are two keywords: name and on. The name sets
what will be displayed in the Actions tab for the workflow you are creating. If
you don't define a name, then the name of the YAML file will be shown as the
Action is running. The on keyword defines what will cause the workflow to be
started. The template uses a value of push, which means
that the workflow will be kicked off when you push to any branch in the
repo. Here is an example of how I set these settings for my libraries:
name:Buildon:pull_request:push:branches:master
Instead of running this workflow on any push event, I wanted a build to happen during two conditions:
- Any Pull Request
- Any push to the master branch
You can see how that was configured above. Being able to start a workflow on any type of event in GitHub is extremely powerful, and it one of the advantages of the tight integration that GitHub Actions has.
Lint Job
The next section of the YAML file is called jobs, this is where each main
block of the workflow will be defined as a job. The jobs will then be further
broken down in to steps, and multiple commands can be executed in each step.
Each job that you define is given a name. In the template, the job is named
build, but there isn't any special significance of this name. They also are
running a lint step for each version of Python being tested against. I decided
that I wanted to run lint once as a separate job, and then once that is
complete, all the testing can be kicked off in parallel.
In order to add lint as a separate job, I created a new job called lint
nested within the jobs keyword. Below is an example of my lint job:
jobs:lint:runs-on:ubuntu-lateststeps:-uses:actions/checkout@v1-name:Setup Pythonuses:actions/setup-python@v1with:python-version:'3.x'-name:Install Dependenciesrun:|pip install pre-commitpre-commit install-hooks-name:Lint with pre-commitrun:pre-commit run --all-files
Next comes the runs-on keyword which defines which platform GitHub Actions
will run this job on, and in this case I am running on linting on the latest
available version of Ubuntu. The steps keyword is where most of the workflow
content will be, since it defines each step that will be taken as it is run.
Each step optionally gets a name, and then either defines an Action to use, or a
command to run.
Let's start with the Actions first, since they are the first two steps in my
lint job. The keyword for an Action is uses, and the value is the action repo
name and the version. I think of Actions as a library, a reusable step that I
can use in my CI/CD pipeline without having to reinvent the wheel. GitHub
developed these first two Actions that I am making use of, but you will see
later that you can make use of any Actions posted by other users, and even
create your own using the Actions SDK and some TypeScript. I am now convinced
that this is the "secret sauce" of GitHub Actions, and will be what makes this
service truly special. I will discuss more about this later.
The first two Actions I am using clones a copy of the code I am testing from my
repo, and sets up Python. Actions often use the with keyword for the
configuration options, and in this case I am telling the setup-python action
to use a newer version from Python 3.
-uses:actions/checkout@v1-name:Setup Pythonuses:actions/setup-python@v1with:python-version:'3.x'
The last two steps of the linting job are using the run keyword. Here I am
defining commands to execute that aren't covered by an Action. As I mentioned
earlier, I am using pre-commit to run Black over the project and check the code
formatting is correct. I have this broken up in to two steps:
- Install Dependencies - installs pre-commit, and the pre-commit hook environments
- Lint with pre-commit - runs Black against all the files in the repo
In the Install Dependencies step, I am also using the pipe operator, "|", which signifies that I am giving multiple commands, and I am separating each one on a new line. We now should have a complete lint job for a Python library, if you haven't already, now would be a good time to commit and push your changes to a branch, and check the lint job passes for your repo.
Test Job
For the test job, I created another job called test, and it also uses
the ubuntu-latest platform for the job. I did use one new keyword here called
needs. This defines that this job should only be started once the lint job has
finished successfully. If I didn't include this, then the lint job and all the
other test jobs would all be started in parallel.
test:needs:lintruns-on:ubuntu-latest
Next up I used another new keyword called strategy. A strategy creates a build
matrix for your jobs. A build matrix is a set of different configurations of the
virtual environment used for the job. For example, you can run a job against
multiple operating systems, tool version, or in this case against different
versions of Python. This prevents repetitiveness because otherwise you would
need to copy and paste the same steps over and over again for different versions
of Python. Finally, the template we are using also had a max-parallel keyword
which limits the number of parallel jobs that can run simultaneously. I am only
using four versions of Python, and I don't have any reason to limit the number
of parallel jobs, so I removed this line for my YAML file.
strategy:matrix:python-version:[2.7,3.6,3.7,3.8]
Now on to the steps of the job. My first two steps, checkout the sources and
setup Python, are the same two steps as I had above in the lint job. There is
one difference, and that is that I am using the ${{ matrix.python-version }}
syntax in the setup Python step. I use the {{ }} syntax to define an
expression. I am using a special kind of expression called a context, which is
a way to access information about a workflow run, the virtual environment,
jobs, steps, and in this case the Python version information from the matrix
parameters that I configured earlier. Finally, I use the $ symbol in front of
the context expression to tell Actions to expand the expression in to its
value. If version 3.8 of Python is currently running from the matrix, then ${{
matrix.python-version }} is replaced by 3.8.
steps:-uses:actions/checkout@v1-name:Set up Python ${{ matrix.python-version }}uses:actions/setup-python@v1with:python-version:${{ matrix.python-version }}
Since I am testing a GTK diagramming library, I need to also install some
Ubuntu dependencies. I use the > symbol as YAML syntax to ignore the newlines
in my run value, this allows me to execute a really long command while keeping
my standard line length in my .yml file.
-name:Install Ubuntu Dependenciesrun:>sudo apt-get update -q && sudo apt-get install--no-install-recommends -y xvfb python3-dev python3-gipython3-gi-cairo gir1.2-gtk-3.0 libgirepository1.0-dev libcairo2-dev
For my projects, I love using Poetry for managing my Python dependencies.
See my other article on Python Packaging with Poetry and
Briefcase for more
information on how to make use of Poetry for your projects. I am using a custom
Action that Daniel Schep created that installs
Poetry. Although installing Poetry manually is pretty straightforward, I really
like being able to make use of these building blocks that others have created.
Although you should always use a Python virtual environment while you are
working on a local development environment, they aren't really needed since
the environment created for CI/CD is already isolated and won't be reused. This
would be a nice improvement to the install-poetry-action, so that the
creation of virtualenvs are turned off by default.
-name:Install Poetryuses:dschep/install-poetry-action@v1.2with:version:1.0.0b3-name:Turn off Virtualenvsrun:poetry config virtualenvs.create false
Next we have Poetry install the dependencies using the poetry.lock file using
the poetry install command. Then we are to the key step of the job, which is
to run all the tests using Pytest. I preface the pytest command with
xvfb-run because this is a GUI library, and many of the tests would fail
because there is no display server, like X or Wayland, running on the CI runner.
The X virtual framebuffer (Xvfb) display server is used to perform all the
graphical operations in memory without showing any screen output.
-name:Install Python Dependenciesrun:poetry install-name:Test with Pytestrun:xvfb-run pytest
The final step of the test phase is to upload the code coverage information. We are using Code Climate for analyzing coverage, because it also integrates a nice maintainability score based on things like code smells and duplication it detects. I find this to be a good tool to help us focus our refactoring and other maintenance efforts. Coveralls and Codecov are good options that I have used as well. In order for the code coverage information to be recorded while Pytest is running, I am using the pytest-cov Pytest plugin.
-name:Code Climate Coverage Actionuses:paambaati/codeclimate-action@v2.3.0env:CC_TEST_REPORTER_ID:195e9f83022747c8eefa3ec9510dd730081ef111acd99c98ea0efed7f632ff8awith:coverageCommand:coverage xml
CD Workflow - Upload to PyPI
I am using a second workflow for my app, and this workflow would actually be
more in place for a library, so I'll cover it here. The Python Package Index
(PyPI) is normally how we share libraries across Python projects, and it is
where they are installed from when you run pip install. Once I am ready to
release a new version of my library, I want the CD pipeline to upload it to
PyPI automatically.
If you recall from earlier, the third GitHub Action Python workflow template was
called Publish Python Package. This template is close to what I needed for my
use case, except I am using Poetry to build and upload instead of using
setup.py to build and Twine to upload. I also used a slightly different event
trigger.
on:release:types:published
This sets my workflow to execute when I fully publish the GitHub release. The
Publish Python Package template used the event created instead. However, it
makes more sense to me to publish the new version, and then upload it to PyPI,
instead of uploading to PyPI and then publishing it. Once a version is uploaded
to PyPI it can't be reuploaded, and new version has to be created to upload
again. In other words, doing the most permanent step last is my preference.
The rest of the workflow, until we get to the last step, should look very similar to the test workflow:
jobs:deploy:runs-on:ubuntu-lateststeps:-uses:actions/checkout@v1-name:Set up Pythonuses:actions/setup-python@v1with:python-version:'3.x'-name:Install Poetryuses:dschep/install-poetry-action@v1.2with:version:1.0.0b3-name:Install Dependenciesrun:poetry install-name:Build and publishrun:|poetry buildpoetry publish -u ${{ secrets.PYPI_USERNAME }} -p ${{ secrets.PYPI_PASSWORD }}
The final step in the workflow uses the poetry publish command to upload the
Wheel and sdist to PyPI. I defined the secrets.PYPI_USERNAME and
secrets.PYPI_PASSWORD context expressions by going to the repository
settings, then selecting Secrets, and defining two new encrypted environmental
variables that are only exposed to this workflow. If a contributor created a
Pull Request from a fork of this repo, the secrets would not be passed to any
of workflows started from the Pull Request. These secrets, passed via the -u
and -p options of the publish command, are used to authenticate with the
PyPI servers.
At this point, we are done with our configuration to test and release a library. Commit and push your changes to your branch, and ensure all the steps pass successfully. This is what the output will look like on the Actions tab in GitHub:

I have posted the final version of my complete GitHub Actions workflows for a Python library on the Gaphas repo.
How to Test and Deploy a Python Application using GitHub Actions
My use case for testing a cross-platform Python Application is slightly different from the previous one we looked at for a library. For the library, it was really important we tested on all the supported versions of Python. For an application, I package the application for the platform it is running on with the version of Python that I want the app to use, normally the latest stable release of Python. So instead of testing with multiple versions of Python, it becomes much more important to ensure that the tests pass on all the platforms that the application will run on, and then package and deploy the app for each platform.
Below are the two pipelines I would like to create, one for CI and one for CD.
Although you could combine these in to a single pipeline, I like that GitHub
Actions allows so much flexibility in being able to define any GitHub event to
start a workflow. This tight integration is definitely a huge bonus here, and it
allows you to make each workflow a little more atomic and understandable. I
named my two workflows build.yml for the CI portion, and release.yml for the
CD portion.

Caching Python Dependencies
Although the lint phase is the same between a library and an application, I am going to add in one more optional cache step that I didn't include earlier for simplification:
-name:Use Python Dependency Cacheuses:actions/cache@v1.0.3with:path:~/.cache/pipkey:${{ runner.os }}-pip-${{ hashFiles('**/poetry.lock') }}restore-keys:${{ runner.os }}-pip-
It is a good practice to use a cache to store information that doesn't often change in your builds, like Python dependencies. It can help speed up the build process and lessen the load on the PyPI servers. While setting this up, I also learned from the Travis CI documentation that you should not cache large files that are quick to install, but are slow to download like Ubuntu packages and docker images. These files take as long to download from the cache as they do from the original source. This explains why the cache action doesn't have any examples on caching these types of files.
The caches work by checking if a cached archive exists at the beginning of the workflow. If it exists, it downloads it and unpacks it to the path location. At the end of the workflow, the action checks if the cache previously existed, if not, this is called a cache miss, and it creates a new archive and uploads it to remote storage.
A few configurations to notice, the path is operating system dependent because
pip stores its cache in different locations. My configuration above is for
Ubuntu, but you would need to use ~\AppData\Local\pip\Cache for Windows and
~/Library/Caches/pip for macOS. The key is used to determine if the correct
cache exists for restoring and saving to. Since I am using Poetry for
dependency management, I am taking the hash of the poetry.lock file and
adding it to end of a key which contains the context expression for the
operating system that the job is running on, runner.os, and pip. This will
look like
Windows-pip-45f8427e5cd3738684a3ca8d009c0ef6de81aa1226afbe5be9216ba645c66e8a,
where the end is a long hash. This way if my project dependencies change, my
poetry.lock will be updated, and a new cache will be created instead of
restoring from the old cache. If you aren't using Poetry, you could also use
your requirements.txt or Pipfile.lock for the same purpose.
As we mentioned earlier, if the key doesn't match an existing cache, it's
called a cache miss. The final configuration option called restore-keys is
optional, and it provides an ordered list of keys to use for restoring the
cache. It does this by sequentially searching for any caches that partially
match in the restore-keys list. If a key partially matches, the action
downloads and unpacks the archive for use, until the new cache is uploaded at
the end of the workflow.
Test Job
Ideally, it would be great to use a build matrix to test across platforms. This way you could have similar build steps for each platform without repeating yourself. This would look something like this:
runs-on:${{ matrix.os }}strategy:matrix:os:[ubuntu-latest,windows-latest,macOS-latest]steps:-name:Install Ubuntu Dependenciesif:matrix.os == 'ubuntu-latest'run:>sudo apt-get update -q && sudo apt-get install--no-install-recommends -y xvfb python3-dev python3-gipython3-gi-cairo gir1.2-gtk-3.0 libgirepository1.0-dev libcairo2-dev-name:Install Brew Dependenciesif:matrix.os == 'macOS-latest'run:brew install gobject-introspection gtk+3 adwaita-icon-theme
Notice the if keyword tests which operating system is currently being used in
order to modify the commands for each platform. As I mentioned earlier, the GTK
app I am working on, requires MSYS2 in order to test
and package it for Windows. Since MSYS2 is a niche platform, most of the steps
are unique and require manually setting paths and executing shell scripts. At
some point maybe we can get some of these unique parts better wrapped in an
action, so that when we abstract up to the steps, they can be more common
across platforms. Right now, using a matrix for each operating system in my
case wasn't easier than just creating three separate jobs, one for each
platform.
If you are interested in a more complex matrix setup, Jeff Triplett posted his configuration for running five different Django versions against five different Python versions.
The implementation of the three test jobs is similar to the library test job that we looked at earlier.
test-linux:needs:lintruns-on:ubuntu-latest...test-macos:needs:lintruns-on:macOS-latest...test-windows:needs:lintruns-on:windows-latest
The other steps to install the dependencies, setup caching, and test with Pytest were identical.
CD Workflow - Release the App Installers
Now that we have gone through the CI workflow for a Python application, on to the CD portion. This workflow is using different event triggers:
name:Releaseon:release:types:[created,edited]
GitHub has a Release tab that is built in to each repo. The deployment workflow here is started if I create or modify a release. You can define multiple events that will start the workflow by adding them as a comma separated list. When I want to release a new version of Gaphor:
- I update the version number in the
pyproject.toml, commit the change, add a version tag, and finally push the commit and the tag. - Once the tests pass, I edit a previously drafted release to point the tag to the tag of the release.
- The release workflow automatically builds and uploads the Python Wheel and sdist, the macOS dmg, and the Windows installer.
- Once I am ready, I click on the GitHub option to Publish release.
In order to achieve this workflow, first we create a job for Windows and macOS:
upload-windows:runs-on:windows-latest...upload-macos:runs-on:macOS-latest...
The next steps to checkout the source, setup Python, install dependencies, install poetry, turn off virtualenvs, use the cache, and have poetry install the Python dependencies are the exact same as the application Test Job above.
Next we build the wheel and sdist, which is a single command when using Poetry:
-name:Build Wheel and sdistrun:poetry build
Our packaging for Windows is using custom shell scripts that run PyInstaller to package up the app, libraries, and Python, and makensis to create a Windows installer. We are also using a custom shell script to package the app for macOS. Once I execute the scripts to package the app, I then upload the release assets to GitHub:
-name:Upload Assetsuses:AButler/upload-release-assets@v2.0with:files:'macos-dmg/*dmg;dist/*;win-installer/*.exe'repo-token:${{ secrets.GITHUB_TOKEN }}
Here I am using Andrew Butler's
upload-release-assets
action. GitHub also has an action to perform this called
upload-release-asset, but
at the time of writing this, it didn't support uploading multiple files using
wildcard characters, called glob patterns. secrets.GITHUB_TOKEN is another
context expression to get the access token to allow Actions permissions to
access the project repository, in this case to upload the release assets to a
drafted release.
The final version of my complete GitHub Actions workflows for the cross-platform app are posted on the Gaphor repo.
Future Improvements to My Workflow
I think there is still some opportunity to simplify the workflows that I have created through updates to existing actions or creating new actions. As I mentioned earlier, it would be nice to have things at a maturity level so that no custom environment variable, paths, or shell scripts need to be run. Instead, we would be building workflows with actions as building blocks. I wasn't expecting this before I started working with GitHub Actions, but I am sold that this would be immensely powerful.
Since GitHub recently released CI/CD for Actions, many of the GitHub provided actions could use a little polish still. Most of the things that I thought of for improvements, already had been recognized by others with Issues opened for Feature requests. If we give it a little time, I am sure these will be improved soon.
I also said that one of my goals was to release to the three major platforms,
but if you were paying attention in the last section, I only mentioned Windows
and macOS. We are currently packaging our app using Flatpak for Linux and it is
distributed through FlatHub. FlatHub does have an
automatic build system, but it requires manifest files stored in a special
separate FlatHub repo for the app. I also contributed to the Flatpak Builder
Tools in order to
automatically generate the needed manifest from the poetry.lock file. This
works good, but it would be nice in the future to have the CD workflow for my
app, kickoff updates to the FlatHub repo.
Bonus - Other Great Actions
Debugging with tmate - tmate is a terminal sharing app built on top of tmux. This great action allows you to pause a workflow in the middle of executing the steps, and then ssh in to the host runner and debug your configuration. I was getting a Python segmentation fault while running my tests, and this action proved to be extremely useful.
Release Drafter - In
my app CD workflow, I showed that I am executing it when I create or edit a
release. The release drafter action drafts my next release with release notes
based on the Pull Requests that are merged. I then only have to edit the
release to add the tag I want to release with, and all of my release assets
automatically get uploaded. The PR
Labeler action goes along
with this well to label your Pull Requests based on branch name patterns like
feature/*.
↧
IslandT: Python if else demo
A simple kata from codewars will show us how to use the if-else statement in python.
The wide mouth frog is particularly interested in the eating habits of other creatures.
He just can’t stop asking the creatures he encounters what they like to eat. But then he meets the alligator who just LOVES to eat wide-mouthed frogs!
When he meets the alligator, it then makes a tiny mouth.
Your goal in this kata is to create the complete the mouth_size method this method takes one argument animal which corresponds to the animal encountered by the frog. If this one is an alligator (case insensitive) return small otherwise return wide.
def mouth_size(animal):
if animal.lower() == "alligator":
return "small"
else:
return "wide"
As you can see, if the animal is an alligator then the function will return “small” mouth, or else “wide” mouth will be returned!
I have started to write again, not just about the programming topic but also about other topics such as web development, browser and online business on this website, therefore stay tuned for more interesting stuff in the future!
↧
↧
Janusworx: #100DaysOfCode, Day 015 – Quick and Dirty Web Page Download
Finally got the program done!
I wanted to write a program that would just get the latest comic from turnoff.us and save the picture to a file.
In the course of writing this little program,
- I learnt about the basics of context handlers
- I learnt about the
osmodule in Python - I learnt how to scrape a web page using requests, beautiful soup and feedparser. (I was going to originally scrape the web page, but then realised that processing the rss feed would be more efficient. I think it’ll also help me extend/improve the program better, later.
- It helped me practice, slicing and dicing Python lists and dictionaries and getting data out of them.
- I learnt how to write and save files to disk.
This was really fun to do.
I see a million ways to take this dinky, little program forward. It could do the whole site for example or download only after comparing the state of the rss feed and fetching new entries etc. It has no error handling at all currently, and I prefer to have very safe, very conservative programs as a user. So lots of work to do. I leave all this for a later date though, while I now forge ahead with my #100DaysOfCode journey.
Getting back to the challenges of the course itself, tomorrow onwards.
↧
Stack Abuse: List Comprehensions in Python
A list is one of the fundamental data types in Python. Every time you come across a variable name that's followed by a square bracket [], or a list constructor, it is a list capable of containing multiple items, making it a compound data type. Similarly, it is also a breeze to declare a new list and subsequently add one or more items to it.
Let us create a new populated list, for example:
>>> new_list = [1, 2, 3, 4, 5]
>>> new_list
[1, 2, 3, 4, 5]
Or we can simply use the append() method to add anything you want to the list:
>>> new_list.append(6)
>>> new_list
[1, 2, 3, 4, 5, 6]
If you need to append multiple items to the same list, the extend() method will come in handy. You simply need to pass the list of items to append to the extend method, as shown below:
>>> new_list.extend([7, 8, 9])
>>> new_list
[1, 2, 3, 4, 5, 6, 7, 8, 9]
As you can see, creating a list and appending it with other items is just a piece of cake. You can accomplish this task without having to make multiple calls to the .append() method.
Similarly, you can use a for loop to append multiple items to a list. For example, we will have to write the following piece of code for creating a list of squares for the integers 1-20.
list_a = []
for i in range(1, 20):
list_a.append(i**2)
What are List Comprehensions in Python?
In simplest of words, list comprehension is the process of creating a new list from an existing list. Or, you can say that it is Python's unique way of appending a for loop to a list. But, it is already pretty simple to declare a list and append anything you like to it. Isn't it? So, why bother comprehending our lists?
List comprehension, in fact, offers many benefits over traditional lists. To begin with, the code spans over only a single line, making it even easier to declare and read. It is also less cumbersome to comprehend lists than using for loops to declare a new one. Finally, it is also a convenient, quicker and intuitive way of generating a new, populated list.
Going back to the squares of the integers 1-20, we can obtain the same result using list comprehension method. Here is how our code will look like now:
list_b = [i**2 for i in range(1, 20)]
Notice how the logic for generating the list items are all wrapped in brackets. We'll cover more about the syntax in the next section.
Syntax for List Comprehensions
Before we move forward, it is imperative to explain the syntax of list comprehension. Here is the basic syntax of list comprehension that contains a condition:
[expression for item in list if conditional]
It may seem a bit backwards with the expression being before the loop, but this is how it's done. The order is this way, presumably, because it would be difficult to put the expression after the conditional without some type of semicolon, which Python doesn't have.
As you might have already guessed, "expression" is actually the output we get when we execute the rest of the code in list comprehension. The code itself is just a for loop iterating over a collection of data. In our example, we are using the expression, or the output, to generate the list of squares.
Note that the conditional is optional, so like in our example above we don't need to include it.
It is also worth mentioning that we have a list to be looped over, the item or items to be iterated, and of course a conditional statement in both the list comprehension and traditional for loops. So each method has the same general constructs, but the difference is how you format and organize them.
We are also going to look at another, more complex example to further understand the concept behind list comprehension.
list_a = [1, 3, 6, 9, 12, 15]
list_b = []
for number in list_a:
if number % 4 == 0:
list_b.append(number)
print(list_b)
We are actually looping over the list_a in the above example. Subsequently, we will append an item to list_b if its value is divisible by 4, which is checked using the modulus operator (%). In this example we'd see the following printed to the console:
[12]
This is because 12 is the only number in that array that is divisible by 4.
Once again, we can just use list comprehension to reduce the total lines of code we have to write to attain the same goal.
As mentioned above, the for loop in the above statement is iterating over the list called list_a. Then it executes the conditional statement that checks if the current value is divisible by 4. Finally, it executes the .append() method when it ascertains that the value is actually divisible by 4.
Now, if you want to write the above piece of code with list comprehension, it would look something like this:
list_a = [1, 3, 6, 9, 12, 15]
list_b = [number for number in list_a if number % 4 == 0]
print(list_b)
As you can see, we have reduced the for loop, which spanned over three lines, to only one line. That is actually the real beauty of list comprehension.
When to Use List Comprehensions
You can use list comprehension in many cases in which you need to generate a list from an iterable. However, the best time to use this method is when you need to add or extract items to a list consistently according to a set pattern. Python developers mostly use them to extract data from an often big collection of items.
Let us suppose you have a list of thousands of current and previous students with their names, their father's name, and addresses. The data of each of the students is further stored in a respective dictionary. But, what if you only want to print their names?
students = [
{
"name" : "Jacob Martin",
"father name" : "Ros Martin",
"Address" : "123 Hill Street",
}, {
"name" : "Angela Stevens",
"father name" : "Robert Stevens",
"Address" : "3 Upper Street London",
}, {
"name" : "Ricky Smart",
"father name" : "William Smart",
"Address" : "Unknown",
}
]
We do have the option to iterate over the list using the traditional for loop:
names_list = []
for student in students:
names_list.append(student['name'])
print(names_list)
Although in this example it's only two lines of code for the for loop, we don't even need to write this many lines. We can accomplish the same task by writing only one line of code through list comprehension method:
names_list = [student['name'] for student in students]
print(names_list)
['Jacob Martin', 'Angela Stevens', 'Ricky Smart']
Conclusion
It is really amazing how list comprehensions actually reduces your workload as well. However, it may seem confusing in the beginning. It is particularly baffling for beginners who have never ventured into this territory before, mostly due to the syntax. You may also find it hard to grasp the concept if you have been programming in other languages because list comprehension does not exist in any of them. The only way to get your head around list comprehension is to practice hard.
↧
NumFOCUS: SunPy Receives NASA Grant, Helps Generate Parker Solar Probe Results
The post SunPy Receives NASA Grant, Helps Generate Parker Solar Probe Results appeared first on NumFOCUS.
↧