There are several ways in which you can extend the functionality of Python. One of these is to write your Python module in C or C++. This process can lead to improved performance and better access to C library functions and system calls. In this tutorial, you’ll discover how to use the Python API to write Python C extension modules.
You’ll learn how to:
- Invoke C functions from within Python
- Pass arguments from Python to C and parse them accordingly
- Raise exceptions from C code and create custom Python exceptions in C
- Define global constants in C and make them accessible in Python
- Test, package, and distribute your Python C extension module
Extending Your Python Program
One of the lesser-known yet incredibly powerful features of Python is its ability to call functions and libraries defined in compiled languages such as C or C++. This allows you to extend the capabilities of your program beyond what Python’s built-in features have to offer.
There are many languages you could choose from to extend the functionality of Python. So, why should you use C? Here are a few reasons why you might decide to build a Python C extension module:
To implement new built-in object types: It’s possible to write a Python class in C, and then instantiate and extend that class from Python itself. There can be many reasons for doing this, but more often than not, performance is primarily what drives developers to turn to C. Such a situation is rare, but it’s good to know the extent to which Python can be extended.
To call C library functions and system calls: Many programming languages provide interfaces to the most commonly used system calls. Still, there may be other lesser-used system calls that are only accessible through C. The os module in Python is one example.
This is not an exhaustive list, but it gives you the gist of what can be done when extending Python using C or any other language.
To write Python modules in C, you’ll need to use the Python API, which defines the various functions, macros, and variables that allow the Python interpreter to call your C code. All of these tools and more are collectively bundled in the Python.h header file.
Writing a Python Interface in C
In this tutorial, you’ll write a small wrapper for a C library function, which you’ll then invoke from within Python. Implementing a wrapper yourself will give you a better idea about when and how to use C to extend your Python module.
Understanding fputs()
fputs() is the C library function that you’ll be wrapping:
intfputs(constchar*,FILE*)
This function takes two arguments:
const char * is an array of characters.FILE * is a file stream pointer.
fputs() writes the character array to the file specified by the file stream and returns a non-negative value. If the operation is successful, then this value will denote the number of bytes written to the file. If there’s an error, then it returns EOF. You can read more about this C library function and its other variants in the manual page entry.
Writing the C Function for fputs()
This is a basic C program that uses fputs() to write a string to a file stream:
#include<stdio.h>#include<stdlib.h>#include<unistd.h>intmain(){FILE*fp=fopen("write.txt","w");fputs("Real Python!",fp);fclose(fp);return1;}This snippet of code can be summarized as follows:
- Open the file
write.txt. - Write the string
"Real Python!" to the file.
Note: The C code in this article should build on most systems. It has been tested on GCC without using any special flags.
In the following section, you’ll write a wrapper for this C function.
Wrapping fputs()
It might seem a little weird to see the full code before an explanation of how it works. However, taking a moment to inspect the final product will supplement your understanding in the following sections. The code block below shows the final wrapped version of your C code:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&filename)){ 7 returnNULL; 8 } 9 10 FILE*fp=fopen(filename,"w");11 bytes_copied=fputs(str,fp);12 fclose(fp);13 14 returnPyLong_FromLong(bytes_copied);15 }This code snippet references three object structures:
PyObjectPyArg_ParseTuple()PyLong_FromLong()
These are used for data type definition for the Python language. You’ll go through each of them now.
PyObject
PyObject is an object structure that you use to define object types for Python. All Python objects share a small number of fields that are defined using the PyObject structure. All other object types are extensions of this type.
PyObject tells the Python interpreter to treat a pointer to an object as an object. For instance, setting the return type of the above function as PyObject defines the common fields that are required by the Python interpreter in order to recognize this as a valid Python type.
Take another look at the first few lines of your C code:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Snip */In line 2, you declare the argument types you wish to receive from your Python code:
char *str is the string you want to write to the file stream.char *filename is the name of the file to write to.
PyArg_ParseTuple()
PyArg_ParseTuple() parses the arguments you’ll receive from your Python program into local variables:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&filename)){ 7 returnNULL; 8 } 9 10 /* Snip */If you look at line 6, then you’ll see that PyArg_ParseTuple() takes the following arguments:
args are of type PyObject.
"ss" is the format specifier that specifies the data type of the arguments to parse. (You can check out the official documentation for a complete reference.)
&str and &filename are pointers to local variables to which the parsed values will be assigned.
PyArg_ParseTuple() evaluates to false on failure. If it fails, then the function will return NULL and not proceed any further.
fputs()
As you’ve seen before, fputs() takes two arguments, one of which is the FILE * object. Since you can’t parse a Python textIOwrapper object using the Python API in C, you’ll have to use a workaround:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&filename)){ 7 returnNULL; 8 } 9 10 FILE*fp=fopen(filename,"w");11 bytes_copied=fputs(str,fp);12 fclose(fp);13 14 returnPyLong_FromLong(bytes_copied);15 }Here’s a breakdown of what this code does:
- In line 10, you’re passing the name of the file that you’ll use to create a
FILE * object and pass it on to the function. - In line 11, you call
fputs() with the following arguments:str is the string you want to write to the file.fp is the FILE * object you defined in line 10.
You then store the return value of fputs() in bytes_copied. This integer variable will be returned to the fputs() invocation within the Python interpreter.
PyLong_FromLong(bytes_copied)
PyLong_FromLong() returns a PyLongObject, which represents an integer object in Python. You can find it at the very end of your C code:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&filename)){ 7 returnNULL; 8 } 9 10 FILE*fp=fopen(filename,"w");11 bytes_copied=fputs(str,fp);12 fclose(fp);13 14 returnPyLong_FromLong(bytes_copied);15 }Line 14 generates a PyLongObject for bytes_copied, the variable to be returned when the function is invoked in Python. You must return a PyObject* from your Python C extension module back to the Python interpreter.
Writing the Init Function
You’ve written the code that makes up the core functionality of your Python C extension module. However, there are still a few extra functions that are necessary to get your module up and running. You’ll need to write definitions of your module and the methods it contains, like so:
staticPyMethodDefFputsMethods[]={{"fputs",method_fputs,METH_VARARGS,"Python interface for fputs C library function"},{NULL,NULL,0,NULL}};staticstructPyModuleDeffputsmodule={PyModuleDef_HEAD_INIT,"fputs","Python interface for the fputs C library function",-1,FputsMethods};These functions include meta information about your module that will be used by the Python interpreter. Let’s go through each of the structs above to see how they work.
PyMethodDef
In order to call the methods defined in your module, you’ll need to tell the Python interpreter about them first. To do this, you can use PyMethodDef. This is a structure with 4 members representing a single method in your module.
Ideally, there will be more than one method in your Python C extension module that you want to be callable from the Python interpreter. This is why you need to define an array of PyMethodDef structs:
staticPyMethodDefFputsMethods[]={{"fputs",method_fputs,METH_VARARGS,"Python interface for fputs C library function"},{NULL,NULL,0,NULL}};Each individual member of the struct holds the following info:
"fputs" is the name the user would write to invoke this particular function.
method_fputs is the name of the C function to invoke.
METH_VARARGS is a flag that tells the interpreter that the function will accept two arguments of type PyObject*:
self is the module object.args is a tuple containing the actual arguments to your function. As explained previously, these arguments are unpacked using PyArg_ParseTuple().
- The final string is a value to represent the method docstring.
PyModuleDef
Just as PyMethodDef holds information about the methods in your Python C extension module, the PyModuleDef struct holds information about your module itself. It is not an array of structures, but rather a single structure that’s used for module definition:
staticstructPyModuleDeffputsmodule={PyModuleDef_HEAD_INIT,"fputs","Python interface for the fputs C library function",-1,FputsMethods};There are a total of 9 members in this struct, but not all of them are required. In the code block above, you initialize the following five:
PyModuleDef_HEAD_INIT is a member of type PyModuleDef_Base, which is advised to have just this one value.
"fputs" is the name of your Python C extension module.
The string is the value that represents your module docstring. You can use NULL to have no docstring, or you can specify a docstring by passing a const char * as shown in the snippet above. It is of type Py_ssize_t. You can also use PyDoc_STRVAR() to define a docstring for your module.
-1 is the amount of memory needed to store your program state. It’s helpful when your module is used in multiple sub-interpreters, and it can have the following values:
- A negative value indicates that this module doesn’t have support for sub-interpreters.
- A non-negative value enables the re-initialization of your module. It also specifies the memory requirement of your module to be allocated on each sub-interpreter session.
FputsMethods is the reference to your method table. This is the array of PyMethodDef structs you defined earlier.
For more information, check out the official Python documentation on PyModuleDef.
PyMODINIT_FUNC
Now that you’ve defined your Python C extension module and method structures, it’s time to put them to use. When a Python program imports your module for the first time, it will call PyInit_fputs():
PyMODINIT_FUNCPyInit_fputs(void){returnPyModule_Create(&fputsmodule);}PyMODINIT_FUNC does 3 things implicitly when stated as the function return type:
- It implicitly sets the return type of the function as
PyObject*. - It declares any special linkages.
- It declares the function as extern “C.” In case you’re using C++, it tells the C++ compiler not to do name-mangling on the symbols.
PyModule_Create() will return a new module object of type PyObject *. For the argument, you’ll pass the address of the method structure that you’ve already defined previously, fputsmodule.
Note: In Python 3, your init function must return a PyObject * type. However, if you’re using Python 2, then PyMODINIT_FUNC declares the function return type as void.
Putting It All Together
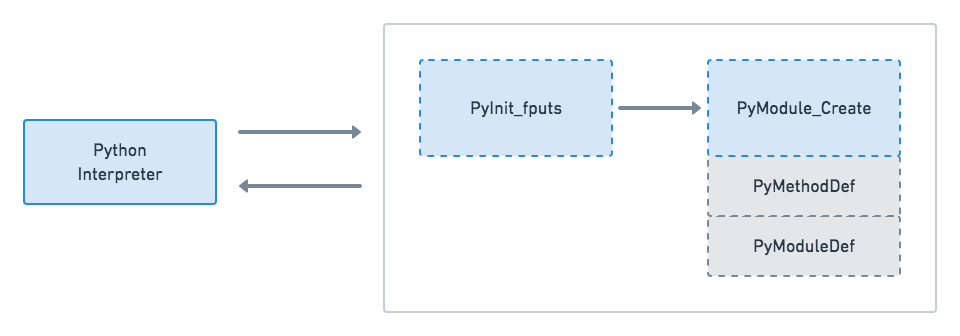
Now that you’ve written the necessary parts of your Python C extension module, let’s take a step back to see how it all fits together. The following diagram shows the components of your module and how they interact with the Python interpreter:
![Python C API Communication]()
When you import your Python C extension module, PyInit_fputs() is the first method to be invoked. However, before a reference is returned to the Python interpreter, the function makes a subsequent call to PyModule_Create(). This will initialize the structures PyModuleDef and PyMethodDef, which hold meta information about your module. It makes sense to have them ready since you’ll make use of them in your init function.
Once this is complete, a reference to the module object is finally returned to the Python interpreter. The following diagram shows the internal flow of your module:
![Python C API Module API]()
The module object returned by PyModule_Create() has a reference to the module structure PyModuleDef, which in turn has a reference to the method table PyMethodDef. When you call a method defined in your Python C extension module, the Python interpreter uses the module object and all of the references it carries to execute the specific method. (While this isn’t exactly how the Python interpreter handles things under the hood, it’ll give you an idea of how it works.)
Similarly, you can access various other methods and properties of your module, such as the module docstring or the method docstring. These are defined inside their respective structures.
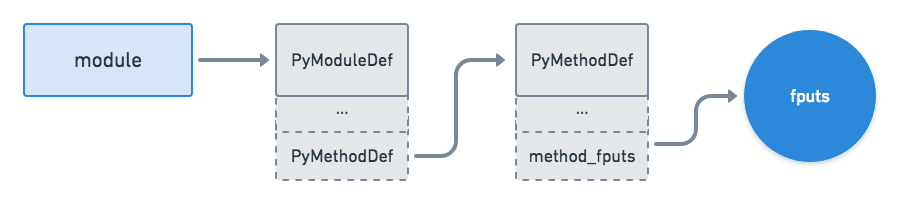
Now you have an idea of what happens when you call fputs() from the Python interpreter. The interpreter uses your module object as well as the module and method references to invoke the method. Finally, let’s take a look at how the interpreter handles the actual execution of your Python C extension module:
![Python C API <code>fputs</code> Function Flow]()
fputs Function Flow" />fputs Function Flow" />fputs Function Flow"/>
Once method_fputs() is invoked, the program executes the following steps:
- Parse the arguments you passed from the Python interpreter with
PyArg_ParseTuple() - Pass these arguments to
fputs(), the C library function that forms the crux of your module - Use
PyLong_FromLong to return the value from fputs()
To see these same steps in code, take a look at method_fputs() again:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&filename)){ 7 returnNULL; 8 } 9 10 FILE*fp=fopen(filename,"w");11 bytes_copied=fputs(str,fp);12 fclose(fp);13 14 returnPyLong_FromLong(bytes_copied);15 }To recap, your method will parse the arguments passed to your module, send them on to fputs(), and return the results.
Packaging Your Python C Extension Module
Before you can import your new module, you first need to build it. You can do this by using the Python package distutils.
You’ll need a file called setup.py to install your application. For this tutorial, you’ll be focusing on the part specific to the Python C extension module. For a full primer, check out How to Publish an Open-Source Python Package to PyPI.
A minimal setup.py file for your module should look like this:
fromdistutils.coreimportsetup,Extensiondefmain():setup(name="fputs",version="1.0.0",description="Python interface for the fputs C library function",author="<your name>",author_email="your_email@gmail.com",ext_modules=[Extension("fputs",["fputsmodule.c"])])if__name__=="__main__":main()The code block above shows the standard arguments that are passed to setup(). Take a closer look at the last positional argument, ext_modules. This takes a list of objects of the Extensions class. An object of the Extensions class describes a single C or C++ extension module in a setup script. Here, you pass two keyword arguments to its constructor, namely:
name is the name of the module.[filename] is a list of paths to files with the source code, relative to the setup script.
Building Your Module
Now that you have your setup.py file, you can use it to build your Python C extension module. It’s strongly advised that you use a virtual environment to avoid conflicts with your Python environment.
Navigate to the directory containing setup.py and run the following command:
$ python3 setup.py install
This command will compile and install your Python C extension module in the current directory. If there are any errors or warnings, then your program will throw them now. Make sure you fix these before you try to import your module.
By default, the Python interpreter uses clang for compiling the C code. If you want to use gcc or any other C compiler for the job, then you need to set the CC environment variable accordingly, either inside the setup script or directly on the command line. For instance, you can tell the Python interpreter to use gcc to compile and build your module this way:
$CC=gcc python3 setup.py install
However, the Python interpreter will automatically fall back to gcc if clang is not available.
Running Your Module
Now that everything is in place, it’s time to see your module in action! Once it’s successfully built, fire up the interpreter to test run your Python C extension module:
>>>>>> importfputs>>> fputs.__doc__'Python interface for the fputs C library function'>>> fputs.__name__'fputs'>>> # Write to an empty file named `write.txt`>>> fputs.fputs("Real Python!","write.txt")13>>> withopen("write.txt","r")asf:>>> print(f.read())'Real Python!' Your function performs as expected! You pass a string "Real Python!" and a file to write this string to, write.txt. The call to fputs() returns the number of bytes written to the file. You can verify this by printing the contents of the file.
Also recall how you passed certain arguments to the PyModuleDef and PyMethodDef structures. You can see from this output that Python has used these structures to assign things like the function name and docstring.
With that, you have a basic version of your module ready, but there’s a lot more that you can do! You can improve your module by adding things like custom exceptions and constants.
Raising Exceptions
Python exceptions are very different from C++ exceptions. If you want to raise Python exceptions from your C extension module, then you can use the Python API to do so. Some of the functions provided by the Python API for exception raising are as follows:
| Function | Description |
|---|
PyErr_SetString(PyObject *type,
const char *message) | Takes two arguments: a PyObject * type argument specifying the type of exception, and a custom message to display to the user |
PyErr_Format(PyObject *type,
const char *format) | Takes two arguments: a PyObject * type argument specifying the type of exception, and a formatted custom message to display to the user |
PyErr_SetObject(PyObject *type,
PyObject *value) | Takes two arguments, both of type PyObject *: the first specifies the type of exception, and the second sets an arbitrary Python object as the exception value |
You can use any of these to raise an exception. However, which to use and when depends entirely on your requirements. The Python API has all the standard exceptions pre-defined as PyObject types.
Raising Exceptions From C Code
While you can’t raise exceptions in C, the Python API will allow you to raise exceptions from your Python C extension module. Let’s test this functionality by adding PyErr_SetString() to your code. This will raise an exception whenever the length of the string to be written is less than 10 characters:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&fd)){ 7 returnNULL; 8 } 9 10 if(strlen(str)<10){11 PyErr_SetString(PyExc_ValueError,"String length must be greater than 10");12 returnNULL;13 }14 15 fp=fopen(filename,"w");16 bytes_copied=fputs(str,fp);17 fclose(fp);18 19 returnPyLong_FromLong(bytes_copied);20 }Here, you check the length of the input string immediately after you parse the arguments and before you call fputs(). If the string passed by the user is shorter than 10 characters, then your program will raise a ValueError with a custom message. The program execution stops as soon as the exception occurs.
Note how method_fputs() returns NULL after raising the exception. This is because whenever you raise an exception using PyErr_*(), it automatically sets an internal entry in the exception table and returns it. The calling function is not required to subsequently set the entry again. For this reason, the calling function returns a value that indicates failure, usually NULL or -1. (This should also explain why there was a need to return NULL when you parse arguments in method_fputs() using PyArg_ParseTuple().)
Raising Custom Exceptions
You can also raise custom exceptions in your Python C extension module. However, things are a bit different. Previously, in PyMODINIT_FUNC, you were simply returning the instance returned by PyModule_Create and calling it a day. But for your custom exception to be accessible by the user of your module, you need to add your custom exception to your module instance before you return it:
staticPyObject*StringTooShortError=NULL;PyMODINIT_FUNCPyInit_fputs(void){/* Assign module value */PyObject*module=PyModule_Create(&fputsmodule);/* Initialize new exception object */StringTooShortError=PyErr_NewException("fputs.StringTooShortError",NULL,NULL);/* Add exception object to your module */PyModule_AddObject(module,"StringTooShortError",StringTooShortError);returnmodule;}As before, you start off by creating a module object. Then you create a new exception object using PyErr_NewException. This takes a string of the form module.classname as the name of the exception class that you wish to create. Choose something descriptive to make it easier for the user to interpret what has actually gone wrong.
Next, you add this to your module object using PyModule_AddObject. This takes your module object, the name of the new object being added, and the custom exception object itself as arguments. Finally, you return your module object.
Now that you’ve defined a custom exception for your module to raise, you need to update method_fputs() so that it raises the appropriate exception:
1 staticPyObject*method_fputs(PyObject*self,PyObject*args){ 2 char*str,*filename=NULL; 3 intbytes_copied=-1; 4 5 /* Parse arguments */ 6 if(!PyArg_ParseTuple(args,"ss",&str,&fd)){ 7 returnNULL; 8 } 9 10 if(strlen(str)<10){11 /* Passing custom exception */12 PyErr_SetString(StringTooShortError,"String length must be greater than 10");13 returnNULL;14 }15 16 fp=fopen(filename,"w");17 bytes_copied=fputs(str,fp);18 fclose(fp);19 20 returnPyLong_FromLong(bytes_copied);21 }After building the module with the new changes, you can test that your custom exception is working as expected by trying to write a string that is less than 10 characters in length:
>>>>>> importfputs>>> # Custom exception>>> fputs.fputs("RP!",fp.fileno())Traceback (most recent call last):
File "<stdin>", line 1, in <module>fputs.StringTooShortError: String length must be greater than 10 When you try to write a string with fewer than 10 characters, your custom exception is raised with a message explaining what went wrong.
Defining Constants
There are cases where you’ll want to use or define constants in your Python C extension module. This is quite similar to how you defined custom exceptions in the previous section. You can define a new constant and add it to your module instance using PyModule_AddIntConstant():
PyMODINIT_FUNCPyInit_fputs(void){/* Assign module value */PyObject*module=PyModule_Create(&fputsmodule);/* Add int constant by name */PyModule_AddIntConstant(module,"FPUTS_FLAG",64);/* Define int macro */#define FPUTS_MACRO 256/* Add macro to module */PyModule_AddIntMacro(module,FPUTS_MACRO);returnmodule;}This Python API function takes the following arguments:
- The instance of your module
- The name of the constant
- The value of the constant
You can do the same for macros using PyModule_AddIntMacro():
PyMODINIT_FUNCPyInit_fputs(void){/* Assign module value */PyObject*module=PyModule_Create(&fputsmodule);/* Add int constant by name */PyModule_AddIntConstant(module,"FPUTS_FLAG",64);/* Define int macro */#define FPUTS_MACRO 256/* Add macro to module */PyModule_AddIntMacro(module,FPUTS_MACRO);returnmodule;}This function takes the following arguments:
- The instance of your module
- The name of the macro that has already been defined
Note: If you want to add string constants or macros to your module, then you can use PyModule_AddStringConstant() and PyModule_AddStringMacro(), respectively.
Open up the Python interpreter to see if your constants and macros are working as expected:
>>>>>> importfputs>>> # Constants>>> fputs.FPUTS_FLAG64>>> fputs.FPUTS_MACRO256
Here, you can see that the constants are accessible from within the Python interpreter.
Testing Your Module
You can test your Python C extension module just as you would any other Python module. This can be demonstrated by writing a small test function for pytest:
importfputsdeftest_copy_data():content_to_copy="Real Python!"bytes_copied=fputs.fputs(content_to_copy,'test_write.txt')withopen('test_write.txt','r')asf:content_copied=f.read()assertcontent_copied==content_to_copyIn the test script above, you use fputs.fputs() to write the string "Real Python!" to an empty file named test_write.txt. Then, you read in the contents of this file and use an assert statement to compare it to what you had originally written.
You can run this test suite to make sure your module is working as expected:
$ pytest -q
test_fputs.py [100%]1 passed in 0.03 seconds
For a more in-depth introduction, check out Getting Started With Testing in Python.
Considering Alternatives
In this tutorial, you’ve built an interface for a C library function to understand how to write Python C extension modules. However, there are times when all you need to do is invoke some system calls or a few C library functions, and you want to avoid the overhead of writing two different languages. In these cases, you can use Python libraries such as ctypes or cffi.
These are Foreign Function libraries for Python that provide access to C library functions and data types. Though the community itself is divided as to which library is best, both have their benefits and drawbacks. In other words, either would make a good choice for any given project, but there are a few things to keep in mind when you need to decide between the two:
The ctypes library comes included in the Python standard library. This is very important if you want to avoid external dependencies. It allows you to write wrappers for other languages in Python.
The cffi library is not yet included in the standard library. This might be a dealbreaker for your particular project. In general, it’s more Pythonic in nature, but it doesn’t handle preprocessing for you.
For more information on these libraries, check out Extending Python With C Libraries and the “ctypes” Module and Interfacing Python and C: The CFFI Module.
Note: Apart from ctypes and cffi, there are various other tools available. For instance, you can also use swig and boost::Py.
Conclusion
In this tutorial, you’ve learned how to write a Python interface in the C programming language using the Python API. You wrote a Python wrapper for the fputs() C library function. You also added custom exceptions and constants to your module before building and testing it.
The Python API provides a host of features for writing complex Python interfaces in the C programming language. At the same time, libraries such as cffi or ctypes can lower the amount of overhead involved in writing Python C extension modules. Make sure you weigh all the factors before making a decision!
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]