This article was published at Create your own Telegram bot with Django on Heroku – Part 10 – Creating a view for your bot’s webhook .
If you are reading this on any other page, which is not some “planet” or aggregator, you are reading stolen content. Please read this article at its source, which is linked before to ensure to get the best reading experience; thank you! ❤
![Django_Pony]()
In the previous part of this series, we created another database model named
Message
to hold the message-data from our
Telegram– bot. I also explained the process of defining a SQL schema using a
Django model, what to consider during that phase and how to bring the
Django’s model field reference docs to a good use during that process. Last but not least, we learned what a
Heroku“
One-Off Dyno” is and how it can be used to execute administrative tasks on our production site like applying outstanding migrations to a database.
This time, I will provide you with the last piece of the puzzle to make your bot available to the world. You will learn how to write and wire the Python code to actually use all that we have prepared so far. At the end of this part, your bot will be able to receive and store each message sent to it by registered users. And since it’s already more than a month since I published the previous article in this series, let’s not waste any more time and jump right in!
A few more details on what we will do today
How to link the outside world (Telegram servers) with your bot’s code and data(base) now? Actually, with Django, that’s quite easy. But if you have never done something like this, you might feel a little lost here.
By now, you have already achieved to:
- … register a Telegram bot using “BotFather“, the official interface provided by Telegram to register bots for their service.
- … create a Django project to start your work in.
- … prepare your project to be easily repeatable by creating a
virtualenv
and a Pipenv
file and thus prepared it to be deployed to a containerized environment. - … register an account at your preferred code-hosting provider (Heroku, if you followed the recommendations of this guide).
- … register a project with your hosting provider to hold your Django project’s code, served by a Git remote and hook.
- … register a new app for your bot in the Django project.
- … create a database and configured your remotely deployed Django application to utilize it.
- … design your database models to hold the data needed from Telegram messages for your bot’s purpose.
- … applied the migrations, which are created from your models definitions, to your production code hosting database.
See? This is already a hell of a lot of complicated things! Managing to get this far is already a huge success! And since I did not receive a single question about anything from my previous articles of this series, you all did manage to achieve all of this successfully, didn’t you? ![😋]()
Great!
So, the last missing piece we have left in front of us is somehow bringing all these efforts together by creating a view.
Linking the outside world and your bot
OK, given the fact that we did not progress for more than a month with this project in the meantime (sorry for that, seriously ![😢]() ), let’s first talk about what it is that we are trying to achieve next. Personally, when I’ve got hit by the “Developer’s block” (which happens more commonly the more time I let pass before I sit down and continue with a project), it helps me to form an easy yet explicit sentence, describing the task at hand.
), let’s first talk about what it is that we are trying to achieve next. Personally, when I’ve got hit by the “Developer’s block” (which happens more commonly the more time I let pass before I sit down and continue with a project), it helps me to form an easy yet explicit sentence, describing the task at hand.
For that, I’m trying not to think about what it was that I’ve done last time or the details of my initial plan or something; it helps to establish a habit of not interrupting your work in the middle of something, really since this allows you to do so and not having to re-think where you left off! Always try to establish something SCRUM evangelists would call a “potentially shippable artifact“, meaning: Something that could be added to a product already running in production without breaking anything but providing a new set of functionality or a good foundation to implement these in subsequent releases, at least.
In this project, that sentence could be something like:
Create an interface (called “Webhook“), which the Telegram bot can connect to and submit messages it received.
In the Django world, this pretty perfectly describes a view. Cited from the very first sentences of the Django views docs:
A view function, or view for short, is simply a Python function that takes a Web request and returns a Web response. This response can be the HTML contents of a Web page, or a redirect, or a 404 error, or an XML document, or an image . . . or anything, really. The view itself contains whatever arbitrary logic is necessary to return that response. This code can live anywhere you want, as long as it’s on your Python path. There’s no other requirement–no “magic”, so to speak. For the sake of putting the code somewhere, the convention is to put views in a file called views.py, placed in your project or application directory.
So, let’s fire up our preferred editor and open the file
bot/views.py
(since we will make all our modifications inside our “bot”-application directory).
So far, only our “
Hello World“-static content-view called
index
is in there. Another interesting file in this context is
bot/urls.py
; open that in your editor as well.
So … let’s do the most obvious things first before we are diving into the logic. Think of a name for your view and create the basic skeleton for it in your
bot/views.py
file. The name is absolutely irrelevant; to prove that, I’ll continue with this called “
talkin_to_me_bruh“. You can come up with pretty much any name here as long as it’s unique. This won’t define the URL-path which the outside world is seeing or anything; it’s just the internal name of a function. So, my skeleton for “
talkin_to_me_bruh” will look like this:
from django.http import HttpResponse
def talkin_to_me_bruh(request):
# please insert magic here
return HttpResponse('OK')If we define a URLconf for this (which we will do in the next step) and navigate to this without inserting some magic at the “please insert magic here” marker, Django would nevertheless render an appropriate HTTP answer, containing the string
OK
in its body.
… why trust me – I’m not a trustworthy person at all
![😈]()
, so let’s just do it (not sponsored by
Nike)! Add this URLconf to your
bot/urls.py
, resulting in every request being processed by our “
talkin_to_me_bruh“-view:
from django.urls import path
from . import views
urlpatterns = [
path('hello/', views.index),
path('hook/', views.talkin_to_me_bruh),
]Save these two changes, add and commit it to your Git repository and push that to your heroku remote:
(dtbot-hT9CNosh) ~/dtbot $ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: bot/urls.py
modified: bot/views.py
no changes added to commit (use "git add" and/or "git commit -a")
(dtbot-hT9CNosh) ~/dtbot $ git add bot/urls.py bot/views.py
(dtbot-hT9CNosh) ~/dtbot $ git commit -m "Added hook/ URLconf and talkin_to_me_bruh - view"
[master 5d4a55f] Added hook/ URLconf and talkin_to_me_bruh - view
2 files changed, 6 insertions(+)
(dtbot-hT9CNosh) ~/dtbot $ git remote -v
heroku https://git.heroku.com/dry-tundra-61874.git (fetch)
heroku https://git.heroku.com/dry-tundra-61874.git (push)
(dtbot-hT9CNosh) ~/dtbot $ git push heroku master
Counting objects: 5, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 614 bytes | 0 bytes/s, done.
Total 5 (delta 3), reused 0 (delta 0)
remote: Compressing source files... done.
remote: Building source:
remote:
remote: -----> Python app detected
remote: -----> Found python-3.6.6, removing
remote: -----> Installing python-3.6.7
remote: -----> Installing pip
remote: -----> Installing dependencies with Pipenv 2018.5.18…
remote: Installing dependencies from Pipfile.lock (ce9952)…
remote: -----> $ python manage.py collectstatic --noinput
remote: /app/.heroku/python/lib/python3.6/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
remote: """)
remote: 119 static files copied to '/tmp/build_ad22ed4ba6e462d165694bcc89345170/staticfiles', 375 post-processed.
remote:
remote: -----> Discovering process types
remote: Procfile declares types -> web
remote:
remote: -----> Compressing...
remote: Done: 64.1M
remote: -----> Launching...
remote: Released v13
remote: https://dry-tundra-61874.herokuapp.com/ deployed to Heroku
remote:
remote: Verifying deploy... done.
To https://git.heroku.com/dry-tundra-61874.git
a4de3de..5d4a55f master -> master
(dtbot-hT9CNosh) ~/dtbot $Awesome! Navigating to https://dry-tundra-61874.herokuapp.com/bot/hook/ (make sure to use your individual Heroku-subdomain instead of “dry-tundra-61874” when following along!) results in a simple “OK” in the browser:
![talkin_to_me_bruh Hook OK]()
Obviously, our browser did not submit anything which could end up in the
request
object, handed over to
talkin_to_me_bruh()
. But even if it had thrown gigabytes of data at it, since we haven’t added any logic to process that data, it would always result in the same, shallow “OK”.
But hey: We just passed another milestone! We now have a place to add our Python code and do whatever we want with the input provided!
![🎊]()
Let’s celebrate with a whole new paragraph
![🍾]()
Learning to interact with our models
So – in the first iteration of our logic, we want to simply write the message received by our bot to the database. But only, if the sender of that message is stored in the
bot.User
model / the
bot_user
table, as our model is ending up as in the database, finally. Let’s review that model for a moment:
class User(models.Model):
user_id = models.IntegerField(unique=True, primary_key=True)
first_name = models.CharField(max_length=64)
last_name = models.CharField(max_length=64)
def __str__(self):
return f'{self.first_name} {self.last_name}'We have 3 columns here:
user_id
, being a unique IntegerField and acting as the primary key for our model.first_name
, being a simple CharField, storing text up to a length of 64 characters.last_name
, also being a simple CharField consisting of up to 64 characters.
In part 8 of this series, we created this model. After having had a closer look at the JSON format being used for message exchange by Telegram, we found out that each Telegram user is identified by a number unique in the whole Telegram infrastructure. The logic we are about to implement here is to add YOUR Telegram user id to that table, enabling you to send messages to your bot that become stored in its database. Messages from any other user id will be discarded.
Thus, before we implement any line of code, first add that user id of yours to your
bot_user
table either using the
Django Admin backend in your browser or by using Python code for it
![🐍]()
. Since the first variant is quite obvious and also was shown in past parts of this article series, I will now show the one using Python code.
![⚠]() Attention: Make sure you fill the proper database in the following steps! I recommend to first do this in your development database, which is when the following steps are not executed in your Heroku – Environment, the SQLite3 one in your Django project folder, named
Attention: Make sure you fill the proper database in the following steps! I recommend to first do this in your development database, which is when the following steps are not executed in your Heroku – Environment, the SQLite3 one in your Django project folder, named
db.sqlite3
by default.
But even before that, figure out your Telegram ID. The easiest way I can imagine is to search for “jsondumpbot” in Telegram, select the (only) match from the list of results and hit “Start” at the bottom of that chat:
![Telegram search for]()
![Telegram conversation with]()
The pixelated areas are showing your Telegram ID. Let’s assume this is
123456789
for now; please make sure to use your own instead in the following examples.
To fire up a full-fledged Python shell which has all our Django-requirements pre-imported, type
python manage.py shell
at the command line prompt of your activated virtualenv:
(dtbot-hT9CNosh) ~/dtbot $ python manage.py shell
Python 3.6.5 (default, Apr 25 2018, 12:19:38)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>>
First, we need to import our
User
model:
>>> from bot.models import User
>>>
Now, we can do all the fancy things with it already that we will use for our logic in Django as well: The whole wide and shiny world of Django’s database API. For example: With the following, I show some cool moves to find out about existing records, like listing all records in our
User
model, selecting a specific one based on it’s
first_name
and
last_name
records and displaying the value from that record’s
user_id
:
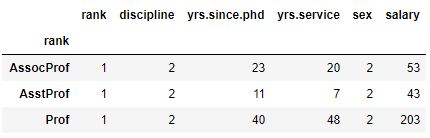
>>> User.objects.all()
<QuerySet [<User: Marc Richter>]>
>>> u1 = User.objects.all()[0]
>>> u1
<User: Marc Richter>
>>> u1.user_id
2
>>> marc = User.objects.get(first_name="Marc", last_name="Richter")
>>> marc.user_id
2
>>> marc is u1
False
>>> marc == u1
True
>>>
… wait a minute – “2”? That’s obviously not my real Telegram user id, but one fantasy-value I did choose when playing around with the Admin backend to provide a valid integer value.
Let’s change that to my “real” user id (
123456789
).
After that, let’s add a whole new record for a user named “
Alucard Țepeș“, identified by Telegram ID
666666666
:
>>> marc = User.objects.get(user_id=2)
>>> marc.user_id
2
>>> marc.user_id = 123456789
>>> marc.save()
>>> alucard = User(first_name="Alucard", last_name="Țepeș", user_id=666666666)
>>> alucard.save()
>>> marc.user_id
123456789
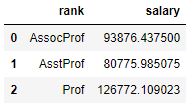
>>> User.objects.all()
<QuerySet [<User: Marc Richter>, <User: Marc Richter>, <User: Alucard Țepeș>]>
There you are – all set! … wait a second! Why are there two records for “Marc Richter” now all of a sudden?? Django’s manual states clearly that records are changed this way! So, why is there one record with
user_id
“2” and another with “123456789” now?
The answer to this is, that since
user_id
is the primary key for this record and needs to stay unique, this is a bit of a special case. In the SQL – background Django is updating a row that is identified by its primary key. So, since this key itself changes, the query creates a new one instead. The same thing happens if you try to change this using the Admin backend to change the user_id field, by the way.
Better: Not change primary keys once they were stored to avoid unexpected behaviors like this!
![🤓]()
With just these few lines of code, you managed to alter an existing record and to create a whole new one. Without having to type a single line of SQL or even using different dialects of SQL, based upon the database backend you are using. Thanks to Django’s database abstraction layer, this code is the same no matter what database backend you are using in your projects! ![👍]()
Now, these two Telegram users are registered in our
bot_user
table; feel free to validate this using the Admin backend: Start a local server by executing
python manage.py runserver
and navigate your browser to http://127.0.0.1:8000/admin/. Log in using your superuser you created previously and navigate to your “
bot > User” section; you should find the changed and created records there:
![Django Admin Backend User Alucard]()
That’s how easy it is to deal with databases and its records in Django! So, technically this enables us to:
- validate if a user id from a received message is in our
bot_user
table - check if a received
update_id
is already stored in the bot_message
table or not - add records to both of these
Basically, all that is missing is to extract the JSON structure from that
request
element received and we are good to go! We will cover this only quite briefly for now to not extend this article too much. If you want to dig in deeper to that topic, check out Django’s excellent docs once more on
Request and response objects.
When a page is requested, Django creates an
HttpRequest object that contains metadata about the request; like the scheme of the request (http or https), the path of the requested page (eg. “/music/bands/the_beatles/”) and so on. Then Django loads the appropriate view (based on the URLconf) and passes the
HttpRequestas the first argument to the view function. So: This argument can be named anything you like it to be named, Django will always pass its
HttpRequest object as this first parameter to your view function. Even though using a different name for this first argument is technically possible and completely valid, naming this
request
is a well-established convention that should not be changed without a good reason to not confuse other developers who might need to review or change your code in the future (when you need to provide code samples to the members of your favorite support forum, for example).
So, we know that we just have to expect JSON structures for this hook. Let’s first write a try…except-Block loading valid JSON structures or discarding everything else by adding these first lines into our
# please insert magic here
– placeholder of our
talkin_to_me_bruh()
view function:
from django.http import HttpResponse
import json
def talkin_to_me_bruh(request):
# please insert magic here
try:
json_message = json.loads(request.body)
except json.decoder.JSONDecodeError as err:
return HttpResponse(str(err))
return HttpResponse('OK')Given a valid JSON data structure, we now have a standard Python object loaded to
json_message
; if you have never worked with the
json
module before, please refer to
its official docs (especially the
conversion table) to learn about the data structures we might end up with here, in case you want to know something I have not covered here.
Let’s make our life a bit easier and artificially load one of the examples I provided once earlier already in part 9 into a Python session for inspection:
{"message": {"chat": {"first_name": "Marc",
"id": 123456789,
"last_name": "Richter",
"type": "private"},
"date": 1533248578,
"from": {"first_name": "Marc",
"id": 123456789,
"is_bot": false,
"language_code": "de",
"last_name": "Richter"},
"message_id": 5,
"text": "Test2"},
"update_id": 941430901}If you want to follow along, copy this JSON structure and save it to a text file in your project folder (or anywhere else, wherever you find it from your Python console). For my example, I saved it to a file called
json_file.txt
:
(dtbot-hT9CNosh) ~/dtbot $ python
Python 3.6.5 (default, Apr 25 2018, 12:19:38)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import json
>>> with open('json_file.txt', 'r') as f:
... json_object = json.loads(f.read())
...
>>> json_object
{'message': {'chat': {'first_name': 'Marc', 'id': 123456789, 'last_name': 'Richter', 'type': 'private'}, 'date': 1533248578, 'from': {'first_name': 'Marc', 'id': 123456789, 'is_bot': False, 'language_code': 'de', 'last_name': 'Richter'}, 'message_id': 5, 'text': 'Test2'}, 'update_id': 941430901}
>>> type(json_object)
<class 'dict'>
>>>Alright, so a
dict
it is. Our
json_message
object is containing a dictionary. That we can work with!
… do I know you?
Let’s add the code which checks if the user id we received the message from is registered in our database and call that function
_is_user_registered
. If yes, have it return “True”, if not, have it return “False”:
from django.http import HttpResponse
from bot.models import User
import json
def talkin_to_me_bruh(request):
# please insert magic here
try:
json_message = json.loads(request.body)
except json.decoder.JSONDecodeError as err:
return HttpResponse(str(err))
def _is_user_registered(user_id: int) -> bool:
if User.objects.filter(user_id__exact=user_id).count() > 0:
return True
return False
return HttpResponse('OK')I think I’ve heard that before …
Next, let’s add a function that checks if the update id of the message is already existing in the table
bot_message
. Let’s call that
_update_id_exists
and just like
_is_user_registered
, it shall return “True” if it exists and “False” of not:
from django.http import HttpResponse
from bot.models import User, Message
import json
def talkin_to_me_bruh(request):
# please insert magic here
try:
json_message = json.loads(request.body)
except json.decoder.JSONDecodeError as err:
return HttpResponse(str(err))
def _is_user_registered(user_id: int) -> bool:
if User.objects.filter(user_id__exact=user_id).count() > 0:
return True
return False
def _update_id_exists(update_id: int) -> bool:
if Message.objects.filter(update_id__exact=update_id).count() > 0:
return True
return False
return HttpResponse('OK')You don’t say… Let me write that one down!
Finally, let’s write a function which adds the content of the JSON structure to our
bot_message
table, in case these former two functions returned the expected results (
_is_user_registered
==
True
and
_update_id_exists
==
False
):
from django.http import HttpResponse, HttpResponseBadRequest
from bot.models import User, Message
from datetime import datetime
import json
from django.views.decorators.csrf import csrf_exempt
def index(request):
return HttpResponse("Hello, world. This is the bot app.")
@csrf_exempt
def talkin_to_me_bruh(request):
# please insert magic here
try:
json_message = json.loads(request.body)
except json.decoder.JSONDecodeError as err:
return HttpResponse(str(err))
def _is_user_registered(user_id: int) -> bool:
if User.objects.filter(user_id__exact=user_id).count() > 0:
return True
return False
def _update_id_exists(update_id: int) -> bool:
if Message.objects.filter(update_id__exact=update_id).count() > 0:
return True
return False
def _add_message_to_db(json_dict: dict) -> (None, True):
try:
sender_id = json_dict['message']['from'].get('id')
sender_object = User.objects.filter(user_id__exact=sender_id).get()
update_id = json_dict.get('update_id')
message_text = json_dict['message'].get('text')
message_date = json_dict['message'].get('date')
except KeyError:
return None
if None in (sender_id, update_id, message_text, message_date):
return None
if _update_id_exists(update_id):
return True
if _is_user_registered(sender_id):
try:
Message(
update_id=int(update_id),
text=str(message_text),
sender=sender_object,
date=datetime.fromtimestamp(int(message_date)),
).save()
return True
except (KeyError, ValueError):
return None
else:
raise ValueError('Sender is rejected')
try:
result = _add_message_to_db(json_message)
except ValueError as e:
return HttpResponseBadRequest(str(e))
if result is True:
return HttpResponse('OK')
else:
return HttpResponseBadRequest('Malformed or incomplete JSON data received')That’s quite a lot that got changed in one go! ![😱]() Let’s go through it, section by section.
Let’s go through it, section by section.
First, we changed the imports; in case we do receive malicious JSON data or a message from an unregistered user id, we need to create an Error-Response object; that’s why we import
HttpResponseBadRequest
which does exactly that.
For the
date
parameter of the
Message
model, we need to generate a
datetime
– object; so we are importing it now.
The third change to the imports is a bit tricky … By default, Django tries to check for and verify a CSRF (Cross-Site-Request-Forgery) token for all POST requests (for an explanation of what CSRF is, please refer to
Wikipedias article on it). This is a good security practice when it comes to forms and so on, but for public APIs, where we want these kinds of accesses, this is rendering our view useless. That’s what Django’s
csrf_exempt
decorator is for, so we import it here and add it to our
talkin_to_me_bruh
view function in line 12.
At the beginning of
_add_message_to_db
, we introduce a try…except block which tries to extract the different elements from the provided dictionary. If any of these raises a
KeyError
or the value is not provided, the function returns
None
, signaling the calling section that we could not successfully extract the values and store the message to the database. Since we know what the Telegram JSON data is formatted like we can make this assumption of “
Malformed or incomplete JSON data received” if this fails.
Next, with
_update_id_exists
we check if the update id already exists in the database. If it is, we return
True
here, which is not entirely true, since we, in fact, did not end up writing to the database successfully, but the result is the same and the record is available already. So, this is supposed to be OK, I guess.
If we come to the section where
_is_user_registered
is called this means that we could extract all necessary data from the request’s body and that the update id was not yet found in the database. So, we are dealing with a valid update here, which potentially needs to be written to the database. But not before we validated that the sender of the message is a registered user.
This,
_is_user_registered
is taking care for. If this returns
False
, we raise an exception here, which is captured and leads to having an
HttpResponseBadRequest
object returned, stating “
Sender is rejected“.
If
_is_user_registered
returns
True
, we are trying to create and save this new record in one go, just like we did when we played around with this in Django’s Python shell before (please note that we imported
Message
from
bot.models
as well).
With all arguments to
Message
, there is not much of a surprise, I think. The only thing worth mentioning is the
date
argument since it takes a datetime object. That’s just the way Django’s
DateTimeField
works. This is explicitly mentioned and explained in the
DateTimeField section of the
Model field reference. There’s no other chance than to look up this kind of things in the first time.
Also, it is important to note that the
sender
argument takes an instance of the corresponding
User
object. This is because
sender
is a foreign key in our model definition and this is how this works in Django.
If this succeeds, our function returns
True
, signaling to have written the message to the database successfully.
With the if-statement following this function definition, we decide if we either return an
HttpResponse
object stating “
OK” or an
HttpResponseBadRequest
object stating “
Malformed or incomplete JSON data received“.
And – that’s basically it! Let’s give this a final test-drive before we deploy this to production.
Test-driving our changes ![🏎]()
By now, there should be made all changes to the code which we discussed already and there should be a user registered to your
User
model’s tables that has the user id “123456789” assigned.
Next, we will start the build-in HTTP server of Django:
(dtbot-hT9CNosh) ~/dtbot $ python manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
December 05, 2018 - 15:35:21
Django version 2.1.2, using settings 'dtbot.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Remember that we saved that JSON data structure to a file called
json_file.txt
? We will now use
curl
to send that towards our webhook to simulate the receiving of a real message from Telegram:
(dtbot-hT9CNosh) ~/dtbot $ curl --header "Content-Type: application/json" --request POST --data "$(cat json_file.txt)" http://127.0.0.1:8000/bot/hook/
OK(dtbot-hT9CNosh) ~/dtbot $ curl --header "Content-Type: application/json" --request POST --data "$(cat json_file.txt)" http://127.0.0.1:8000/bot/hook/
OK(dtbot-hT9CNosh) ~/dtbot $
(dtbot-hT9CNosh) ~/dtbot $
Noice that small “OK” in front of our prompt? That’s the response curl receives from our bot. Executing it a second time (sending the same message towards our hook) appears to be exactly the same for the outside world. Internally, our code noticed that a record with that update id is already there and directly returned that
HttpResponse
object.
Let’s validate this by looking at the database in the Admin backend:
![dtbot - Django's message table containing 1 record]()
Indeed, just one record. Let’s edit the text of that in the Admin backend by something else and then re-run that curl command. If we are correct, our hook should still feedback success but not change that message record or add a new one.
For me, this works. So should your code.
Next, change the update id inside the
json_file.txt
and re-execute the curl command. This time, a second message should have been added to your Message database (validate in the Admin backend once more).
This works for me as well.
Ship it! ![🛳]()
Congratulations! By now, you should be able to deploy your code to your production site by commiting the changes to your Git repo and push the changes to heroku remote.
Since we did not change any model this time, we do not need to make and apply migrations and your bot should be able to receive messages, immediately (remember to register your users with their proper user ids to the production bot’s database!). You just learned how to register new users by several ways and validate the functionality of your bot as well. Use the force, Luke Dude! ![🤣]()
One last thing to make sure is to set your bot to Hook-Mode again in case you had switched that in the meantime. Please see part 4 of this series for a description how to do this.
That’s it! Apart from the fine-tuning and the fact that your bot isn’t really doing stuff besides storing messages it receives right now, your Telegram bot is more or less ready by now! You can let this stay in Hook-Mode from now on, already. In the next parts we will add a bit of functionality to the bot.
Outlook for the next part of the series
You just learned how to write a view that serves as a proper Webhook for your Telegram bot. Also, you learned how to interact with the database from within your code and the Python shell and how to find, set and update records. Finally, you enabled your project to receive and store messages. So you can send whatever text messages you’d like to store to your Telegram bot from now on.
In the next article of this series, we will add a bit more functionality to the bot. Have it answer to the messages it receives, for example. Also, since this is about to become a bot to store your cash spendings, we will add pattern recognition logic to enable the bot to sum and track your spendings.
Also, when we saw that we ended up with a doubled record in our User table, we realized that the current string representation of the records for that table is not really helpful, displaying the same lines containing “Marc Richter” twice. Having displayed the same name twice made it hard to identify the correct record for deletion. We will change that as well and by that see how to make changes like this to a database which has already records stored to it, using Django’s workflows.
If you liked or disliked this article, I’d love to read that in the comments!
![🐍]() Enjoy coding!
Enjoy coding! ![❤]()
Born in 1982, Marc Richter is an IT enthusiastic since 1994. He became addicted when he first put hands on their family’s pc and never stopped investigating and exploring new things since then.
He is married to Jennifer Richter and proud father of two wonderful children, Lotta and Linus.
His current professional focus is DevOps and Python development.
An exhaustive bio can be found at this blog post.
Found my articles useful? Maybe you would like to support my efforts and give me a tip then?
Marc Richter's personal site - About Linux, programming in Python and Music



 Found the duplicate item
Found the duplicate item



 ), let’s first talk about what it is that we are trying to achieve next. Personally, when I’ve got hit by the “
), let’s first talk about what it is that we are trying to achieve next. Personally, when I’ve got hit by the “ , so let’s just do it (not sponsored by
, so let’s just do it (not sponsored by 
 Let’s celebrate with a whole new paragraph
Let’s celebrate with a whole new paragraph 
 . Since the first variant is quite obvious and also was shown in past parts of this article series, I will now show the one using Python code.
. Since the first variant is quite obvious and also was shown in past parts of this article series, I will now show the one using Python code. Attention: Make sure you fill the proper database in the following steps! I recommend to first do this in your development database, which is when the following steps are not executed in your Heroku – Environment, the SQLite3 one in your Django project folder, named
Attention: Make sure you fill the proper database in the following steps! I recommend to first do this in your development database, which is when the following steps are not executed in your Heroku – Environment, the SQLite3 one in your Django project folder, named 




 Let’s go through it, section by section.
Let’s go through it, section by section.