>>> set() == frozenset()
True
>>> [] == ()
False
True
>>> [] == ()
False
This is working out well so far. I think driving more attention at the things that are going on can only be good. Also to explain will always help. It also kind of motivates me a bit.
Also as part of my communications offensive, I am using my Twitter account more regularily. I used to highlight important fixes, or occasionally releases of some importance there. I will continue to do only important stuff there, but with more regularity.
And I noticed in the past, even when I do not post, followers makes me happy. So here you go:
This continues TWN #2 where I promised to speak more of it, and this is the main focus of my work on Nuitka right now.
Brief summary, context switches were how this was initially implemented. The main reason being that for C++ there never was going to be a way to save and restore state in the middle of an expression that involves constructors and destructors.
Fast forward some years, and C-ish entered the picture. No objects are used anymore, and Nuitka is purely C11 now, which has convinience of C++, but no objects. Instead goto is used a lot already. So everytime an exception occurs, a goto is done, every time a branch is done, a loop exit or continue, you get it, another goto.
But so far, all Python level variables of a frame live on that C stack still, and the context switch is done with functions that swap stack. That is fast, but the imporant drawback is that it takes more memory. How deep of a stack will we need? And we can use really many, if you imagine a pool of 1000 coroutines, that quickly become impossible to deal with.
So, the new way of doing this basically goes like this:
defg():yield1yield2
This was some far becoming something along this lines:
PyObject*impl_g(NuitkaGenerator*generator){YIELD(const_int_1);YIELD(const_int_2);PyErr_SetException(StopIteration);returnNULL;}
The YIELD in there was basically doing the switching of the stacks and for the C code, it looked like a normal function call.
In the new approach, this is done:
PyObject*impl_g(NuitkaGenerator*generator){switch(generator->m_resume_point){case1:gotoresume_1;case2:gotoresume_2;}generator->m_yielded=const_int_1;generator->resume_point=1returnNULL;resume_1:generator->m_yielded=const_int_2;generator->resume_point=2returnNULL;resume_2:PyErr_SetException(StopIteration);returnNULL;}
As you can see, the function has an initial dispatcher. Resume point 0 means we are starting at the top. Then every yield results in a function return with an updated resume point.
I experimented with this actually a long time ago, and experimental code was the result that remained in Nuitka. The problem left to solve was to store the variables that would normally live on the stack, in a heap storage. That is what I am currently working on.
This leads me to "heap storage", which is what I am currently working on and will report on next week. Once that is there, goto generators can work, and will become the norm. Until then, I am refactoring a lot to get accesses to variable go through proper objects that know their storage locations and types.
So there have been 2 more hotfixes. One was to make the enum and __new__ compatibility available that I talked about last week in TWN #2 <./nuitka-this-week-2.html#python3-enumerators> coupled with a new minor things.
And then another one, actually important, where Python3 __annotations__ by default was the empty dictionary, but then could be modified, corrupting the Nuitka internally used one severely.
Right now I have on factory another fix for nested namespace packages in Python3 and that might become another hotfix soon.
As you know, I am following the git flow model, where it's easy to push out small fixes, and just those, on top of the last release. I tend to decide based on importance. However, I feel that with the important fixes in the hotfixes now, it's probably time to make a full release, to be sure everybody gets those.
Finishing heap storage is my top priority right now and I hope to complete the refactorings necessary in the coming week. I will also talk about how it also enables C types work next week.
Until next week then!
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2018-08-11 16:23:07 GMT
So there's a beta release of PyOpenGL 3.1.3b1 up on PyPI. It needs testing on Mac and Win64/32 if possible. You should be able to install it with:
pip install "pyopengl==3.1.3b1""pyopengl-accelerate==3.1.3b1"
The biggest change being that it should work on Python 3.7, and has the current khronos extensions included.
I've released PyFilesystem 2.1.0.
This version is the accumulation of many minor revisions, with multiple fixes, enhancements and some interesting new features. We also have nicer doc strings and Mypy compatible typing information, thanks to Martin Larralde.
If you aren't familiar with PyFilesystem, it is a common API to filesystems, whether its your hard-drive, archives, memory, FTP servers, or cloud services. The API is easier to use than the standard library, but works just about everywhere. See the Pyfilesystem Wiki for more information.
The copy, move, and mirror functionality has been extended with a workers argument, which will enable multi-threaded copies if it is set to something greater than 0. This is hugely beneficial for uploading and downloading over a network as it allows you to saturate your available bandwidth.
For instance, the following will use 4 threads to upload your projects directory to a bucket on Amazon S3.
from fs.copy import copy_fs
copy_fs('~/projects', 's3://mybucket', workers=4)
Technically this will use 5 threads to do the upload; the main threads handles the directory scanning, while 4 thread are busy uploading or downloading data.
PyFilesystem has always had good support for walking a directory tree, but in many cases this can now be replaced with globbing. Essentially globbing is like a wildcard that can match multiple components of a path.
Here's an example which uses the glob feature to recursively remove all the .pyc files from your projects directory.
I have perfectly decent syntax highlighting in my blog, but it doesn't generate flashy thumbnails.
Here is a slightly less trivial example, that counts the number of bytes stored in .git directories in your projects folder:
import fs
bytes_in_git = 0
with fs.open_fs("~/projects") as projects_fs:
for match in projects_fs.glob("**/.git/"):
with projects_fs.opendir(match.path) as git_dir:
bytes_in_git += git_dir.glob("**").count().data
print(f"{bytes_in_git} bytes in git directories")
The intentions of this post is to familiarize usage of Google APIs with Python. Google services are cool and you can build products and services around it. We will see through examples how you can use various google services such as spreadsheet, slides and drive through Python. I hope people can take ideas from the […]
The post Brief Introduction to Google APIs(Sheets, Slides, Drive) appeared first on The Tara Nights.
Masonite is an ambitious new web framework that draws inspiration from many other successful projects in other languages. In this episode Joe Mancuso, the primary author and maintainer, explains his goal of unseating Django from its position of prominence in the Python community. He also discusses his motivation for building it, how it is architected, and how you can start using it for your own projects.
The intro and outro music is from Requiem for a Fish The Freak Fandango Orchestra / CC BY-SA
Image may be NSFW.Last year I played around with using jsonschema for validating some data that I was reading into my Python programs. The API for the library was straightforward but the schema turned out to be a pretty sprawling affair: stellar-schema.json
This past weekend I started looking at adding some persistence to this program in the form of SQLAlchemy-backed data structures. To make those work right, I decided that I had to change the schema for these data file as well. Looking at the jsonschema, I realized that I was having a hard time remembering what all the schema keywords meant and how to modify the file; never a good sign! So I decided to reimplement the schema in something simpler.
At work, we use a library called voluptuous. One of the nice things about it is that the containers are Python data structures and the types are Python type constructors. So simple things can be very simple:
from voluptuous import Schema
schema = [
{'hosts': str,
'gather_facts': bool,
'tasks': [],
}
]
The unfortunate thing about voluptuous is that the reference documentation is very bad. It doesn’t have any recipe-style documentation which can teach you how to best accomplish tasks. So when you do have to reach deeper to figure out how to do something a bit more complex, you can try to find an example in the README.md (a pretty good resource but there’s no table of contents so you’re often left wondering whether what you want is documented there or not) or you might have to hunt around with google for a blog post or stackoverflow question that explains how to accomplish that. If someone else hasn’t discovered an answer already…. well, then, voluptuous may well have just the feature you need but you might never find it.
The feature that I needed today was to integrate Python-3.4’s Enum type with voluptuous. The closest I found was this feature request which asked for enum support to be added. The issue was closed with a few examples of “code that works” which didn’t quite explain all the underlying concepts to a new voluptuous user like myself. I took away three ideas:
Schema(Coerce(EnumType)) was supposed to workSchema(EnumType) was supposed to work but…Schema(EnumType) doesn’t work the way the person who opened the issue (or I) would get value from.I was still confused but at least now I had some pieces of code to try out. So here’s what my first series of tests looked like:
from enum import Enum
import voluptuous as v
# My eventual goal: data_to_validate = {"type": "one"}
MyTypes = Enum("MyTypes", ['one', 'two', 'three'])
s1 = v.Schema(MyTypes)
s2 = v.Schema(v.Coerce(MyTypes))
s1('one') # validation error (figured that would be the case from the ticket)
s1(MyTypes.one) # Works but not helpful for me
s2('one') # validation error (Thought this one would work...)
Hmm… so far, this isn’t looking too hopeful. The only thing that I got working isn’t going to help me validate my actual data. Well, let’s google for what Coerce actually does….
A short while later, I think I see what’s going on. Coerce will attempt to mutate the data given to it into a new type via the function it is given. In the case of an Enum, you can call the Enum on the actual values backing the Enum, not the symbolic labels. For the symbolic labels, you need to use square bracket notation. Square brackets are syntax for the __getitem__ magic method so maybe we can pass that in to get what we want:
MyTypes = Enum("MyTypes", ['one', 'two', 'three'])
s2 = v.Schema(v.Coerce(MyTypes))
s3 = v.Schema(v.Coerce(MyTypes.__getitem__))
s2(1) # This validates
s3('one') # And so does this! Yay!
Okay, so now we think that this all makes sense…. but there’s actually one more wrinkle that we have to work out. It turns out that Coerce only marks a value as Invalid if the function it’s given throws a TypeError or ValueError. __getitem__ throws a KeyError so guess what:
>>> symbolic_only({"type": "five"})
Traceback (most recent call last):
File "", line 1, in
File "/home/badger/.local/lib/python3.6/site-packages/voluptuous/schema_builder.py", line 267, in __call__
return self._compiled([], data)
File "/home/badger/.local/lib/python3.6/site-packages/voluptuous/schema_builder.py", line 587, in validate_dict
return base_validate(path, iteritems(data), out)
File "/home/badger/.local/lib/python3.6/site-packages/voluptuous/schema_builder.py", line 379, in validate_mapping
cval = cvalue(key_path, value)
File "/home/badger/.local/lib/python3.6/site-packages/voluptuous/schema_builder.py", line 769, in validate_callable
return schema(data)
File "/home/badger/.local/lib/python3.6/site-packages/voluptuous/validators.py", line 95, in __call__
return self.type(v)
File "/usr/lib64/python3.6/enum.py", line 327, in __getitem__
return cls._member_map_[name]
KeyError: 'five'
The code throws a KeyError instead of a voluptuous Invalid exception. Okay, no problem, we just have to remember to wrap the __getitem__ with a function which returns ValueError if the name isn’t present. Anything else you should be aware of? Well, for my purposes, I only want the enum’s symbolic names to match but what if you wanted either the symbolic names or the actual values to work (s2 or s3)? For that, you can combine this with voluptuous’s Any function. Here’s what those validators will look like:
from enum import Enum
import voluptuous as v
data_to_validate = {"type": "one"}
MyTypes = Enum("MyTypes", ['one', 'two', 'three'])
def mytypes_validator(value):
try:
MyTypes[value]
except KeyError:
raise ValueError(f"{value} is not a valid member of MyTypes")
return value
symbolic_only = v.Schema({"type": v.Coerce(mytypes_validator)})
symbols_and_values = v.Schema({"type":
v.Any(v.Coerce(MyTypes),
v.Coerce(mytypes_validator),
)})
symbolic_only(data_to_validate) # Hip Hip!
symbols_and_values(data_to_validate) # Hooray!
symbols_and_values({"type": 1}) # If this is what you *really* want
symbolic_only({"type": 1}) # If you want implementation to remain hidden
symbols_and_values({"type": 5}) # Prove that invalids are getting caught
This week we welcome Lovely ricel Banquil (AKA Banx) as our PyDev of the Week. Banx is a tester by trade and recently presented a talk at PyCon Thailand. Let’s spend some time getting to know Lovely better!
Can you tell us a little about yourself (hobbies, education, etc):
Hi! My name is Banx and I’m a Software QA Engineer for a startup in the Philippines.
I’m an avid cat lover, my favorite author is Agatha Christie ( whodunnits!!! and Hercule Poirot’s moustache :p ), I still follow the Chicago Bulls even though they suck, I love seeing the world, and I’m a nurse by profession.
Yep, you read it right. I took up Nursing in college, got my license to practice as a nurse (which I never did). Now I code and hunt for bugs, and I love every minute of it.
Image may be NSFW.
Clik here to view.
Why did you start using Python?
I started using Python because it seemed like a good first language to learn and it’s one of the languages that our team is using, which meant that I could get access to mentors who can guide me and tell me when my code sucks. Image may be NSFW.
Clik here to view.
What other programming languages do you know and which is your favorite?
I know a bit of Javascript, but haven’t really fully delved into it yet. For now I’m sticking with Python, but I’m definitely planning to continue learning Javascript before the year ends.
What projects are you working on now?
I’m currently writing tests, all using Python and pytest plugins. Also, I’m working to get my own blog up using Python and Django. (I really love Python don’t I?)
Which Python libraries are your favorite (core or 3rd party)?
The selenium library is my first love, and for some weird reason, I really love the Requests library. I’m not sure why either :p
Is there anything else you’d like to say?
One of the reasons why I love Python is also because of the Python community, which I think is very warm and supportive as a whole. I’ve been to a few Python conferences and I’ve never felt like I was an outsider in one. Sometimes I grapple with the so-called “impostor syndrome”, which stems from the fact that my background is very far from Tech, but then I see my colleagues and the Python community, all of whom have been very supportive and accepting of me, and my doubts diminish and I feel more strengthened and secure in my role in the tech industry.
Thanks for doing the interview, Banx!
This is a quick tutorial to get you start with django-crispy-forms and never look back.
Crispy-forms is a great application that gives you control over how you render Django forms, without breaking the default behavior. This tutorial is going to be tailored towards Bootstrap 4, but it can also be used with older Bootstrap versions as well as with the Foundation framework.
The main reason why I like to use it on my projects is because you can simply render a Django form using `` and it will be nicely rendered with Bootstrap 4, with very minimal setup. It’s a really life saver.
Install it using pip:
pip install django-crispy-formsAdd it to your INSTALLED_APPS and select which styles to use:
settings.py
INSTALLED_APPS=[...'crispy_forms',]CRISPY_TEMPLATE_PACK='bootstrap4'You can either download the latest Bootstrap 4 version at getbootstrap.com. In that case, go to download page and get the Compiled CSS and JS version.
Or you can use the hosted Bootstrap CDN:
<linkrel="stylesheet"href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css"integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO"crossorigin="anonymous"><script src="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.min.js"integrity="sha384-ChfqqxuZUCnJSK3+MXmPNIyE6ZbWh2IMqE241rYiqJxyMiZ6OW/JmZQ5stwEULTy"crossorigin="anonymous"></script>For simplicity, I will be using the CDN version. Here is my base.html template that will be referenced in the following examples:
<!doctype html><htmllang="en"><head><metacharset="utf-8"><metaname="viewport"content="width=device-width, initial-scale=1, shrink-to-fit=no"><linkrel="stylesheet"href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css"integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO"crossorigin="anonymous"><title>Django People</title></head><body><divclass="container"><divclass="row justify-content-center"><divclass="col-8"><h1class="mt-2">Django People</h1><hrclass="mt-0 mb-4">{%blockcontent%}{%endblock%}</div></div></div></body></html>I only added the CSS file because we won’t be using any JavaScript feature.
Suppose we have a model named Person as follows:
models.py
fromdjango.dbimportmodelsclassPerson(models.Model):name=models.CharField(max_length=130)email=models.EmailField(blank=True)job_title=models.CharField(max_length=30,blank=True)bio=models.TextField(blank=True)Let’s say we wanted to create a view to add new Person objects. In that case we could use the built-in CreateView:
views.py
fromdjango.views.genericimportCreateViewfrom.modelsimportPersonclassPersonCreateView(CreateView):model=Personfields=('name','email','job_title','bio')Without any further change, Django will try to use a template named people/person_form.html. In that case “people”
is the name of my Django app:
people/person_form.html
{%extends'base.html'%}{%blockcontent%}<formmethod="post">{%csrf_token%}{{form}}<buttontype="submit"class="btn btn-success">Save person</button></form>{%endblock%}This is a very basic form rendering, and as it is, Django will render it like this, with no style, just plain form fields:
Image may be NSFW.
Clik here to view.
To render the same form using Bootstrap 4 CSS classes you can do the following:
people/person_form.html
{%extends'base.html'%}{%loadcrispy_forms_tags%}{%blockcontent%}<formmethod="post"novalidate>{%csrf_token%}{{form|crispy}}<buttontype="submit"class="btn btn-success">Save person</button></form>{%endblock%}Now the result, much better:
Image may be NSFW.
Clik here to view.
There are some cases where you may want more freedom to render your fields. You can do so by rendering the fields
manually and using the as_crispy_field template filter:
{%extends'base.html'%}{%loadcrispy_forms_tags%}
**people/person_form.html**
{%blockcontent%}<formmethod="post"novalidate>{%csrf_token%}<divclass="row"><divclass="col-6">{{form.name|as_crispy_field}}</div><divclass="col-6">{{form.email|as_crispy_field}}</div></div>{{form.job_title|as_crispy_field}}{{form.bio|as_crispy_field}}<buttontype="submit"class="btn btn-success">Save person</button></form>{%endblock%}And the result is something like the screen shot below:
Image may be NSFW.
Clik here to view.
The django-crispy-forms app have a special class named FormHelper to make your life easier and to give you complete
control over how you want to render your forms.
Here is an example of an update view:
forms.py
fromdjangoimportformsfromcrispy_forms.helperimportFormHelperfromcrispy_forms.layoutimportSubmitfrompeople.modelsimportPersonclassPersonForm(forms.ModelForm):classMeta:model=Personfields=('name','email','job_title','bio')def__init__(self,*args,**kwargs):super().__init__(*args,**kwargs)self.helper=FormHelper()self.helper.form_method='post'self.helper.add_input(Submit('submit','Save person'))The job is done inside the __init__() method. The rest is just a regular Django model form. Here I’m defining that
this form should handle the request using the POST method and the form should have an submit button with label
“Save person”.
Now our view, just regular Django code:
views.py
fromdjango.views.genericimportUpdateViewfrompeople.modelsimportPersonfrompeople.formsimportPersonFormclassPersonUpdateView(UpdateView):model=Personform_class=PersonFormtemplate_name='people/person_update_form.html'Then in our template:
people/person_update_form.html
{%extends'base.html'%}{%loadcrispy_forms_tags%}{%blockcontent%}{%crispyform%}{%endblock%}Here we can simply call the {%crispy%} template tag and pass our form instance as parameter.
And that’s all you need to render the form:
Image may be NSFW.
Clik here to view.
That’s pretty much it for the basics. Honestly that’s about all that I use. Usually I don’t even go for the
FormHelper objects. But there are much more about it. If you are interested, you can check their official
documentation: django-crispy-forms.readthedocs.io.
If you are not sure about where you should create a certain file, or want to explore the sample project I created for this tutorial, you can grab the source code on GitHub at github.com/sibtc/bootstrap-forms-example.
This article shows how to install Python 3, pip, venv, virtualenv, and pipenv on Red Hat Enterprise Linux 7. After following the steps in this article, you should be in a good position to follow many Python guides and tutorials using RHEL.
Using Python virtual environments is a best practice to isolate project-specific dependencies and create reproducible environments. Other tips and FAQs for working with Python and software collections on RHEL 7 are also covered.
There are a number of different ways to get Python 3 installed on RHEL. This article uses Red Hat Software Collections because these give you a current Python installation that is built and supported by Red Hat. During development, support might not seem that important to you. However, support is important to those who have to deploy and operate the applications you write. To understand why this is important, consider what happens when your application is in production and a critical security vulnerability in a core library (for example SSL/TLS) is discovered. This type of scenario is why many enterprises use Red Hat.
Python 3.6 is used in this article. It was the most recent, stable release when this was written. However, you should be able to use these instructions for any of the versions of Python in Red Hat Software Collections including 2.7, 3.4, 3.5, and future collections such as 3.7.
In this article, the following topics are discussed:
venvvirtualenvpipenvHere are the basic steps so you can just get going. See below for explanations and more details.
root.rhscl and optional software repos using subscription-manager.yum to install @development. This makes sure you’ve got GCC, make, git, etc. so you can build any modules that contain compiled code.yum to install rh-python36.yum to install python-tools, numpy, scipy, and six from RHSCL RPMs.$ su - # subscription-manager repos --enable rhel-7-server-optional-rpms \ --enable rhel-server-rhscl-7-rpms # yum -y install @development # yum -y install rh-python36 # yum -y install rh-python36-numpy \ rh-python36-scipy \ rh-python36-python-tools \ rh-python36-python-six # exit
scl enable to add python 3 to your path(s).pip in an isolated environment without being root.$ scl enable rh-python36 bash $ python3 -V Python 3.6.3 $ python -V # python now also points to Python3 Python 3.6.3 $ mkdir ~/pydev $ cd ~/pydev $ python3 -m venv py36-venv $ source py36-env/bin/activate (py36-venv) $ python3 -m pip install ...some modules...
If you start a new session, here are the steps for using your virtual environment:
$ scl enable rh-python36 bash $ cd ~/pydev $ source py36-env/bin/activate
The benefit of using Red Hat Software Collections is that you can have multiple versions of Python installed at the same time along with the base Python 2.7 that shipped with RHEL 7. You can easily switch between versions with scl enable.
Note: The latest stable packages for .Net Core, Go, Rust, PHP 7, Ruby 2.5, GCC, Clang/LLVM, Nginx, MongoDB, MariaDB, PostgreSQL, and more are all yum– installable as software collections. So you should take the time to get comfortable with software collections.
Using software collections requires an extra step because you have to enable the collection you want to use. Enabling just adds the necessary paths (PATH, MANPATH, LD_LIBRARY_PATH) to your environment. Once you get the hang of it, software collections are fairly easy to use. It really helps to understand the way that environment-variable changes work in Linux/UNIX. Changes can be made only to the current process. When a child process is created, it inherits the environment of the parent. Any environment changes made in the parent after the child has been created will have no effect on the child. Therefore, the changes made by scl enable will affect only the current terminal session or anything started from it. This article also shows how you can permanently enable a software collection for your user account.
If you install modules that depend on compiled code you’ll need the tools to compile them. If you haven’t already installed development tools run the following command:
$ su - # yum install @development
While the default/base RHEL software repos have many development tools, these are the older versions that are shipped with the OS and are supported for the full 10-year life of the OS. Packages that are updated more frequently and have a different support lifecycle are distributed in other repos that aren’t enabled by default.
Red Hat Software Collections are in the rhscl repo. RHSCL packages have some dependencies on packages in the optional-rpms repo, so you need to enable both.
To enable the additional repos, run the following commands as root:
$ su - # subscription-manager repos \ --enable rhel-7-server-optional-rpms \ --enable rhel-server-rhscl-7-rpms
Notes:
-server- to -workstation-.yum when installing or updating software.To see which repos are available for your current subscription, run the following command:
# subscription-manager repos --list
To see which repos are enabled, use --list-enabled:
# subscription-manager repos --list-enabled
You can now install Python 3.6 (or other versions in RHSCL) with yum:
# yum install rh-python36
Notes:
/opt/rh/.scl enable. See below.rh-python35rh-python34python27python-devel, pip, setuptools, and virtualenv.python-devel package contains the files needed if you have to build any modules that dynamically link into Python (such as C/C++ code).Optionally, you may want to install the following RPM packages that are part of the software collection:
rh-python36-python-tools is a collection of tools included with Python 3, 2to3, and idle3.rh-python36-numpy is a fast multidimensional array facility for Python.rh-python36-scipy provides scientific tools for Python.rh-python36-python-six provides Python 2 and 3 compatible utilities.rh-python36-python-sqlalchemy is a modular and flexible ORM library for Python.rh-python36-PyYAML is a YAML parser and emitter for Python.rh-python36-python-simplejson is a simple, fast, extensible JSON encoder/decoder for Python.Example:
# yum install rh-python36-numpy \ rh-python36-scipy \ rh-python36-python-tools \ rh-python36-python-six
Note: By default system modules will not be used with Python virtual environments. Use the option --system-site-packages when creating the virtual environment to include system modules.
scl enable)Python 3 is now installed. You no longer need to run under the root user ID. The rest of the commands should be executed using your normal user account.
As previously mentioned, software collections are installed under /opt/rh and aren’t automatically added to your PATH, MANPATH, and LD_LIBRARY_PATH. The command scl enable will make the necessary changes and run a command. Because of the way environment variables work in Linux (and UNIX), the changes will take effect only for the command run by scl enable. You can use bash as the command to start an interactive session. This is one of the most common ways (but not the only way) of working with software collections.
$ scl enable rh-python36 bash $ python3 -V Python 3.6.3 $ python -V # python now points to Python 3 Python 3.6.3 $ which python /opt/rh/rh-python36/root/usr/bin/python
Note: Enabling the Python collection makes the python in your path, with no version number, point to Python 3. /usr/bin/python will still be Python 2. You can still run Python 2 by typing python2, python2.7, or /usr/bin/python. It is recommended that you use a version number to avoid any ambiguity about what python means. This also applies to other Python commands in .../bin such as pip, pydoc, python-config, pyvenv, and virtualenv. For more information, see PEP 394.
NOTE: See How to permanently enable a software collection below to permanently put Python 3 in your path.
Using Python virtual environments is a best practice to isolate project-specific dependencies and create reproducible environments. In other words, it’s a way to avoid conflicting dependencies that lead to dependency hell. Using a virtual environment will let you use pip to install whatever modules you need for your project in an isolated directory under your normal user ID. You can easily have multiple projects with different dependencies. To work on a specific project, you activate the virtual environment, which adds the right directories to your path(s).
Using virtual environments along with pip list, pip freeze, and a requirements.txt file gives you a path to a reproducible environment to run your code it. Others that need to run your code can use the requirements.txt file you generate to create a matching environment.
By default, virtual environments will not use any system installed modules, or modules installed under your home directory. From an isolation perspective and for creating reproducible environments this is generally considered the correct behavior. However, you can change that by using the argument --system-site-packages.
venv or virtualenv or something else?When you install Python 3 from Red Hat Software Collections, venv, virtualenv, and pip will be installed, so you are ready to install whatever modules you choose. “Installing Python Modules” in the current Python documentation says this:
venv is the standard tool for creating virtual environments, and has been part of Python since Python 3.3.virtualenv is a third-party alternative (and predecessor) to venv. It allows virtual environments to be used on versions of Python prior to 3.4, which either don’t provide venv at all or aren’t able to automatically install pip into created environments.So for all the recent versions of Python 3, venvis preferred.
If you work with Python 2.7, you’ll need to use virtualenv.
The commands to create the virtual environments differ only in the module name used. Once created, the command to activate the virtual environment is the same.
Note: for virtualenv, using python3.6 -m virtualenv is recommended instead of using the virtualenv command. See Avoid using Python wrapper scripts below for more information.
venvIf you haven’t already done so, enable the rh-python36 collection:
$ scl enable rh-python36 bash
Now create the virtual environment. To avoid any surprises, use an explicit version number for running Python:
$ python3.6 -m venv myproject1
Anytime you need to activate the virtual environment, run the following command.
$ source myproject1/bin/activate
Note: once you’ve activated a virtual environment, your prompt will change to remind you that you are working in a virtual environment. Example:
(myproject1) $
Note: When you log in again, or start a new session, you will need to activate the virtual environment using the source command again. Note: you should already have run scl enable before activating the virtual environment.
For more information, see Virtual Environments and Packages in the Python 3 tutorial at docs.python.org.
virtualenvIf you haven’t already done so, enable the rh-python36 collection:
$ scl enable rh-python36 bash
Now create the virtual environment. To avoid any surprises, use an explicit version number for running Python:
$ python3.6 -m virtualenv myproject1
Anytime you need to activate the virtual environment, run the following command. Note: you should already have run scl enable before activating the virtual environment.
$ source myproject1/bin/activate
Note: once you’ve activated a virtual environment, your prompt will change to remind you that you are working in a virtual environment. Example:
(myproject1) $
Note: When you log in again, or start a new session, you will need to activate the virtual environment using the source command again. Note: you should already have run scl enable before activating the virtual environment.
For more information, see Installing packages using pip and virtualenv in the Python Packaging User Guide.
pipenvFrom the Python Packaging User Guide tutorial, Managing Application Dependencies:
“Pipenv is a dependency manager for Python projects. If you’re familiar with Node.js’ npm or Ruby’s bundler, it is similar in spirit to those tools. While pip alone is often sufficient for personal use, Pipenv is recommended for collaborative projects as it’s a higher-level tool that simplifies dependency management for common use cases.”
With pipenv you no longer need to use pip and virtualenv separately. pipenv isn’t currently part of the standard Python 3 library or Red Hat Software Colleciton. You can install it using pip. (Note: see the recommendation below about not running pip install as root.) Since pipenv uses virtualenv to manage environments, you should install pipenvwithout having any virtual environment activated. However, don’t forget to enable the Python 3 software collection first.
$ scl enable rh-python36 bash # if you haven’t already done so $ python3.6 -m pip install --user pipenv
Creating and using isolated environments with pipenv works a bit differently than venv or virtualenv. A virtual environment will automatically be created if no Pipfile exists in the current directory when you install the first package. However, it’s a good practice to explicitly create an environment with the specific version of Python you want to use.
$ scl enable rh-python36 bash # if you haven’t already done so $ mkdir -p ~/pydev/myproject2 $ cd ~/pydev/myproject2 $ pipenv --python 3.6 $ pipenv install requests
To activate a Pipenv environment, cd into that directory and run pipenv shell.
$ scl enable rh-python36 bash # if you haven’t already done so $ cd ~/pydev/myproject2 $ pipenv shell
Pipenv is similar to scl enable in that it doesn’t try to modify the current environment with source, instead it starts a new shell. To deactivate, exit the shell. You can also run a command in the pipenv environment by using pipenv run command.
For more information see:
python command: Avoid surprises by using a version numberTo avoid surprises, don’t type python. Use an explicit version number in the command, such as python3.6 or python2.7.
At a minimum, always use python3 or python2. If you are reading this article, you’ve got more than one version of Python installed on your system. Depending on your path, you might get different versions. Activating and deactivating virtual environments, as well as enabling a software collection, changes your path, so it can be easy to be confused about what version you’ll get from typing python.
The same problem occurs with any of the Python utilities such as pip or pydoc. Using version numbers, for example, pip3.6, is recommended. At a minimum use the major version number: pip3. See the next section for a more robust alternative.
which to determine which Python version will be runUse the which command to determine the full path that will be used when you type a command. This will help you understand which version of python is in your path first and will get run when you type python.
Examples:
$ which python # before scl enable /usr/bin/python $ scl enable rh-python36 bash $ which python /opt/rh/rh-python36/root/usr/bin/python $ source ~/pydev/myproject1/bin/activate (myproject1) $ which python ~/pydev/myproject1/bin/python
virtualenv: Use the module nameSome Python utilities are put in your path as a wrapper script in a .../bin directory. This is convenient because you can just type pip or virtualenv. Most Python utilities are actually just Python modules with wrapper scripts to start Python and run the code in the module.
The problem with wrapper scripts is the same ambiguity that happens when typing python. Which version of pip or virtualenv you will get when you type the command without a version number? For things to work correctly, there is the additional complication that the utility needs to match the version of Python you intend to be using. Some subtle (hard to diagnose) problems can occur if you wind up unintentionally mixing versions.
Note: There are several directories that wrapper scripts can reside in. Which version you get is dependent on your path, which changes when you enable software collections and/or activate virtual environments. Modules installed with pip --user put their wrapper scripts in ~/.local/bin, which can get obscured by activating the software collection or a virtual environment.
You can avoid the surprises from the path issues by running the module directly from a specific version of Python by using -m modulename. While this involves more typing, it is a much safer approach.
Recommendations:
pip, use python3.6 -m pip.pyvenv, use python3.6 -m venv.virtualenv, use python3.6 -m virtualenv.pip install as root (or with sudo)Running pip install as root either directly or by using sudo is a bad idea and will cause you problems at some point. Some of the problems that you may encounter are:
pip installed packages. The conflicts will most likely show up when you need to install a fixed or upgraded package or module. The install might fail or, worse, you may wind up with a broken installation. It’s best to let yum be the exclusive manager of the files in the system directories.pip. When you want to run your Python code on another system, what needs to be installed? Does it need to be installed system-wide? Will you get the same version of the modules you tested your code under?pip install as root means all modules get installed in a system-wide directory, making it hard to determine which modules were installed for a specific application.Using virtual environments will allow you to isolate the modules you install for each project from the modules that are part of the Python installation from Red Hat. Using virtual environments is considered a best practice to create isolated environments that provide the dependencies needed for a specific purpose. You don’t need to use --user when running pip in a virtual environment since it will default to installing in the virtual environment, which you should have write access to.
If you aren’t using virtual environments, or need a module/tool to be available outside of a virtual environments, use pip --user to install modules under your home directory.
In case you think this is overly dire, see this xkcd comic. Don’t forget to hover so you see the alt text.
pip --userSome guides recommend using pip --user. While this is preferred over running pip as root, using virtual environments is much better practice for properly isolating the modules you need for a given project or set of projects. pip --user installs use ~/.local, which can be obscured by enabling software collections and/or activating virtual environments. For modules that install wrapper scripts in ~/.local/bin, this can cause a mismatch between the wrapper script and the module.
The exception to this advice is modules and tools that you need to use outside of virtual environments. The primary example is pipenv. You should use pip install --user pipenv to install pipenv. That way, you’ll have pipenv in your path without any virtual environments.
The Python version installed in /usr/bin/python and /usr/bin/python2 is part of the operating system. RHEL was tested with a specific Python release (2.7.5) that will be maintained for the full ten-year supported life of the OS. Many of the built-in administration tools are actually written in Python. Trying to change the version of Python in /usr/bin might actually break some of the OS functionality.
At some point, you might want to run your code on a different version of the OS. That OS will likely have a different version of Python installed as /usr/bin/python, /usr/bin/python2, or even /usr/bin/python3. The code you write may have dependencies on a specific version that can be best managed through virtual environments and/or software collections.
The one exception to the above is if you are writing system administration tools. In that case, you should use the Python in /usr/bin because it has the correct modules and libraries installed for the APIs in the OS. Note: If you are writing system administration or management tools in Python, you might want to take a look at Ansible. Ansible is written in Python, uses Jinja2 for templating, and provides higher-level abstractions for many system tasks.
Tip: If you need to work with Python 2.7, install the python27 software collection. Follow the installation steps above but use python27 instead of rh-python36. You can enable both collections at the same time, so you’ll have both the newer python2.7 and python3.6 in your path. Note: the collection you enable last is the one that will be first in your path, which determines the version you get when you type a command like python or pip without an explicit version number.
/usr/bin/python, /usr/bin/python2, or /usr/bin/python2.7As mentioned above, the system Python is part of Red Hat Enterprise Linux 7 and is used by critical system utilities such as yum. (Yes, yum is written in Python.) So overwriting the system Python is likely to break your system—badly. If you try to compile Python from source, do not do a make install (as root) without using a different prefix or it will overwrite /usr/bin/python.
You should always enable the Python software collection before using any of Python virtual environment utilities to create or activate an environment. In order for things to work correctly, you need to have your desired version of Python in your path because it will be needed by the Python virtual environment. A number of problems, some of which are subtle, come up if you try to enable/activate in the wrong order.
Example for venv:
$ scl enable rh-python36 bash $ python3.6 -m venv myproject1 $ source myproject1/bin/activate
When reactivating later in a new shell:
$ scl enable rh-python36 bash $ source myproject1/bin/activate
Example for virtualenv:
$ scl enable rh-python36 bash $ python3.6 -m virtualenv myproject1 $ source myproject1/bin/activate
When reactivating later in a new shell:
$ scl enable rh-python36 bash $ source myproject1/bin/activate
To permanently add Python 3 to your path(s), you can add an scl_source command to the “dot files” for your specific user ID. The benefit of this approach is that the collection is already enabled at every login. If you are using a graphical desktop, everything that you start from the menu will already have the collection enabled.
There are a few caveats with this approach:
python with no version number, you will get Python 3 instead of Python 2. You can still get Python 2 by typing python2 or python2.7. Using an explicit version number is strongly recommended..../bin such as pip, pydoc, python-config, pyvenv, and virtualenv. Use a version number to avoid surprises.scl disablecommand. Everything is in environment variables, so you can work around it, but it would be a manual process. You can, however, enable a different software collection that will then take precedence over the collection in your profile.Using your preferred text editor, add the following line to your ~/.bashrc:
# Add RHSCL Python 3 to my login environment source scl_source enable rh-python36
Note: you could also add the scl_source line to the start of a build script to select the desired Python for the build. If your build script isn’t written as a shell/bash script, you could just wrap it in a shell script that has the source scl_source command and then runs your build script.
You can create a script that will use Python from the software collection without a requirement for scl enable to be manually run first. This can be done by using /usr/bin/scl enable as the interpreter for the script:
#!/usr/bin/scl enable rh-python36 -- python3
import sys
version = "Python %d.%d" % (sys.version_info.major, sys.version_info.minor)
print("You are running Python",version)
Note: You may be tempted to try using just the full path to .../root/usr/bin/python without the scl enable. In many cases, this won’t work. The behavior is dependent on the specific software collection. For most collections, this will fail with a shared library error, since LD_LIBRARY_PATH isn’t set correctly. The python27 collection doesn’t give an error, but it finds the wrong shared library, so you get the wrong version of Python, which can be surprising. However, rh-python36 can be referenced directly without setting LD_LIBRARY_PATH, but it is currently the only Python collection that works that way. There is no guarantee that future collections will work the same way.
You can use the command scl -l to see what software collections are installed. This will show all software collections that are installed, whether they are enabled or not.
$ scl -l python27 rh-python36
The environment variable X_SCLS contains a list of the software collections that are currently enabled.
$ echo $X_SCLS $ for scl in $X_SCLS; do echo $scl; done rh-python36 python27
In scripts, you can use scl_enabled collection-name to test if a specific collection is enabled.
See Red Hat Software Collections Product Life Cycle on the Red Hat Customer Portal. It has a list of Red Hat Software Collections packages and support information.
You can also check the release notes for the most recent release of Red Hat Software Collections.
You can use yum search to search for additional packages and see the other versions that are available:
To search for other packages that are part of the rh-python36 collection:
# yum search rh-python36
Starting with the Python 3.4 collection, the collection and package names are all prefixed with rh-. So you can use the following command to see all of the rh-python packages and, therefore, see what collections are available.
# yum search rh-python
Note: to see the available packages in the Python 2.7 collection, search for python27.
# yum search python27
You can, of course, just search for python and get a list of every available RPM that has python in the name or description. It will be a very long list, so it’s best to redirect the output to a file and use grep or a text editor to search the file. The packages that start with python- (without a version number) are part of the base RHEL Python 2.7.5 packages that are installed in /usr/bin.
This error occurs when you are trying to run a binary but the shared libraries it depends on can’t be found. Typically this occurs when trying to run python from a software collection without enabling it first. In addition to setting PATH, scl enable also sets LD_LIBRARY_PATH. This adds the directory containing the software collection’s shared objects to the library search path.
To see what environment variables are modified, take a look at /opt/rh/rh-python/enable.
$ cat /opt/rh/rh-python36/enable
export PATH=/opt/rh/rh-python36/root/usr/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/opt/rh/rh-python36/root/usr/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export MANPATH=/opt/rh/rh-python36/root/usr/share/man:$MANPATH
export PKG_CONFIG_PATH=/opt/rh/rh-python36/root/usr/lib64/pkgconfig${PKG_CONFIG_PATH:+:${PKG_CONFIG_PATH}}
export XDG_DATA_DIRS="/opt/rh/rh-python36/root/usr/share:${XDG_DATA_DIRS:-/usr/local/share:/usr/share}"
pythonFirst, running python with no version number is likely to give you an unexpected version of Python at some point. The result is dependent on your PATH, which depends on whether you’ve enabled the software collection and/or activated the virtual environment. If you use a version number such as python3.6 and you haven’t enabled/activated the right environment, you’ll get a clean and easy-to-understand “command not found” error.
Second, you can also get the wrong version if you’ve forgotten to enable the software collection. Enabling the software collection puts the collection’s /bin directory in your path first, so it will hide all of the other versions of commands with the same name.
The software collection needs to be enabled even if you give the full path to the python binary. For most of the collections, you’ll get a shared library error (see above) without the library path being set correctly. However, if you try this with the python27 collection, you’ll get Python 2.7.5 (the default version) instead of Python 2.7.13 as you’d expect. This is because the shared library dependency is satisfied out of /lib instead of from the software collection, so you pick up the system Python.
pip: ImportError cannot import name ‘main’If you run pip upgrade --user pip, as some guides suggest, the pip command will no longer work. The problem is a path issue combined with an incompatibility between versions. The user installation of pip placed a new pip command in ~/.local/bin. However, ~/.local/bin is in your path *after* the software collection. So you get the older wrapper script that is incompatible with the newer module.
This can be worked around in several ways:
pip wrapper script in the .../bin directory of the virtual environment.pip as a module: python3.6 -m pip install … (See “Avoid Python wrapper scripts” above.)pip outside of virtual environments.pip wrapper script: ~/.local/bin/pip3.6.~/.local/bin as the first directory in your PATH after enabling the Python software collection.Note: To uninstall the upgraded pip that was installed in ~/.local, run the following command under your regular user ID (not root):
$ python3.6 -m pip uninstall pip
virtualenv3.6The rh-python36 software collection includes the virtualenv wrapper script but does not have a link for virtualenv3.6. There are two workarounds for this, but first I should point out that venv is now the Python 3 preferred tool for virtual environments.
The preferred workaround is to avoid the wrapper script entirely and invoke the module directly:
$ python3.6 -m virtualenv myproject1
Alternatively, you could create your own symlink in your ~/bin directory:
$ ln -s /opt/rh/rh-python36/root/usr/bin/virtualenv ~/bin/virtualenv3.6
Nick Coghlan and Graham Dumpleton gave a talk Developing in Python on Red Hat Platforms at DevNation 2016. The talk is chock full of information and still very relevant. They include information on building Python applications using containers, using s2i, and deploying to Red Hat OpenShift. I recommend watching the video or at least reviewing the slides.
After reading this article you’ve learned:
venv and virtualenv. Both tools will be installed for you as part of the software collection.pipenv, a tool that is similar to npm, which is recommended by the Python Packaging Guide for managing application dependencies, especially on shared projects. Pipenv provides one command that integrates both pip and virtualenv.pip install as root to avoid conflicts with the RPM packages installed by yumpython without a version number to avoid ambiguity about which version will be run and surprises that might result from thatyum depend on it and might breakpip upgrade breaks pip with: ImportError cannot import name ‘main’python
Image may be NSFW.
Clik here to view.
The post How to install Python 3 on RHEL appeared first on RHD Blog.
There’s only two days left to join the Kickstarter for my latest book, Jupyter Notebook 101. It’s also one of the best times to help out as you get to help shape the book right now. I always take my reader’s feedback when writing my books into consideration and have added lots of extra information in my books because of their requests.
David Heinemeier Hansson is the creator of Ruby on Rails, founder & CTO at Basecamp (formerly 37signals). He's a best selling author, public speaker, and even a Le Mans class winning racing driver.
All of that, of course, is awesome. But that's not why I asked him on the show. In 2014, during a RailsConf keynote, he started a discussion about damage caused by TDD. This was followed by a few blog posts, and then a series of recorded hangouts with Martin Fowler and Kent Beck. This is what I wanted to talk with David about; this unconventional yet practical and intuitive view of how testing and development work together.
It's a great discussion. I think you'll get a lot out of it.
Special Guest: David Heinemeier Hansson.
Sponsored By:
Links:
<p>David Heinemeier Hansson is the creator of Ruby on Rails, founder & CTO at Basecamp (formerly 37signals). He's a best selling author, public speaker, and even a Le Mans class winning racing driver. </p> <p>All of that, of course, is awesome. But that's not why I asked him on the show. In 2014, during a RailsConf keynote, he started a discussion about damage caused by TDD. This was followed by a few blog posts, and then a series of recorded hangouts with Martin Fowler and Kent Beck. This is what I wanted to talk with David about; this unconventional yet practical and intuitive view of how testing and development work together. </p> <p>It's a great discussion. I think you'll get a lot out of it.</p><p>Special Guest: David Heinemeier Hansson.</p><p>Sponsored By:</p><ul><li><a rel="nofollow" href="http://testandcode.com/pycharm">PyCharm</a>: <a rel="nofollow" href="http://testandcode.com/pycharm">If you value your time, you owe it to yourself to try PyCharm. The team has set up a link just for Test & Code listeners. If you use the link [testandcode.com/pycharm](https://testandcode.com/pycharm), you can try PyCharm Professional for free for 3 months. This offer is only good until Sept 1, so don't forget. Plus using the link (I'll also have it in the show notes) lets PyCharm know that supporting Test & Code is a good thing.</a></li></ul><p>Links:</p><ul><li><a title="Is TDD dead? - Part 1" rel="nofollow" href="https://www.youtube.com/watch?v=z9quxZsLcfo">Is TDD dead? - Part 1</a></li><li><a title="My reaction to "Is TDD Dead?", including links to the other parts of the video series" rel="nofollow" href="http://pythontesting.net/agile/is-tdd-dead/">My reaction to "Is TDD Dead?", including links to the other parts of the video series</a></li><li><a title="RailsConf 2014 - Keynote: Writing Software by David Heinemeier Hansson - YouTube" rel="nofollow" href="https://www.youtube.com/watch?v=9LfmrkyP81M">RailsConf 2014 - Keynote: Writing Software by David Heinemeier Hansson - YouTube</a></li><li><a title="TDD is dead. Long live testing. (DHH)" rel="nofollow" href="http://david.heinemeierhansson.com/2014/tdd-is-dead-long-live-testing.html">TDD is dead. Long live testing. (DHH)</a></li><li><a title="Test-induced design damage (DHH)" rel="nofollow" href="http://david.heinemeierhansson.com/2014/test-induced-design-damage.html">Test-induced design damage (DHH)</a></li><li><a title="Slow database test fallacy (DHH)" rel="nofollow" href="http://david.heinemeierhansson.com/2014/slow-database-test-fallacy.html">Slow database test fallacy (DHH)</a></li></ul>If you’ve done a little work in Git and are starting to understand the basics we covered in our introduction to Git, but you want to learn to be more efficient and have more control, then this is the place for you!
In this tutorial, we’ll talk about how to address specific commits and entire ranges of commits, using the stash to save temporary work, comparing different commits, changing history, and how to clean up the mess if something doesn’t work out.
This article assumes you’ve worked through our first Git tutorial or at a minimum understand the basics of what Git is and how it works.
There’s a lot of ground to cover, so let’s get going.
There are several options to tell Git which revision (or commit) you want to use. We’ve already seen that we can use a full SHA (25b09b9ccfe9110aed2d09444f1b50fa2b4c979c) and a short SHA (25b09b9cc) to indicate a revision.
We’ve also seen how you can use HEAD or a branch name to specify a particular commit as well. There are a few other tricks that Git has up its sleeve, however.
Sometimes it’s useful to be able to indicate a revision relative to a known position, like HEAD or a branch name. Git provides two operators that, while similar, behave slightly differently.
The first of these is the tilde (~) operator. Git uses tilde to point to a parent of a commit, so HEAD~ indicates the revision before the last one committed. To move back further, you use a number after the tilde: HEAD~3 takes you back three levels.
This works great until we run into merges. Merge commits have two parents, so the ~ just selects the first one. While that works sometimes, there are times when you want to specify the second or later parent. That’s why Git has the caret (^) operator.
The ^ operator moves to a specific parent of the specified revision. You use a number to indicate which parent. So HEAD^2 tells Git to select the second parent of the last one committed, not the “grandparent.” It can be repeated to move back further: HEAD^2^^ takes you back three levels, selecting the second parent on the first step. If you don’t give a number, Git assumes 1.
Note: Those of you using Windows will need to escape the ^ character on the DOS command line by using a second ^.
To make life even more fun and less readable, I’ll admit, Git allows you to combine these methods, so 25b09b9cc^2~3^3 is a valid way to indicate a revision if you’re walking back a tree structure with merges. It takes you to the second parent, then back three revisions from that, and then to the third parent.
There are a couple of different ways to specify ranges of commits for commands like git log. These don’t work exactly like slices in Python, however, so be careful!
Double Dot Notation
The “double dot” method for specifying ranges looks like it sounds: git log b05022238cdf08..60f89368787f0e. It’s tempting to think of this as saying “show me all commits after b05022238cdf08 up to and including 60f89368787f0e” and, if b05022238cdf08 is a direct ancestor of 60f89368787f0e, that’s exactly what it does.
Note: For the rest of this section, I will be replacing the SHAs of individual commits with capital letters as I think that makes the diagrams a little easier to follow. We’ll use this “fake” notation later as well.
It’s a bit more powerful than that, however. The double dot notation actually is showing you all commits that are included in the second commit that are not included in the first commit. Let’s look at a few diagrams to clarify:
Image may be NSFW.
Clik here to view.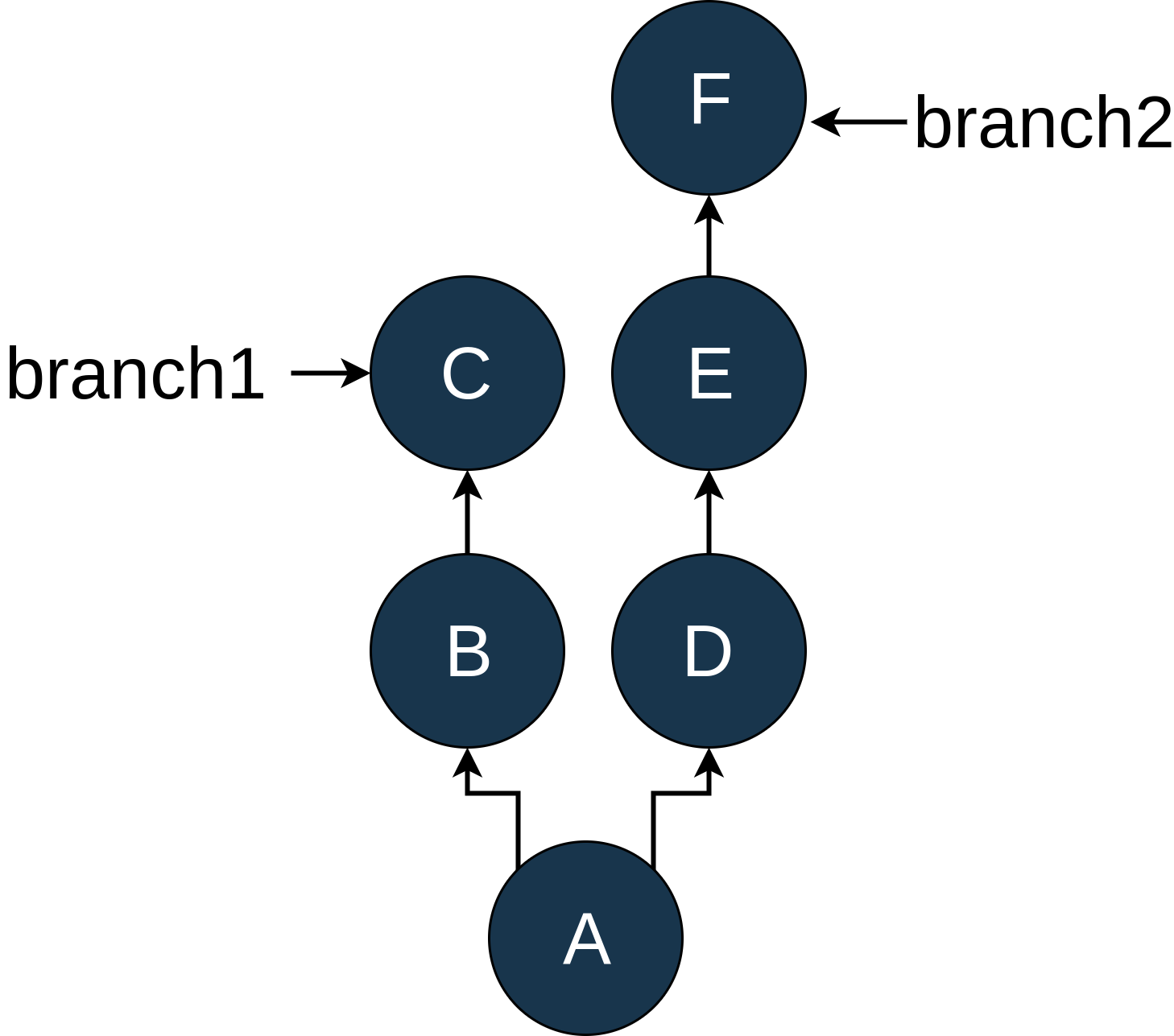 B->C, Branch2 A->D->E->F" />B->C, Branch2 A->D->E->F" />
B->C, Branch2 A->D->E->F" />B->C, Branch2 A->D->E->F" />
As you can see, we have two branches in our example repo, branch1 and branch2, which diverged after commit A. For starters, let’s look at the simple situation. I’ve modified the log output so that it matches the diagram:
$ git log --oneline D..F
E "Commit message for E"F "Commit message for F"D..F gives you all of the commits on branch2after commit D.
A more interesting example, and one I learned about while writing this tutorial, is the following:
$ git log --oneline C..F
D "Commit message for D"E "Commit message for E"F "Commit message for F"This shows the commits that are part of commit F that are not part of commit C. Because of the structure here, there is not a before/after relationship to these commits because they are on different branches.
What do you think you’ll get if you reverse the order of C and F?
$ git log --oneline F..C
B "Commit message for B"C "Commit message for C"Triple Dot
Triple dot notation uses, you guessed it, three dots between the revision specifiers. This works in a similar manner to the double dot notation except that it shows all commits that are in either revision that are not included in both revisions.
For our diagram above, using C...F shows you this:
$ git log --oneline C...F
D "Commit message for D"E "Commit message for E"F "Commit message for F"B "Commit message for B"C "Commit message for C"Double and triple dot notation can be quite powerful when you want to use a range of commits for a command, but they’re not as straightforward as many people think.
Branches vs. HEAD vs. SHA
This is probably a good time to review what branches are in Git and how they relate to SHAs and HEAD.
HEAD is the name Git uses to refer to “where your file system is pointing right now.” Most of the time, this will be pointing to a named branch, but it does not have to be. To look at these ideas, let’s walk through an example. Suppose your history looks like this:
Image may be NSFW.
Clik here to view.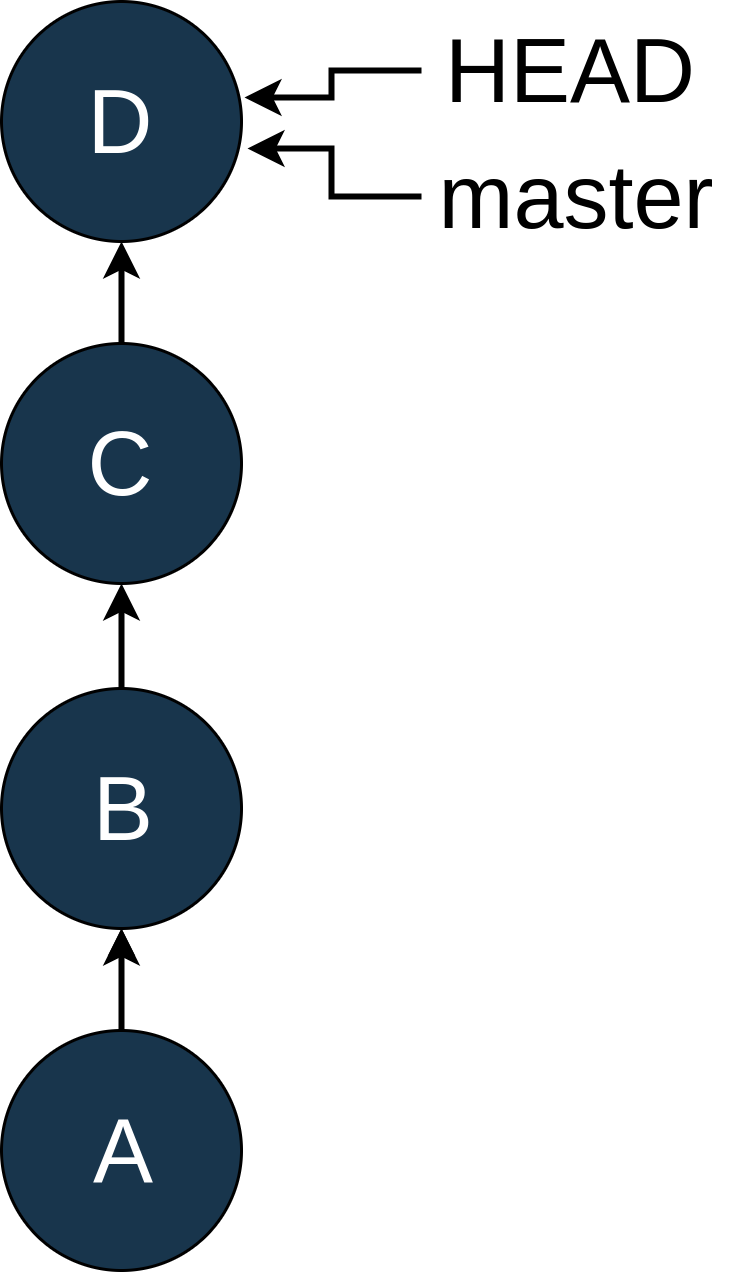
At this point, you discover that you accidentally committed a Python logging statement in commit B. Rats. Now, most people would add a new commit, E, push that to master and be done. But you are learning Git and want to fix this the hard way and hide the fact that you made a mistake in the history.
So you move HEAD back to B using git checkout B, which looks like this:
Image may be NSFW.
Clik here to view.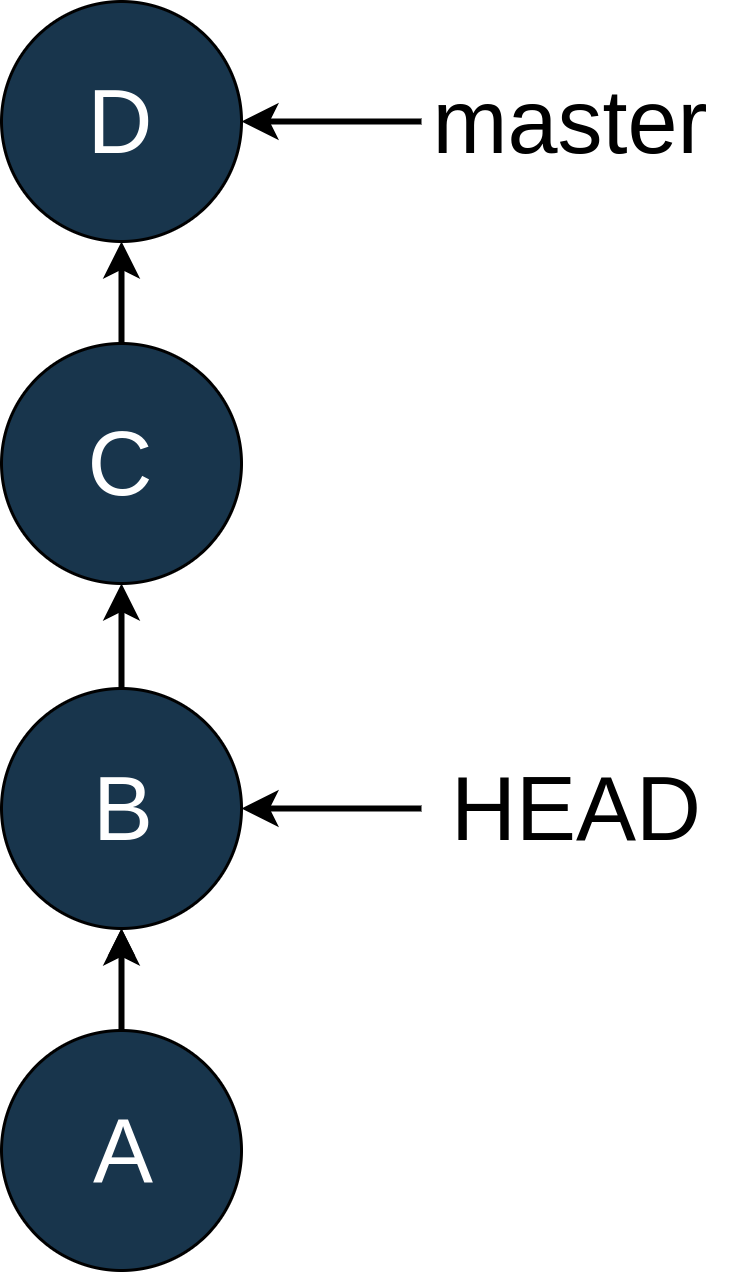
You can see that master hasn’t changed position, but HEAD now points to B. In the Intro to Git tutorial, we talked about the “detached HEAD” state. This is that state again!
Since you want to commit changes, you create a new branch with git checkout -b temp:
Image may be NSFW.
Clik here to view.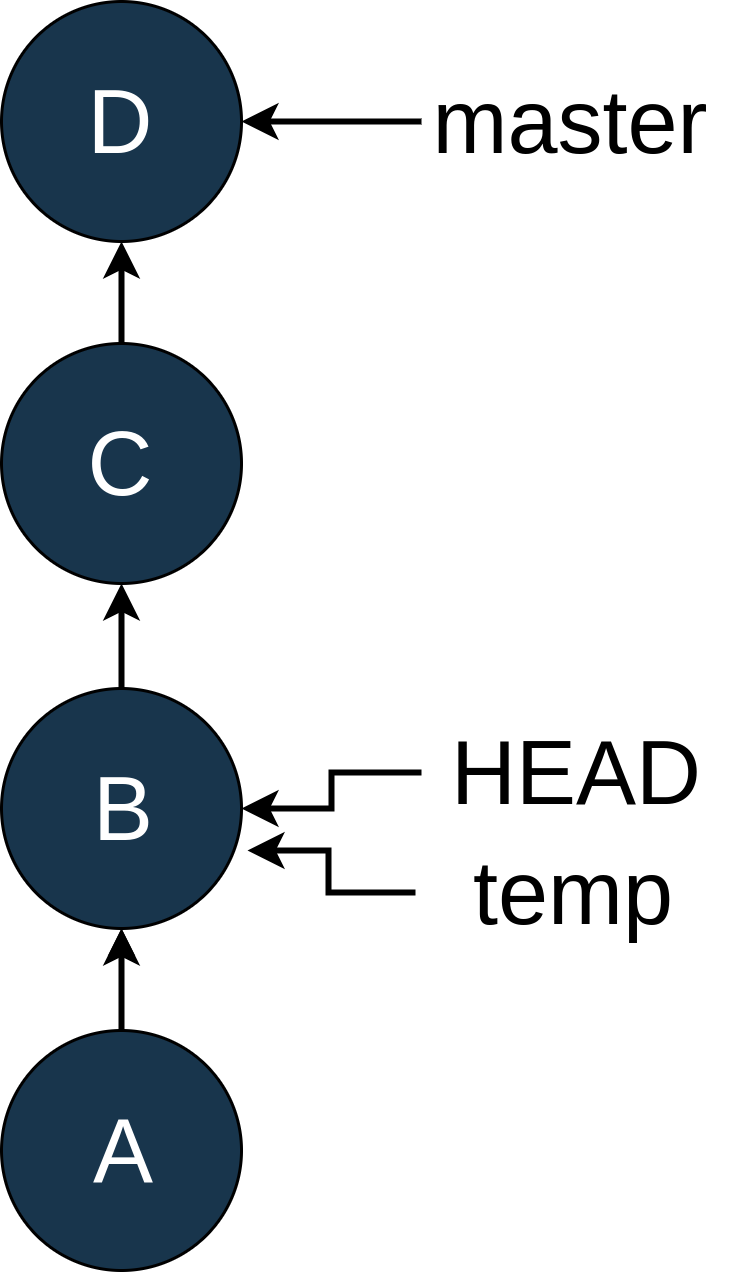
Now you edit the file and remove the offending log statement. Once that is done, you use git add and git commit --amend to modify commit B:
Image may be NSFW.
Clik here to view.
Whoa! There’s a new commit here called B'. Just like B, it has A as its parent, but C doesn’t know anything about it. Now we want master to be based on this new commit, B'.
Because you have a sharp memory, you remember that the rebase command does just that. So you get back to the master branch by typing git checkout master:
Image may be NSFW.
Clik here to view.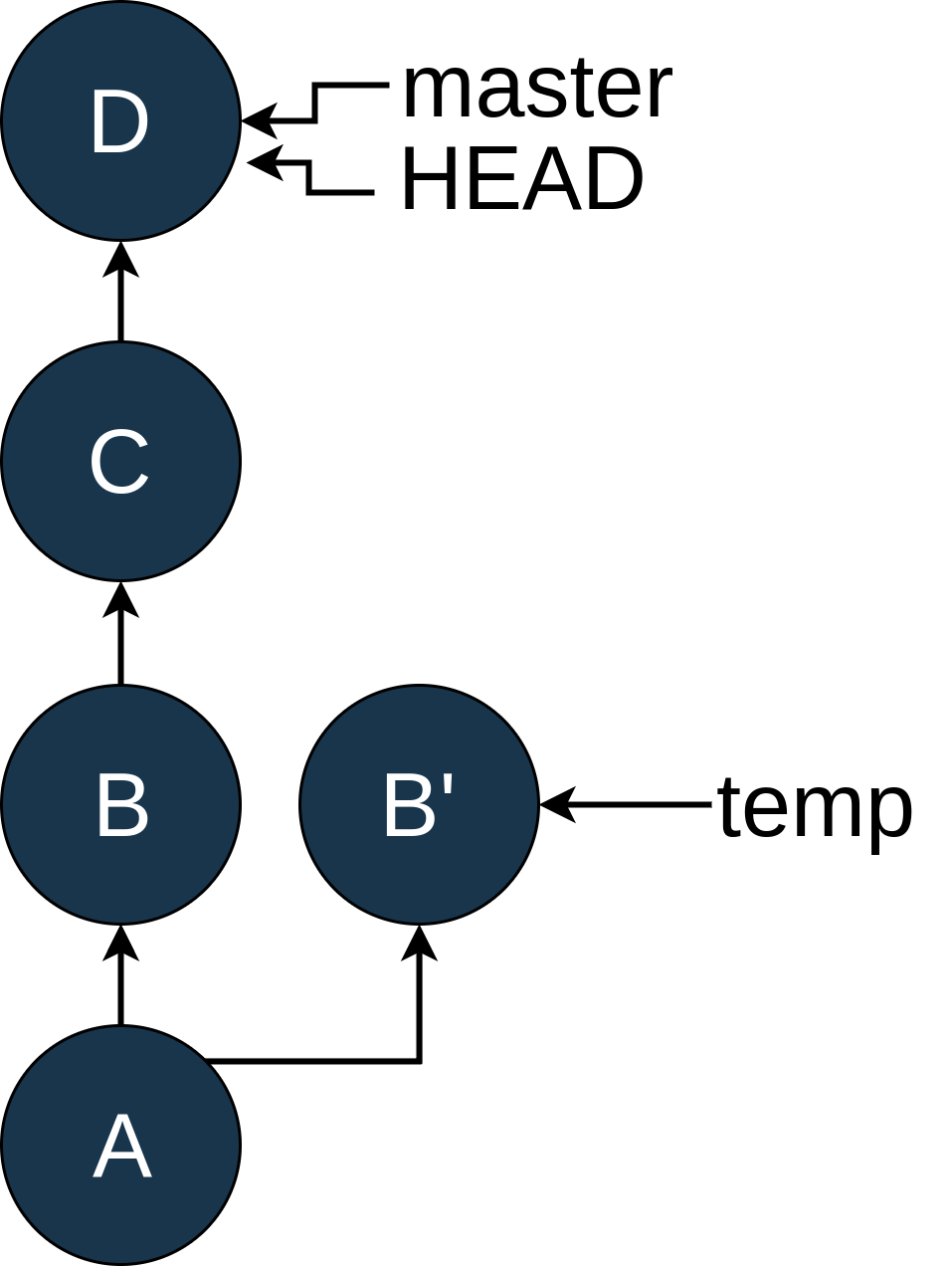
Once you’re on master, you can use git rebase temp to replay C and D on top of B:
Image may be NSFW.
Clik here to view.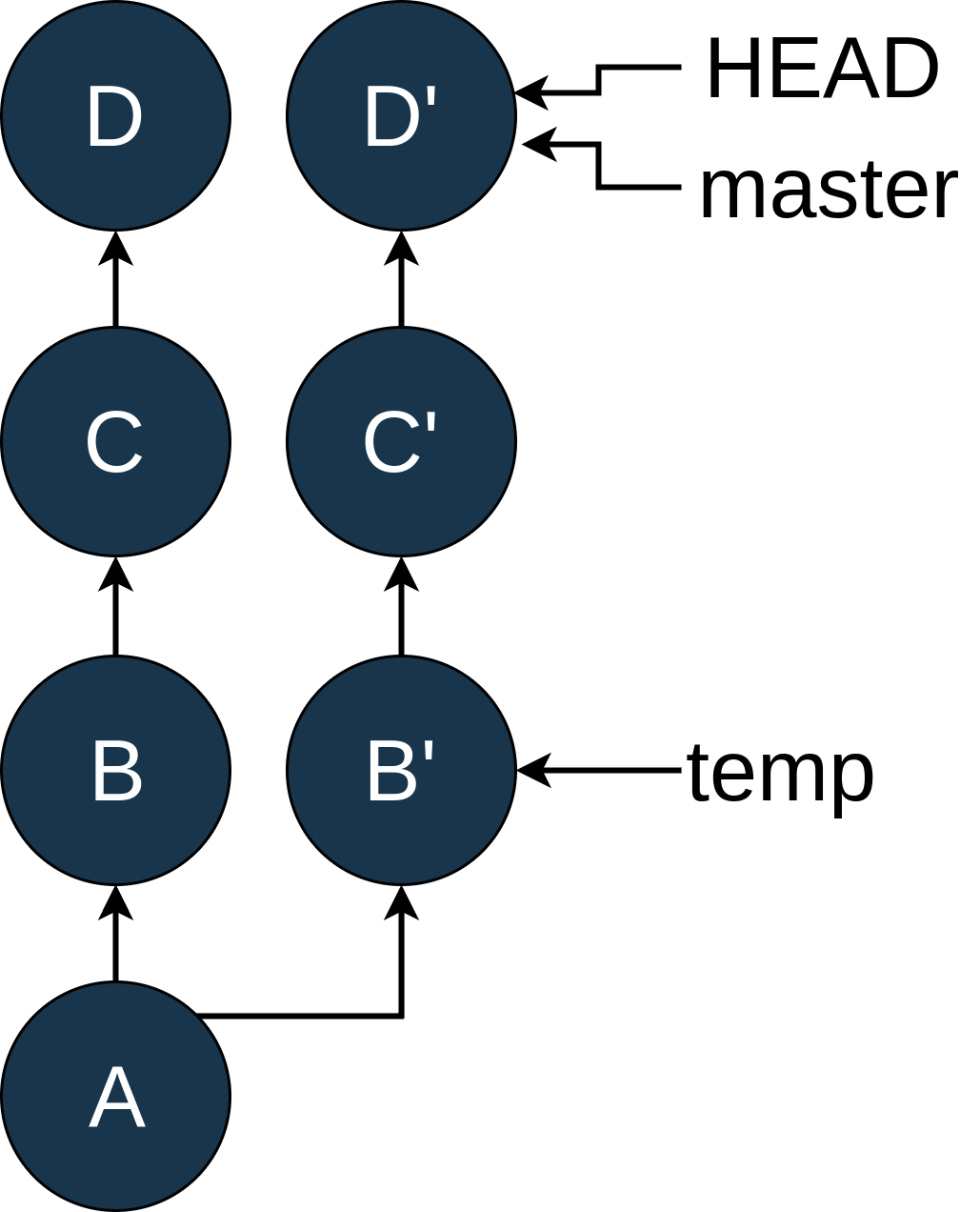
You can see that the rebase created commits C' and D'. C' still has the same changes that C has, and D' has the same changes as D, but they have different SHAs because they are now based on B' instead of B.
As I mentioned earlier, you normally wouldn’t go to this much trouble just to fix an errant log statement, but there are times when this approach could be useful, and it does illustrate the differences between HEAD, commits, and branches.
More
Git has even more tricks up its sleeve, but I’ll stop here as I’ve rarely seen the other methods used in the wild. If you’d like to learn about how to do similar operations with more than two branches, checkout the excellent write-up on Revision Selection in the Pro Git book.
git stashOne of the Git features I use frequently and find quite handy is the stash. It provides a simple mechanism to save the files you’re working on but are not ready to commit so you can switch to a different task. In this section, you’ll walk through a simple use case first, looking at each of the different commands and options, then you will wrap up with a few other use cases in which git stash really shines.
git stash save and git stash popSuppose you’re working on a nasty bug. You’ve got Python logging code in two files, file1 and file2, to help you track it down, and you’ve added file3 as a possible solution.
In short, the changes to the repo are as follows:
file1 and done git add file1.file2 but have not added it.file3 and have not added it.You do a git status to confirm the condition of the repo:
$ git status
On branch masterChanges to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2Untracked files: (use "git add <file>..." to include in what will be committed) file3Now a coworker (aren’t they annoying?) walks up and tells you that production is down and it’s “your turn.” You know you can break out your mad git stash skills to save you some time and save the day.
You haven’t finished with the work on files 1, 2, and 3, so you really don’t want to commit those changes but you need to get them off of your working directory so you can switch to a different branch to fix that bug. This is the most basic use case for git stash.
You can use git stash save to “put those changes away” for a little while and return to a clean working directory. The default option for stash is save so this is usually written as just git stash.
When you save something to stash, it creates a unique storage spot for those changes and returns your working directory to the state of the last commit. It tells you what it did with a cryptic message:
$ git stash save
Saved working directory and index state WIP on master: 387dcfc adding some filesHEAD is now at 387dcfc adding some filesIn that output, master is the name of the branch, 387dcfc is the SHA of the last commit, adding some files is the commit message for that commit, and WIP stands for “work in progress.” The output on your repo will likely be different in those details.
If you do a status at this point, it will still show file3 as an untracked file, but file1 and file2 are no longer there:
$ git status
On branch masterUntracked files: (use "git add <file>..." to include in what will be committed) file3nothing added to commit but untracked files present (use "git add" to track)At this point, as far as Git is concerned, your working directory is “clean,” and you are free to do things like check out a different branch, cherry-pick changes, or anything else you need to.
You go and check out the other branch, fix the bug, earn the admiration of your coworkers, and now are ready to return to this work.
How do you get the last stash back? git stash pop!
Using the pop command at this point looks like this:
$ git stash pop
On branch masterChanges not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file1 modified: file2Untracked files: (use "git add <file>..." to include in what will be committed) file3no changes added to commit (use "git add" and/or "git commit -a")Dropped refs/stash@{0} (71d0f2469db0f1eb9ee7510a9e3e9bd3c1c4211c)Now you can see at the bottom that it has a message about “Dropped refs/stash@{0}”. We’ll talk more about that syntax below, but it’s basically saying that it applied the changes you had stashed and got rid of the stash itself. Before you ask, yes, there is a way to use the stash and not get rid of it, but let’s not get ahead of ourselves.
You’ll notice that file1 used to be in the index but no longer is. By default, git stash pop doesn’t maintain the status of changes like that. There is an option to tell it to do so, of course. Add file1 back to the index and try again:
$ git add file1
$ git status
On branch masterChanges to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2Untracked files: (use "git add <file>..." to include in what will be committed) file3$ git stash save "another try"Saved working directory and index state On master: another tryHEAD is now at 387dcfc adding some files$ git stash pop --index
On branch masterChanges to be committed: (use "git reset HEAD <file>..." to unstage) modified: file1Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file2Untracked files: (use "git add <file>..." to include in what will be committed) file3Dropped refs/stash@{0} (aed3a02aeb876c1137dd8bab753636a294a3cc43)You can see that the second time we added the --index option to the git pop command, which tells it to try to maintain the status of whether or not a file is in the index.
In the previous two attempts, you probably noticed that file3 was not included in your stash. You might want to keep file3 together with those other changes. Fortunately, there is an option to help you with that: --include-untracked.
Assuming we’re back to where we were at the end of the last example, we can re-run the command:
$ git stash save --include-untracked "third attempt"Saved working directory and index state On master: third attemptHEAD is now at 387dcfc adding some files$ git status
On branch masternothing to commit, working directory cleanThis put the untracked file3 into the stash with our other changes.
Before we move on, I just want to point out that save is the default option for git stash. Unless you’re specifying a message, which we’ll discuss later, you can simply use git stash, and it will do a save.
git stash listOne of the powerful features of git stash is that you can have more than one of them. Git stores stashes in a stack, which means that by default it always works with the most recently saved stash. The git stash list command will show you the stack of stashes in your local repo. Let’s create a couple of stashes so we can see how this works:
$echo"editing file1">> file1
$ git stash save "the first save"Saved working directory and index state On master: the first saveHEAD is now at b3e9b4d adding file3$# you can see that stash save cleaned up our working directory$# now create a few more stashes by "editing" files and saving them$echo"editing file2">> file2
$ git stash save "the second save"Saved working directory and index state On master: the second saveHEAD is now at b3e9b4d adding file3$echo"editing file3">> file3
$ git stash save "the third save"Saved working directory and index state On master: the third saveHEAD is now at b3e9b4d adding file3$ git status
On branch masternothing to commit, working directory cleanYou now have three different stashes saved. Fortunately, Git has a system for dealing with stashes that makes this easy to deal with. The first step of the system is the git stash list command:
$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the second savestash@{2}: On master: the first saveList shows you the stack of stashes you have in this repo, the newest one first. Notice the stash@{n} syntax at the start of each entry? That’s the name of that stash. The rest of the git stash subcommand will use that name to refer to a specific stash. Generally if you don’t give a name, it always assumes you mean the most recent stash, stash@{0}. You’ll see more of this in a bit.
Another thing I’d like to point out here is that you can see the message we used when we did the git stash save "message" command in the listing. This can be quite helpful if you have a number of things stashed.
As we mentioned above, the save [name] portion of the git stash save [name] command is not required. You can simply type git stash, and it defaults to a save command, but the auto-generated message doesn’t give you much information:
$echo"more editing file1">> file1
$ git stash
Saved working directory and index state WIP on master: 387dcfc adding some filesHEAD is now at 387dcfc adding some files$ git stash list
stash@{0}: WIP on master: 387dcfc adding some filesstash@{1}: On master: the third savestash@{2}: On master: the second savestash@{3}: On master: the first saveThe default message is WIP on <branch>: <SHA> <commit message>., which doesn’t tell you much. If we had done that for the first three stashes, they all would have had the same message. That’s why, for the examples here, I use the full git stash save <message> syntax.
git stash showOkay, so now you have a bunch of stashes, and you might even have meaningful messages describing them, but what if you want to see exactly what’s in a particular stash? That’s where the git stash show command comes in. Using the default options tells you how many files have changed, as well as which files have changed:
$ git stash show stash@{2} file1 | 1 + 1 file changed, 1 insertion(+)The default options do not tell you what the changes were, however. Fortunately, you can add the -p/--patch option, and it will show you the diffs in “patch” format:
$ git stash show -p stash@{2}diff --git a/file1 b/file1index e212970..04dbd7b 100644--- a/file1+++ b/file1@@ -1 +1,2 @@ file1+editing file1Here it shows you that the line “editing file1” was added to file1. If you’re not familiar with the patch format for displaying diffs, don’t worry. When you get to the git difftool section below, you’ll see how to bring up a visual diff tool on a stash.
git stash pop vs. git stash applyYou saw earlier how to pop the most recent stash back into your working directory by using the git stash pop command. You probably guessed that the stash name syntax we saw earlier also applies to the pop command:
$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the second savestash@{2}: On master: the first save$ git stash pop stash@{1}On branch masterChanges not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)while read line; do echo -n "$line" | wc -c; done< modified: file2no changes added to commit (use "git add" and/or "git commit -a")Dropped stash@{1} (84f7c9890908a1a1bf3c35acfe36a6ecd1f30a2c)$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the first saveYou can see that the git stash pop stash@{1} put “the second save” back into our working directory and collapsed our stack so that only the first and third stashes are there. Notice how “the first save” changed from stash@{2} to stash@{1} after the pop.
It’s also possible to put a stash onto your working directory but leave it in the stack as well. This is done with git stash apply:
$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the first save$ git stash apply stash@{1}On branch masterChanges not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: file1 modified: file2no changes added to commit (use "git add" and/or "git commit -a")$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the first saveThis can be handy if you want to apply the same set of changes multiple times. I recently used this while working on prototype hardware. There were changes needed to get the code to work on the particular hardware on my desk, but none of the others. I used git stash apply to apply these changes each time I brought down a new copy of master.
git stash dropThe last stash subcommand to look at is drop. This is useful when you want to throw away a stash and not apply it to your working directory. It looks like this:
$ git status
On branch masternothing to commit, working directory clean$ git stash list
stash@{0}: On master: the third savestash@{1}: On master: the first save$ git stash drop stash@{1}Dropped stash@{1} (9aaa9996bd6aa363e7be723b4712afaae4fc3235)$ git stash drop
Dropped refs/stash@{0} (194f99db7a8fcc547fdd6d9f5fbffe8b896e2267)$ git stash list
$ git status
On branch masternothing to commit, working directory cleanThis dropped the last two stashes, and Git did not change your working directory. There are a couple of things to notice in the above example. First, the drop command, like most of the other git stash commands, can use the optional stash@{n} names. If you don’t supply it, Git assumes stash@{0}.
The other interesting thing is that the output from the drop command gives you a SHA. Like other SHAs in Git, you can make use of this. If, for example, you really meant to do a pop and not a drop on stash@{1} above, you can create a new branch with that SHA it showed you (9aaa9996):
$ git branch tmp 9aaa9996
$ git status
On branch masternothing to commit, working directory clean$# use git log <branchname> to see commits on that branch$ git log tmp
commit 9aaa9996bd6aa363e7be723b4712afaae4fc3235Merge: b3e9b4d f2d6eccAuthor: Jim Anderson <your_email_here@gmail.com>Date: Sat May 12 09:34:29 2018 -0600 On master: the first save[rest of log deleted for brevity]Once you have that branch, you can use the git merge or other techniques to get those changes back to your branch. If you didn’t save the SHA from the git drop command, there are other methods to attempt to recover the changes, but they can get complicated. You can read more about it here.
git stash Example: Pulling Into a Dirty TreeLet’s wrap up this section on git stash by looking at one of its uses that wasn’t obvious to me at first. Frequently when you’re working on a shared branch for a longer period of time, another developer will push changes to the branch that you want to get to your local repo. You’ll remember that we use the git pull command to do this. However, if you have local changes in files that the pull will modify, Git refuses with an error message explaining what went wrong:
error: Your local changes to the following files would be overwritten by merge:<list of files that conflict>Please, commit your changes or stash them before you can merge.AbortingYou could commit this and then do a pull , but that would create a merge node, and you might not be ready to commit those files. Now that you know git stash, you can use it instead:
$ git stash
Saved working directory and index state WIP on master: b25fe34 Cleaned up when no TOKEN is present. Added ignored tasksHEAD is now at <SHA> <commit message>$ git pull
Updating <SHA1>..<SHA2>Fast-forward<more info here>$ git stash pop
On branch masterYour branch is up-to-date with 'origin/master'.Changes not staged for commit:<rest of stash pop output trimmed>It’s entirely possible that doing the git stash pop command will produce a merge conflict. If that’s the case, you’ll need to hand-edit the conflict to resolve it, and then you can proceed. We’ll discuss resolving merge conflicts below.
git diffThe git diff command is a powerful feature that you’ll find yourself using quite frequently. I looked up the list of things it can compare and was surprised by the list. Try typing git diff --help if you’d like to see for yourself. I won’t cover all of those use cases here, as many of them aren’t too common.
This section has several use cases with the diff command, which displays on the command line. The next section shows how you can set Git up to use a visual diff tool like Meld, Windiff, BeyondCompare, or even extensions in your IDE. The options for diff and difftool are the same, so most of the discussion in this section will apply there too, but it’s easier to show the output on the command line version.
The most common use of git diff is to see what you have modified in your working directory:
$echo"I'm editing file3 now">> file3
$ git diff
diff --git a/file3 b/file3index faf2282..c5dd702 100644--- a/file3+++ b/file3@@ -1,3 +1,4 @@{other contents of files3}+I'm editing file3 nowAs you can see, diff shows you the diffs in a “patch” format right on the command line. Once you work through the format, you can see that the + characters indicate that a line has been added to the file, and, as you’d expect, the line I'm editing file3 now was added to file3.
The default options for git diff are to show you what changes are in your working directory that are not in your index or in HEAD. If you add the above change to the index and then do diff, it shows that there are no diffs:
$ git add file3
$ git diff
[no output here]I found this confusing for a while, but I’ve grown to like it. To see the changes that are in the index and staged for the next commit, use the --staged option:
$ git diff --staged
diff --git a/file3 b/file3index faf2282..c5dd702 100644--- a/file3+++ b/file3@@ -1,3 +1,4 @@ file1 file2 file3+I'm editing file3 nowThe git diff command can also be used to compare any two commits in your repo. This can show you the changes between two SHAs:
$ git diff b3e9b4d 387dcfc
diff --git a/file3 b/file3deleted file mode 100644index faf2282..0000000--- a/file3+++ /dev/null@@ -1,3 +0,0 @@-file1-file2-file3You can also use branch names to see the full set of changes between one branch and another:
$ git diff master tmp
diff --git a/file1 b/file1index e212970..04dbd7b 100644--- a/file1+++ b/file1@@ -1 +1,2 @@ file1+editing file1You can even use any mix of the revision naming methods we looked at above:
$ git diff master^ master
diff --git a/file3 b/file3new file mode 100644index 0000000..faf2282--- /dev/null+++ b/file3@@ -0,0 +1,3 @@+file1+file2+file3When you compare two branches, it shows you all of the changes between two branches. Frequently, you only want to see the diffs for a single file. You can restrict the output to a file by listing the file after a -- (two minuses) option:
$ git diff HEAD~3 HEAD
diff --git a/file1 b/file1index e212970..04dbd7b 100644--- a/file1+++ b/file1@@ -1 +1,2 @@ file1+editing file1diff --git a/file2 b/file2index 89361a0..91c5d97 100644--- a/file2+++ b/file2@@ -1,2 +1,3 @@ file1 file2+editing file2diff --git a/file3 b/file3index faf2282..c5dd702 100644--- a/file3+++ b/file3@@ -1,3 +1,4 @@ file1 file2 file3+I'm editing file3 now$ git diff HEAD~3 HEAD -- file3
diff --git a/file3 b/file3index faf2282..c5dd702 100644--- a/file3+++ b/file3@@ -1,3 +1,4 @@ file1 file2 file3+I'm editing file3 nowThere are many, many options for git diff, and I won’t go into them all, but I do want to explore another use case, which I use frequently, showing the files that were changed in a commit.
In your current repo, the most recent commit on master added a line of text to file1. You can see that by comparing HEAD with HEAD^:
$ git diff HEAD^ HEAD
diff --git a/file1 b/file1index e212970..04dbd7b 100644--- a/file1+++ b/file1@@ -1 +1,2 @@ file1+editing file1That’s fine for this small example, but frequently the diffs for a commit can be several pages long, and it can get quite difficult to pull out the filenames. Of course, Git has an option to help with that:
$ git diff HEAD^ HEAD --name-only
file1The --name-only option will show you the list of filename that were changed between two commits, but not what changed in those files.
As I said above, there are many options and use cases covered by the git diff command, and you’ve just scratched the surface here. Once you have the commands listed above figured out, I encourage you to look at git diff --help and see what other tricks you can find. I definitely learned new things preparing this tutorial!
git difftoolGit has a mechanism to use a visual diff tool to show diffs instead of just using the command line format we’ve seen thus far. All of the options and features you looked at with git diff still work here, but it will show the diffs in a separate window, which many people, myself included, find easier to read. For this example, I’m going to use meld as the diff tool because it’s available on Windows, Mac, and Linux.
Difftool is something that is much easier to use if you set it up properly. Git has a set of config options that control the defaults for difftool. You can set these from the shell using the git config command:
$ git config --global diff.tool meld
$ git config --global difftool.prompt falseThe prompt option is one I find important. If you do not specify this, Git will prompt you before it launches the external build tool every time it starts. This can be quite annoying as it does it for every file in a diff, one at a time:
$ git difftool HEAD^ HEAD
Viewing (1/1): 'python-git-intro/new_section.md'Launch 'meld' [Y/n]: ySetting prompt to false forces Git to launch the tool without asking, speeding up your process and making you that much better!
In the diff discussion above, you covered most of the features of difftool, but I wanted to add one thing I learned while researching for this article. Do you remember above when you were looking at the git stash show command? I mentioned that there was a way to see what is in a given stash visually, and difftool is that way. All of the syntax we learned for addressing stashes works with difftool:
$ git difftool stash@{1}As with all stash subcommands, if you just want to see the latest stash, you can use the stash shortcut:
$ git difftool stash
Many IDEs and editors have tools that can help with viewing diffs. There is a list of editor-specific tutorials at the end of the Introduction to Git tutorial.
One feature of Git that frightens some people is that it has the ability to change commits. While I can understand their concern, this is part of the tool, and, like any powerful tool, you can cause trouble if you use it unwisely.
We’ll talk about several ways to modify commits, but before we do, let’s discuss when this is appropriate. In previous sections you saw the difference between your local repo and a remote repo. Commits that you have created but have not pushed are in your local repo only. Commits that other developers have pushed but you have not pulled are in the remote repo only. Doing a push or a pull will get these commits into both repos.
The only time you should be thinking about modifying a commit is if it exists on your local repo and not the remote. If you modify a commit that has already been pushed from the remote, you are very likely to have a difficult time pushing or pulling from that remote, and your coworkers will be unhappy with you if you succeed.
That caveat aside, let’s talk about how you can modify commits and change history!
git commit --amendWhat do you do if you just made a commit but then realize that flake8 has an error when you run it? Or you spot a typo in the commit message you just entered? Git will allow you to “amend” a commit:
$ git commit -m "I am bad at spilling"[master 63f74b7] I am bad at spilling 1 file changed, 4 insertions(+)$ git commit --amend -m "I am bad at spelling"[master 951bf2f] I am bad at spelling Date: Tue May 22 20:41:27 2018 -0600 1 file changed, 4 insertions(+)Now if you look at the log after the amend, you’ll see that there was only one commit, and it has the correct message:
$ git log
commit 951bf2f45957079f305e8a039dea1771e14b503cAuthor: Jim Anderson <your_email_here@gmail.com>Date: Tue May 22 20:41:27 2018 -0600 I am bad at spellingcommit c789957055bd81dd57c09f5329c448112c1398d8Author: Jim Anderson <your_email_here@gmail.com>Date: Tue May 22 20:39:17 2018 -0600 new message[rest of log deleted]If you had modified and added files before the amend, those would have been included in the single commit as well. You can see that this is a handy tool for fixing mistakes. I’ll warn you again that doing a commit --amend modifies the commit. If the original commit was pushed to a remote repo, someone else may already have based changes on it. That would be a mess, so only use this for commits that are local-only.
git rebaseA rebase operation is similar to a merge, but it can produce a much cleaner history. When you rebase, Git will find the common ancestor between your current branch and the specified branch. It will then take all of the changes after that common ancestor from your branch and “replay” them on top of the other branch. The result will look like you did all of your changes after the other branch.
This can be a little hard to visualize, so let’s look at some actual commits. For this exercise, I’m going to use the --oneline option on the git log command to cut down on the clutter. Let’s start with a feature branch you’ve been working on called my_feature_branch. Here’s the state of that branch:
$ git log --oneline
143ae7f second feature commitaef68dc first feature commit2512d27 Common Ancestor CommitYou can see that the --oneline option, as you might expect, shows just the SHA and the commit message for each commit. Your branch has two commits after the one labeled 2512d27 Common Ancestor Commit.
You need a second branch if you’re going to do a rebase and master seems like a good choice. Here’s the current state of the master branch:
$ git log --oneline master
23a558c third master commit5ec06af second master commit190d6af first master commit2512d27 Common Ancestor CommitThere are three commits on master after 2512d27 Common Ancestor Commit. While you still have my_feature_branch checked out, you can do a rebase to put the two feature commits after the three commits on master:
$ git rebase master
First, rewinding head to replay your work on top of it...Applying: first feature commitApplying: second feature commit$ git log --oneline
cf16517 second feature commit69f61e9 first feature commit23a558c third master commit5ec06af second master commit190d6af first master commit2512d27 Common Ancestor CommitThere are two things to notice in this log listing:
1) As advertised, the two feature commits are after the three master commits.
2) The SHAs of those two feature commits have changed.
The SHAs are different because the repo is slightly different. The commits represent the same changes to the files, but since they were added on top of the changes already in master, the state of the repo is different, so they have different SHAs.
If you had done a merge instead of a rebase, there would have been a new commit with the message Merge branch 'master' into my_feature_branch, and the SHAs of the two feature commits would be unchanged. Doing a rebase avoids the extra merge commit and makes your revision history cleaner.
git pull -rUsing a rebase can be a handy tool when you’re working on a branch with a different developer, too. If there are changes on the remote, and you have local commits to the same branch, you can use the -r option on the git pull command. Where a normal git pull does a merge to the remote branch, git pull -r will rebase your commits on top of the changes that were on the remote.
git rebase -iThe rebase command has another method of operation. There is a -i flag you can add to the rebase command that will put it into interactive mode. While this seems confusing at first, it is an amazingly powerful feature that lets you have full control over the list of commits before you push them to a remote. Please remember the warning about not changing the history of commits that have been pushed.
These examples show a basic interactive rebase, but be aware that there are more options and more use cases. The git rebase --help command will give you the list and actually does a good job of explaining them.
For this example, you’re going to imagine you’ve been working on your Python library, committing several times to your local repo as you implement a solution, test it, discover a problem and fix it. At the end of this process you have a chain of commits on you local repo that all are part of the new feature. Once you’ve finished the work, you look at your git log:
$ git log --oneline
8bb7af8 implemented feedback from code review504d520 added unit test to cover new bug56d1c23 more flake8 clean upd9b1f9e restructuring to clean up08dc922 another bug fix7f82500 pylint cleanupa113f67 found a bug fixing3b8a6f2 First attempt at solutionaf21a53 [older stuff here]There are several commits here that don’t add value to other developers or even to you in the future. You can use rebase -i to create a “squash commit” and put all of these into a single point in history.
To start the process, you run git rebase -i af21a53, which will bring up an editor with a list of commits and some instructions:
pick 3b8a6f2 First attempt at solution
pick a113f67 found a bug fixing
pick 7f82500 pylint cleanup
pick 08dc922 another bug fix
pick d9b1f9e restructuring to clean up
pick 56d1c23 more flake8 clean up
pick 504d520 added unit test to cover new bug
pick 8bb7af8 implemented feedback from code review
# Rebase af21a53..8bb7af8 onto af21a53 (8 command(s))
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
You’ll notice that the commits are listed in reverse order, oldest first. This is the order in which Git will replay the commits on top of af21a53. If you just save the file at this point, nothing will change. This is also true if you delete all the text and save the file.
Also, there are several lines starting with a # reminding you how to edit this file. These comments can be removed but do not need to be.
But you want to squash all of these commits into one so that “future you” will know that this is the commit that completely added the feature. To do that, you can edit the file to look like this:
pick 3b8a6f2 First attempt at solution
squash a113f67 found a bug fixing
s 7f82500 pylint cleanup
s 08dc922 another bug fix
s d9b1f9e restructuring to clean up
s 56d1c23 more flake8 clean up
s 504d520 added unit test to cover new bug
s 8bb7af8 implemented feedback from code review
You can use either the full word for the commands, or, as you did after the first two lines, use the single character version. The example above selected to “pick” the oldest commit and the “squash” each of the subsequent commits into that one. If you save and exit the editor, Git will proceed to put all of those commits into one and then will bring up the editor again, listing all of the commit messages for the squashed commit:
# This is a combination of 8 commits.
# The first commit's message is:
Implemented feature ABC
# This is the 2nd commit message:
found a bug fixing
# This is the 3rd commit message:
pylint cleanup
# This is the 4th commit message:
another bug fix
[the rest trimmed for brevity]
By default a squash commit will have a long commit message with all of the messages from each commit. In your case it’s better to reword the first message and delete the rest. Doing that and saving the file will finish the process, and your log will now have only a single commit for this feature:
$ git log --oneline
9a325ad Implemented feature ABCaf21a53 [older stuff here]Cool! You just hid any evidence that you had to do more than one commit to solve this issue. Good work! Be warned that deciding when to do a squash merge is frequently more difficult than the actual process. There’s a great article that does a nice job of laying out the complexities.
As you probably guessed, git rebase -i will allow you to do far more complex operations. Let’s look at one more example.
In the course of a week, you’ve worked on three different issues, committing changes at various times for each. There’s also a commit in there that you regret and would like to pretend never happened. Here’s your starting log:
$ git log --oneline
2f0a106 feature 3 commit 3f0e14d2 feature 2 commit 3b2eec2c feature 1 commit 3d6afbee really rotten, very bad commit6219ba3 feature 3 commit 270e07b8 feature 2 commit 2c08bf37 feature 1 commit 2c9747ae feature 3 commit 1fdf23fc feature 2 commit 10f05458 feature 1 commit 13ca2262 older stuff hereYour mission is to get this into three clean commits and remove that one bad one. You can follow the same process, git rebase -i 3ca2262, and Git presents you with the command file:
pick 0f05458 feature 1 commit 1
pick fdf23fc feature 2 commit 1
pick c9747ae feature 3 commit 1
pick c08bf37 feature 1 commit 2
pick 70e07b8 feature 2 commit 2
pick 6219ba3 feature 3 commit 2
pick d6afbee really rotten, very bad commit
pick b2eec2c feature 1 commit 3
pick f0e14d2 feature 2 commit 3
pick 2f0a106 feature 3 commit 3
Interactive rebase allows your to not only specify what to do with each commit but also lets you rearrange them. So, to get to your three commits, you edit the file to look like this:
pick 0f05458 feature 1 commit 1
s c08bf37 feature 1 commit 2
s b2eec2c feature 1 commit 3
pick fdf23fc feature 2 commit 1
s 70e07b8 feature 2 commit 2
s f0e14d2 feature 2 commit 3
pick c9747ae feature 3 commit 1
s 6219ba3 feature 3 commit 2
s 2f0a106 feature 3 commit 3
# pick d6afbee really rotten, very bad commit
The commits for each feature are grouped together with only one of them being “picked” and the rest “squashed.” Commenting out the bad commit will remove it, but you could have just as easily deleted that line from the file to the same effect.
When you save that file, you’ll get a separate editor session to create the commit message for each of the three squashed commits. If you call them feature 1, feature 2, and feature 3, your log will now have only those three commits, one for each feature:
$ git log --oneline
f700f1f feature 3443272f feature 20ff80ca feature 13ca2262 older stuff hereJust like any rebase or merge, you might run into conflicts in this process, which you will need to resolve by editing the file, getting the changes correct, git add-ing the file, and running git rebase --continue.
I’ll end this section by pointing out a few things about rebase:
1) Creating squash commits is a “nice to have” feature, but you can still work successfully with Git without using it.
2) Merge conflicts on large interactive rebases can be confusing. None of the individual steps are difficult, but there can be a lot of them
3) We’ve just scratched the surface on what you can do with git rebase -i. There are more features here than most people will ever discover.
git revert vs. git reset: Cleaning UpUnsurprisingly, Git provides you several methods for cleaning up when you’ve made a mess. These techniques depend on what state your repo is in and whether or not the mess is local to your repo or has been pushed to a remote.
Let’s start by looking at the easy case. You’ve made a commit that you don’t want, and it hasn’t been pushed to remote. Start by creating that commit so you know what you’re looking at:
$ ls >> file_i_do_not_want
$ git add file_i_do_not_want
$ git commit -m "bad commit"[master baebe14] bad commit 2 files changed, 31 insertions(+) create mode 100644 file_i_do_not_want$ git log --oneline
baebe14 bad commit443272f feature 20ff80ca feature 13ca2262 older stuff hereThe example above created a new file, file_i_do_not_want, and committed it to the local repo. It has not been pushed to the remote repo yet. The rest of the examples in this section will use this as a starting point.
To manage commits that are on the local repo only, you can use the git reset command. There are two options to explore: --soft and --hard.
The git reset --soft <SHA> command tells Git to move HEAD back to the specified SHA. It doesn’t change the local file system, and it doesn’t change the index. I’ll admit when I read that description, it didn’t mean much to me, but looking at the example definitely helps:
$ git reset --soft HEAD^
$ git status
On branch masterChanges to be committed: (use "git reset HEAD <file>..." to unstage) new file: file_i_do_not_want$ git log --oneline
443272f feature 20ff80ca feature 13ca2262 older stuff hereIn the example, we reset HEAD to HEAD^. Remember that ^ tells Git to step back one commit. The --soft option told Git to not change the index or the local file system, so the file_i_do_not_want is still in the index in the “Changes to be committed:” state. The git log command shows that the bad commit was removed from the history, though.
That’s what the --soft option does. Now let’s look at the --hard option. Let’s go back to your original state so that bad commit is in the repo again and try --hard:
$ git log --oneline
2e9d704 bad commit443272f feature 20ff80ca feature 13ca2262 older stuff here$ git reset --hard HEAD^
HEAD is now at 443272f feature 2$ git status
On branch masternothing to commit, working directory clean$ git log --oneline
443272f feature 20ff80ca feature 13ca2262 older stuff hereThere are several things to notice here. First the reset command actually gives you feedback on the --hard option where it does not on the --soft. I’m not sure of why this is, quite honestly. Also, when we do the git status and git log afterwards, you see that not only is the bad commit gone, but the changes that were in that commit have also been wiped out. The --hard option resets you completely back to the SHA you specified.
Now, if you remember the last section about changing history in Git, it’s dawned on you that doing a reset to a branch you’ve already pushed to a remote might be a bad idea. It changes the history and that can really mess up your co-workers.
Git, of course, has a solution for that. The git revert command allows you to easily remove the changes from a given commit but does not change history. It does this by doing the inverse of the commit you specify. If you added a line to a file, git revert will remove that line from the file. It does this and automatically creates a new “revert commit” for you.
Once again, reset the repo back to the point that bad commit is the most recent commit. First confirm what the changes are in bad commit:
$ git diff HEAD^
diff --git a/file_i_do_not_want b/file_i_do_not_wantnew file mode 100644index 0000000..6fe5391--- /dev/null+++ b/file_i_do_not_want@@ -0,0 +1,6 @@+file1+file2+file3+file4+file_i_do_not_want+growing_fileYou can see that we’ve simply added the new file_i_do_not_want to the repo. The lines below @@ -0,0 +1,6 @@ are the contents of that new file. Now, assuming that this time you’ve pushed that bad commit to master and you don’t want your co-workers to hate you, use revert to fix that mistake:
$ git revert HEAD
[master 8a53ee4] Revert "bad commit" 1 file changed, 6 deletions(-) delete mode 100644 file_i_do_not_wantWhen you run that command, Git will pop up an editor window allowing you to modify the commit message for the revert commit:
Revert "bad commit"
This reverts commit 1fec3f78f7aea20bf99c124e5b75f8cec319de10.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# deleted: file_i_do_not_want
#
Unlike commit, git revert does not have an option for specifying the commit message on the command line. You can use -n to skip the message editing step and tell Git to simply use the default message.
After we revert the bad commit, our log shows a new commit with that message:
$ git log --oneline
8a53ee4 Revert "bad commit"1fec3f7 bad commit443272f feature 20ff80ca feature 13ca2262 older stuff hereThe “bad commit” is still there. It needs to be there because you don’t want to change history in this case. There’s a new commit, however, which “undoes” the changes that are in that commit.
git cleanThere’s another “clean up” command that I find useful, but I want to present it with a caution.
Caution: Using git clean can wipe out files that are not committed to the repo that you will not be able to recover.
git clean does what you guess it would: it cleans up your local working directory. I’ve found this quite useful when something large goes wrong and I end up with several files on my file system that I do not want.
In its simple form, git clean simply removes files that are not “under version control.” This means that files that show up in the Untracked files section when you look at git status will be removed from the working tree. There is not a way to recover if you do this accidentally, as those files were not in version control.
That’s handy, but what if you want to remove all of the pyc files created with your Python modules? Those are in your .gitignore file, so they don’t show up as Untracked and they don’t get deleted by git clean.
The -x option tells git clean to remove untracked and ignored files, so git clean -x will take care of that problem. Almost.
Git is a little conservative with the clean command and won’t remove untracked directories unless you tell it to do so. Python 3 likes to create __pycache__directories, and it’d be nice to clean these up, too. To solve this, you would add the -d option. git clean -xd will clean up all of the untracked and ignored files and directories.
Now, if you’ve raced ahead and tested this out, you’ve noticed that it doesn’t actually work. Remember that warning I gave at the beginning of this section? Git tries to be cautious when it comes to deleting files that you can’t recover. So, if you try the above command, you see an error message:
$ git clean -xd
fatal: clean.requireForce defaults to true and neither -i, -n, nor -f given; refusing to cleanWhile it’s possible to change your git config files to not require it, most people I’ve talked to simply get used to using the -f option along with the others:
$ git clean -xfd
Removing file_to_deleteAgain, be warned that git clean -xfd will remove files that you will not be able to get back, so please use this with caution!
When you’re new to Git, merge conflicts seem like a scary thing, but with a little practice and a few tricks, they can become much easier to deal with.
Let’s start with some of the tricks that can make this easier. The first one changes the format of how conflicts are shown.
diff3 FormatWe’ll walk through a simple example to see what Git does by default and what options we have to make it easier. To do this, create a new file, merge.py, that looks like this:
defdisplay():print("Welcome to my project!")Add and commit this file to your branch master, and this will be your baseline commit. You’ll create branches that modify this file in different ways, and then you’ll see how to resolve the merge conflict.
You now need to create separate branches that will have conflicting changes. You’ve seen how this is done before, so I won’t describe it in detail:
$ git checkout -b mergebranch
Switched to a new branch 'mergebranch'$ vi merge.py # edit file to change 'project' to 'program'$ git add merge.py
$ git commit -m "change project to program"[mergebranch a775c38] change project to program 1 file changed, 1 insertion(+), 1 deletion(-)$ git status
On branch mergebranchnothing to commit, working directory clean$ git checkout master
Switched to branch 'master'$ vi merge.py # edit file to add 'very cool' before project$ git add merge.py
$ git commit -m "added description of project"[master ab41ed2] added description of project 1 file changed, 1 insertion(+), 1 deletion(-)$ git show-branch master mergebranch
* [master] added description of project ! [mergebranch] change project to program--* [master] added description of project + [mergebranch] change project to program*+ [master^] baseline for mergingAt this point you have conflicting changes on mergebranch and master. Using the show-branch command we learned in our Intro tutorial, you can see this visually on the command line:
$ git show-branch master mergebranch
* [master] added description of project ! [mergebranch] change project to program--* [master] added description of project + [mergebranch] change project to program*+ [master^] baseline for mergingYou’re on branch master, so let’s try to merge in mergebranch. Since you’ve made the changes with the intent of creating a merge conflict, lets hope that happens:
$ git merge mergebranch
Auto-merging merge.pyCONFLICT (content): Merge conflict in merge.pyAutomatic merge failed; fix conflicts and then commit the result.As you expected, there’s a merge conflict. If you look at status, there’s a good deal of useful information there. Not only does it say that you’re in the middle of a merge, You have unmerged paths, but it also shows you which files are modified, merge.py:
$ git status
On branch masterYou have unmerged paths. (fix conflicts and run "git commit")Unmerged paths: (use "git add <file>..." to mark resolution) both modified: merge.pyno changes added to commit (use "git add" and/or "git commit -a")You have done all that work to get to the point of having a merge conflict. Now you can start learning about how to resolve it! For this first part, you’ll be working with the command line tools and your editor. After that, you’ll get fancy and look at using visual diff tools to solve the problem.
When you open merge.py in your editor, you can see what Git produced:
defdisplay():<<<<<<<HEADprint("Welcome to my very cool project!")=======print("Welcome to my program!")>>>>>>>mergebranchGit uses diff syntax from Linux to display the conflict. The top portion, between <<<<<<< HEAD and =======, are from HEAD, which in your case is master. The bottom portion, between ======= and >>>>>>> mergebranch are from, you guessed it, mergebranch.
Now, in this very simple example, it’s pretty easy to remember which changes came from where and how we should merge this, but there’s a setting you can enable which will make this easier.
The diff3 setting modifies the output of merge conflicts to more closely approximate a three-way merge, meaning in this case that it will show you what’s in master, followed by what it looked like in the common ancestor, followed by what it looks like in mergebranch:
defdisplay():<<<<<<<HEADprint("Welcome to my very cool project!")|||||||mergedcommonancestorsprint("Welcome to my project!")=======print("Welcome to my program!")>>>>>>>mergebranchNow that you can see the starting point, “Welcome to my project!”, you can see exactly what change was made on master and what change was made on mergebranch. This might not seem like a big deal on such a simple example, but it can make a huge difference on large conflicts, especially merges where someone else made some of the changes.
You can set this option in Git globally by issuing the following command:
$ git config --global merge.conflictstyle diff3
Okay, so you understand how to see the conflict. Let’s go through how to fix it. Start by editing the file, removing all of the markers Git added, and making the one conflicting line correct:
defdisplay():print("Welcome to my very cool program!")You then add your modified file to the index and commit your merge. This will finish the merge process and create the new node:
$ git add merge.py
$ git commit
[master a56a01e] Merge branch 'mergebranch'$ git log --oneline
a56a01e Merge branch 'mergebranch'ab41ed2 added description of projecta775c38 change project to programf29b775 baseline for mergingMerge conflicts can happen while you’re cherry-picking, too. The process when you are cherry-picking is slightly different. Instead of using the git commit command, you use the git cherry-pick --continue command. Don’t worry, Git will tell you in the status message which command you need to use. You can always go back and check that to be sure.
git mergetoolSimilar to git difftool, Git will allow you to configure a visual diff tool to deal with three-way merges. It knows about several different tools on different operating systems. You can see the list of tools it knows about on your system by using the command below. On my Linux machine, it shows the following:
$ git mergetool --tool-help
'git mergetool --tool=<tool>' may be set to one of the following: araxis gvimdiff gvimdiff2 gvimdiff3 meld vimdiff vimdiff2 vimdiff3The following tools are valid, but not currently available: bc bc3 codecompare deltawalker diffmerge diffuse ecmerge emerge kdiff3 opendiff p4merge tkdiff tortoisemerge winmerge xxdiffSome of the tools listed above only work in a windowedenvironment. If run in a terminal-only session, they will fail.Also similar to difftool, you can configure the mergetool options globally to make it easier to use:
$ git config --global merge.tool meld
$ git config --global mergetool.prompt falseThe final option, mergetool.prompt, tells Git not to prompt you each time it opens a window. This might not sound annoying, but when your merge involves several files it will prompt you between each of them.
You’ve covered a lot of ground in these tutorials, but there is so much more to Git. If you’d like to take a deeper dive into Git, I can recommend these resources:
--help is useful for any of the subcommands you know. git diff --help produces almost 1000 lines of information. While portions of these are quite detailed, and some of them assume a deep knowledge of Git, reading the help for commands you use frequently can teach you new tricks on how to use them.[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
django-html-validator is a Django project that can validate your generated HTML. It does so by sending the HTML to https://html5.validator.nu/ or you can start your own Java server locally with vnu.jar from here.
The output is that you can have validation errors printed to stdout or you can have them put as .txt files in a temporary directory. You can also include it in your test suite and make it so that tests fail if invalid HTML is generated during rendering in Django unit tests.
The project seems to have become a lot more popular than I thought it would. It started as a one-evening-hack and because there was interest I wrapped it up in a proper project with "docs" and set up CI for future contributions.
I kinda of forgot the project since almost all my current projects generate JSON on the server and generates the DOM on-the-fly with client-side JavaScript but apparently a lot of issues and PRs were filed related to making it work in Django 2.x. So I took the time last night to tidy up the tox.ini etc. and the necessary compatibility fixes to make it work with but Django 1.8 up to Django 2.1. Pull request here.
Thank you all who contributed! I'll try to make a better job noticing filed issues in the future.





