Learn how to use Python’s email and smtp modules in this video. You can also read the written version of this video here: http://python101.pythonlibrary.org/ or get the book here: https://leanpub.com/python_101
↧
Mike Driscoll: Python 101: Episode #17 – The email and smtp modules
↧
PyCon.DE & PyData Karlsruhe: PyCon.DE & PyData Karlsruhe 2018 Keynote: Wes McKinney
We are very happy to confirm Wes McKinney as a keynote speaker for PyCon.DE 2018 & PyData Karlsruhe.

Wes McKinney has been creating fast, easy-to-use data wrangling and statistical computing tools, mostly in the Python programming language, since 2007. He is best known for creating the pandas project and writing the book Python for Data Analysis. He is a PMC member of the Apache Arrow and Parquet projects in The Apache SoftwareFoundation.
↧
↧
Bhishan Bhandari: Python Variables
The intentions of this blog is to familiarize with how variables are assigned, the mechanism behind variable assignment, discuss equal status and how almost everything is an object in python, manipulations of objects held by the symbolic names that act as containers and termed as variables. Variable Assignment In Python, you don’t really assign a […]
The post Python Variables appeared first on The Tara Nights.
↧
Real Python: Documenting Python Code: A Complete Guide
Welcome to your complete guide to documenting Python code. Whether you’re documenting a small script or a large project, whether you’re a beginner or seasoned Pythonista, this guide will cover everything you need to know.
We’ve broken up this tutorial into four major sections:
- Why Documenting Your Code Is So Important: An introduction to documentation and its importance
- Commenting vs. Documenting Code: An overview of the major differences between commenting and documenting, as well as the appropriate times and ways to use commenting
- Documenting Your Python Code Base Using Docstrings: A deep dive into docstrings for classes, class methods, functions, modules, packages, and scripts, as well as what should be found within each one
- Documenting Your Python Projects: The necessary elements and what they should contain for your Python projects
Feel free to read through this tutorial from beginning to end or jump to a section you’re interested in. It was designed to work both ways.
Why Documenting Your Code Is So Important
Hopefully, if you’re reading this tutorial, you already know the importance of documenting your code. But if not, then let me quote something Guido mentioned to me at a recent PyCon:
“Code is more often read than executed.”
— Guido Van Rossum
When you write code, you write it for two primary audiences: your users and your developers (including yourself). Both audiences are equally important. If you’re like me, you’ve probably opened up old codebases and wondered to yourself, “What in the world was I thinking?” If you’re having a problem reading your own code, imagine what your users or other developers are experiencing when they’re trying to use or contribute to your code.
Conversely, I’m sure you’ve run into a situation where you wanted to do something in Python and found what looks like a great library that can get the job done. However, when you start using the library, you look for examples, write-ups, or even official documentation on how to do something specific and can’t immediately find the solution.
After searching, you come to realize that the documentation is lacking or even worse, missing entirely. This is a frustrating feeling that deters you from using the library, no matter how great or efficient the code is. Daniele Procida summarized this situation best:
“It doesn’t matter how good your software is, because if the documentation is not good enough, people will not use it.“
In this guide, you’ll learn from the ground up how to properly document your Python code from the smallest of scripts to the largest of Python projects to help prevent your users from ever feeling too frustrated to use or contribute to your project.
Commenting vs. Documenting Code
Before we can go into how to document your Python code, we need to distinguish documenting from commenting.
In general, commenting is describing your code to/for developers. The intended main audience is the maintainers and developers of the Python code. In conjunction with well-written code, comments help to guide the reader to better understand your code and its purpose and design:
“Code tells you how; Comments tell you why.”
— Jeff Atwood (aka Coding Horror)
Documenting code is describing its use and functionality to your users. While it may be helpful in the development process, the main intended audience is the users. The following section describes how and when to comment your code.
Basics of Commenting Code
Comments are created in Python using the pound sign (#) and should be brief statements no longer than a few sentences. Here’s a simple example:
defhello_world():# A simple comment preceding a simple print statementprint("Hello World")According to PEP 8, comments should have a maximum length of 72 characters. This is true even if your project changes the max line length to be greater than the recommended 80 characters. If a comment is going to be greater than the comment char limit, using multiple lines for the comment is appropriate:
defhello_long_world():# A very long statement that just goes on and on and on and on and# never ends until after it's reached the 80 char limitprint("Hellooooooooooooooooooooooooooooooooooooooooooooooooooooooo World")Commenting your code serves multiple purposes, including:
Planning and Reviewing: When you are developing new portions of your code, it may be appropriate to first use comments as a way of planning or outlining that section of code. Remember to remove these comments once the actual coding has been implemented and reviewed/tested:
# First step# Second step# Third step
Code Description: Comments can be used to explain the intent of specific sections of code:
# Attempt a connection based on previous settings. If unsuccessful,# prompt user for new settings.
Algorithmic Description: When algorithms are used, especially complicated ones, it can be useful to explain how the algorithm works or how it’s implemented within your code. It may also be appropriate to describe why a specific algorithm was selected over another.
# Using quick sort for performance gainsTagging: The use of tagging can be used to label specific sections of code where known issues or areas of improvement are located. Some examples are:
BUG,FIXME, andTODO.# TODO: Add condition for when val is None
Comments to your code should be kept brief and focused. Avoid using long comments when possible. Additionally, you should use the following four essential rules as suggested by Jeff Atwood:
Keep comments as close to the code being described as possible. Comments that aren’t near their describing code are frustrating to the reader and easily missed when updates are made.
Don’t use complex formatting (such as tables or ASCII figures). Complex formatting leads to distracting content and can be difficult to maintain over time.
Don’t include redundant information. Assume the reader of the code has a basic understanding of programming principles and language syntax.
Design your code to comment itself. The easiest way to understand code is by reading it. When you design your code using clear, easy-to-understand concepts, the reader will be able to quickly conceptualize your intent.
Remember that comments are designed for the reader, including yourself, to help guide them in understanding the purpose and design of the software.
Commenting Code via Type Hinting (Python 3.5+)
Type hinting was added to Python 3.5 and is an additional form to help the readers of your code. In fact, it takes Jeff’s fourth suggestion from above to the next level. It allows the developer to design and explain portions of their code without commenting. Here’s a quick example:
defhello_name(name:str)->str:return(f"Hello {name}")From examining the type hinting, you can immediately tell that the function expects the input name to be of a type str, or string. You can also tell that the expected output of the function will be of a type str, or string, as well. While type hinting helps reduce comments, take into consideration that doing so may also make extra work when you are creating or updating your project documentation.
You can learn more about type hinting and type checking from this video created by Dan Bader.
Documenting Your Python Code Base Using Docstrings
Now that we’ve learned about commenting, let’s take a deep dive into documenting a Python code base. In this section, you’ll learn about docstrings and how to use them for documentation. This section is further divided into the following sub-sections:
- Docstrings Background: A background on how docstrings work internally within Python
- Docstring Types: The various docstring “types” (function, class, class method, module, package, and script)
- Docstring Formats: The different docstring “formats” (Google, NumPy/SciPy, reStructured Text, and Epytext)
Docstrings Background
Documenting your Python code is all centered on docstrings. These are built-in strings that, when configured correctly, can help your users and yourself with your project’s documentation. Along with docstrings, Python also has the built-in function help() that prints out the objects docstring to the console. Here’s a quick example:
>>> help(str)Help on class str in module builtins:class str(object) | str(object='') -> str | str(bytes_or_buffer[, encoding[, errors]]) -> str | | Create a new string object from the given object. If encoding or | errors are specified, then the object must expose a data buffer | that will be decoded using the given encoding and error handler. | Otherwise, returns the result of object.__str__() (if defined) | or repr(object). | encoding defaults to sys.getdefaultencoding(). | errors defaults to 'strict'. # Truncated for readabilityHow is this output generated? Since everything in Python is an object, you can examine the directory of the object using the dir() command. Let’s do that and see what find:
>>> dir(str)['__add__', ..., '__doc__', ..., 'zfill'] # Truncated for readabilityWithin that directory output, there’s an interesting property, __doc__. If you examine that property, you’ll discover this:
>>> print(str.__doc__)str(object='') -> strstr(bytes_or_buffer[, encoding[, errors]]) -> strCreate a new string object from the given object. If encoding orerrors are specified, then the object must expose a data bufferthat will be decoded using the given encoding and error handler.Otherwise, returns the result of object.__str__() (if defined)or repr(object).encoding defaults to sys.getdefaultencoding().errors defaults to 'strict'.Voilà! You’ve found where docstrings are stored within the object. This means that you can directly manipulate that property. However, there are restrictions for builtins:
>>> str.__doc__="I'm a little string doc! Short and stout; here is my input and print me for my out"Traceback (most recent call last):
File "<stdin>", line 1, in <module>TypeError: can't set attributes of built-in/extension type 'str'Any other custom object can be manipulated:
defsay_hello(name):print(f"Hello {name}, is it me you're looking for?")say_hello.__doc__="A simple function that says hello... Richie style">>> help(say_hello)Help on function say_hello in module __main__:say_hello(name) A simple function that says hello... Richie stylePython has one more feature that simplifies docstring creation. Instead of directly manipulating the __doc__ property, the strategic placement of the string literal directly below the object will automatically set the __doc__ value. Here’s what happens with the same example as above:
defsay_hello(name):"""A simple function that says hello... Richie style"""print(f"Hello {name}, is it me you're looking for?")>>> help(say_hello)Help on function say_hello in module __main__:say_hello(name) A simple function that says hello... Richie styleThere you go! Now you understand the background of docstrings. Now it’s time to learn about the different types of docstrings and what information they should contain.
Docstring Types
Docstring conventions are described within PEP 257. Their purpose is to provide your users with a brief overview of the object. They should be kept concise enough to be easy to maintain but still be elaborate enough for new users to understand their purpose and how to use the documented object.
In all cases, the docstrings should use the triple-double quote (""") string format. This should be done whether the docstring is multi-lined or not. At a bare minimum, a docstring should be a quick summary of whatever is it you’re describing and should be contained within a single line:
"""This is a quick summary line used as a description of the object."""Multi-lined docstrings are used to further elaborate on the object beyond the summary. All multi-lined docstrings have the following parts:
- A one-line summary line
- A blank line proceeding the summary
- Any further elaboration for the docstring
- Another blank line
"""This is the summary lineThis is the further elaboration of the docstring. Within this section,you can elaborate further on details as appropriate for the situation.Notice that the summary and the elaboration is separated by a blank newline."""# Notice the blank line above. Code should continue on this line.All docstrings should have the same max character length as comments (72 characters). Docstrings can be further broken up into three major categories:
- Class Docstrings: Class and class methods
- Package and Module Docstrings: Package, modules, and functions
- Script Docstrings: Script and functions
Class Docstrings
Class Docstrings are created for the class itself, as well as any class methods. The docstrings are placed immediately following the class or class method indented by one level:
classSimpleClass:"""Class docstrings go here."""defsay_hello(self,name:str):"""Class method docstrings go here."""print(f'Hello {name}')Class docstrings should contain the following information:
- A brief summary of its purpose and behavior
- Any public methods, along with a brief description
- Any class properties (attributes)
- Anything related to the interface for subclassers, if the class is intended to be subclassed
The class constructor parameters should be documented within the __init__ class method docstring. Individual methods should be documented using their individual docstrings. Class method docstrings should contain the following:
- A brief description of what the method is and what it’s used for
- Any arguments (both required and optional) that are passed including keyword arguments
- Label any arguments that are considered optional or have a default value
- Any side effects that occur when executing the method
- Any exceptions that are raised
- Any restrictions on when the method can be called
Let’s take a simple example of a data class that represents an Animal. This class will contain a few class properties, instance properties, a __init__, and a single instance method:
classAnimal:""" A class used to represent an Animal ... Attributes ---------- says_str : str a formatted string to print out what the animal says name : str the name of the animal sound : str the sound that the animal makes num_legs : int the number of legs the animal has (default 4) Methods ------- says(sound=None) Prints the animals name and what sound it makes"""says_str="A {name} says {sound}"def__init__(self,name,sound,num_legs):""" Parameters ---------- name : str The name of the animal sound : str The sound the animal makes num_legs : int, optional The number of legs the animal (default is 4)"""self.name=nameself.sound=soundself.num_legs=num_legsdefsays(self,sound=None):"""Prints what the animals name is and what sound it makes. If the argument `sound` isn't passed in, the default Animal sound is used. Parameters ---------- sound : str, optional The sound the animal makes (default is None) Raises ------ NotImplementedError If no sound is set for the animal or passed in as a parameter."""ifself.soundisNoneandsoundisNone:raiseNotImplementedError("Silent Animals are not supported!")out_sound=self.soundifsoundisNoneelsesoundprint(self.says_str.format(name=self.name,sound=out_sound))Package and Module Docstrings
Package docstrings should be placed at the top of the package’s __init__.py file. This docstring should list the modules and sub-packages that are exported by the package.
Module docstrings are similar to class docstrings. Instead of classes and class methods being documented, it’s now the module and any functions found within. Module docstrings are placed at the top of the file even before any imports. Module docstrings should include the following:
- A brief description of the module and its purpose
- A list of any classes, exception, functions, and any other objects exported by the module
The docstring for a module function should include the same items as a class method:
- A brief description of what the function is and what it’s used for
- Any arguments (both required and optional) that are passed including keyword arguments
- Label any arguments that are considered optional
- Any side effects that occur when executing the function
- Any exceptions that are raised
- Any restrictions on when the function can be called
Script Docstrings
Scripts are considered to be single file executables run from the console. Docstrings for scripts are placed at the top of the file and should be documented well enough for users to be able to have a sufficient understanding of how to use the script. It should be usable for its “usage” message, when the user incorrectly passes in a parameter or uses the -h option.
If you use argparse, then you can omit parameter-specific documentation, assuming it’s correctly been documented within the help parameter of the argparser.parser.add_argument function. It is recommended to use the __doc__ for the description parameter within argparse.ArgumentReader’s constructor. Check out our tutorial on Command-Line Parsing Libraries for more details on how to use argparse and other common command line parsers.
Finally, any custom or third-party imports should be listed within the docstrings to allow users to know which packages may be required for running the script. Here’s an example of a script that is used to simply print out the column headers of a spreadsheet:
"""Spreadsheet Column PrinterThis script allows the user to print to the console all columns in thespreadsheet. It is assumed that the first row of the spreadsheet is thelocation of the columns.This tool accepts comma separated value files (.csv) as well as excel(.xls, .xlsx) files.This script requires that `pandas` be installed within the Pythonenvironment you are running this script in.This file can also be imported as a module and contains the followingfunctions: * get_spreadsheet_cols - returns the column headers of the file * main - the main function of the script"""importargparseimportpandasaspddefget_spreadsheet_cols(file_loc,print_cols=False):"""Gets and prints the spreadsheet's header columns Parameters ---------- file_loc : str The file location of the spreadsheet print_cols : bool, optional A flag used to print the columns to the console (default is False) Returns ------- list a list of strings used that are the header columns"""file_data=pd.read_excel(file_loc)col_headers=list(file_data.columns.values)ifprint_cols:print("\n".join(col_headers))returncol_headersdefmain():parser=argparse.ArgumentParser(description=__doc__)parser.add_argument('intput_file',type=str,help="The spreadsheet file to pring the columns of")args=parser.parse_args()get_spreadsheet_cols(args.input_file,print_cols=True)if__name__=="__main__":main()Docstring Formats
You may have noticed that, throughout the examples given in this tutorial, there has been specific formatting with common elements: Arguments, Returns, and Attributes. There are specific docstrings formats that can be used to help docstring parsers and users have a familiar and known format. The formatting used within the examples in this tutorial are NumPy/SciPy-style docstrings. Some of the most common formats are the following:
| Formatting Type | Description | Supported by Sphynx | Formal Specification |
|---|---|---|---|
| Google docstrings | Google’s recommended form of documentation | Yes | No |
| reStructured Text | Official Python documentation standard; Not beginner friendly but feature rich | Yes | Yes |
| NumPy/SciPy docstrings | NumPy’s combination of reStructured and Google Docstrings | Yes | Yes |
| Epytext | A Python adaptation of Epydoc; Great for Java developers | Not officially | Yes |
The selection of the docstring format is up to you, but you should stick with the same format throughout your document/project. The following are examples of each type to give you an idea of how each documentation format looks.
Google Docstrings Example
"""Gets and prints the spreadsheet's header columnsParameters: file_loc (str): The file location of the spreadsheet print_cols (bool): A flag used to print the columns to the console (default is False)Returns: list: a list of strings representing the header columns"""reStructured Text Example
"""Gets and prints the spreadsheet's header columns:param file_loc: The file location of the spreadsheet:type file_loc: str:param print_cols: A flag used to print the columns to the console (default is False):type print_cols: bool:returns: a list of strings representing the header columns:rtype: list"""NumPy/SciPy Docstrings Example
"""Gets and prints the spreadsheet's header columnsParameters----------file_loc : str The file location of the spreadsheetprint_cols : bool, optional A flag used to print the columns to the console (default is False)Returns-------list a list of strings representing the header columns"""Epytext Example
"""Gets and prints the spreadsheet's header columns@type file_loc: str@param file_loc: The file location of the spreadsheet@type print_cols: bool@param print_cols: A flag used to print the columns to the console (default is False)@rtype: list@returns: a list of strings representing the header columns"""Documenting Your Python Projects
Python projects come in all sorts of shapes, sizes, and purposes. The way you document your project should suit your specific situation. Keep in mind who the users of your project are going to be and adapt to their needs. Depending on the project type, certain aspects of documentation are recommended. The general layout of the project and its documentation should be as follows:
project_root/
│
├── project/ # Project source code
├── docs/
├── README
├── HOW_TO_CONTRIBUTE
├── CODE_OF_CONDUCT
├── examples.py
Projects can be generally subdivided into three major types: Private, Shared, and Public/Open Source.
Private Projects
Private projects are projects intended for personal use only and generally aren’t shared with other users or developers. Documentation can be pretty light on these types of projects. There are some recommended parts to add as needed:
- Readme: A brief summary of the project and its purpose. Include any special requirements for installation or operating the project.
examples.py: A Python script file that gives simple examples of how to use the project.
Remember, even though private projects are intended for you personally, you are also considered a user. Think about anything that may be confusing to you down the road and make sure to capture those in either comments, docstrings, or the readme.
Shared Projects
Shared projects are projects in which you collaborate with a few other people in the development and/or use of the project. The “customer” or user of the project continues to be yourself and those limited few that use the project as well.
Documentation should be a little more rigorous than it needs to be for a private project, mainly to help onboard new members to the project or alert contributors/users of new changes to the project. Some of the recommended parts to add to the project are the following:
- Readme: A brief summary of the project and its purpose. Include any special requirements for installing or operating the project. Additionally, add any major changes since the previous version.
examples.py: A Python script file that gives simple examples of how to use the projects.- How to Contribute: This should include how new contributors to the project can start contributing.
Public and Open Source Projects
Public and Open Source projects are projects that are intended to be shared with a large group of users and can involve large development teams. These projects should place as high of a priority on project documentation as the actual development of the project itself. Some of the recommended parts to add to the project are the following:
Readme: A brief summary of the project and its purpose. Include any special requirements for installing or operating the projects. Additionally, add any major changes since the previous version. Finally, add links to further documentation, bug reporting, and any other important information for the project. Dan Bader has put together a great tutorial on what all should be included in your readme.
How to Contribute: This should include how new contributors to the project can help. This includes developing new features, fixing known issues, adding documentation, adding new tests, or reporting issues.
Code of Conduct: Defines how other contributors should treat each other when developing or using your software. This also states what will happen if this code is broken. If you’re using Github, a Code of Conduct template can be generated with recommended wording. For Open Source projects especially, consider adding this.
License: A plaintext file that describes the license your project is using. For Open Source projects especially, consider adding this.
docs: A folder that contains further documentation. The next section describes more fully what should be included and how to organize the contents of this folder.
The Four Main Sections of the docs Folder
Daniele Procida gave a wonderful PyCon 2017 talk and subsequent blog post about documenting Python projects. He mentions that all projects should have the following four major sections to help you focus your work:
- Tutorials: Lessons that take the reader by the hand through a series of steps to complete a projects (or meaningful exercise). Geared towards the users learning.
- How-To Guides: Guides that take the reader through the steps required to solve a common problem (problem-oriented recipes).
- References: Explanations that clarify and illuminate a particular topic. Geared towards understanding.
- Explanations: Technical descriptions of the machinery and how to operate it (key classes, functions, APIs, and so forth). Think Encyclopedia article.
The following table shows how all of these sections relates to each other as well as their overall purpose:
| Most Useful When We’re Studying | Most Useful When We’re Coding | |
|---|---|---|
| Practical Step | Tutorials | How-To Guides |
| Theoretical Knowledge | Explanation | Reference |
In the end, you want to make sure that your users have access to the answers to any questions they may have. By organizing your project in this manner, you’ll be able to answer those questions easily and in a format they’ll be able to navigate quickly.
Documentation Tools and Resources
Documenting your code, especially large projects, can be daunting. Thankfully there are some tools out and references to get you started:
| Tool | Description |
|---|---|
| Sphinx | A collection of tools to auto-generate documentation in multiple formats |
| Epydoc | A tool for generating API documentation for Python modules based on their docstrings |
| Read The Docs | Automatic building, versioning, and hosting of your docs for you |
| Doxygen | A tool for generating documentation that supports Python as well as multiple other languages |
| MkDocs | A static site generator to help build project documentation using the Markdown language |
| pycco | A “quick and dirty” documentation generator that displays code and documentation side by side. Check out our tutorial on how to use it for more info. |
Along with these tools, there are some additional tutorials, videos, and articles that can be useful when you are documenting your project:
- Carol Willing - Practical Sphinx - PyCon 2018
- Daniele Procida - Documentation-driven development - Lessons from the Django Project - PyCon 2016
- Eric Holscher - Documenting your project with Sphinx & Read the Docs - PyCon 2016
- Titus Brown, Luiz Irber - Creating, building, testing, and documenting a Python project: a hands-on HOWTO - PyCon 2016
- Restructured Text Official Documentation
- Sphinx’s reStructured Text Primer
Sometimes, the best way to learn is to mimic others. Here are some great examples of projects that use documentation well:
Where Do I Start?
The documentation of projects have a simple progression:
- No Documentation
- Some Documentation
- Complete Documentation
- Good Documentation
- Great Documentation
If you’re at a loss about where to go next with your documentation, look at where your project is now in relation to the progression above. Do you have any documentation? If not, then start there. If you have some documentation but are missing some of the key project files, get started by adding those.
In the end, don’t get discouraged or overwhelmed by the amount of work required for documenting code. Once you get started documenting your code, it becomes easier to keep going. Feel free to comment if you have questions or reach out to the Real Python Team on social media, and we’ll help.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
↧
NumFOCUS: Two Sigma Renews Corporate Sponsorship of NumFOCUS
The post Two Sigma Renews Corporate Sponsorship of NumFOCUS appeared first on NumFOCUS.
↧
↧
PyCharm: PyCharm 2018.2 Out Now
PyCharm 2018.2 is now available: Pipenv environments, pytest support improvements, new and improved quick documentation, and much more
New in PyCharm
- PyCharm now fully supports pipenv: easily create projects with pipenv, create a pipfile, and have PyCharm update it for you when you install packages. If you’re checking out a project from GitHub with a pipfile, a pipenv will be created automatically, and you can install all dependencies with one click.
- Support for pytest has been improved in PyCharm 2018.2: code completion and inspections are now support for pytest fixtures. If you’d like to use BDD, pytest-bdd is now supported as well. Please note that BDD support is available only in PyCharm Professional Edition.
- Quick documentation has been redesigned to be easier to use and also just to look better. Don’t have docs yet? The reStructuredText editor now comes with a preview window, making editing rst files a lot easier.
Further code insight, version control, and other improvements have been made, read the What’s New page to learn more. Already convinced? Then download PyCharm now
Do you have questions, complaints, or suggestions? Please reach out to us! Ask questions to our support team, report bugs and suggestions on our issue tracker, or just connect with us on Twitter.
↧
Mike Driscoll: Jupyter Notebook 101 Preview Chapters
I am currently working on a new book called Jupyter Notebook 101 that I am planning to release in November 2018. I have put together a PDF that shows a rough draft of the first couple of chapters of the book along with an appendix. You can check out the PDF here:
If you would like to pre-order the book or just learn more about it, you can do so on Kickstarter.

↧
Python Software Foundation: The PSF Jobs Volunteer Team: Community Service Award Q1 2018 Recipient
The popularity of the Python language has increased exponentially in recent years. Notably, Stack Overflow highlighted Python as the fastest growing major programming language. As Pythonistas, we know why: Python is easy to learn, solves real world problems in a variety of fields, and has an amazingly friendly community.
With its success, companies around the world are using Python to build and improve their products, creating a growing need for people that know – or are willing to learn – the language. Today you can see Python’s popularity reflected in the growing supply of Python-related jobs with a quick internet search. Or you can head over to the the Python official site and look at the Python Jobs board! Created in 2010 as a way to connect developers and companies, the Python Jobs board was relaunched in early 2015 and has since been run by an awesome team of volunteers.
It’s with great pride that the Python Software Foundation has awarded Jon Clements, Melanie Jutras, Rhys Yorke, Martijn Pieters, and Marc-Andre Lemburg with the Q1 2018 Community Service Award:
As a job poster, all you need to do is register on the Python website and create a job posting filling out the required information. Then, the Jobs Volunteer Team will review them one by one against a list of criteria – such as text format, the job description and how it is related to Python. The entry can be automatically published or sent back to its author with a review note. The process may seem simple, but imagine doing that for hundreds of jobs each year - that's a lot of responsibility!
The PSF Jobs Volunteer team has five members, including members Marc Andre and Rhys York.
Marc-Andre is the CEO and founder of eGenix.com, a Python-focused project and consulting company based in Germany. He has a degree in mathematics from the University of Düsseldorf.
His work with Python started in 1994.
As a Python Core Developer, Marc-Andre designed and implemented the Unicode support in Python 2.0, and authored the mx Extensions. He is also the EuroPython Society (EPS) Chair, a Python Software Foundation (PSF) founding Fellow and co-founded a local Python meeting in Düsseldorf (PyDDF). He served on the board of the PSF and EPS for many terms and loves to contribute to the growth of Python wherever he can.
Rhys grew up in a small town in Ontario, Canada where he developed a passion for drawing, writing and technology.
He began working in 1999 on Marvel Comics' Deadpool, and since that time has had the opportunity to work on ThunderCats, G.I. Joe, Battle of the Planets, and a number of exciting properties. He works in the film, television and video game industries - notably on Funcom’s "The Secret World", Drinkbox’s "Tales from Space: About a Blob" and Ubisoft's "FarCry 5".
Rhys recently wrapped on the third season of the science-fiction television series "The Expanse" as well as on the film "Polar". Rhys is also currently working as Art Director at Brown Bags Films on an undisclosed animation project. As if that wasn’t enough, Rhys teaches Python to children and adults as well. Rhys is very passionate about promoting programming literacy.
Explaining his involvement with the PSF Jobs Volunteer Team, Marc-Andre says,
The Jobs Team faced several challenges during the platform redesign, such as managing the project, rethinking the review process, and finding people to help and. Following the relaunch the team faced additional challenges in keeping up with processing all the job posts that were remaining in the backlog.
As for the future of the Team, Rhys wants to continue providing a service to the Python community and Marc-Andre has worked with the PSF to turn the group into a PSF Working Group as of July 24, 2018. This change will enable to group to get more recognition from the PSF and the Python community at large.
If you want contribute and be a part of the Team, Marc-Andre says:
Today, the job reviews are pretty easy to manage. We have laid out a set of rules which work well and reviews don't take long to do anymore. The process is documented here.
There are still a few rough edges in the system, so if there are Django programmers willing to help, please get in contact with Berker Peksağ and submit Pull Requests for the open issues we have on the tracker.
Rhys adds, “Do it. Even if you have little time, giving back to the community is a rewarding experience.”
![]()
![]()
![]()
![]()
![]()
With its success, companies around the world are using Python to build and improve their products, creating a growing need for people that know – or are willing to learn – the language. Today you can see Python’s popularity reflected in the growing supply of Python-related jobs with a quick internet search. Or you can head over to the the Python official site and look at the Python Jobs board! Created in 2010 as a way to connect developers and companies, the Python Jobs board was relaunched in early 2015 and has since been run by an awesome team of volunteers.
It’s with great pride that the Python Software Foundation has awarded Jon Clements, Melanie Jutras, Rhys Yorke, Martijn Pieters, and Marc-Andre Lemburg with the Q1 2018 Community Service Award:
RESOLVED, that the Python Software Foundation award the Q1 2018 Community Service Award to the following members of the PSF Jobs Volunteer Team for the many hours they have contributed to reviewing and managing the hundreds of job postings submitted on an annual basis: Jon Clements, Melanie Jutras, Rhys Yorke, Martijn Pieters, and Marc-Andre Lemburg.
PSF Jobs Volunteer Team: A Team of Dedicated Volunteers
The PSF Jobs Volunteer team has five members, including members Marc Andre and Rhys York.
Marc-Andre is the CEO and founder of eGenix.com, a Python-focused project and consulting company based in Germany. He has a degree in mathematics from the University of Düsseldorf.
His work with Python started in 1994.
As a Python Core Developer, Marc-Andre designed and implemented the Unicode support in Python 2.0, and authored the mx Extensions. He is also the EuroPython Society (EPS) Chair, a Python Software Foundation (PSF) founding Fellow and co-founded a local Python meeting in Düsseldorf (PyDDF). He served on the board of the PSF and EPS for many terms and loves to contribute to the growth of Python wherever he can.
Rhys grew up in a small town in Ontario, Canada where he developed a passion for drawing, writing and technology.
He began working in 1999 on Marvel Comics' Deadpool, and since that time has had the opportunity to work on ThunderCats, G.I. Joe, Battle of the Planets, and a number of exciting properties. He works in the film, television and video game industries - notably on Funcom’s "The Secret World", Drinkbox’s "Tales from Space: About a Blob" and Ubisoft's "FarCry 5".
Rhys recently wrapped on the third season of the science-fiction television series "The Expanse" as well as on the film "Polar". Rhys is also currently working as Art Director at Brown Bags Films on an undisclosed animation project. As if that wasn’t enough, Rhys teaches Python to children and adults as well. Rhys is very passionate about promoting programming literacy.
Engagement, Challenges and the Future of the Python Job Board
“I took over the Job Boards project after the previous maintainer, Chris Wither, left the project in 2013. I kickstarted the relaunch project in February 2014 to migrate the old job board to the new platform.
The project was on hold for several months between August 2014 and January 2015, but then picked up speed again and we were able to relaunch the Job Board on March 19th 2015.
Since then a team of reviewers has been working hard to keep up with the many job postings we get each day.”
The Jobs Team faced several challenges during the platform redesign, such as managing the project, rethinking the review process, and finding people to help and. Following the relaunch the team faced additional challenges in keeping up with processing all the job posts that were remaining in the backlog.
As for the future of the Team, Rhys wants to continue providing a service to the Python community and Marc-Andre has worked with the PSF to turn the group into a PSF Working Group as of July 24, 2018. This change will enable to group to get more recognition from the PSF and the Python community at large.
How you can get involved
Today, the job reviews are pretty easy to manage. We have laid out a set of rules which work well and reviews don't take long to do anymore. The process is documented here.
There are still a few rough edges in the system, so if there are Django programmers willing to help, please get in contact with Berker Peksağ and submit Pull Requests for the open issues we have on the tracker.
Rhys adds, “Do it. Even if you have little time, giving back to the community is a rewarding experience.”
 |
| Marc-Andre, member of The PSF Jobs Volunteer Team |
↧
pythonwise: Specifying test cases for pytest using TOML
Say you have a function that converts text and you'd like to test it. You can write a directory with input and output and use pytest.parameterize to iterate over the cases. The problem is that the input and the output are in different files and it's not obvious to see them next to each other.
If the text for testing is not that long, you can place all the cases in a configuration file. In this example I'll be using TOML format to hold the cases and each case will be in a table in array of tables. You can probably do the same with multi document YAML.
Here's the are the test cases
And here's the testing code (mask removes passwords from the text)
When running pytest, you'll see the following:
$ python -m pytest -v
========================================= test session starts =========================================
platform linux -- Python 3.7.0, pytest-3.6.3, py-1.5.4, pluggy-0.6.0 -- /home/miki/.local/share/virtualenvs/pytest-cmp-F3l45TQF/bin/python
cachedir: .pytest_cache
rootdir: /home/miki/Projects/pythonwise/pytest-cmp, inifile:
collected 3 items
test_mask.py::test_mask[passwd] PASSED [ 33%]
test_mask.py::test_mask[password] PASSED [ 66%]
test_mask.py::test_mask[no change] PASSED [100%]
====================================== 3 passed in 0.01 seconds =======================================
If the text for testing is not that long, you can place all the cases in a configuration file. In this example I'll be using TOML format to hold the cases and each case will be in a table in array of tables. You can probably do the same with multi document YAML.
Here's the are the test cases
And here's the testing code (mask removes passwords from the text)
When running pytest, you'll see the following:
$ python -m pytest -v
========================================= test session starts =========================================
platform linux -- Python 3.7.0, pytest-3.6.3, py-1.5.4, pluggy-0.6.0 -- /home/miki/.local/share/virtualenvs/pytest-cmp-F3l45TQF/bin/python
cachedir: .pytest_cache
rootdir: /home/miki/Projects/pythonwise/pytest-cmp, inifile:
collected 3 items
test_mask.py::test_mask[passwd] PASSED [ 33%]
test_mask.py::test_mask[password] PASSED [ 66%]
test_mask.py::test_mask[no change] PASSED [100%]
====================================== 3 passed in 0.01 seconds =======================================
↧
↧
Bhishan Bhandari: MongoDB and Python
Python is used in many applications, mainly due to its flexibility and availability of various libraries. It works for just about any types of scenarios. This also suggests, it is often coupled with database systems. MongoDB, a NoSql. The intentions of this blog is to show through examples how python can be used to interact […]
The post MongoDB and Python appeared first on The Tara Nights.
↧
Kay Hayen: Nuitka this week #1
Contents
New Series Rationale
I think I tend to prefer coding over communication too much. I think I need to make more transparent what I am doing. Also things, will be getting exciting continuously for a while now.
I used to report posts, many years ago, every 3 months or so, and that was nice for me also to get an idea of what changed, but I stopped. What did not happen, was to successfully engage other people to contribute.
This time I am getting more intense. I will aim to do roughly weekly or bi-weekly reports, where I highlight things that are going on, newly found issues, hotfixes, all the things Nuitka.
Planned Mode
I will do it this fashion. I will write a post to the mailing list, right about wednesday every week or so. I need to pick a day. I am working from home that day, saving me commute time. I will invest that time into this.
The writing will not be too high quality at times. Bare with me there. Then I will check feedback from the list, if any. Hope is for it to point out the things where I am not correct, missing, or even engage right away.
Topics are going to be random, albeit repeating. I will try and make links to previous issues where applicable. Therefore also the TOC, which makes for link targets in the pages.
Locals Dict
When I am speaking of locals dict, I am talking of class scopes (and functions with exec statements). These started to use actual dictionary a while ago, which was a severe setback to optimization.
Right now, so for this week, after a first prototype was making the replacement of local dict assignment and references for Python2, and kind of worked through my buildbots, flawlessly, I immediately noticed that it would require some refactoring to not depend on the locals scopes to be only in one of the trace collections. Thinking of future inlining, maybe part of a locals scope was going to be in multiple functions, that ought to not be affected.
Therefore I made a global registry of locals scopes, and working on those, I checked its variables, if they can be forward propagated, and do this not per module, but after all the modules have been done. This is kind of a setback for the idea of module specific optimization (cachable later on) vs. program optimization, but since that is not yet a thing, it can remain this way for now.
Once I did that, I was interested to see the effect, but to my horror, I noticed, that memory was not released for the locals dict nodes. It was way too involved with cyclic dependencies, which are bad. So that was problematic of course. Compilation to keep nodes in memory for both tracing the usage as a locals dict and temporary variables, wasn't going to help scaling at all.
Solution is finalization
Nodes need Finalization
So replaced nodes reference a parent, and then the locals scope references variables, and trace collections referencing variables, which reference locals scopes, and accesses referencing traces, and so on. The garbage collector can handle some of this, but seems I was getting past that.
For a solution, I started to add a finalize method, which released the links for locals scopes, when they are fully propagated, on the next run.
Adding a finalize to all nodes, ought to make sure, memory is released soon, and might even find bugs, as nodes become unusable after they are supposedly unused. Obviously, there will currently be cases, where nodes becomes unused, but they are not finalized yet. Also, often this is more manual, because part of the node is to be released, but one child is re-used. That is messy.
Impact on Memory Usage
The result was a bit disappointing. Yes, memory usage of mercurial compilation went back again, but mostly to what it had been. Some classes are now having their locals dict forward propagated, but the effect is not always a single dictionary making yet. Right now, function definitions, are not forward at all propagated. This is a task I want to take on before next release though, but maybe not, there is other things too. But I am assuming that will make most class dictionaries created without using any variables at all anymore, which should make it really lean.
Type Hints Question
Then, asking about type hints, I got the usual question about Nuitka going to use it. And my stance is unchanged. They are just hints, not reliable. Need to behave the same if users do it wrong. Suggested to create decorated which make type hints enforced. But I expect nobody takes this on though. I need to make it a Github issue of Nuitka, although technically it is pure CPython work and ought to be done independently. Right now Nuitka is not yet there anyway yet, to take full advantage.
Python 3.7
Then, for Python 3.7, I have long gotten the 3.6 test suite to pass. I raised 2 bugs with CPython, one of which lead to update of a failing test. Nuitka had with large delay, caught of with what del __annotations__ was doing in a class. Only with the recent work for proper locals dict code generation, we could enforce a name to be local, and have proper code generation, that allows for it to be unset.
This was of course a bit of work. But the optimization behind was always kind of necessary to get right. But now, that I got this, think of my amazement when for 3.7 they reverted to the old behavior, where annotiatons then corrupt the module annotations
The other bug is a reference counting bug, where Nuitka tests were failing with CPython 3.7, and turns out, there is a bug in the dictionary implementation of 3.7, but it only corrupts counts reported, not actual objects, so it's harmless, but means for 3.7.0 the reference count tests are disabled.
Working through the 3.7 suite, I am cherry picking commits, that e.g. allow the repr of compiled functions to contain <compiled_function ...> and the like. Nothing huge yet. There is now a subscript of type, and foremost the async syntax became way more liberal, so it is more complex for Nuitka to make out if it is a coroutine due to something happening inside a generator declared inside of it. Also cr_origin was added to coroutines, but that is mostly it.
Coroutine Compatibility
A bigger thing was that I debugged coroutines and their interaction with uncompiled and compiled coroutines awaiting one another, and turns out, there was a lot to improve.
The next release will be much better compatible with asyncio module and its futures, esp with exceptions to cancel tasks passed along. That required to clone a lot of CPython generator code, due to how ugly they mess with bytecode instruction pointers in yield from on an uncompiled coroutine, as they don't work with send method unlike everything else has to.
PyLint Troubles
For PyLint, the 2.0.0 release found new things, but unfortunately for 2.0.1 there is a lot of regressions that I had to report. I fixed the versions of first PyLint, and now also Astroid, so Travis cannot suddenly start to fail due to a PyLint release finding new warnings.
Currently, if you make a PR on Github, a PyLint update will break it. And also the cron job on Travis that checks master.
As somebody pointed out, I am now using requires.io to check for Nuitka dependencies. But since 1.9.2 is still needed for Python2, that kind of is bound to give alarms for now.
TODO solving
I have a habit of doing off tasks, when I am with my notebook in some place, and don't know what to work on. So I have some 2 hours recently like this, and used it to look at TODO and resolve them.
I did a bunch of cleanups for static code helpers. There was one in my mind about calling a function with a single argument. That fast call required a local array with one element to put the arg into. That makes using code ugly.
Issues Encountered
So the enum module of Python3 hates compiled classes and their staticmethod around __new__. Since it manually unwraps __new__ and then calls it itself, it then finds that a staticmethod object cannot be called. It's purpose is to sit in the class dictionary to give a descriptor that removes the self arg from the call.
I am contemplating submitting an upstream patch for CPython here. The hard coded check for PyFunction on the __new__ value is hard to emulate.
So I am putting the staticmethod into the dictionary passed already. But the undecorated function should be there for full compatibility.
If I were to make compiled function type that is both a staticmethod alike and a function, maybe I can work around it. But it's ugly and a burden. But it would need no change. And maybe there is more core wanting to call __new__ manually
Plans
I intend to make a release, probably this weekend. It might not contain full 3.7 compatibility yet, although I am aiming at that.
Then I want to turn to "goto generators", a scalability improvement of generators and coroutines that I will talk about next week then.
Until next week.
↧
Curtis Miller: High Dimensional Data, MSRI, and San Francisco in 2018; Reflections
Last fall my adviser alerted me to the [MSRI workshop on high-dimensional data](http://www.msri.org/summer_schools/827) and suggested I may be interested. I applied and was accepted to participate. Thus, from July 9th to July 20th I stayed in San Francisco (for the first time in my life), living in the dorms of UC Berkeley and attending the workshop. I got to experience San Francisco's legendary weather (escaping Salt Lake City's triple-digit heat) while learning mathematics. I enjoyed the experience and wanted to share it.
↧
Ian Ozsvald: Keynote at EuroPython 2018 on “Citizen Science”
I’ve just had the privilege of giving my first keynote at EuroPython (and my second keynote this year), I’ve just spoken on “Citizen Science”. I gave a talk aimed at engineers showing examples of projects around healthcare and humanitarian topics using Python that make the world a better place. The main point was “gather your data, draw graphs, start to ask questions”– this is something that anyone can do:
 EuroPython crowd for my keynote
EuroPython crowd for my keynote
NOTE that this write-up will evolve over a few days, I have to add the source code and other links later.
In the talk I covered 4 short stories and then gave a live demo of a Jupyter Lab to graph some audience-collected data:
- Gorjan’s talk on Macedonian awful-air-quality from PyDataAmsterdam 2018
- My talks on solving Sneeze Diagnosis given at PyDataLondon 2017, ODSC 2017 and elsewhere
- Anna’s talk on improving baby-delivery healthcare from PyDataWarsaw 2017
- Dirk’s talk on saving Orangutangs with Drones from PyDataAmsterdam 2017
- Jupyter Lab demo on “guessing my dog’s weight” to crowd-source guesses which we investigate using a Lab
The goal of the live demo was to a) collect data (before and after showing photos of my dog) and b) show some interesting results that come out of graphing the results using histograms so that c) everyone realises that drawing graphs of their own data is possible and perhaps is something they too can try.
The slides are here.
Here’s some output. Approximately 440 people participated in the two single-answer surveys. The first (poor-information estimate) is “What’s the weight of my dog in kg when you know nothing about the dog?” and the second (good-information estimate) is “The same, but now you’ve seen 8+ pictures of my dog”.
With poor information folk tended to go for the round numbers (see the spikes at 15, 20, 30, 35, 40). After the photos the variance reduced (the talk used more graphs to show this), which is what I wanted to see. Ada’s actual weight is 17kg so the “wisdom of the crowds” estimate was off, but not terribly so and since this wasn’t a dog-fanciers crowd, that’s hardly surprising!
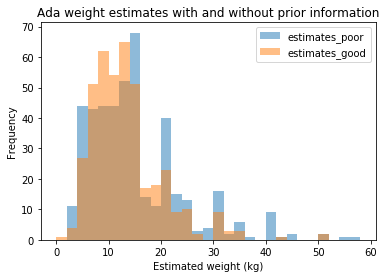 The slides conclude with two sets of links, one of which points the reader at open data sources which could be used in your own explorations.
The slides conclude with two sets of links, one of which points the reader at open data sources which could be used in your own explorations.
Ian applies Data Science as an AI/Data Scientist for companies in ModelInsight and in his Mor Consulting, sign-up for Data Science tutorials in London. He also founded the image and text annotation API Annotate.io, lives in London and is a consumer of fine coffees.
The post Keynote at EuroPython 2018 on “Citizen Science” appeared first on Entrepreneurial Geekiness.
↧
↧
Continuum Analytics Blog: Faster Machine Learning – Deep Learning with GPUs
The Big Deal With GPUsIf you’ve been following data science and machine learning, you’ve probably heard the term GPU. But what exactly is a GPU? And why are they so popular all of a sudden? What A GPU IsA Graphics Processing Unit (GPU) is a computer chip that can perform massively parallel computations exceedingly fast. …
Read more →
The post Faster Machine Learning – Deep Learning with GPUs appeared first on Anaconda.
↧
Python Bytes: #88 Python has brought computer programming to a vast new audience
↧
PyCharm: PyCharm 2018.2.1 RC Out Now
PyCharm 2018.2.1 Release Candidate is now available, with various bug fixes. Get it now from our Confluence page
Improved in This Version
- A rendering issue (IDEA-195614) that affected Linux users of any IntelliJ-based IDE was resolved
- Many JavaScript editing issues were resolved, see the release notes for details
Interested?
Download the RC from our confluence page
If you’re on Ubuntu 16.04 or later, you can use snap to get PyCharm RC versions, and stay up to date. You can find the installation instructions on our website.
The release candidate (RC) is not an early access program (EAP) build, and does not bundle an EAP license. If you get PyCharm Professional Edition RC, you will either need a currently active PyCharm subscription, or you will receive a 30-day free trial.
↧
Davy Wybiral: Hacked by a USB Device?!
I made a USB device that forces Windows machines to subscribe to my channel when someone plugs it in. 😃
↧
↧
Bhishan Bhandari: Python Subprocess
Through this post, we will discuss and see via examples the purpose of subprocess, how to spawn processes, how to connect to their input/output and error pipes, etc. subprocess As the name suggests, subprocess is used to spawn sub-processes. It also allows for us to get the output from the process, error if any as […]
The post Python Subprocess appeared first on The Tara Nights.
↧
Semaphore Community: Building and Testing an API Wrapper in Python
This article is brought with ❤ to you by Semaphore.
Introduction
Most websites we use provide an HTTP API to enable developers to access their data from their own applications. For developers utilizing the API, this usually involves making some HTTP requests to the service, and using the responses in their applications. However, this may get tedious since you have to write HTTP requests for each API endpoint you intend to use. Furthermore, when a part of the API changes, you have to edit all the individual requests you have written.
A better approach would be to use a library in your language of choice that helps you abstract away the API's implementation details. You would access the API through calling regular methods provided by the library, rather than constructing HTTP requests from scratch. These libraries also have the advantage of returning data as familiar data structures provided by the language, hence enabling idiomatic ways to access and manipulate this data.
In this tutorial, we are going to write a Python library to help us communicate with The Movie Database's API from Python code.
By the end of this tutorial, you will learn:
- How to create and test a custom library which communicates with a third-party API and
- How to use the custom library in a Python script.
Prerequisites
Before we get started, ensure you have one of the following Python versions installed:
- Python 2.7, 3.3, 3.4, or 3.5
We will also make use of the Python packages listed below:
requests- We will use this to make HTTP requests,vcrpy- This will help us record HTTP responses during tests and test those responses, andpytest- We will use this as our testing framework.
Project Setup
We will organize our project as follows:
.
├── requirements.txt
├── tests
│ ├── __init__.py
│ ├── test_tmdbwrapper.py
│ └── vcr_cassettes
└── tmdbwrapper
└── __init__.py
└── tv.py
This sets up a folder for our wrapper and one for holding the tests. The
vcr_cassettes subdirectory inside tests will store our recorded HTTP
interactions with The Movie Database's API.
Our project will be organized around the functionality we expect to provide in
our wrapper. For example, methods related to TV functionality will be in the
tv.py file under the tmdbwrapper directory.
We need to list our dependencies in the requirements.txt file as follows.
At the time of writing, these are the latest versions. Update the version numbers
if later versions have been published by the time you are reading this.
requests==2.11.1
vcrpy==1.10.3
pytest==3.0.3
Finally, let's install the requirements and get started:
pip install -r requirements.txt
Test-driven Development
Following the test-driven development practice, we will write the tests for our application first, then implement the functionality to make the tests pass.
For our first test, let's test that our module will be able to fetch a TV show's info from TMDb successfully.
# tests/test_tmdbwrapper.pyfromtmdbwrapperimportTVdeftest_tv_info():"""Tests an API call to get a TV show's info"""tv_instance=TV(1396)response=tv_instance.info()assertisinstance(response,dict)assertresponse['id']==1396,"The ID should be in the response"In this initial test, we are demonstrating the behavior we expect our complete
module to exhibit. We expect that our tmdbwrapper package will contain a TV
class, which we can then instantiate with a TMDb TV ID.
Once we have an instance of the class, when we call the info method, it should
return a dictionary containing the TMDb TV ID we provided under the 'id' key.
To run the test, execute the py.test command from the root directory.
As expected, the test will fail with an error message that should contain
something similar to the following snippet:
ImportError while importing test module '/Users/kevin/code/python/tmdbwrapper/tests/test_tmdbwrapper.py'.
'cannot import name TV'
Make sure your test modules/packages have valid Python names.
This is because the tmdbwrapper package is empty right now. From now on, we will
write the package as we go, adding new code to fix the failing tests, adding
more tests and repeating the process until we have all the functionality we need.
Implementing Functionality in Our API Wrapper
To start with, the minimal functionality we can add at this stage is creating the TV class inside our package.
Let's go ahead and create the class in the tmdbwrapper/tv.py file:
# tmdbwrapper/tv.pyclassTV(object):passAdditionally, we need to import the TV class in the tmdbwrapper/__init__.py file,
which will enable us to import it directly from the package.
# tmdbwrapper/__init__.pyfrom.tvimportTVAt this point, we should re-run the tests to see if they pass. You should now see the following error message:
> tv_instance = TV(1396)
E TypeError: object() takes no parameters
We get a TypeError. This is good. We seem to be making some progress.
Reading through the error, we can see that it occurs when we try to instantiate
the TV class with a number.
Therefore, what we need to do next is implement a constructor for the TV class
that takes a number. Let's add it as follows:
# tmdbwrapper/tv.pyclassTV(object):def__init__(self,id):passAs we just need the minimal viable functionality right now, we will leave the
constructor empty, but ensure that it receives self and id as parameters.
This id parameter will be the TMDb TV ID that will be passed in.
Now, let's re-run the tests and see if we made any progress. We should see the following error message now:
> response = tv_instance.info()
E AttributeError: 'TV' object has no attribute 'info'
This time around, the problem is that we are using the info method from the tv_instance,
and this method does not exist. Let's add it.
# tmdbwrapper/tv.pyclassTV(object):def__init__(self,id):passdefinfo(self):passAfter running the tests again, you should see the following failure:
> assert isinstance(response, dict)
E assert False
E + where False = isinstance(None, dict)
For the first time, it's the actual test failing, and not an error in our code.
To make this pass, we need to make the info method return a dictionary. Let's
also pre-empt the next failure we expect. Since we know that the returned
dictionary should have an id key, we can return a dictionary with an
'id' key whose value will be the TMDb TV ID provided when the class is initialized.
To do this, we have to store the ID as an instance variable, in order to access
it from the info function.
# tmdbwrapper/tv.pyclassTV(object):def__init__(self,id):self.id=iddefinfo(self):return{'id':self.id}If we run the tests again, we will see that they pass.
Writing Foolproof Tests
You may be asking yourself why the tests are passing, since we clearly have not fetched any info from the API. Our tests were not exhaustive enough. We need to actually ensure that the correct info that has been fetched from the API is returned.
If we take a look at the TMDb documentation
for the TV info method, we can see that there are many additional fields
returned from the TV info response, such as poster_path, popularity, name,
overview, and so on.
We can add a test to check that the correct fields are returned in the response,
and this would in turn help us ensure that our tests are indeed checking for a correct
response object back from the info method.
For this case, we will select a handful of these properties and ensure that they are in the response. We will use pytest fixtures for setting up the list of keys we expect to be included in the response.
Our test will now look as follows:
# tests/test_tmdbwrapper.pyfrompytestimportfixturefromtmdbwrapperimportTV@fixturedeftv_keys():# Responsible only for returning the test datareturn['id','origin_country','poster_path','name','overview','popularity','backdrop_path','first_air_date','vote_count','vote_average']deftest_tv_info(tv_keys):"""Tests an API call to get a TV show's info"""tv_instance=TV(1396)response=tv_instance.info()assertisinstance(response,dict)assertresponse['id']==1396,"The ID should be in the response"assertset(tv_keys).issubset(response.keys()),"All keys should be in the response"Pytest fixtures help us create test data that we can then use in other tests.
In this case, we create the tv_keys fixture which returns a list of some of the
properties we expect to see in the TV response.
The fixture helps us keep our code clean, and explicitly separate the scope of the two
functions.
You will notice that the test_tv_info method now takes tv_keys as a parameter.
In order to use a fixture in a test, the test has to receive the fixture name as
an argument. Therefore, we can make assertions using the test data.
The tests now help us ensure that the keys from our fixtures are a subset of the
list of keys we expect from the response.
This makes it a lot harder for us to cheat in our tests in future, as we did before.
Running our tests again should give us a constructive error message which fails because our response does not contain all the expected keys.
Fetching Data from TMDb
To make our tests pass, we will have to construct a dictionary object
from the TMDb API response and return that in the info method.
Before we proceed, please ensure you have obtained an API key from TMDb by registering. All the available info provided by the API can be viewed in the API Overview page and all methods need an API key. You can request one after registering your account on TMDb.
First, we need a requests session
that we will use for all HTTP interactions.
Since the api_key parameter is required for all requests, we will attach it to
this session object so that we don't have to specify it every time we need to make an
API call. For simplicity, we will write this in the package's __init__.py
file.
# tmdbwrapper/__init__.pyimportosimportrequestsTMDB_API_KEY=os.environ.get('TMDB_API_KEY',None)classAPIKeyMissingError(Exception):passifTMDB_API_KEYisNone:raiseAPIKeyMissingError("All methods require an API key. See ""https://developers.themoviedb.org/3/getting-started/introduction ""for how to retrieve an authentication token from ""The Movie Database")session=requests.Session()session.params={}session.params['api_key']=TMDB_API_KEYfrom.tvimportTVWe define a TMDB_API_KEY variable which gets the API key from the
TMDB_API_KEY environment variable. Then, we go ahead and initialize a requests
session and provide the API key in the params object. This means that it will
be appended as a parameter to each request we make with this session object.
If the API key is not provided, we will raise a custom APIKeyMissingError with
a helpful error message to the user.
Next, we need to make the actual API request in the info method as follows:
# tmdbwrapper/tv.pyfrom.importsessionclassTV(object):def__init__(self,id):self.id=iddefinfo(self):path='https://api.themoviedb.org/3/tv/{}'.format(self.id)response=session.get(path)returnresponse.json()First of all, we import the session object that we defined in the package root.
We then need to send a GET request to the TV info URL that returns details about a single TV show, given its ID.
The resulting response object is then returned as a dictionary by calling the
.json() method on it.
There's one more thing we need to do before wrapping this up. Since we are now making actual API calls, we need to take into account some API best practices. We don't want to make the API calls to the actual TMDb API every time we run our tests, since this can get you rate limited.
A better way would be to save the HTTP response the first time a request is made,
then reuse this saved response on subsequent test runs. This way, we minimize
the amount of requests we need to make on the API and ensure that our tests still
have access to the correct data. To accomplish this, we will use the vcr package:
# tests/test_tmdbwrapper.pyimportvcr@vcr.use_cassette('tests/vcr_cassettes/tv-info.yml')deftest_tv_info(tv_keys):"""Tests an API call to get a TV show's info"""tv_instance=TV(1396)response=tv_instance.info()assertisinstance(response,dict)assertresponse['id']==1396,"The ID should be in the response"assertset(tv_keys).issubset(response.keys()),"All keys should be in the response"We just need to instruct vcr where to store the HTTP response for the
request that will be made for any specific test. See vcr's docs on
detailed usage information.
At this point, running our tests requires that we have a TMDB_API_KEY environment
variable set, or else we'll get an APIKeyMissingError.
One way to do this is by setting it right before running the tests,
i.e. TMDB_API_KEY='your-tmdb-api-key' py.test.
Running the tests with a valid API key should have them passing.
Adding More Functions
Now that we have our tests passing, let's add some more functionality to our wrapper. Let's add the ability to return a list of the most popular TV shows on TMDb. We can add the following test:
# tests/test_tmdbwrapper.py@vcr.use_cassette('tests/vcr_cassettes/tv-popular.yml')deftest_tv_popular():"""Tests an API call to get a popular tv shows"""response=TV.popular()assertisinstance(response,dict)assertisinstance(response['results'],list)assertisinstance(response['results'][0],dict)assertset(tv_keys).issubset(response['results'][0].keys())Note that we are instructing vcr to save the API response in a different file.
Each API response needs its own file.
For the actual test, we need to check that the response is a dictionary
and contains a results key, which contains a list of TV show dictionary objects.
Then, we check the first item in the results list to ensure it is a
valid TV info object, with a test similar to the one we used for the info method.
To make the new tests pass, we need to add the popular method to the TV class.
It should make a request to the popular TV shows path, and then return
the response serialized as a dictionary.
Let's add the popular method to the TV class as follows:
# tmdbwrapper/tv.py@staticmethoddefpopular():path='https://api.themoviedb.org/3/tv/popular'response=session.get(path)returnresponse.json()Also, note that this is a staticmethod, which means it doesn't need the class
to be initialized for it to be used. This is because it doesn't use any instance
variables, and it's called directly from the class.
All our tests should now be passing.
Taking Our API Wrapper for a Spin
Now that we've implemented an API wrapper, let's check if
it works by using it in a script. To do this, we will write a program that
lists out all the popular TV shows on TMDb along with their popularity rankings.
Create a file in the root folder of our project. You can name the file anything you like — ours is called testrun.py.
# example.pyfrom__future__importprint_functionfromtmdbwrapperimportTVpopular=TV.popular()fornumber,showinenumerate(popular['results'],start=1):print("{num}. {name} - {pop}".format(num=number,name=show['name'],pop=show['popularity']))If everything is working correctly, you should see an ordered list of the current popular TV shows and their popularity rankings on The Movie Database.
Filtering Out the API Key
Since we are saving our HTTP responses to a file on a disk, there are chances
we might expose our API key to other people, which is a Very Bad Idea™,
since other people might use it for malicious purposes. To deal with this, we
need to filter out the API key from the saved responses.
To do this, we need to add a filter_query_parameters keyword argument to the
vcr decorator methods as follows:
@vcr.use_cassette('tests/vcr_cassettes/tv-popular.yml',filter_query_parameters=['api_key'])This will save the API responses, but it will leave out the API key.
Continuous Testing on Semaphore CI
Lastly, let's add continuous testing to our application using Semaphore CI.
We want to ensure that our package works on various platforms and that we don't accidentally break functionality in future versions. We do this through continuous automatic testing.
Ensure you've committed everything on Git, and push your repository to GitHub or Bitbucket, which will enable Semaphore to fetch your code. Next, sign up for a free Semaphore account, if don't have one already. Once you've confirmed your email, it's time to create a new project.
Follow these steps to add the project to Semaphore:
Once you're logged into Semaphore, navigate to your list of projects and click the "Add New Project" button:
![Add New Project Screen]()
Next, select the account where you wish to add the new project.
![Select Account Screen]()
Select the repository that holds the code you'd like to build:
![Select Repository Screen]()
Configure your project as shown below:
![Project Configuration Screen]()




Finally, wait for the first build to run.
It should fail, since as we recall, the TMDB_API_KEY environment key is required
for the tests to run.
Navigate to the Project Settings page of your application and add your API key
as an environment variable as shown below:

Make sure to check the Encrypt content checkbox when adding the key to ensure
the API key will not be publicly visible.
Once you've added that and re-run the build, your tests should be passing again.
Conclusion
We have learned how to write a Python wrapper for an HTTP API by writing one ourselves. We have also seen how to test such a library and what are some best practices around that, such as not exposing our API keys publicly when recording HTTP responses.
Adding more methods and functionality to our API wrapper should be straightforward, since we have set up methods that should guide us if we need to add more. We encourage you to check out the API and implement one or two extra methods to practice. This should be a good starting point for writing a Python wrapper for any API out there.
Please reach out with any questions or feedback that you may have in the comments section below. You can also check out the complete code and contribute on GitHub.
This article is brought with ❤ to you by Semaphore.
↧
Weekly Python StackOverflow Report: (cxxxvi) stackoverflow python report
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2018-07-29 06:14:37 GMT
Between brackets: [question score / answers count]
Build date: 2018-07-29 06:14:37 GMT
- In python, why does 0xbin() return False? - [140/4]
- Why do two identical lists have a different memory footprint? - [78/2]
- Why did pip upgrade from version 10 to version 18? - [39/1]
- How come I can add the boolean value False but not True in a set in Python? - [20/3]
- How to remove every occurrence of sub-list from list - [15/9]
- Python: round float values to interval limits / grid - [9/5]
- Transforming a dict to another structure in Python - [9/3]
- Checking that a pandas.Series.index contains a value - [8/2]
- Is there a difference between : "file.readlines()", "list(file)" and "file.read().splitlines(True)"? - [7/4]
- What is Numpy equivalence of dataframe.loc() in Pandas - [7/2]
↧