Which is the best server for hosting Django Apps, Best hosting provider for Django Apps, Cheapest Django Hosting, PythonAnyWhere Reviews, Django Hosting,
↧
Python Circle: How to upgrade to paid account on PythonAnyWhere
↧
Matt Layman: Fast Forms With UpdateView - Building SaaS #44
In this episode, we worked on an edit view. We used Django’s generic UpdateView to add the process and test drove the creation of the view to verify things every step of the way.
We worked on a view to make it possible to edit the CourseTask model that are the actions that a student must complete for a course.
To complete the form quickly, I took advantage of Django’s ModelForm views.
↧
↧
Codementor: Overload Functions in Python
Python natively does not support function overloading - having multiple functions with the same name. Today we see how we can implement and add this functionality to Python by using common language constructs like decorators and dictionaries.
↧
py.CheckIO: Maya Island
↧
Stack Abuse: Formatting Strings with the Python Template Class
Introduction
Python Templates are used to substitute data into strings. With Templates, we gain a heavily customizable interface for string substitution (or string interpolation).
Python already offers many ways to substitute strings, including the recently introduced f-Strings. While it is less common to substitute strings with Templates, its power lies in how we can customize our string formatting rules.
In this article, we'll format strings with Python's Template class. We'll then have a look at how we can change the way our Templates can substitute data into strings.
For a better understanding of these topics, you'll require some basic knowledge on how to work with classes and regular expressions.
Understanding the Python Template Class
The Python Template class was added to the string module since Python 2.4. This class is intended to be used as an alternative to the built-in substitution options (mainly to %) for creating complex string-based templates and for handling them in a user-friendly way.
The class's implementation uses regular expressions to match a general pattern of valid template strings. A valid template string, or placeholder, consists of two parts:
- The
$symbol - A valid Python identifier. An identifier is any sequence of upper and lower case letters A to Z, underscores (
_), and digits 0 to 9. An identifier cannot begin with digits nor can it be a Python keyword.
In a template string, $name and $age would be considered valid placeholders.
To use the Python Template class in our code, we need to:
- Import
Templatefrom thestringmodule - Create a valid template string
- Instantiate
Templateusing the template string as an argument - Perform the substitution using a substitution method
Here's a basic example of how we can use the Python Template class in our code:
>>> from string import Template
>>> temp_str = 'Hi $name, welcome to $site'
>>> temp_obj = Template(temp_str)
>>> temp_obj.substitute(name='John Doe', site='StackAbuse.com')
'Hi John Doe, welcome to StackAbuse.com'
We notice that when we build the template string temp_str, we use two placeholders: $name and $site. The $ sign performs the actual substitution and the identifiers (name and site) are used to map the placeholders to the concrete objects that we need to insert into the template string.
The magic is completed when we use the substitute() method to perform the substitution and build the desired string. Think of substitute() as if we were telling Python, go through this string and if you find $name, then replace it for John Doe. Continue searching through the string and, if you find the identifier $site, then turn it into StackAbuse.com.
The names of the arguments that we pass to .substitute() need to match with the identifiers that we used in the placeholders of our template string.
The most important difference between Template and the rest of the string substitution tools available in Python is that the type of the argument is not taken into account. We can pass in any type of object that can be converted into a valid Python string. The Template class will automatically convert these objects into strings and then insert them into the final string.
Now that we know the basics on how to use the Python Template class, let's dive into the details of its implementation to get a better understanding of how the class works internally. With this knowledge at hand, we'll be able to effectively use the class in our code.
The Template String
The template string is a regular Python string that includes special placeholders. As we've seen before, these placeholders are created using a $ sign, along with a valid Python identifier. Once we have a valid template string, the placeholders can be replaced by our own values to create a more elaborated string.
According to PEP 292 -- Simpler String Substitutions, the following rules apply for the use of the $ sign in placeholders:
$$is an escape; it is replaced with a single$$identifiernames a substitution placeholder matching a mapping key of "identifier". By default, "identifier" must spell a Python identifier as defined in http://docs.python.org/reference/lexical_analysis.html#identifiers-and-keywords. The first non-identifier character after the$character terminates this placeholder specification.${identifier}is equivalent to$identifier. It is required when valid identifier characters follow the placeholder but are not part of the placeholder, e.g."${noun}ification". (Source)
Let's code some examples to better understand how these rules work.
We'll start with an example of how we can escape the $ sign. Suppose we're dealing with currencies and we need to have the dollar sign in our resulting strings. We can double the $ sign to escape itself in the template string as follows:
>>> budget = Template('The $time budget for investment is $$$amount')
>>> budget.substitute(time='monthly', amount='1,000.00')
'The monthly budget for investment is $1,000.00'
Note that there is no need to add and extra space between the escaped sign and next placeholder like we did in $$$amount. Templates are smart enough to be able to escape the $ sign correctly.
The second rule states the basics for building a valid placeholder in our template strings. Every placeholder needs to be built using the $ character followed by a valid Python identifier. Take a look at the following example:
>>> template = Template('$what, $who!')
>>> template.substitute(what='Hello', who='World')
'Hello, World!'
Here, both placeholders are formed using valid Python identifiers (what and who). Also notice that, as stated in the second rule, the first non-identifier character terminates the placeholder as you can see in $who! where the character ! isn't part of the placeholder, but of the final string.
There could be situations where we need to partially substitute a word in a string. That's the reason we have a second option to build a placeholder. The third rule states that ${identifier} is equivalent to $identifier and should be used when valid identifier characters follow the placeholder but are not part of the placeholder itself.
Let's suppose that we need to automate the creation of files containing commercial information about our company's products. The files are named following a pattern that includes the product code, name, and production batch, all of them separated by an underscore (_) character. Consider the following example:
>>> filename_temp = Template('$code_$product_$batch.xlsx')
>>> filename_temp.substitute(code='001', product='Apple_Juice', batch='zx.001.2020')
Traceback (most recent call last):
...
KeyError: 'code_'
Since _ is a valid Python identifier character, our template string doesn't work as expected and Template raises a KeyError. To correct this problem, we can use the braced notation (${identifier}) and build our placeholders as follows:
>>> filename_temp = Template('${code}_${product}_$batch.xlsx')
>>> filename_temp.substitute(code='001', product='Apple_Juice', batch='zx.001.2020')
'001_Apple_Juice_zx.001.2020.xlsx'
Now the template works correctly! That's because the braces properly separate our identifiers from the _ character. It's worth noting that we only need to use the braced notation for code and product and not for batch because the . character that follows batch isn't a valid identifier character in Python.
Finally, the template string is stored in the template property of the instance. Let's revisit the Hello, World! example, but this time we're going to modify template a little bit:
>>> template = Template('$what, $who!') # Original template
>>> template.template = 'My $what, $who template' # Modified template
>>> template.template
'My $what, $who template'
>>> template.substitute(what='Hello', who='World')
'My Hello, World template'
Since Python doesn't restrict the access to instance attributes, we can modify our template string to meet our needs whenever we want. However, this is not a common practice when using the Python Template class.
It's best to create new instances of Template for every different template string we use in our code. This way, we'll avoid some subtle and hard-to-find bugs related to the use of uncertain template strings.
The substitute() Method
So far, we've been using the substitute() method on a Template instance to perform string substitution. This method replaces the placeholders in a template string using keyword arguments or using a mapping containing identifier-value pairs.
The keyword arguments or the identifiers in the mapping must agree with the identifiers used to define the placeholders in the template string. The values can be any Python type that successfully converts to a string.
Since we've covered the use of keyword arguments in previous examples, let's now concentrate on using dictionaries. Here's an example:
>>> template = Template('Hi $name, welcome to $site')
>>> mapping = {'name': 'John Doe', 'site': 'StackAbuse.com'}
>>> template.substitute(**mapping)
'Hi John Doe, welcome to StackAbuse.com'
When we use dictionaries as arguments with substitute(), we need to use the dictionary unpacking operator: **. This operator will unpack the key-value pairs into keyword arguments that will be used to substitute the matching placeholders in the template string.
Common Template Errors
There are some common errors that we can inadvertently introduce when using the Python Template class.
For example, a KeyError is raised whenever we supply an incomplete set of argument to substitute(). Consider the following code which uses an incomplete set of arguments:
>>> template = Template('Hi $name, welcome to $site')
>>> template.substitute(name='Jane Doe')
Traceback (most recent call last):
...
KeyError: 'site'
If we call substitute() with a set of arguments that doesn't match all the placeholders in our template string, then we'll get a KeyError.
If we use an invalid Python identifier in some of our placeholders, then we'll get a ValueError telling us that the placeholder is incorrect.
Take this example where we use an invalid identifier, $0name as a placeholder instead of $name.
>>> template = Template('Hi $0name, welcome to $site')
>>> template.substitute(name='Jane Doe', site='StackAbuse.com')
Traceback (most recent call last):
...
ValueError: Invalid placeholder in string: line 1, col 4
Only when the Template object reads the template string to perform the substitution that it discovers the invalid identifier. It immediately raises a ValueError. Note that 0name isn't a valid Python identifier or name because it starts with a digit.
The safe_substitute() Method
The Python Template class has a second method that we can use to perform string substitution. The method is called safe_substitute(). It works similarly to substitute() but when we use an incomplete or non-matching set of arguments the method doesn't rise a KeyError.
In this case, the missing or non-matching placeholder appears unchanged in the final string.
Here's how safe_substitute() works using an incomplete set of arguments (site will be missing):
>>> template = Template('Hi $name, welcome to $site')
>>> template.safe_substitute(name='John Doe')
'Hi John Doe, welcome to $site'
Here, we fist call safe_substitute() using an incomplete set of arguments. The resulting string contains the original placeholder $site, but no KeyError is raised.
Customizing the Python Template Class
The Python Template class is designed for subclassing and customization. This allows us to modify the regular expression patterns and other attributes of the class to meet our specific needs.
In this section, we'll be covering how to customize some of the most important attributes of the class and how this impact the general behavior of our Template objects. Let's start with the class attribute .delimiter.
Using a Different Delimiter
The class attribute delimiter holds the character used as the placeholder's starting character. As we've seen so far, its default value is $.
Since the Python Template class is designed for inheritance, we can subclass Template and change the default value of delimiter by overriding it. Take a look at the following example where we override the delimiter to use # instead of $:
from string import Template
class MyTemplate(Template):
delimiter = '#'
template = MyTemplate('Hi #name, welcome to #site')
print(template.substitute(name='Jane Doe', site='StackAbuse.com'))
# Output:
# 'Hi Jane Doe, welcome to StackAbuse.com'
# Escape operations also work
tag = MyTemplate('This is a Twitter hashtag: ###hashtag')
print(tag.substitute(hashtag='Python'))
# Output:
# 'This is a Twitter hashtag: #Python'
We can use our MyTemplate class just like we use the regular Python Template class. However, we must now use # instead of $ to build our placeholders. This can be handy when we're working with strings that handle a lot of dollar signs, for example, when we're dealing with currencies.
Note: Do not replace a delimiter with a regular expression. The template class automatically escapes the delimiter. Therefore, if we use a regular expression as delimiter it's highly likely that our custom Template would not work correctly.
Changing What Qualifies as an Identifier
The idpattern class attribute holds a regular expression that is used to validate the second half of a placeholder in a template string. In other words, idpattern validates that the identifiers we use in our placeholders are valid Python identifiers. The default value of idpattern is r'(?-i:[_a-zA-Z][_a-zA-Z0-9]*)'.
We can subclass Template and use our own regular expression pattern for idpattern. Suppose that we need to restrict the identifiers to names that neither contain underscores (_) nor digits ([0-9]). To do this, we can override idpattern and remove these characters from the pattern as follow:
from string import Template
class MyTemplate(Template):
idpattern = r'(?-i:[a-zA-Z][a-zA-Z]*)'
# Underscores are not allowed
template = MyTemplate('$name_underscore not allowed')
print(template.substitute(name_underscore='Jane Doe'))
If we run this code we will get this error:
Traceback (most recent call last):
...
KeyError: 'name'
We can confirm that digits are not allowed as well:
template = MyTemplate('$python3 digits not allowed')
print(template.substitute(python3='Python version 3.x'))
The error will be:
Traceback (most recent call last):
...
KeyError: 'python'
Since underscore and digits are not included in our custom idpattern, the Template object applies the second rule and break the placeholder with the first non-identifier character after $. That's why we get a KeyError in each case.
Building Advanced Template Subclasses
There could be situations where we need to modify the behavior of the Python Template class, but overriding delimiter, idpattern, or both is not enough. In these cases, we can go further and override the pattern class attribute to define an entirely new regular expression for our custom Template subclasses.
If you decide to use a whole new regular expression for pattern, then you need to provide a regular expression with four named groups:
escapedmatches the escape sequence for the delimiter, like in$$namedmatches the delimiter and a valid Python identifier, like in$identifierbracedmatches the delimiter and a valid Python identifier using braces, like in${identifier}invalidmatches other ill-formed delimiters, like in$0site
The pattern property holds a compiled regular expression object. However, it's possible to inspect the original regular expression string by accessing the pattern attribute of the pattern property. Check out the following code:
>>> template = Template('$name')
>>> print(template.pattern.pattern)
\$(?:
(?P<escaped>\$) | # Escape sequence of two delimiters
(?P<named>(?-i:[_a-zA-Z][_a-zA-Z0-9]*)) | # delimiter and a Python identifier
{(?P<braced>(?-i:[_a-zA-Z][_a-zA-Z0-9]*))} | # delimiter and a braced identifier
(?P<invalid>) # Other ill-formed delimiter exprs
)
This code outputs the default string used to compile the pattern class attribute. In this case, we can clearly see the four named groups that conform to the default regular expression. As stated before, if we need to deeply customize the behavior of Template, then we should provide these same four named groups along with specific regular expressions for each group.
Running Code with eval() and exec()
Note:The built-in functions eval() and exec() can have important security implications when used with malicious input. Use with caution!
This last section is intended to open up your eyes on how powerful the Python Template class can be if we use it along with some Python built-in functions like eval() and exec().
The eval() function executes a single Python expression and returns its result. The exec() function also executes a Python expression, but it never returns its value. You normally use exec() when you're only interested in the side-effect of an expression, like a changed variable value for example.
The examples that we're going to cover may seem somewhat unconventional, but we're sure that you can find some interesting use cases for this powerful combination of Python tools. They give insight into how tools that generate Python code work!
For the first example, we're going to use a Template along with eval() to dynamically create lists via a list comprehension:
>>> template = Template('[$exp for item in $coll]')
>>> eval(template.substitute(exp='item ** 2', coll='[1, 2, 3, 4]'))
[1, 4, 9, 16]
>>> eval(template.substitute(exp='2 ** item', coll='[3, 4, 5, 6, 7, 8]'))
[8, 16, 32, 64, 128, 256]
>>> import math
>>> eval(template.substitute(expression='math.sqrt(item)', collection='[9, 16, 25]'))
[3.0, 4.0, 5.0]
Our template object in this example holds the basic syntax of a list comprehension. Beginning with this template, we can dynamically create lists by substituting the placeholders with valid expressions (exp) and collections (coll). As a final step, we run the comprehension using eval().
Since there is no limit on how complex our template strings can be, it's possible to create template strings that hold any piece of Python code. Let's consider the following example of how to use a Template object for creating an entire class:
from string import Template
_class_template = """
class ${klass}:
def __init__(self, name):
self.name = name
def ${method}(self):
print('Hi', self.name + ',', 'welcome to', '$site')
"""
template = Template(_class_template)
exec(template.substitute(klass='MyClass',
method='greet',
site='StackAbuse.com'))
obj = MyClass("John Doe")
obj.greet()
Here, we create a template string to hold a fully-functional Python class. We can later use this template for creating different classes but using different names according to our needs.
In this case, exec() creates the real class and bring it to our current namespace. From this point on, we can freely use the class as we would do with any regular Python class.
Even though these examples are fairly basic, they show how powerful the Python Template class can be and how we can take advantage of it to solve complex programming problems in Python.
Conclusion
The Python Template class is intended to be used for string substitution or string interpolation. The class works using regular expressions and provides a user-friendly and powerful interface. It's a viable alternative to other to the built-in string substitution options when it comes to creating complex string-based templates.
In this article, we've learned how the Python Template class works. We also learned about the more common errors that we can introduce when using Template and how to work around them. Finally, we covered how to customize the class through subclassing and how to use it to run Python code.
With this knowledge at hand, we're in a better condition to effectively use the Python Template class to perform string interpolation or substitution in our code.
↧
↧
PyCharm: PyCharm 2019.3.3
Our PyCharm release is now ready! We’ve added some important fixes to make sure we provide you with the best tool we can, so be sure to update to the newest version! You can get it from within PyCharm (Help | Check for Updates), using JetBrains Toolbox, or by downloading the new version from our website.
In this version of PyCharm
- PyCharm will now always detect Git if it’s installed in the default directory on Windows, regardless of whether it’s on the PATH.
- There’s good news for people developing apps that need to use the camera or microphone on macOS Mojave or later. In order to use these, the OS needs you to give permission to the application. As PyCharm doesn’t use either the microphone or camera, applications that tried to get permission would automatically be blocked. We’ve now resolved this problem.
- SQL database users will be happy to hear we have fixed the issue with the freezes that occurred when autocompleting database table names in joins. Now you can again expect fast autocomplete results and work productively with your databases.
- We know that some of you work with web technologies, which is why PyCharm Professional Edition includes all the JavaScript features from JetBrains WebStorm, and so when there is an issue, we make sure to include the fixes. This time it was a total IDE freeze issue that was caused by a JavaScript library, we have included the fix in PyCharm.
And many more small fixes, see our release notes for details.
Getting the New Version
You can update PyCharm by choosing Help | Check for Updates (or PyCharm | Check for Updates on macOS) in the IDE. PyCharm will be able to patch itself to the new version, there should no longer be a need to run the full installer.
If you’re on Ubuntu 16.04 or later, or any other Linux distribution that supports snap, you should not need to upgrade manually, you’ll automatically receive the new version.
↧
Peter Bengtsson: How to resolve a git conflict in poetry.lock
We use poetry in MDN Kuma. That means there's a pyproject.toml and a poetry.lock file. To add or remove dependencies, you don't touch either file in an editor. For example, to add a package:
poetry add --dev black
It changes pyproject.tomlandpoetry.lock for you. (Same with yarn add somelib which edits package.jsonandyarn.lock).
Suppose that you make a pull request to add a new dependency, but someone sneaks a new pull request in before you and have theirs landed in master before. Well, that's how you end up in this place:
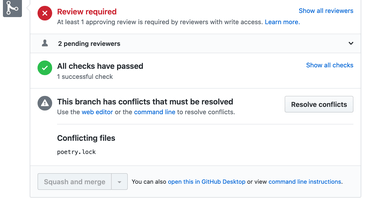
So how do you resolve that?
So, you go back to your branch and run something like:
git checkout master git pull origin master git checkout my-branch git merge master
Now you get this in git status:
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: poetry.lockAnd the contents of poetry.lock looks something like this:
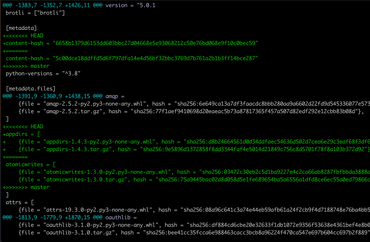
I wish there just was a way poetry itself could just figure fix this.
What you need to do is to run:
# Get poetry.lock to look like it does in master git checkout --theirs poetry.lock # Rewrite the lock file poetry lock
Now, your poetry.lock file should correctly reflect the pyproject.toml that has been merged from master.
To finish up, resolve the conflict:
git add poetry.lock git commit -a -m "conflict resolved" # and most likely needed poetry install
content-hash
Inside the poetry.lock file there's the lock file's hash. It looks like this:
[metadata] content-hash = "875b6a3628489658b323851ce6fe8dafacd5f69e5150d8bb92b8c53da954c1be"
So, as can be seen in my screenshot, when git conflicted on this it looks like this:
[metadata]
+<<<<<<< HEAD+content-hash = "6658b1379d6153dd603bbc27d04668e5e93068212c50e76bd068e9f10c0bec59"+=======
content-hash = "5c00dce18ddffd5d6f797dfa14e4d56bf32bbc3769d7b761a2b1b3ff14bce287"
+>>>>>>> masterBasically, the content-hash = "5c00dce1... is what you'd find in master and content-hash = "6658b137... is what you would see in your branch before the conflict.
When you run that poetry lock you can validate that the new locking worked because it should be a hash. One that is neither 5c00dce1... or 6658b137....
Notes
I'm still new to poetry and I'm learning. This was just some loud note-to-self so I can remember for next time.
I don't yet know what else can be automated if there's a conflict in pyproject.toml too. And what do you do if there are serious underlying conflicts in Python packages, like they added a package that requires somelib<=0.99 and you added something that requires somelib>=1.11.
Also, perhaps there are ongoing efforts within the poetry project to help out with this.
↧
Python Circle: How to compress the uploaded image before storing it in Django
Compressing an image in Django before storing it to the server, How to upload and compress and image in Django python, Reducing the size of an image in Django, Faster loading of Django template, Solving cannot write mode RGBA as JPEG error,
↧
Python Circle: How to upload an Image file in Django
This article explains the simple steps of uploading and storing an image in Django application, After storing the image, how to use it in Django template or emails, Uploading a file in Django, Storing image in Django model, Uploading and storing the image in Django model, HTML for multipart file upload
↧
↧
IslandT: Plotting earning graph based on the month with Python
For those of you who have followed the record sales and save data into the database project, this will be the final chapter of this project. In the future, you can follow the project updates on the Github page.
In this chapter, I have included the combo box which allows the user to select the month he or she wishes to see the graph of sale data!
There is no need to create another combo box to let the user select the month before he submits the earning into the database. We just need to extract the data from the earning table based on the date which has been automatically inserted during the data submission project.
Below is the user interface part of the program where only a combo box has been added beside the plot buttons to let the user selects the month he wishes to view the graph of total earning.
import tkinter as tk
from tkinter import ttk
from Input import Input
win = tk.Tk()
win.title("Earn Great")
def submit(cc): # commit the data into earning table
if(cc=="Shoe"):
sub_mit.submit(shoe_type.get(), earning.get(), location.get(), cc)
elif(cc=='Shirt'):
sub_mit.submit(shirt_type.get(), earning.get(), location.get(), cc)
else:
print("You need to enter a value!")
#create label frame for the shoe ui
shoe_frame= ttk.Labelframe(win, text ="Shoe Sale")
shoe_frame.grid(column=0, row=0, padx=4, pady=4, sticky='w')
# create combo box for the shoe type
shoe_type = tk.StringVar()
shoe_combo = ttk.Combobox(shoe_frame, width=9, textvariable = shoe_type)
shoe_combo['values'] = ('Baby Girl', 'Baby Boy', 'Boy', 'Girl', 'Man', 'Woman')
shoe_combo.current(0)
shoe_combo.grid(column=0, row=0)
# create the submit button for shoe type
action_shoe = ttk.Button(shoe_frame, text="submit", command= lambda: submit("Shoe"))
action_shoe.grid(column=1, row=0)
#create label frame for the shirt ui
shirt_frame= ttk.Labelframe(win, text ="Shirt Sale")
shirt_frame.grid(column=0, row=1, padx=4, pady=4, sticky='w')
# create combo box for the shirt type
shirt_type = tk.StringVar()
shirt_combo = ttk.Combobox(shirt_frame, width=16, textvariable = shirt_type)
shirt_combo['values'] = ('T-Shirt', 'School Uniform', 'Baby Cloth', 'Jacket', 'Blouse', 'Pajamas')
shirt_combo.current(0)
shirt_combo.grid(column=0, row=0)
# create the submit button for shirt type
action_shirt = ttk.Button(shirt_frame, text="submit", command= lambda: submit("Shirt"))
action_shirt.grid(column=1, row=0)
#create label frame for the earning ui
earning_frame= ttk.Labelframe(win, text ="Earning")
earning_frame.grid(column=1, row=0, padx=4, pady=4, sticky='w')
# create combo box for the shoe earning
earning = tk.StringVar()
earn_combo = ttk.Combobox(earning_frame, width=9, textvariable = earning)
earn_combo['values'] = ('1.00', '2.00', '3.00', '4.00', '5.00', '6.00', '7.00', '8.00', '9.00', '10.00')
earn_combo.current(0)
earn_combo.grid(column=0, row=0)
#create label frame for the location ui
location_frame= ttk.Labelframe(win, text ="Location")
location_frame.grid(column=1, row=1, padx=4, pady=4, sticky='w')
# create combo box for the sale location
location = tk.StringVar()
location_combo = ttk.Combobox(location_frame, width=13, textvariable = location)
location_combo['values'] = ('Down Town', 'Market', 'Bus Station', 'Beach', 'Tea House')
location_combo.current(0)
location_combo.grid(column=0, row=0)
def plot(cc): # plotting the bar chart of total sales
sub_mit.plot(location.get(), cc, month.get())
#create label frame for the plot graph ui
plot_frame= ttk.Labelframe(win, text ="Plotting Graph Select Date")
plot_frame.grid(column=0, row=2, padx=4, pady=4, sticky='w')
# create the plot button for shoe type
action_pshoe = ttk.Button(plot_frame, text="Shoe", command= lambda: plot("Shoe"))
action_pshoe.grid(column=1, row=0)
# create the plot button for shirt type
action_pshirt = ttk.Button(plot_frame, text="Shirt", command= lambda: plot("Shirt"))
action_pshirt.grid(column=2, row=0)
# create the plot button for all items
action_p_loc = ttk.Button(plot_frame, text="All Items", command= lambda: plot("All Items"))
action_p_loc.grid(column=3, row=0)
# create combo box for the sale's month
month = tk.StringVar()
month_combo = ttk.Combobox(plot_frame, width=3, textvariable = month)
month_combo['values'] = ('01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12')
month_combo.current(0)
month_combo.grid(column=4, row=0)
win.resizable(0,0)
sub_mit = Input()
sub_mit.setting()
win.mainloop()
Here is the program to plot the graph and to save the data.
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
class Input:
def __init__(self):
pass
def setting(self):
conn = sqlite3.connect('daily_earning.db')
print("Opened database successfully")
try:
conn.execute('''CREATE TABLE DAILY_EARNING_CHART
(ID INTEGER PRIMARY KEY AUTOINCREMENT,
DESCRIPTION TEXT (50) NOT NULL,
EARNING TEXT NOT NULL,
TYPE TEXT NOT NULL,
LOCATION TEXT NOT NULL,
TIME TEXT NOT NULL);''')
except:
pass
conn.close()
def submit(self,description, earning, location, cc): # Insert values into earning table
self.description = description
self.earning = earning
self.location = location
self.cc = cc
try:
sqliteConnection = sqlite3.connect('daily_earning.db')
cursor = sqliteConnection.cursor()
print("Successfully Connected to SQLite")
sqlite_insert_query = "INSERT INTO DAILY_EARNING_CHART (DESCRIPTION,EARNING,TYPE, LOCATION, TIME) VALUES ('" + self.description + "','"+ self.earning + "','" + self.cc + "','" + self.location + "',datetime('now', 'localtime'))"
count = cursor.execute(sqlite_insert_query)
sqliteConnection.commit()
print("Record inserted successfully into DAILY_EARNING_CHART table", cursor.rowcount)
cursor.close()
except sqlite3.Error as error:
print("Failed to insert earning data into sqlite table", error)
finally:
if (sqliteConnection):
sqliteConnection.close()
def plot(self, location, cc, month): # plotting the bar chart
plt.clf() #this is uses to clear the previous graph plot
# dictionary uses to print out the month within header of the graph
monthdict = {'01':'January', '02':'Febuary', '03':'March', '04':'April', '05':'May', '06' : 'June', '07':'July', '08':'August', '09':'September', '10':'October', '11':'November', '12':'December'}
try:
shoe_dict = {'Baby Girl' : 0.00, 'Baby Boy' : 0.00, 'Boy':0.00, 'Girl':0.00, 'Man':0.00, 'Woman':0.00}
shirt_dict = {'T-Shirt':0.00, 'School Uniform':0.00, 'Baby Cloth':0.00, 'Jacket':0.00, 'Blouse':0.00, 'Pajamas':0.00}
sqliteConnection = sqlite3.connect('daily_earning.db')
cursor = sqliteConnection.cursor()
print("Successfully Connected to SQLite")
if cc=='All Items':
cursor.execute("SELECT * FROM DAILY_EARNING_CHART WHERE LOCATION=?", (location,))
else:
cursor.execute("SELECT * FROM DAILY_EARNING_CHART WHERE TYPE=? AND LOCATION=?", (cc, location))
rows = cursor.fetchall()
for row in rows:
if(row[5].split('-')[1]) == month:
if cc=="Shoe":
shoe_dict[row[1]] += float(row[2])
elif cc=="Shirt":
shirt_dict[row[1]] += float(row[2])
elif cc=="All Items":
if row[1] in shoe_dict:
shoe_dict[row[1]] += float(row[2])
else:
shirt_dict[row[1]] += float(row[2])
# dictionary for the graph axis
label_x = []
label_y = []
if cc=="Shoe":
for key, value in shoe_dict.items():
label_x.append(key)
label_y.append(value)
elif cc=="Shirt":
for key, value in shirt_dict.items():
label_x.append(key)
label_y.append(value)
else:
for key, value in shirt_dict.items():
label_x.append(key)
label_y.append(value)
for key, value in shoe_dict.items():
label_x.append(key)
label_y.append(value)
# begin plotting the bar chart
s = pd.Series(index=label_x, data=label_y)
s.plot(color="green", kind="bar", title = cc + " Sales for " + monthdict[month] + " at " + location)
plt.show()
except sqlite3.Error as error:
print("Failed to plot earning data", error)
finally:
if (sqliteConnection):
sqliteConnection.close()
Take note that we need to clear the cache of the graph so those bar charts on the graph will not overlap after the program has plotted the bar chart for the first time and wishes to plot another graph.
 Select a month before plotting the graph
Select a month before plotting the graph The earning chart for the month of February
The earning chart for the month of FebruaryThat is about it, in the future, any latest project update will only appear on the Github page as I have mentioned before.
↧
Talk Python to Me: #250 Capture over 400x C02 as trees with AI and Python
As the popularity of Python grows, we see it popping up in all sorts of interesting places and projects. On this episode, you'll meet C.K. Sample and Nathan Papapietro from HyperGiant. They are using Python and AI to develop the EOS Bioreactor.
↧
Weekly Python StackOverflow Report: (ccxiv) stackoverflow python report
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2020-02-08 21:07:24 GMT
Between brackets: [question score / answers count]
Build date: 2020-02-08 21:07:24 GMT
- Fastest way for boolean matrix computations - [6/3]
- find_peaks does not identify a peak at the start of the array - [6/3]
- Matplotlib with brokenaxes package second Y-Axis - [6/1]
- Pandas nunique equivalent with NumPy - [6/1]
- What do these set operations do, and why do they give different results? - [6/1]
- How can to run python unittests in Django in debug mode with PyCharm using local settings? - [6/0]
- Better way to add the result of apply (multiple outputs) to an existing DataFrame with column names - [5/4]
- How can I change the Python interpreter in virtual environment (Ubuntu 18.04LTS)? - [5/4]
- Is it good code style if a Python function returns different types depending on the arguments - [5/2]
- OpenCV cv2.imshow is not working because of the qt - [5/1]
↧
Mike Driscoll: How to Check if a File is a Valid Image with Python
Python has many modules in its standard library. One that is often overlooked is imghdr which lets you identify what image type that is contained in a file, byte stream or path-like object.
The imghdr can recognize the following image types:
- rgb
- gif
- pbm
- pgm
- ppm
- tiff
- rast
- xbm
- jpeg / jpg
- bmp
- png
- webp
- exr
Here is how you would use it imghdr to detect the image type of a file:
>>> import imghdr >>> path = 'python.jpg' >>> imghdr.what(path) 'jpeg' >>> path = 'python.png' >>> imghdr.what(path) 'png'
All you need to do is pass a path to imghdr.what(path) and it will tell you what it thinks the image type is.
An alternative method to use would be to use the Pillow package which you can install with pip if you don’t already have it.
Here is how you can use Pillow:
>>> from PIL import Image
>>> img = Image.open('/home/mdriscoll/Pictures/all_python.jpg')
>>> img.format
'JPEG'
This method is almost as easy as using imghdr. In this case, you need to create an Image object and then call its format attribute. Pillow supports more image types than imghdr, but the documentation doesn’t really say if the format attribute will work for all those image types.
Anyway, I hope this helps you in identifying the image type of your files.
The post How to Check if a File is a Valid Image with Python appeared first on The Mouse Vs. The Python.
↧
↧
PyBites: Exploring the Mutpy Library and How PyBites Uses it to Verify Test Code
A while back we launched our Test Bites. In this follow up article Harrison explains the MutPy mutation testing tool in depth and how we use it to verify test code on our platform. Enter Harrison.
Table of Contents
- What Is Mutation Testing?
- What Is Mut.py?
- Example of Mut.py's Output
- Killing Mutants
- Summary of Results
- Typical Workflow
- Tips for Completing Test Bites
What Is Mutation Testing?
Mutation testing is a way of testing your tests. It should be used after you already have tests that cover your code well.
In the case of a Test Bite on PyBites, that means you should have 100% code coverage first.
The way it works is by subtly changing, in various ways, the source code being tested, then rerunning the tests for each change.
If the tests continue to pass, then the change was not caught. The idea is that if a random change can be made to the code without causing a failure, then either the tests are not specific enough, or they don't cover enough.
Thus, mutation testing can help you identify areas where your tests are weak and need improvement. Beyond the improvements to your tests, I believe one of the main benefits is the depth of understanding of the code being tested that you often develop. I'll talk more about that later.
Mutation testing has been around for a long time, but because it can be slow, it only recently has started to become more popular. If your tests take a long time to run already, adding mutation testing will increase that time by quite a bit.
Some people also argue that a reason not to use it is that sometimes the mutations are not useful in improving tests. Sometimes you deliberately do not want to test a particular line of code--but to make the mutation tester happy, you either have to test that line or add a comment to tell it not to mutate that line, which doesn't look very nice and can be distracting.
I think it does have pros and cons, so use your discretion in whether to make mutation testing a regular part of a project. For PyBites, where the code is short and the tests are fast, mut.py is a good way to test Test Bites.
Some common terminology in mutation testing inludes: mutant, killed, incompetent, and survived:
Mutant: this refers to a changed copy of the original code.
Killed: a killed mutant is one that causes one of your tests to fail.
Incompetent: an incompetent mutant causes the code to raise an error, before your tests even run. You can consider it killed.
Survived: a mutant that survives did not cause your tests to fail, so the change was not caught.
I like to use an analogy of a lab experimenting on mutant mice. Imagine you're in charge of the last line of defence security system preventing the mutants from escaping and wreaking havoc on society.
A bunch of mutants break out and try to escape. If an escaping mutant survives, your security system needs to be improved. If one is killed, your security system did its job. An incompetent mutant accidentally drank poison before it even got to your security system.
What is Mut.py?
Mut.py is a mutation tester for Python programs. There also exist Mutmut and Cosmic Ray, which you can explore for your own use, but these require multiple commands to run and review results, so they were not ideal for the PyBites environment.
Mut.py makes changes to your Python programs by applying various operations to Abstract Syntax Trees. There are a lot of powerful options -- the complete list can be found in the repository -- which can be used to customize how mutants are generated, types of output, and more.
How to Read Mut.py's Output
There are four sections in Mut.py's output, which are marked by [*]:
The section starting with
Start mutation processloads the code and tests.The section starting with
3 tests passed, which runs the tests with the original (unmutated) code.Start mutants generation and executionmarks the main section, where the mutants are actually generated and tested.The section starting with
Mutation scoresummarizes the results of the mutations.
The first two sections are fairly self-explanatory, and for the most part you won't need to look at them. So, we'll focus on the third and fourth sections.
Here's an example of Mut.py's output from a partially-completed Bite 241:
===2. MutPyoutput====== $ mut.py--targetnumbers_to_dec--unit-testtest_numbers_to_dec.py--runnerpytest-m===
[*] Startmutationprocess:
-targets: numbers_to_dec-tests: /tmp/test_numbers_to_dec.py
[*] 3testspassed:
-test_numbers_to_dec [0.32171s]
[*] Startmutantsgenerationandexecution:
- [# 1] CODnumbers_to_dec: [0.11618s] incompetent- [# 2] CODnumbers_to_dec: [0.11565s] killedbytest_numbers_to_dec.py::test_out_of_range- [# 3] COInumbers_to_dec: [0.11298s] incompetent- [# 4] COInumbers_to_dec: [0.11256s] killedbytest_numbers_to_dec.py::test_out_of_range- [# 5] COInumbers_to_dec: [0.11287s] killedbytest_numbers_to_dec.py::test_out_of_range- [# 6] CRPnumbers_to_dec: [0.11643s] killedbytest_numbers_to_dec.py::test_correct- [# 7] CRPnumbers_to_dec:
--------------------------------------------------------------------------------14: """15: fornuminnums:
16: if(isinstance(num, bool)ornot(isinstance(num, int))):
17: raiseTypeError-18: elifnot(numinrange(0, 10)):
+18: elifnot(numinrange(0, 11)):
19: raiseValueError20:
21: returnint(''.join(map(str, nums)))--------------------------------------------------------------------------------
[0.11324s] survived- [# 8] CRPnumbers_to_dec: [0.13675s] killedbytest_numbers_to_dec.py::test_correct- [# 9] LCRnumbers_to_dec: [0.11509s] killedbytest_numbers_to_dec.py::test_wrong_type
[*] Mutationscore [1.50227s]: 85.7%-all: 9-killed: 6(66.7%)-survived: 1(11.1%)-incompetent: 2(22.2%)-timeout: 0(0.0%)Killing Mutants
The third section of the output gives us all the information we need to start killing mutants, but it can be confusing.
Let's break down a few lines to see what each part means, and which parts are relevant to killing mutants.
- [# 1] COD numbers_to_dec: [0.11618 s] incompetent
[# 1]is the mutation number. It identifies the mutation and allows you to rerun Mut.py with only that mutation to make debugging faster, using the--mutation-number MUTATION_NUMBERflag.CODis the mutation operator. It stands for “conditional operator deletion.” The mutation operator tells you what Mut.py did to mutate the code. The full list of mutation operators can be found in the readme.numbers_to_decis the module being mutated.[0.11618 s]is how long the tests took for this mutation. Sometimes, a mutation will result in an infinite loop, or otherwise cause the tests to take a long time. Mut.py tracks the time for each mutation and compares it to the baseline tests it ran before mutations started, so it can detect and end tests that take much longer than the baseline.incompetentis the result of the mutation. More on this later!
- [# 2] COD numbers_to_dec: [0.11565 s] killed by test_numbers_to_dec.py::test_out_of_range
This is an example of a mutation that was killed. It includes the test module and the specific function from that module which killed the mutant. So, what that means is thattest_out_of_range was the first test to fail.
Note that both this mutation and the previous one would normally print out more information, but PyBites shortens the output to make it clearer. You don't need the extra information for these mutations because they're already done. However, if you run the same command locally, the output will be much more verbose.
- [# 7] CRP numbers_to_dec: … [0.11324 s] survived
Here's a mutant that survived.
It contains the same information the other mutants do, as well as outputting the diff that shows the exact change that was made. The line starting with - 18: is the original code, and the line starting with + 18: is the mutation. The rest is just there for context. In this case, we can see that Mut.py replaced the constant 10 with 11.
With this information, we have what we need to make a test that fails. The test has to make sure that the range doesn't change. Doing that can be tricky, and a lot of people have struggled with this particular mutant.
s
In order to make sure it doesn't change at all, you have to know what it does. This is one of the benefits of testing with Mut.py, as I mentioned above: it forces you to think: what exactly does this code do? Then: how do I test this code to make sure it does exactly what it is supposed to do?
Pretty useful questions!
Summary of Results
The final section summarizes the results, telling us how many mutations there were and the percentage that didn't survive. There are also four ways a mutation can be categorized: killed, survived, incompetent, or timeout.
In this case, 6 mutants were killed, 1 survived, 2 were incompetent, and 0 timed out. Keeping in mind that the goal of your tests is to fail when a mutant is applied, here's an explanation of the categories. We already talked about the killed, survived, and incompetent categories, so that just leaves...
Timeout mutants took too long to run. The cutoff is at 10x longer than the baseline of how long the tests took to run on the unmutated code, so probably what happened is that a loop got broken and started going for infinity or just taking way longer. These ones don't count against us.
Typical workflow
Write code. (Doesn't apply to PyBites test bites -- the code is already written!)
Write tests.
Run mut.py.
Focus on a mutation that survived.
Write/modify a test to fail when the mutation is applied.
Repeat 3-5 until all mutations are killed.
Tips for Completing Test Bites
Some mutants can be particularly, frustratingly stubborn! Sometimes the best thing to do is to step away from the problem for a while and come back to it later. When that doesn't work, here are some tips to help:
Think about these questions:
“What exactly does this line of code do?”
“In what way does this mutation change what this line of code does?”
“How can I write a test that passes for the original line of code, but fails when it is mutated?”
Refresh your memory about how mutation testing works. The process can be especially confusing when you're testing that the code raises errors when it's supposed to, like in the example from Bite 241. You have to write a test that causes the code to fail and the test to pass in the normal (unmutated) case, but causes the code to pass and the test to fail when mutated. Thinking through the workflow may help keep things straight.
Ask for help on the PyBites Slack channel (#pytest channel). There's almost always someone around who will be willing to help. Knowing when to ask for help is part of the learning process, too!
Keep Calm and Code in Python!
-- Harrison
↧
Kushal Das: Python course inside of NSA via a FOIA request
Woke on on Sunday morning, and found Chris Swenson's tweet, he did a FOIA request about the Python course inside of NSA, and then scanned the almost 400 pages of course material. It is 118MB :)
I just went though the document quickly, and a few points from there.
isDivisibleBy7(), sounds like wriiten by a JAVA person :)- too many extra parathesis in the conditional statements.
- same goes to while statement,
while (i <= 20): while (True)- They have an internal Python package index: http://bbtux022.gp.proj.nsa.ip.gov/PYPI (seems only for education purpose)
- Their gitlab instance is: gitlab.coi.nsa.ic.gov
- Exception handling came too late in the course.
- They teach profiling using cProfile
- They also teach f-strings.
- They have some sort of internal cloud MACHINESHOP, most probably the instances are on CentOS/RHEL as they are using
yumcommands two years ago. - They have internal safari access too, but, again on http, http://ncmd-ebooks-1.ncmd.nsa.ic.gov/9781785283758
- They also have an internal wikipedia dump or just some sort of proxy to the main instance, https://wikipedia.nsa.ic.gov/en/Colossally_abundant_number
- An internal jupyter gallery which runs over HTTPS.
- Mentions pickle, but, no mention of the security implications.
- Internal pip mirror: https://pip.proj.nsa.ic.gov/
- git installation instructions are for CentOS/RHEL/Ubuntu/Windows, no Debian :(
↧
Ned Batchelder: sys.getsizeof is not what you want
This week at work, an engineer mentioned that they were looking at the sizes of data returned by an API, and it was always coming out the same, which seemed strange. It turned out the data was a dict, and they were looking at the size with sys.getsizeof.
Sounds great! sys.getsizeof has an appealing name, and the description in the docs seems really good:
sys.getsizeof(object)
Return the size of an object in bytes. The object can be any type of object. All built-in objects will return correct results [...]
But the fact is, sys.getsizeof is almost never what you want, for two reasons: it doesn’t count all the bytes, and it counts the wrong bytes.
The docs go on to say:
Only the memory consumption directly attributed to the object is accounted for, not the memory consumption of objects it refers to.
This is why it doesn’t count all the bytes. In the case of a dictionary, “objects it refers to” includes all of the keys and values. getsizeof is only reporting on the memory occupied by the internal table the dict uses to track all the keys and values, not the size of the keys and values themselves. In other words, it tells you about the internal bookkeeping, and not any of your actual data!
The reason my co-worker’s API responses was all the same size was because they were dictionaries with the same number of keys, and getsizeof was ignoring all the keys and values when reporting the size:
>>> d1 = {"a": "a", "b": "b", "c": "c"}
>>> d2 = {"a": "a"*100_000, "b": "b"*100_000, "c": "c"*100_000}
>>> sys.getsizeof(d1)
232
>>> sys.getsizeof(d2)
232
If you wanted to know how large all the keys and values were, you could sum their lengths:
>>> def key_value_length(d):
... klen = sum(len(k) for k in d.keys())
... vlen = sum(len(v) for v in d.values())
... return klen + vlen
...
>>> key_value_length(d1)
6
>>> key_value_length(d2)
300003
You might ask, why is getsizeof like this? Wouldn’t it be more useful if it gave you the size of the whole dictionary, including its contents? Well, it’s not so simple. Data in memory can be shared:
>>> x100k = "x" * 100_000
>>> d3 = {"a": x100k, "b": x100k, "c": x100k}
>>> key_value_length(d3)
300003
Here there are three values, each 100k characters, but in fact, they are all the same value, actually the same object in memory. That 100k string only exists once. Is the “complete” size of the dict 300k? Or only 100k?
It depends on why you are asking about the size. Our d3 dict is only about 100k bytes in RAM, but if we try to write it out, it will probably be about 300k bytes.
And sys.getsizeof also reports on the wrong bytes:
>>> sys.getsizeof(1)
28
>>> sys.getsizeof("a")
50
Huh? How can a small integer be 28 bytes? And the one-character string “a” is 50 bytes!? It’s because Python objects have internal bookkeeping, like links to their type, and reference counts for managing memory. That extra bookkeeping is overhead per-object, and sys.getsizeof includes that overhead.
Because sys.getsizeof reports on internal details, it can be baffling:
>>> sys.getsizeof("a")
50
>>> sys.getsizeof("ab")
51
>>> sys.getsizeof("abc")
52
>>> sys.getsizeof("á")
74
>>> sys.getsizeof("áb")
75
>>> sys.getsizeof("ábc")
76
>>> face = "\N{GRINNING FACE}"
>>> len(face)
1
>>> sys.getsizeof(face)
80
>>> sys.getsizeof(face + "b")
84
>>> sys.getsizeof(face + "bc")
88
With an ASCII string, we start at 50 bytes, and need one more byte for each ASCII character. With an accented character, we start at 74, but still only need one more byte for each ASCII character. With an exotic Unicode character (expressed here with the little-used \N Unicode name escape), we start at 80, and then need four bytes for each ASCII character we add! Why? Because Python has a complex internal representation for strings. I don’t know why those numbers are the way they are. PEP 393 has the details if you are curious. The point here is: sys.getsizeof is almost certainly not the thing you want.
The “size” of a thing depends on how the thing is being represented. The in-memory Python data structures are one representation. When the data is serialized to JSON, that will be another representation, with completely different reasons for the size it becomes.
In my co-worker’s case, the real question was, how many bytes will this be when written as CSV? The sum-of-len method would be much closer to the right answer than sys.getsizeof. But even sum-of-len might not be good enough, depending on how accurate the answer has to be. Quoting rules and punctuation overhead change the exact length. It might be that the only way to get an accurate enough answer is to serialize to CSV and check the actual result.
So: know what question you are really asking, and choose the right tool for the job. sys.getsizeof is almost never the right tool.
↧
Techiediaries - Django: Django 3 Tutorial & CRUD Example with MySQL and Bootstrap
Django 3 is released with full async support! In this tutorial, we'll see by example how to create a CRUD application from scratch and step by step. We'll see how to configure a MySQL database, enable the admin interface, and create the django views.
We'll be using Bootstrap 4 for styling.
You'll learn how to:
- Implement CRUD operations,
- Configure and access a MySQL database,
- Create django views, templates and urls,
- Style the UI with Bootstrap 4
Django 3 Features
Django 3 comes with many new features such as:
- MariaDB support: Django now officially supports MariaDB 10.1+. You can use MariaDB via the MySQL backend,
- ASGI support for async programming,
- Django 3.0 provides support for running as an ASGI application, making Django fully async-capable
- Exclusion constraints on PostgreSQL: Django 3.0 adds a new ExclusionConstraint class which adds exclusion constraints on PostgreSQL, etc.
Prerequisites
Let's start with the prerequisites for this tutorial. In order to follow the tutorial step by step, you'll need a few requirements, such as:
- Basic knowledge of Python,
- Working knowledge of Django (
django-admin.pyandmanage.py), - A recent version of Python 3 installed on your system (the latest version is 3.7),
- MySQL database installed on your system.
We will be using pip and venv which are bundled as modules in recent versions of Python so you don't actually need to install them unless you are working with old versions.
If you are ready, lets go started!
Django 3 Tutorial, Step 1 - Creating a MySQL Database
In this step, we'll create a mysql database for storing our application data.
Open a new command-line interface and run the mysql client as follows:
$ mysql -u root -p
You'll be prompted for your MySQL password, enter it and press Enter.
Next, create a database using the following SQL statement:
mysql> create database mydb;
We now have an empty mysql database!
Django 3 Tutorial, Step 2 - Initializing a New Virtual Environment
In this step, we'll initialize a new virtual environment for installing our project packages in separation of the system-wide packages.
Head back to your command-line interface and run the following command:
$ python3 -m venv .env
Next, activate your virtual environment using the following command:
$ source .env/bin/activate
At this point of our tutorial, we've a mysql database for persisting data and created a virtual environment for installing the project packages.
Django 3 Tutorial, Step 3 - Installing Django and MySQL Client
In this step, we'll install django and mysql client from PyPI using pip in our activated virtual environment.
Head back to your command-line interface and run the following command to install the django package:
$ pip install django
At the time of writing this tutorial, django-3.0.2 is installed.
You will also need to install the mysql client for Python using pip:
$ pip install mysqlclient
Django 3 Tutorial, Step 4 - Initializing a New Project
In this step, we'll initialize a new django project using the django-admin.
Head back to your command-line interface and run the following command:
$ django-admin startproject djangoCrudExample
Next, open the settings.py file and update the database settings to configure the mydb database:
DATABASES={'default':{'ENGINE':'django.db.backends.mysql','NAME':'mydb','USER':'root','PASSWORD':'<YOUR_DB_PASSWORD>','HOST':'localhost','PORT':'3306',}}Next, migrate the database using the following commands:
$ cd djangoCrudExample
$ python3 manage.py migrate
You'll get a similar output:
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying admin.0003_logentry_add_action_flag_choices... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying auth.0010_alter_group_name_max_length... OK
Applying auth.0011_update_proxy_permissions... OK
Applying sessions.0001_initial... OK
This simply applies a set of builtin django migrations to create some necessary database tables or the working of django.
Django 3 Tutorial, Step 5 - Installing django-widget-tweaks
In this step, we'll install django-widget-tweaks in our virtual environment.
Head back to your command-line interface and run the following command:
$ pip insll django-widget-tweaks
Next, open the settings.py file and add the application to the installed apps:
INSTALLED_APPS=['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles','widget_tweaks']Django 3 Tutorial, Step 6 - Creating an Admin User
In this step, we'll create an admin user that will allow us to access the admin interface of our app using the following command:
$ python manage.py createsuperuser
Provide the desired username, email and password when prompted:
Username (leave blank to use 'ahmed'):
Email address: ahmed@gmail.com
Password:
Password (again):
Superuser created successfully.
Django 3 Tutorial, Step 7 - Creating a Django Application
In this step, we'll create a django application.
Head back to your command-line interface, and run the following command:
$ python manage.py startapp crudapp
Next, you need to add it in the settings.py file as follows:
INSTALLED_APPS=['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles','widget_tweaks','crudapp']Django 3 Tutorial, Step 8 - Creating the Model(s)
In this step. we'll create the database model for storing contacts.
Open the crudapp/models.py file and add the following code:
fromdjango.dbimportmodelsclassContact(models.Model):firstName=models.CharField("First name",max_length=255,blank=True,null=True)lastName=models.CharField("Last name",max_length=255,blank=True,null=True)email=models.EmailField()phone=models.CharField(max_length=20,blank=True,null=True)address=models.TextField(blank=True,null=True)description=models.TextField(blank=True,null=True)createdAt=models.DateTimeField("Created At",auto_now_add=True)def__str__(self):returnself.firstNameAfter creating these model, you need to create migrations using the following command:
$ python manage.py makemigrations
You should get a similar output:
crudapp/migrations/0001_initial.py
- Create model Contact
Next, you need to migrate your database using the following command:
$ python manage.py migrate
You should get a similar output:
Applying crudapp.0001_initial... OK
Django 3 Tutorial, Step 9 - Creating a Form
In this step, we'll create a form for creating a contact.
In the crudapp folder, create a forms.py file and add the following code:
fromdjangoimportformsfrom.modelsimportContactclassContactForm(forms.ModelForm):classMeta:model=Contactfields="__all__"We import the Contact model from the models.py file. We created a class called ContactForm, subclassing Django’s ModelForms from the django.forms package and specifying the model we want to use. We also specified that we will be using all fields in the Contact model. This will make it possible for us to display those fields in our templates.
Django 3 Tutorial, Step 10 - Creating the Views
In this step, we'll create the views for performing the CRUD operations.
Open the crudapp/views.py file and add:
fromdjango.shortcutsimportrender,redirect,get_object_or_404from.modelsimportContactfrom.formsimportContactFormfromdjango.views.genericimportListView,DetailViewNext, add:
classIndexView(ListView):template_name='crudapp/index.html'context_object_name='contact_list'defget_queryset(self):returnContact.objects.all()classContactDetailView(DetailView):model=Contacttemplate_name='crudapp/contact-detail.html'Next, add:
defcreate(request):ifrequest.method=='POST':form=ContactForm(request.POST)ifform.is_valid():form.save()returnredirect('index')form=ContactForm()returnrender(request,'crudapp/create.html',{'form':form})defedit(request,pk,template_name='crudapp/edit.html'):contact=get_object_or_404(Contact,pk=pk)form=ContactForm(request.POSTorNone,instance=post)ifform.is_valid():form.save()returnredirect('index')returnrender(request,template_name,{'form':form})defdelete(request,pk,template_name='crudapp/confirm_delete.html'):contact=get_object_or_404(Contact,pk=pk)ifrequest.method=='POST':contact.delete()returnredirect('index')returnrender(request,template_name,{'object':contact})Django 3 Tutorial, Step 11 - Creating Templates
Open the settings.py file and add os.path.join(BASE_DIR, 'templates') to the TEMPLATES array:
TEMPLATES=[{'BACKEND':'django.template.backends.django.DjangoTemplates','DIRS':[os.path.join(BASE_DIR,'templates')],'APP_DIRS':True,'OPTIONS':{'context_processors':['django.template.context_processors.debug','django.template.context_processors.request','django.contrib.auth.context_processors.auth','django.contrib.messages.context_processors.messages',],},},]This will tell django to look for the templates in the templates folder.
Next, inside the crudapp folder create a templates folder:
$ mkdir templates
Next, inside the templates folder, create the following files:
base.htmlconfirm_delete.htmledit.htmlindex.htmlcreate.htmlcontact-detail.html
By running the following commands from the root of your project:
$ mkdir templates
$ cd templates
$ mkdir crudapp
$ touch crudapp/base.html
$ touch crudapp/confirm_delete.html
$ touch crudapp/edit.html
$ touch crudapp/index.html
$ touch crudapp/create.html
$ touch crudapp/contact-detail.html
Open the crudapp/templates/base.html file and the add:
<!DOCTYPE html><html><head><title>Django 3 CRUD Example</title><metacharset="utf-8"><metaname="viewport"content="width=device-width, initial-scale=1"><linkrel="stylesheet"href="https://maxcdn.bootstrapcdn.com/bootstrap/3.4.0/css/bootstrap.min.css"></head><body>
{% block content %}
{% endblock %}
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo"crossorigin="anonymous"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.3/umd/popper.min.js"integrity="sha384-ZMP7rVo3mIykV+2+9J3UJ46jBk0WLaUAdn689aCwoqbBJiSnjAK/l8WvCWPIPm49"crossorigin="anonymous"></script><script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script><script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.4.0/js/bootstrap.min.js"></script></body></html>Next, open the crudapp/templates/index.html file and the add:
{% extends 'crudapp/base.html' %}
{% block content %}
<divclass="container-fluid"><divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-10 col-xs-10 col-sm-10"><h3class="round3"style="text-align:center;">Contacts</h3></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div><divclass="row"><divclass="col-md-10 col-xs-10 col-sm-10"></div><divclass="col-md-2 col-xs-1 col-sm-1"><br/><ahref="{% url 'create' %}"><buttontype="button"class="btn btn-success"><spanclass="glyphicon glyphicon-plus"></span></button></a></div></div><br/>
{% for contact in contact_list %}
<divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-7 col-xs-7 col-sm-7"><ulclass="list-group"><liclass="list-group-item "><ahref="{% url 'detail' contact.pk %}"> {{ contact.firstName }} {{contact.lastName}} </a><spanclass="badge"></span></li></ul><br></div><divclass="col-md-1 col-xs-1 col-sm-1"><ahref="{% url 'detail' contact.pk %}"><buttontype="button"class="btn btn-info"><spanclass="glyphicon glyphicon-open"></span></button></a></div><divclass="col-md-1"><ahref="{% url 'edit' contact.pk %}"><buttontype="button"class="btn btn-info"><spanclass="glyphicon glyphicon-pencil"></span></button></a></div><divclass="col-md-1"><ahref="{% url 'delete' contact.pk %}"><buttontype="button"class="btn btn-danger"><spanclass="glyphicon glyphicon-trash"></span></button></a></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div>
{% endfor %}
</div>
{% endblock %}
Next, open the crudapp/templates/create.html file and the add:
{% load widget_tweaks %}
<!DOCTYPE html><html><head><title>Posts</title><metacharset="utf-8"><metaname="viewport"content="width=device-width, initial-scale=1"><linkrel="stylesheet"href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css"integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO"crossorigin="anonymous"><style type="text/css"><style></style></style></head><body><divclass="container-fluid"><divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-10 col-xs-10 col-sm-10 "><br/><h6style="text-align:center;"><fontcolor="red"> All fields are required</font></h6></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div><divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-10 col-xs-10 col-sm-10"><formmethod="post"novalidate>
{% csrf_token %}
{% for hidden_field in form.hidden_fields %}
{{ hidden_field }}
{% endfor %}
{% for field in form.visible_fields %}
<divclass="form-group">
{{ field.label_tag }}
{% render_field field class="form-control" %}
{% if field.help_text %}
<smallclass="form-text text-muted">{{ field.help_text }}</small>
{% endif %}
</div>
{% endfor %}
<buttontype="submit"class="btn btn-primary">post</button></form><br></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div></div><script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo"crossorigin="anonymous"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.3/umd/popper.min.js"integrity="sha384-ZMP7rVo3mIykV+2+9J3UJ46jBk0WLaUAdn689aCwoqbBJiSnjAK/l8WvCWPIPm49"crossorigin="anonymous"></script><script src="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.min.js"integrity="sha384-ChfqqxuZUCnJSK3+MXmPNIyE6ZbWh2IMqE241rYiqJxyMiZ6OW/JmZQ5stwEULTy"crossorigin="anonymous"></script></body></html>Next, open the crudapp/templates/edit.html file and the add:
{% load widget_tweaks %}
<!DOCTYPE html><html><head><title>Edit Contact</title><metacharset="utf-8"><metaname="viewport"content="width=device-width, initial-scale=1"><linkrel="stylesheet"href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css"integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO"crossorigin="anonymous"><style type="text/css"><style></style></style></head><body><divclass="container-fluid"><divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-10 col-xs-10 col-sm-10 "><br/><h6style="text-align:center;"><fontcolor="red"> All fields are required</font></h6></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div><divclass="row"><divclass="col-md-1 col-xs-1 col-sm-1"></div><divclass="col-md-10 col-xs-10 col-sm-10"><formmethod="post"novalidate>
{% csrf_token %}
{% for hidden_field in form.hidden_fields %}
{{ hidden_field }}
{% endfor %}
{% for field in form.visible_fields %}
<divclass="form-group">
{{ field.label_tag }}
{% render_field field class="form-control" %}
{% if field.help_text %}
<smallclass="form-text text-muted">{{ field.help_text }}</small>
{% endif %}
</div>
{% endfor %}
<buttontype="submit"class="btn btn-primary">submit</button></form><br></div><divclass="col-md-1 col-xs-1 col-sm-1"></div></div></div><script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo"crossorigin="anonymous"></script><script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.3/umd/popper.min.js"integrity="sha384-ZMP7rVo3mIykV+2+9J3UJ46jBk0WLaUAdn689aCwoqbBJiSnjAK/l8WvCWPIPm49"crossorigin="anonymous"></script><script src="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/js/bootstrap.min.js"integrity="sha384-ChfqqxuZUCnJSK3+MXmPNIyE6ZbWh2IMqE241rYiqJxyMiZ6OW/JmZQ5stwEULTy"crossorigin="anonymous"></script></body></html>Next, open the crudapp/templates/confirm_delete.html file and the add:
{% extends 'crudapp/base.html' %}
{% block content %}
<divclass="container"><divclass="row"></div><br/><divclass="row"><divclass="col-md-2 col-xs-2 col-sm-2"></div><divclass="col-md-10 col-xs-10 col-sm-10"><formmethod="post">
{% csrf_token %}
<divclass="form-row"><divclass="alert alert-warning">
Are you sure you want to delete {{ object }}?
</div></div><buttontype="submit"class="btn btn-danger"><spanclass="glyphicon glyphicon-trash"></span></button></form></div></div></div>
{% endblock %}
Django 3 Tutorial, Step 12 - Creating URLs
In this step, we'll create the urls to access our CRUD views.
Go to the urls.py file and update it as follows:
fromdjango.contribimportadminfromdjango.urlsimportpathfromcrudappimportviewsurlpatterns=[path('admin/',admin.site.urls),path('contacts/',views.IndexView.as_view(),name='index'),path('contacts/<int:pk>/',views.ContactDetailView.as_view(),name='detail'),path('contacts/edit/<int:pk>/',views.edit,name='edit'),path('contacts/create/',views.create,name='create'),path('contacts/delete/<int:pk>/',views.delete,name='delete'),]Django 3 Tutorial, Step 11 - Running the Local Development Server
In this step, we'll run the local development server for playing with our app without deploying it to the web.
Head back to your command-line interface and run the following command:
$ python manage.py runserver
Next, go to the http://localhost:8000/ address with a web browser.
Conclusion
In this django 3 tutorial, we have initialized a new django project, created and migrated a MySQL database, and built a simple CRUD interface.
↧
↧
Mike Driscoll: PyDev of the Week: Paul Sokolovsky
This week we welcome Paul Sokolovsky as our PyDev of the Week! Paul is the creator of Pycopy, which is described as “a minimalist and memory-efficient Python implementation for constrained systems, microcontrollers, and just everything”. You can check out more of his contributions to open source on Github. Let’s take a few moments to get to know Paul better!

Can you tell us a little about yourself (hobbies, education, etc):
I have Computer Science as my first masters, and later got another masters in Linguistics – when I was a CS student I was interested in Natural Language Processing subfield of AI, and wanted to get a formal degree to work in that areas, perhaps in academia, but that never panned out, I got sucked up into the IT industry, a common story ;-).
Hobbies – well, nothing special, I like to travel, and even if a plane carries me far away, I like to get on my feet and explore like humans did it for millennia. Though if there’s a motorbike for rent, I like to ride it to a more distant mountain before climbing it. My latest interest is history. Like, everyone took history lessons in school and might have their “favorite” history of a particular country at particular timeframe, but trying to grasp history of mankind across the mentioned millennia is a different matter.
Why did you start using Python?
Oh, as many students, at that age I drooled over Lisp and Scheme programming languages. I did a few projects in them, and while they were definitely great and I could grok them, it occurred to me that I wasn’t not sure about the rest of world. Programming is inherently social activity. And besides the power of those languages, their drawbacks were also evident, and while I was able to surmount them, other people might be not just unable, but even unwilling to do that.
So, I started my quest of the best-in-compromise programming languages, sifting thru dozens of both mainstream and obscure languages of that time. I stopped when I found Python. I think of it as “Lisp for real world”. Those were the times of Python 1.5.1…
What other programming languages do you know and which is your favorite?
Based on the above, it shouldn’t come as surprise that Python is my favorite languages. I know a bunch of scripting languages – Perl, PHP, Java, JavaScript, Lisp, Scheme, and more “systemish” ones like C and C++. I definitely watch the space and keep an eye on Go, Rust which approaching upstream and niche contenders like Nim, Zig, whatever. I don’t rush into using them – again, I passed that stage of language-hopping when I was a student.
What projects are you working on now?
My biggest project currently is Pycopy, which is a lightweight and minimalist implementation of Python, with a library and software ecosystem around it. While I loved Python all along, that was one of problems I’ve seem with it – it’s too big, so I couldn’t use it everywhere I wanted, like small embedded devices like routers or WiFi access points (that kind would be nowadays called “IoT devices”). I had to leave Python and try to involve with smaller languages like Lua, but I failed to acquire Stockholm syndrome for them, and always came back to Python, and thus zero progress with some interesting projects requiring small and cheap devices, like Smart Home.
That’s why when I heard about MicroPython Kickstarter campaign and read some technical descriptions which were very solid, I got instantly hooked and pledged to its author to open up source soon after the conclusion of the very successful campaign, instead of at the time of shipping the devices – all to allow open-source cooperation. I’ve
contributed to MicroPython for around 4 years since, having written some 30% of the codebase. Sadly, going forward, I felt that the ideas of minimalism with which we started are being betrayed, while conflict of interest was growing between a contributor doing a work in his own free time, based on beliefs and ideals, vs a small business which needs to satisfy its customers to stay afloat and generate profit. So, we parted our ways.
That’s how Pycopy came to be. Unlike MicroPython, which came to concentrate on “microcontrollers” (a mistake repeated after another small Python implementation, PyMite, which in my opinion came is its downfall), Pycopy wants to be a full-stack language for “everything”. The ideals is to use one language on your desktop/laptop, in the cloud if you use that, on mobile devices if you care to run your software on them, and all the way down to microcontrollers, though while cool, it still remains a relatively niche case, with small, but Linux-based devices often more accessible and cost-effective.
So, beyond the core interpreter with minimal set of modules, the Pycopy project offers standard library, which strives to be compatible with CPython, while still remaining small, a web micro-framework, database drivers, SDL (graphics library) bindings, FFMPEG (video/audio library) bindings, recently being developed binding for LLVM, which is compiler backend to easily develop accelerator JIT engines, as something which Python community direly needs, to counter those simpleton claims that “Python is slow” – and many other things. It’s really cool, you should check it out. It’s definitely something I wanted to develop whole my life, and I’m glad I’ll be content with having done that when I grow old ;-).
One important thing is that all the above isn’t done in some formal plan or to reimplement everything what “big” Python has. It’s all done based on demand/interest from myself and contributors. Like, I got interested in playing with video surveillance and that’s why I implemented FFMPEG bindings to access video from a camera (instead of
streaming it into to an unknown party’s cloud). I find this as recent, maybe niche, but definitely a trend – to come to up with human-scale computing – instead of corporate-scale or industry-scale – something, which a mere human can understand as a whole, modify for one’s own needs, and extend. That’s exactly the idea behind the Pycopy project! And don’t get me wrong – we need corporate-scale or industry-scale projects too, that’s what I do at my day job. But in my own free time, which generally belongs to my family and fellow humans with which I share common interests, I’d rather do something human-size.
Any other Python projects caught your attention recently?
One great project I spotted too late last August is PPCI, Pure PythonCompiler Infrastructure by Windel Bouwman. “Too late” as I usually watch project spaces of interest to me, for example I’m aware of 3-4 C language compilers implemented in Python. But PPCI is a true gem, living to its promise of being not just a small adhoc compiler, but the entire compiler infrastructure from parsing down to “almost industrial grade” optimization and codegeneration. And with all that, it’s largely a result of one man’s work in his own free time, which again shows the power Python brings. All in all, it’s a kind of project I always dreamed to work on, but never was brave enough to start. I now try to carve out time to contribute to it, and envision it to become a go-to project for all people interested in compilers and optimization.
Second project is a recent find. As an intro, it by now should be clear that I don’t just develop my own project, but keep an eye on the wide community progress. In my opinion, it’s the base of open-source idea that duplication of effort should be avoided, but if it happens, an author of such a project should have a clear answer for both themselves and users/contributors of why the duplication happens. So, I already mentioned PyMite as a “spiritual successor” of MicroPython/Pycopy.
Another similar project was TinyPy. Both of these projects implemented just a small subset of the language, so in effect they were Python-like languages and barely could run any real Python code. That’s why I jumped on MicroPython bandwagon, which promised (and delivered) almost complete compatibility with Python language (but not libraries, though users could add those themselves). Despite that, TinyPy is really cool project, e.g. it implements bytecode compiler in Python itself (something which I’m doing now for Pycopy too). The more interesting was to find out that some guy decided to revive the old TinyPy and build a new project Called TPython++ based on it. To me personally it looks like an adhoc attempt to marry it with a game engine, but I can’t know it all. If anything, it shows how vibrant, wide-reaching the Python community is.
Thanks for doing the interview, Paul!
The post PyDev of the Week: Paul Sokolovsky appeared first on The Mouse Vs. The Python.
↧
PyBites: Productivity Mondays - How to Instantly Save 2-3 Hours a Day
Efficiency is doing things right; effectiveness is doing the right things. - Peter Drucker
Imagine what an extra 2-3 hours a day can give you. Reading consistently for an hour a day in your field can change your career for the better. An hour of Python coding a day can land you a developer job over time. What about spending more time with your family?
This stuff matters!
In my early days I was a perfectionist. I only later read how this rubbed some people the wrong way when I was cleaning out old study reports.
More importantly it prevented me from taking massive action towards my goals!
An eye for detail is a good quality to have, specially as a developer. But at the end of the day practicality beats purity (Zen of Python).
Being effective vs being efficient.
This paragraph of Tim Ferriss' 4 hour work week blew us away:
Here are two truims to keep in mind:
Doing something unimportant well does not make it important.
Requiring a lot of time does not make a task important.
From this moment forward, remember this: What you do is infinitely more important than how you do it.
Efficiency is still important, but it is useless unless applied to the right things.
A few things we changed for ourselves this year that is getting us major results:
We plan in advance: the weekend we plan out our weeks, the night before we plan out our days. If you don't do this, stop reading and grab a piece of paper ... 1 min in planning saves you 10 min in execution, to me that seems a pretty awesome ROI. Also this instantly clears your mind (= better sleep).
We define our 80/20 (Pareto principle) and try to stick with that. Only a few things really matter. Less is more!
We use time blocks (deadlines). As per Parkinson's law: work expands so as to fill the time available for its completion. We all know how efficient you can be the day before holidays, no? :)
Now go take some action: cut ruthlessly in your schedule and report back below if you were able to save some time to work on the more meaningful stuff (Python, reading, portfolio, career, etc). See you next week.
↧
IslandT: Create a project which shows the nutrition and diet data for generic foods, packaged foods, and restaurant meals using python
Hello, nice to be back again, are you people ready for the next python project? In this latest project which will take maybe around half a month to complete, I will develop a python application that will show the nutrition and diet data for generic foods, packaged foods, and restaurant meals to the user. This application will use one of the free APIs from Rapid API to receive all the data that this project ever needs.
First of all, if you have not yet signed up for a free account at Rapid API, then just go ahead and do so. This site offers both the paid API and free API which the application developer can use in his or her own project. After you have signed up and signed into your account, search for this API: Edamam Food and Grocery Database.
About the food API:
Edamam provides access to a food and grocery database with over 750,000 basic foods, restaurant items, and consumer packaged foods – The foods in the Food API can be filtered by Diet and health filters generated by Edamam. All food database data is enriched with diet, allergy and health labeling, as calculated by Edamam based on the food’s ingredients. Peanut Free, Shellfish Free, Gluten-Free, Vegan and Vegetarian are some of the 20+ claims generated automatically. – For basic foods from the food database (flour, eggs, flour, etc.), Edamam returns data for calories, fats, carbohydrates, protein, cholesterol, sodium for a total of 28 nutrients. For UPC foods and fast foods data is return as listed on their nutrition label UPC or Barcode search – The Food Database API provides access to over 550,000 unique UPC codes. Low-cost solution – Edamam provides free Food API access with its basic plan for developers, startups and non-profits alike. – Enterprise customers are charged a very low monthly and per call fee based on usage. Custom packages are also available.
We will use the basic plan from the above-mentioned provider to develop our application for our own use, for those of you who are interested in the Enterprise version, you can ask the API provider for further information. I don’t know how much data will I get from the free version but we will see when we progress together!
In this chapter, I am just going to take it easy by following the python code provides by the API provider on their page to make a request and see what will I get from the API call. I have created a file to keep the API key and the API hostname so the program can read those two items later on.
import requests
# read the host and key from file then insert into a list
key_host = []
# since the file is there therefore no need to use the try and except block
f=open("key.txt", "r")
if f.mode == 'r':
f_l = f.readlines()
for line in f_l:
key_host.append(line)
f.close()
url = "https://edamam-food-and-grocery-database.p.rapidapi.com/parser"
querystring = {"ingr":"orange"}
headers = {
'x-rapidapi-host': key_host[0][:-1],
'x-rapidapi-key': key_host[1]
}
response = requests.request("GET", url, headers=headers, params=querystring)
print(response.text)
Below is what we receive after the API call.
 Part of the data we have received
Part of the data we have receivedI have also noticed that there are lots of URIs within the returning data that we can use to make further API call (perhaps?).
The above is just a simple program, I like to go from really easy to complicated, we build a little bit of stuff day by day, and we will get there slowly, don’t worry!
↧