The Python standard library is full of underappreciated gems. One of them allows for simple and elegant function dispatching based on argument types. This makes it perfect for serialization of arbitrary objects – for example to JSON in web APIs and structured logs.
↧
Hynek Schlawack: Better Python Object Serialization
↧
S. Lott: Patreon Book Idea
See "Additional, Related Content". It's one of the posts here: https://www.patreon.com/slott.
I think there's space for a Building Skills in Functional Python title next to the Building Skills in OO Design.
↧
↧
Codementor: How I use Python to get Salesforce data
Writing a script that accesses data from Salesforce from using the Python language is easier than you think. Go ahead and Salesforce and Python combination!
↧
Python Software Foundation: Python Software Foundation Fellow Members for Q4 2019
We are happy to announce our newest PSF Fellow Members for Q4!
Let's continue to recognize Pythonistas all over the world for their impact on our community. The criteria for Fellow members is available online: https://www.python.org/psf/fellows/. If you would like to nominate someone to be a PSF Fellow, please send a description of their Python accomplishments and their email address to psf-fellow at python.org. We are accepting nominations for quarter 1 through February 20, 2020.
The Fellow Work Group is looking for more members from all around the world! If you are a PSF Fellow and would like to help review nominations, please email us at psf-fellow at python.org. More information is available at: https://www.python.org/psf/fellows/.![]()
![]()
![]()
![]()
![]()
Q4 2019
Humphrey Butau
Ngazetungue Muheue
Twitter
Pablo Galindo Salgado
GitHub, Twitter
Patrick Arminio
Twitter, Personal website
Ngazetungue Muheue
Pablo Galindo Salgado
GitHub, Twitter
Patrick Arminio
Twitter, Personal website
Congratulations! Thank you for your continued contributions. We have added you to our Fellow roster online.
The above members have contributed to the Python ecosystem by teaching Python, contributing to and maintaining CPython, organizing Python events and conferences, starting Python communities in their home countries, and overall being great mentors in our community. Each of them continues to help make Python more accessible around the world. To learn more about the new Fellow members, check out their links above.
The above members have contributed to the Python ecosystem by teaching Python, contributing to and maintaining CPython, organizing Python events and conferences, starting Python communities in their home countries, and overall being great mentors in our community. Each of them continues to help make Python more accessible around the world. To learn more about the new Fellow members, check out their links above.
Let's continue to recognize Pythonistas all over the world for their impact on our community. The criteria for Fellow members is available online: https://www.python.org/psf/fellows/. If you would like to nominate someone to be a PSF Fellow, please send a description of their Python accomplishments and their email address to psf-fellow at python.org. We are accepting nominations for quarter 1 through February 20, 2020.
Help Wanted!
↧
Real Python: Python args and kwargs: Demystified
Sometimes, when you look at a function definition in Python, you might see that it takes two strange arguments: *args and **kwargs. If you’ve ever wondered what these peculiar variables are, or why your IDE defines them in main(), then this course is for you! You’ll learn how to use args and kwargs in Python to add more flexibility to your functions.
By the end of the course, you’ll know:
- What
*argsand**kwargsactually mean - How to use
*argsand**kwargsin function definitions - How to use a single asterisk (
*) to unpack iterables - How to use two asterisks (
**) to unpack dictionaries
This course assumes that you already know how to define Python functions and work with lists and dictionaries.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
↧
↧
Python Engineering at Microsoft: Python in Visual Studio Code – January 2020 Release
We are pleased to announce that the January 2020 release of the Python Extension for Visual Studio Code is now available. You candownload the Python extension from the Marketplace, or install it directly from the extension gallery in Visual Studio Code. If you already have the Python extension installed, you can also get the latest update by restarting Visual Studio Code. You can learn more about Python support in Visual Studio Code in the documentation.
In this release we addressed 59 issues, including:
- Kernel selection in Jupyter Notebooks
- Performance improvements in the Jupyter Notebook editor
- Auto-activation of environments in the terminal on load (thanks Igor Aleksanov!)
- Fixes to rebuilding ctags on save and on start
If you’re interested, you can check the full list of improvements in our changelog.
Kernel selection in Jupyter Notebooks

In the top right of the Notebook Editor and the Interactive Window, you will now be able to see the current kernel that the notebook is using along with the kernel status (i.e. whether it is idle, busy, etc…). This release also allows you to change your kernel to other Python kernels. To change your current active kernel, click on the current kernel to bring up the VS Code kernel selector and select which kernel you want to switch to from the list.
Performance improvements in the Jupyter Notebook editor!
This release includes many improvements to the performance of Jupyter in VS Code in both the Notebook editor and the Interactive Window. This was accomplished through caching previous kernels and through optimizing the search for Jupyter. Some of the significant improvements due to these changes are:
- Initial starting of the Jupyter server is faster, and subsequent starts of the Jupyter server are more than 2X faster
- Creating a blank new Jupyter notebook is 2X faster
- Opening Jupyter Notebooks (especially with a large file size) is now 2x faster
Note: these performance calculations were measured in our testing, your improvements may vary.
Auto-activation of environments in the terminal on load
When you have a virtual or conda environment selected in your workspace and you create a new terminal, the Python extension activates the selected environment in that new terminal. Now, this release includes the option of having environments to be auto activated in an already open terminal right when the Python extension loads.

To enable this feature, you can add the setting “python.terminal.activateEnvInCurrentTerminal“: true to your settings.json file. Then when the extension loads and there’s a terminal open in VS Code, the selected environment will be automatically activated.
Fixes to rebuilding ctags on save and on start
The ctags tool is responsible for generating workspace symbols for the user. As a result, the document outline becomes populated with file symbols, allowing you to easily find these symbols (such as functions) within your workspace.
This release includes a fix for the most upvoted bug report on our GitHub repo (GH793), related to ctags. Now, tags stored in the .vscode folder for your project can be rebuilt when the Python extension loads by setting “python.workspaceSymbols.rebuildOnStart” to true, or rebuilt on every file save by setting “python.workspaceSymbols.rebuildOnFileSave” to true.

You can learn more about ctags support in our documentation.
Other Changes and Enhancements
We have also added small enhancements and fixed issues requested by users that should improve your experience working with Python in Visual Studio Code. Some notable changes include:
- Support the ability to take input from users inside of a notebook or the Interactive Window. (#8601)
- Support local images in markdown and output for notebooks. (#7704)
- Support saving plotly graphs in the Interactive Window or inside of a notebook. (#7221)
- Use “conda run” when executing Python and an Anaconda environment is selected. (#7696)
- Activate conda environment using path when name is not available. (#3834)
- Add QuickPick dropdown option to Run All/Debug All parametrized tests. (thanks to Philipp Loose) (#5608)
We’re constantly A/B testing new features. If you see something different that was not announced by the team, you may be part of the experiment! To see if you are part of an experiment, you can check the first lines in the Python extension output channel. If you wish to opt-out of A/B testing, you can open the user settings.json file (View > Command Palette… and run Preferences: Open Settings (JSON)) and set the “python.experiments.enabled” setting to false.
Be sure todownload the Python extensionfor Visual Studio Code now to try out the above improvements. If you run into any problems, please file an issue on thePython VS Code GitHubpage.
The post Python in Visual Studio Code – January 2020 Release appeared first on Python.
↧
PyCoder’s Weekly: Issue #402 (Jan. 7, 2020)
#402 – JANUARY 7, 2020
View in Browser »
Last Python 2.7 Maintenance Release on April 2020
Python 2.7 is retired and became EOL on Jan 1, 2020. The last 2.7 release will be in April 2020.
PYTHON.ORG
Ubuntu 20.04 LTS Moves Along With Its Python 2 Removal
“With Python 2 having reached end-of-life at the start of 2020, Ubuntu and Debian developers continue their work on removing Python 2 at least from the base OS. Work continues on transitioning packages to Python 3 or otherwise ultimately dropping unmaintained packages.”
MICHAEL LARABEL
Optimize Your Python Applications in One Place
Dissect problematic requests with Datadog’s detailed flame graphs, and trace their path across your environment. See which caches, databases, or services are generating errors or contributing to overall latency to assist troubleshooting efforts or to identify opportunities for optimization →
DATADOGsponsor
Python *args and **kwargs Demystified
Learn how to use args and kwargs in Python to add more flexibility to your functions. You’ll also take a closer look at the single and double-asterisk unpacking operators, which you can use to unpack any iterable object in Python.
REAL PYTHONvideo
I’m Not Feeling the Async Pressure
“So for you developers of async libraries here is a new year’s resolution for you: give back pressure and flow control the importance they deserve in documentation and API.”
ARMIN RONACHER
Considering Python’s Target Audience [2017]
Who is Python being designed for? CPython core dev Nick Coghlan discusses Python’s and PyPI’s target audience and design philosophy. Recommended reading.
NICK COGHLAN
DjangoCon Europe 2020 Announcement
DjangoCon Europe 2020 will take place in Porto, Portugal from May 27–31, 2020.
DJANGOPROJECT.COM
Discussions
Which Little Known Python Tool Do You Consider Indispensable?
ast.literal_eval() vs functools.lru_cache() vs pdb.pm() vs reprlib.recursive_repr()– Which one is your favorite?
RAYMOND HETTINGER
Python Jobs
Python Web Developer (Remote)
Software Engineer (Bristol, UK)
Articles & Tutorials
A Python Packaging Carol
“Quite often, I see people being wrong on the internet about Python packaging. But the way in which they’re wrong is subtle, and often passes unnoticed. The issue with much of the discussion is in conflating multiple different things under the term ‘packaging’, and failing to be clear exactly which of them is being discussed or criticized.”
JAMES BENNETT
Using Pandas and Python to Explore Your Dataset
In this step-by-step tutorial, you’ll learn how to start exploring a dataset with Pandas and Python. You’ll learn how to access specific rows and columns to answer questions about your data. You’ll also see how to handle missing values and prepare to visualize your dataset in a Jupyter notebook.
REAL PYTHON
How to Build a Python Recommendation Engine
Did you know that 70% of movies a Netflix user watches are from recommendations? Recommendation engines provide significant value to user-bases. Check out ActiveState’s tutorial on how to build your own in Python with Pandas and Flask →
ACTIVESTATEsponsor
Counting Queries: Basic Performance Testing in Django
“Testing application performance is hard and time consuming, but there’s a type of test that is both easy to do and has a great impact in performance. In this blog post we will show how to unit test the number of queries to the database your application is making.”
FILIPE XIMENES• Shared by Filipe Ximenes
Exploring NumPy’s linspace() Function
NumPy supports different ways of generating arrays, and this tutorial is going to explore one way of do so, using the np.linspace() function. It returns evenly-spaced numbers and can generate arrays of any dimensionality.
AHMED GAD
pytest Features You Need in Your (Testing) Life
Tips that make your testing experience more enjoyable and more efficient, like filtering warnings, testing stdout/stderr, and parametrization.
MARTIN HEINZ
Autograding Handwritten Mathematical Answer Sheets
This article is about building a computer vision model to automatically grade handwritten mathematical worksheets using Python.
DIVYAPRABHA M• Shared by Divyaprabha M
Making Python Programs Blazingly Fast
“First rule of optimization is to not do it. But, if you really have to, then I hope these few tips help you with that.”
MARTIN HEINZ
Zero-Downtime Deploys With a Single Server
How PyDist achieves zero-downtime deploys without a typical load balancer and blue/green server infrastructure.
ALEX BECKER• Shared by Alex Becker
Measure and Improve Python Code Performance with Blackfire.io
Profile in development, test/staging, and production—with no overhead for end users! Blackfire supports any Python version from 2.7.x and 3.x. Find bottlenecks in wall-time, I/O, CPU, memory, HTTP requests and SQL queries.
BLACKFIREsponsor
How to Write a Python Web API With Pyramid and Cornice
Using Pyramid and Cornice to build and document scalable RESTful web services.
MOSHE ZADKA
Projects & Code
tmtoolkit: Text Mining and Topic Modeling Toolkit
GITHUB.COM/WZBSOCIALSCIENCECENTER• Shared by Markus Konrad
ElasticBatch: Easy Elasticsearch Inserts for Data Processing Workflows
GITHUB.COM/DKASLOVSKY• Shared by Daniel Kaslovsky
switchenv: Python-Based Tool for Managing Bash Environments
GITHUB.COM/ROBDMC• Shared by Rob deCarvalho
Events
Heidelberg Python Meetup
January 8, 2020
MEETUP.COM
Python North East
January 8, 2020
PYTHONNORTHEAST.COM
PyStaDa
January 8, 2020
PYSTADA.GITHUB.IO
pyCologne User Group Treffen
January 8, 2020
PYCOLOGNE.DE
Santa Cruz Python Meetup
January 8, 2020
MEETUP.COM
Python Atlanta
January 9, 2020
MEETUP.COM
Yola Python Club 2020
January 11 to January 12, 2020
EVENTBRITE.COM
Python Miami
January 11 to January 12, 2020
PYTHONDEVELOPERSMIAMI.COM
Happy Pythoning!
This was PyCoder’s Weekly Issue #402.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
↧
Dataquest: Tutorial: Python Regex (Regular Expressions) for Data Scientists
In this tutorial, learn how to use regular expressions and the pandas library to manage large data sets during data analysis.
The post Tutorial: Python Regex (Regular Expressions) for Data Scientists appeared first on Dataquest.
↧
Will Kahn-Greene: How to pick up a project with an audit
Over the last year, I was handed a bunch of projects in various states. One of the first things I do when getting a new project that I'm suddenly responsible for is to audit the project. That helps me figure out what I'm looking at and what I need to do with it next.
This blog post covers my process for auditing projects I'm suddenly the proud owner of.
Read more… (5 min remaining to read)
↧
↧
Stack Abuse: Deploying Django Applications to AWS EC2 with Docker
Introduction
In the fast-paced field of web applications, containerization has become not only common but the preferred mode of packaging and delivering web applications. Containers allow us to package our applications and deploy them anywhere without having to reconfigure or adapt our applications to the deployment platform.
At the forefront of containerization is Docker, which is a tool that is used to package and run applications in containers that are platform agnostic. Serverless technology is also flourishing in this era of containerization and is proving to be the go-to option for developers when deploying their applications with more and more providers allowing users to deploy containerized software.
While building an application is important, making it available to the end-users is also a crucial part of the product. In this post, we will package a Django application using Docker and deploy it to Amazon's EC2.
What is EC2?
Amazon's Elastic Compute Cloud (EC2) is an offering that allows developers to provision and run their applications by creating instances of virtual machines in the cloud. EC2 also offers automatic scaling where resources are allocated based on the amount of traffic received.
Just like any other AWS offerings, EC2 can be easily integrated with the other Amazon services such as the Simple Queue Service (SQS), or Simple Storage Service (S3), among others.
EC2 has the following features:
- Instances: Virtual computing environments or servers that allow developers to run their applications. These instances can be configured in terms of memory, storage, computing power, and network resources to suit the current need or scenario.
- Amazon Machine Images (AMIs): Preconfigured templates that are used to create instances. They come with operating systems and preloaded software as required and are customizable.
- Instance Store Volumes: Used to store data temporarily. This data is deleted when the instance is terminated.
- Elastic Block Store (EBS) Volumes: Highly available and reliable storage volumes that are attached to instances for the purpose of persistently storing data. The data stored in EBS Volumes outlives the instances and multiple volumes can be mounted on an instance.
- Security Groups: Virtual firewalls that govern access to instances by specifying protocols, IP address ranges, and ports. This enables us to control and restrict traffic to our instances.
These are but a few of the features of Amazon's Elastic Compute Cloud and more can be found in the documentation.
Prerequisites
In this tutorial, we'll build a web application and deploy it to Amazon's EC2 service. To achieve that we need:
- An Amazon Web Services (AWS) account which will give us access to EC2. Through this link, you can sign up for the free tier which is sufficient for the work in this post.
- Python 3.6+, Pip, and Virtualenv installed in order to build our Django application.
- Docker will also be needed to package our application and easily run it in a container that is not only portable but can run anywhere Docker is installed.
Dockerizing a Django Application
We are going to start by building our simple Django application and containerizing it to allow us to easily deploy it. Let's start off with creating a folder for our project:
$ mkdir django_ec2 && cd $_
Then a virtual environment:
$ virtualev --python=python3 env --no-site-packages
Then, let's activate it and install Django:
$ source env/bin/activate
$ pip install Django
A simple placeholder Django app will suffice. All we have to do to bootstrap the project is run django-admin's startproject command, which starts a basic project for the given directory name:
$ django-admin startproject django_ec2_project
Then, let's enter the project directory:
$ cd django_ec2_project
And start a lightweight development server:
$ python manage.py runserver
If all goes well, we should be able to view the following landing page when we access our application at localhost:8000:

Before packaging our Django application, we need to allow traffic from all sources, which we can achieve by modifying the ALLOWED_HOSTS setting in django_ec2_project/django_ec2_project/settings.py:
# Add the asterisk in the empty list
ALLOWED_HOSTS = ['*']
Since this is enough to be deployed, let us go ahead and containerize our application by adding a Dockerfile in the root of our project containing the following:
FROM python:3.6-alpine
MAINTAINER Robley Gori <ro6ley.github.io>
EXPOSE 8000
RUN apk add --no-cache gcc python3-dev musl-dev
ADD . /django_ec2
WORKDIR /django_ec2
RUN pip install -r requirements.txt
RUN python django_ec2_project/manage.py makemigrations
RUN python django_ec2_project/manage.py migrate
CMD [ "python", "django_ec2_project/manage.py", "runserver", "0.0.0.0:8000" ]
This Dockerfile describes how our application will be containerized and run. At the top, we use a base image that comes with Python 3.6 installed. We also expose the port 8000, which means that traffic into the container should be directed to that port, which is also where our Django application will be running from. We install a few packages to our image and then add our Django application to the django_ec2 directory.
Since our Django project is containerized, we will not need to create a virtual environment since it is already isolated from the machine that will be running it. Therefore, we install the requirements directly and run the migrations.
At the very end, we add the command that will be executed when the container is started, which in our case will also start our Django application and run it on port 8000.
If you'd like a more in-depth explanation on this topic, check out our article Dockerizing Python Applications.
The next step will be to build our Docker image using the Dockerfile above. Before that, we will save the dependencies installed in the environment to a file:
$ pip freeze > requirements.txt
And only then, let's build the docker image:
$ docker build . -t django_ec2
Through this command, Docker will look for our Dockerfile in the current folder and use it to build an image, which will be tagged as django_ec2. Once our image is built, we can run it using the command:
$ docker run -d -p 8000:8000 django_ec2
This command will start our container that has our running Django application and map the port 8000 on our machine to the container's port 8000, as specified by the -p flag and will run headlessly (even after we close the terminal) as specified by the -d flag.
We should be welcomed by the same Django landing page when we navigate to localhost:8000 once again, only that this time we will be accessing the application in the Docker container as opposed to the one in our local machine.
With our image ready, we need to publish it to Dockerhub to ease the deployment process on EC2.
Dockerhub is a registry for ready images that enables users to create and share customized Docker images for all purposes. It also allows us to publish our images to be accessed on other platforms such as AWS. In our case, we will publish our image to Dockerhub, then pull it into EC2 for deployment.
To publish our image, we need to create an account on Dockerhub first, and log in to it on our terminal:
$ docker login
Once logged in, we will need to tag our image with our username and then push it to Dockerhub:
$ docker tag django_ec2 <DOCKERHUB_USERNAME>/django_ec2
$ docker push <DOCKERHUB_USERNAME>/django_ec2
With this, we are ready for the next step, which is to deploy our application to Amazon's Elastic Compute Cloud.
Deploying to EC2
With our Docker image ready and published to Dockerhub, we can now log in to our AWS account console and in the EC2 dashboard, we can spin up a new instance - which is achieved through a series of steps.
Choose the AMI
The first step involves selecting an Amazon Machine Image (AMI) that will be used to create our instance. We are presented with options including Red Hat, Ubuntu Server, and Windows Server.
For this demonstration we will need an image that is customized to run containers and ships with Docker. To find it, type ECS in the search bar:

The Amazon ECS-Optimized Amazon Linux 2 is ideal for our scenario and it is the one we will choose.
Choose Instance Type

After choosing the AMI for our instance, we now have to choose an instance type. Our choice here will dictate the number of resources our instance will have in terms of CPU, memory, storage, and network performance capacity.
Since we are on the AWS free tier, we will go ahead and use the t2.micro instance, which is meant for general-purpose instances and comes with 1 virtual CPU and 1 GiB of memory.
The list contains more powerful instance types with others being optimized for compute power, memory, or storage.
Configure Instance

Now that we have chosen the instance type, the next step allows us to specify some more details about our instance, including the number of instances to be launched at any given time, networking options, and file systems, among other details. We will not make any changes to the default options in this step.
Add Storage

The fourth step involves adding and specifying the storage details for our instance. This section allows us to add additional volumes, specify volume size and types, and whether our storage will be encrypted or not.
8GB is the default option and is more than enough for our simple Django application.
Add Tags

AWS allows us to assign labels to our resources through which we can categorize them in terms of purpose, access, or environment. Tags are not mandatory but highly recommended to help identify resources as they increase in number.
Configure Security Group

We defined Security Groups earlier in the post, and in this step of the process, we configure them by either creating a new security group or using an existing one.
We are going to create a new Security Group that will define what traffic will be accepted to our server. The first rule is the SSH rule that will allow SSH traffic into our instance via port 22.
We will modify the source to Anywhere and also add a new rule for Custom TCP and set the source to Anywhere and the port range to 8000. This will allow us to access our Django web application via the port 8000.
Review and Launch

This is the final step where we are presented with the configuration details of our instance for verification. We can also edit the configuration at this point before launching our instance.
If everything is correct, we can finally click on "Launch" to finally start our instance:

Before our instance is launched, we need to create a key pair that will enable us to access our running instance. In order to run our Django application, we need to sign in to the instance and deploy it there.
The private key will be used to authenticate us and give us access to the instance for us to proceed with our deployment. The confirmation of the launch of the instance is then displayed on the next page:

Accessing the EC2 Instance
With the private key downloaded and the instance running, let us now log in and deploy our application.
For this, we need the .pem file downloaded earlier and a terminal window. We will also need a user name for the chosen AMI - for the Amazon Linux AMI, the default username is ec2-user.
The instance's public DNS is also required to connect to it and this can be found on the instance's details section on the EC2 console dashboard.
Let us open a terminal in the folder that contains our private key file. We'll first need to change the key permissions to avoid seeing an "unprotected key file" warning:
$ chmod 400 <PRIVATE_KEY_FILE_NAME>
Then we can use the ssh utility, along with our key file, to connect to the instance:
$ ssh -i <PRIVATE_KEY_FILE_NAME> ec2-user@<PUBLIC_DNS>
__| __| __|
_| ( \__ \ Amazon Linux 2 (ECS Optimized)
____|\___|____/
For documentation, visit http://aws.amazon.com/documentation/ecs
12 package(s) needed for security, out of 25 available
Run "sudo yum update" to apply all updates.
-bash: warning: setlocale: LC_CTYPE: cannot change locale (UTF-8): No such file or directory
[ec2-user@ip-###-##-##-## ~]$
The response above means that we have successfully signed in to our instance, we will start by pulling our application image from Dockerhub and running it using the docker run command:
$ docker run -d -p 8000:8000 <DOCKERHUB_USERNAME>/django_ec2
Once our Docker image is pulled into our instance and successfully running, we can now access our Django application on the web through the same address we used to SSH into it.
When we do, we are welcomed with:

Our Django application is now live on AWS Elastic Compute Cloud!
Conclusion
In this post, we have containerized a Django application using Docker and successfully deployed it to Amazon's EC2 service. We have also learned what EC2 is and what it offers to us as developers and how we can leverage it to make our web applications available for the end-users.
The source code for the script in this project can be found here on GitHub.
↧
Real Python: Exploring HTTPS With Python
Have you ever wondered why it’s okay for you to send your credit card information over the Internet? You may have noticed the https:// on URLs in your browser, but what is it, and how does it keep your information safe? Or perhaps you want to create a Python HTTPS application, but you’re not exactly sure what that means. How can you be sure that your web application is safe?
It may surprise you to know that you don’t have to be an expert in security to answer these questions! In this tutorial, you’ll get a working knowledge of the various factors that combine to keep communications over the Internet safe. You’ll see concrete examples of how a Python HTTPS application keeps information secure.
In this tutorial, you’ll learn how to:
- Monitor and analyze network traffic
- Apply cryptography to keep data safe
- Describe the core concepts of Public Key Infrastructure (PKI)
- Create your own Certificate Authority
- Build a Python HTTPS application
- Identify common Python HTTPS warnings and errors
Free Bonus:Click here to get access to a free Flask + Python video tutorial that shows you how to build Flask web app, step-by-step.
What Is HTTP?
Before you dive into HTTPS and its use in Python, it’s important to understand its parent, HTTP. This acronym stands for HyperText Transfer Protocol, which underpins most of the communications that go on when you’re surfing your favorite websites. More specifically, HTTP is how a user agent, like your web browser, communicates with a web server, like realpython.com. Here’s a simplified diagram of HTTP communications:

This diagram shows a simplified version of how your computer communicates with a server. Here’s the breakdown of each step:
- You tell your browser to go to
http://someserver.com/link. - Your device and the server set up a TCP connection.
- Your browser sends an HTTP request to the server.
- The server receives the HTTP request and parses it.
- The server responds with an HTTP response.
- Your computer receives, parses, and displays the response.
This breakdown captures the basics of HTTP. You make a request to a server, and the server returns a response. While HTTP doesn’t require TCP, it does require a reliable lower-level protocol. In practice, this is almost always TCP over IP (though Google is trying to create a replacement). If you need a refresher, then check out Socket Programming in Python (Guide).
As protocols go, HTTP is one of the simpler ones. It was designed to send content over the Internet, like HTML, videos, images, and so on. This is done with an HTTP request and response. HTTP requests contain the following elements:
- The method describes what action the client wants to perform. The method for static content is typically
GET, though there are others available, likePOST,HEAD, andDELETE. - The path indicates to the server what web page you would like to request. For example, the path of this page is
/python-https. - The version is one of several HTTP versions, like 1.0, 1.1, or 2.0. The most common is probably 1.1.
- The headers help describe additional information for the server.
- The body provides the server with information from the client. Though this field is not required, it’s typical for some methods to have a body, like a
POST.
These are the tools your browser uses to communicate with a server. The server responds with an HTTP response. The HTTP response contains the following elements:
- The version identifies the HTTP version, which will typically be the same as the request’s version.
- The status code indicates whether a request was completed successfully. There are quite a few status codes.
- The status message provides a human-readable message that helps describe the status code.
- The headers allow the server to respond with additional metadata about the request. These are the same concept as request headers.
- The body carries the content. Technically, this is optional, but typically it contains a useful resource.
These are the building blocks for HTTP. If you’re interested in learning more about HTTP, then you can check out an overview page to learn about the protocol in more depth.
What Is HTTPS?
Now that you understand a bit more about HTTP, what is HTTPS? The good news is, you already know this! HTTPS stands for HyperText Transfer Protocol Secure. Fundamentally, HTTPS is the same protocol as HTTP but with the added implication that the communications are secure.
HTTPS doesn’t rewrite any of the HTTP fundamentals on which it’s built. Instead, HTTPS consists of regular HTTP sent over an encrypted connection. Typically, this encrypted connection is provided by either TLS or SSL, which are cryptographic protocols that encrypt the information before it’s sent over a network.
Note: TLS and SSL are extremely similar protocols, though SSL is on its way out, with TLS to take its place. The differences in these protocols are outside the scope of this tutorial. It’s enough to know that TLS is the newer, better version of SSL.
So, why create this separation? Why not just introduce the complexity into the HTTP protocol itself? The answer is portability. Securing communications is an important and hard problem, but HTTP is only one of many protocols that require security. There are countless others across a wide variety of applications:
- Instant Messaging
- VoIP (Voice over IP)
There are others, as well! If each of these protocols had to create their own security mechanism, then the world would be much less secure and much more confusing. TLS, which is often used by the above protocols, provides a common method to secure communications.
Note: This separation of protocols is a common theme in networking, so much so that it has a name. The OSI Model represents communications from physical medium all the way up to the HTML rendered on this page!
Almost all of the information you’ll learn in this tutorial will be applicable to more than just Python HTTPS applications. You’ll be learning the basics of secure communications along with how it applies specifically to HTTPS.
Why Is HTTPS Important?
Secure communications are critical in providing a safe online environment. As more of the world moves online, including banks and healthcare sites, it’s becoming more and more important for developers to create Python HTTPS applications. Again, HTTPS is just HTTP over TLS or SSL. TLS is designed to provide privacy from eavesdroppers. It can also provide authentication of both the client and the server.
In this section, you’ll explore these concepts in depth by doing the following:
- Creating a Python HTTPS server
- Communicating with your Python HTTPS server
- Capturing these communications
- Analyzing those messages
Let’s get started!
Creating an Example Application
Suppose you’re the leader of a cool Python club called the Secret Squirrels. The Squirrels, being secret, require a secret message to attend their meetings. As the leader, you choose the secret message, which changes for each meeting. Sometimes, though, it’s hard for you to meet with all the members before the meeting to tell them the secret message! You decide to set up a secret server where members can just see the secret message for themselves.
Note: The example code used in this tutorial is not designed for production. It’s designed to help you learn the basics of HTTP and TLS. Please do not use this code for production. Many of the examples below have terrible security practices. In this tutorial, you’ll learn about TLS, and one way it can help you be more secure.
You’ve followed some tutorials on Real Python and decide to use some dependencies you know:
To install all of these dependencies, you can use pip:
$ pip install flask uwsgi requests
With your dependencies installed, you begin to write your application. In a file called server.py, you create a Flask application:
# server.pyfromflaskimportFlaskSECRET_MESSAGE="fluffy tail"app=Flask(__name__)@app.route("/")defget_secret_message():returnSECRET_MESSAGEThis Flask application will display the secret message whenever someone visits the / path of your server. With that out of the way, you deploy your application on your secret server and run it:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
This command starts up a server using the Flask application above. You start it on a weird port because you don’t want people to be able to find it, and pat yourself on the back for being so sneaky! You can confirm that it’s working by visiting http://localhost:5683 in your browser.
Since everyone in the Secret Squirrels knows Python, you decide to help them out. You write a script called client.py that will help them get the secret message:
# client.pyimportosimportrequestsdefget_secret_message():url=os.environ["SECRET_URL"]response=requests.get(url)print(f"The secret message is: {response.text}")if__name__=="__main__":get_secret_message()This code will print out the secret message as long as they have the SECRET_URL environment variable set. In this case, the SECRET_URL is 127.0.0.1:5683. So, your plan is to give each club member the secret URL and tell them to keep it secret and safe.
While this might seem okay, rest assured it’s not! In fact, even if you were to put a username and password on this site, it still wouldn’t be safe. But even if your team somehow did manage to keep the URL safe, your secret message still wouldn’t be secure. To demonstrate why you’ll need to know a little bit about monitoring network traffic. To do this, you’ll be using a tool called Wireshark.
Setting Up Wireshark
Wireshark is a widely used tool for network and protocol analysis. What this means is that it can help you see what’s happening over network connections. Installing and setting up Wireshark is optional for this tutorial, but feel free if you’d like to follow along. The download page has several installers available:
- macOS 10.12 and later
- Windows installer 64-bit
- Windows installer 32-bit
If you’re using Windows or Mac, then you should be able to download the appropriate installer and follow the prompts. In the end, you should have a running Wireshark.
If you’re on a Debian-based Linux environment, then the installation is a bit harder, but still possible. You can install Wireshark with the following commands:
$ sudo add-apt-repository ppa:wireshark-dev/stable
$ sudo apt-get update
$ sudo apt-get install wireshark
$ sudo wireshark
You should be met with a screen that looks something like this:
With Wireshark running, it’s time to analyze some traffic!
Seeing That Your Data Is Not Safe
The way your current client and server are running is not secure. HTTP will send everything in the clear for anyone to see. What this means is that even if someone doesn’t have your SECRET_URL, they can still see everything you do as long as they can monitor traffic on any device between you and the server.
This should be relatively scary for you. After all, you don’t want other people showing up for your Secret Squirrel meetings! You can prove that this is happening. First, start up your server if you don’t still have it running:
$ uwsgi --http-socket 127.0.0.1:5683 --mount /=server:app
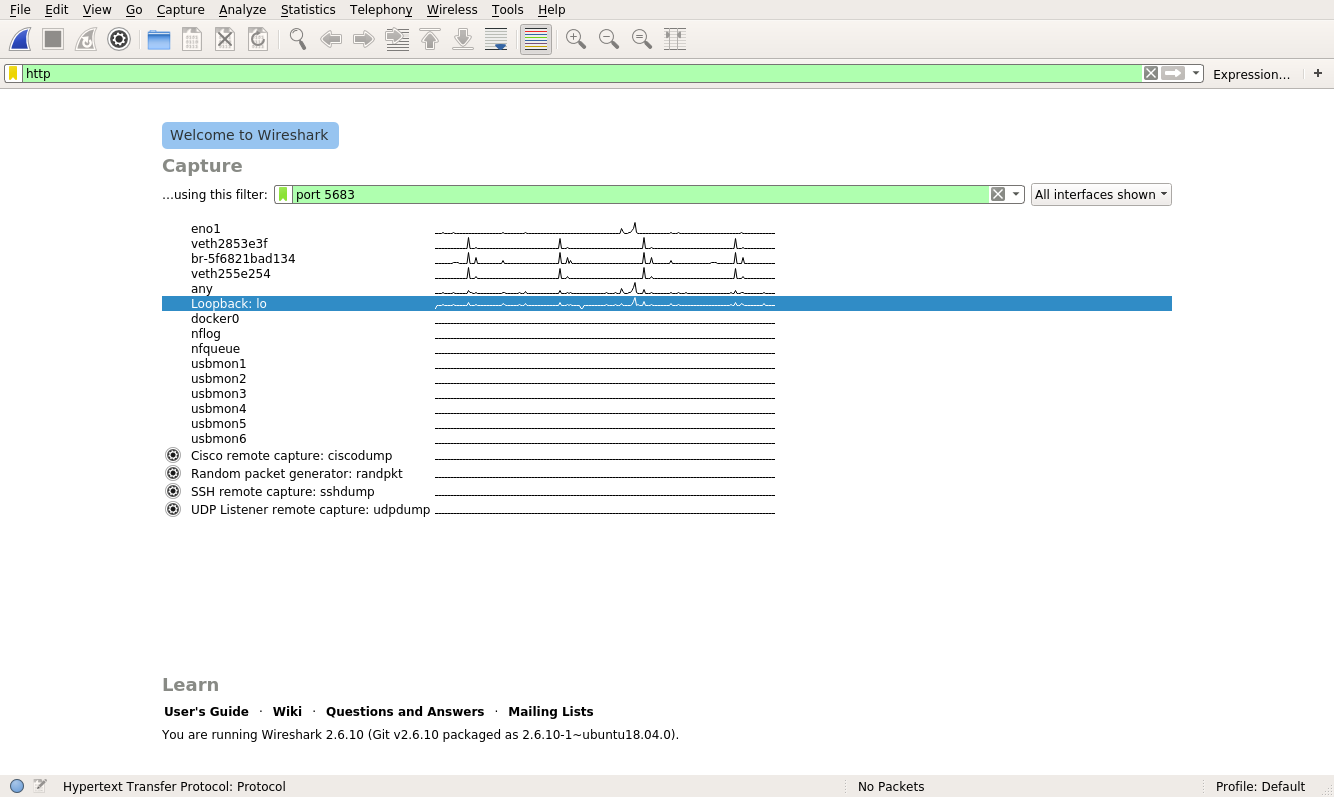
This will start up your Flask application on port 5683. Next, you’ll start a packet capture in Wireshark. This packet capture will help you see all the traffic going to and from the server. Begin by selecting the Loopback:lo interface on Wireshark:

You can see that the Loopback:lo portion is highlighted. This instructs Wireshark to monitor this port for traffic. You can do better and specify which port and protocol you’d like to capture. You can type port 5683 in the capture filter and http in the display filter:
The green box indicates that Wireshark is happy with the filter you typed. Now you can begin the capture by clicking on the fin in the top left:
Clicking this button will spawn a new window in Wireshark:

This new window is fairly plain, but the message at the bottom says <live capture in progress>, which indicates that it’s working. Don’t worry that nothing is being displayed, as that’s normal. In order for Wireshark to report anything, there has to be some activity on your server. To get some data, try running your client:
$SECRET_URL="http://127.0.0.1:5683" python client.py
The secret message is: fluffy tailAfter executing the client.py code from above, you should now see some entries in Wireshark. If all has gone well, then you’ll see two entries that look something like this:

These two entries represent the two parts of the communication that occurred. The first one is the client’s request to your server. When you click on the first entry, you’ll see a plethora of information:
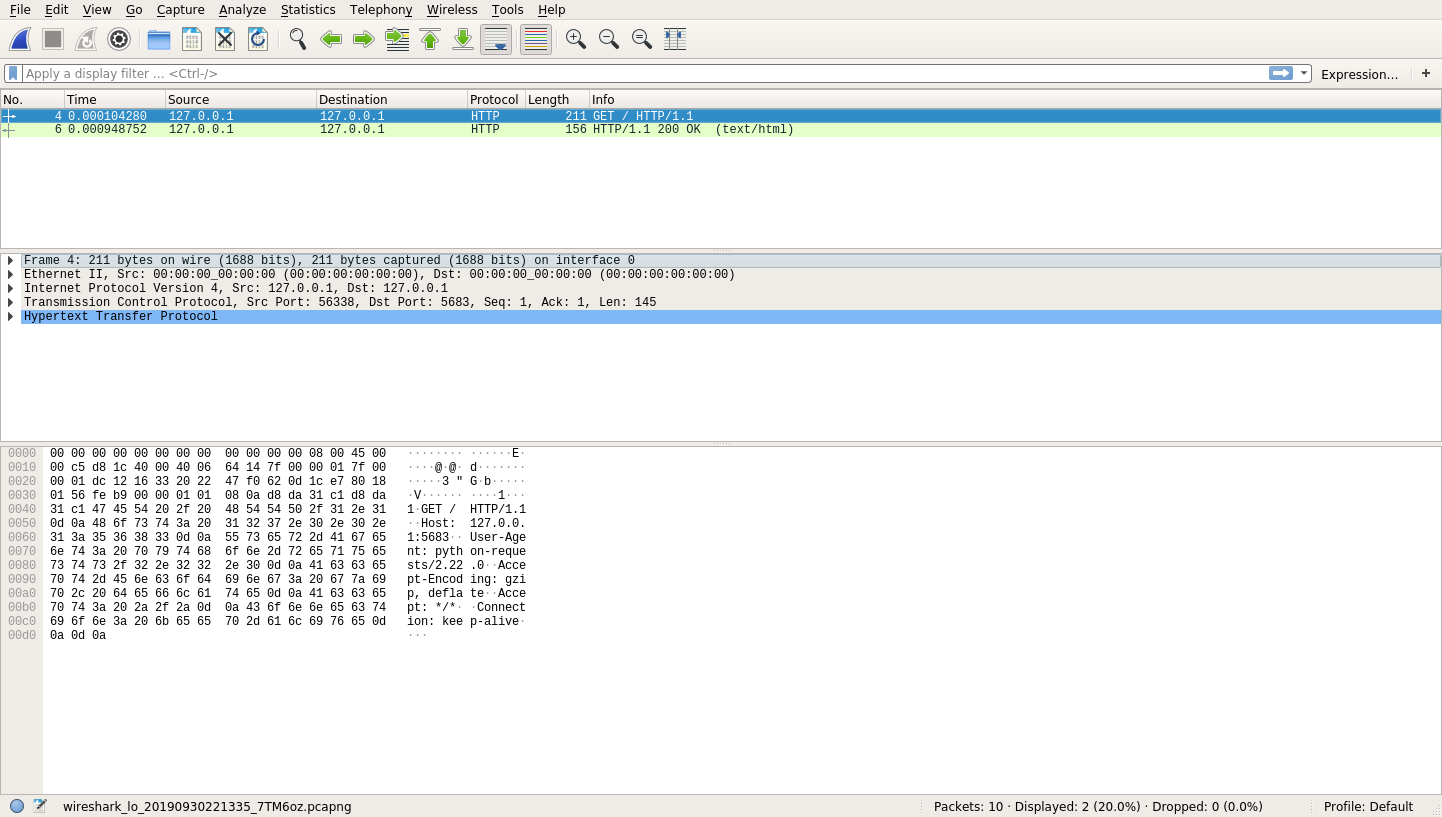
That’s a lot of information! At the top, you still have your HTTP request and response. Once you select one of these entries, you’ll see the middle and bottom row populate with information.
The middle row provides you with a breakdown of the protocols that Wireshark was able to identify for the selected request. This breakdown allows you to explore what actually happened in your HTTP Request. Here’s a quick summary of the information Wireshark describes in the middle row from top to bottom:
- Physical Layer: This row describes the physical interface used to send the request. In your case, this is probably Interface ID 0 (lo) for your loopback interface.
- Ethernet Information: This row shows you the Layer-2 Protocol, which includes source and destination MAC addresses.
- IPv4: This row displays source and destination IP addresses (127.0.0.1).
- TCP: This row includes the required TCP handshake in order to create a reliable pipe of data.
- HTTP: This row displays information about the HTTP request itself.
When you expand the Hypertext Transfer Protocol layer, you can see all the information that makes up an HTTP Request:
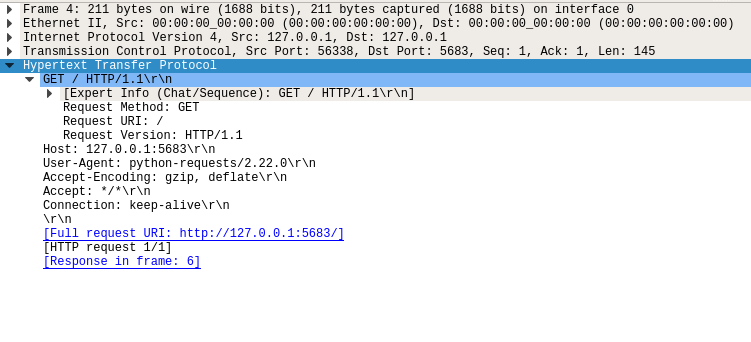
This image shows you your script’s HTTP request:
- Method:
GET - Path:
/ - Version:
1.1 - Headers:
Host: 127.0.0.1:5683,Connection: keep-alive, and others - Body: No body
The last row you’ll see is a hex dump of the data. You may notice in this hex dump that you can actually see the parts of your HTTP request. That’s because your HTTP request was sent in the open. But what about the reply? If you click on the HTTP response, then you’ll see a similar view:
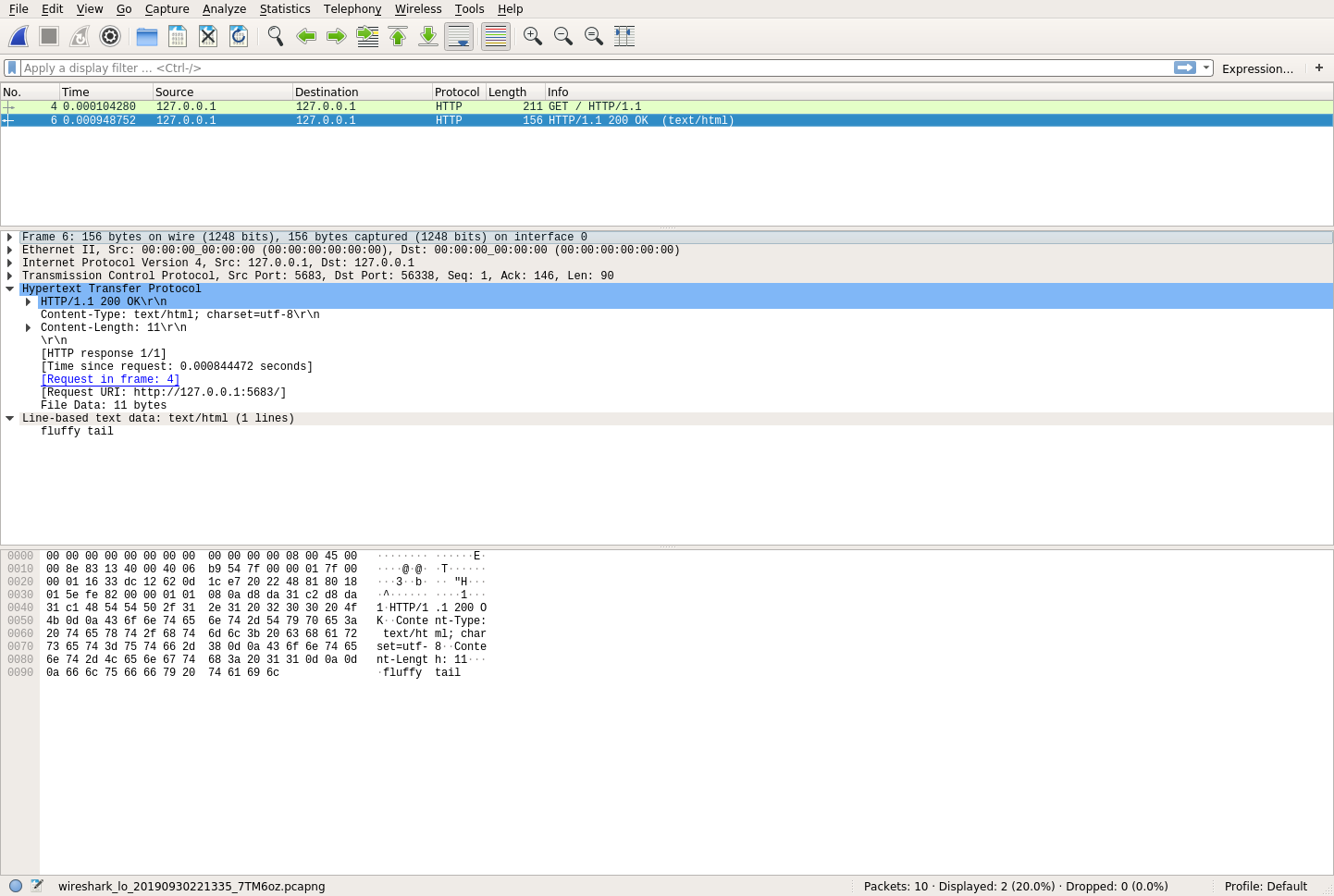
Again, you have the same three sections. If you look carefully at the hex dump, then you’ll see the secret message in plain text! This is a big problem for the Secret Squirrels. What this means is that anyone with some technical know-how can very easily see this traffic if they’re interested. So, how do you solve this problem? The answer is cryptography.
How Does Cryptography Help?
In this section, you’ll learn one way to keep your data safe by creating your own cryptography keys and using them on both your server and your client. While this won’t be your final step, it will help you get a solid foundation for how to build Python HTTPS applications.
Understanding Cryptography Basics
Cryptography is a way to secure communications from eavesdroppers, or adversaries. Another way to state this is that you’re taking normal information, called plaintext, and converting it to scrambled text, called ciphertext.
Cryptography can be intimidating at first, but the fundamental concepts are pretty accessible. In fact, you’ve probably already practiced cryptography before. If you’ve ever had a secret language with your friends and used it to pass notes in class, then you’ve practiced cryptography. (If you haven’t done that, then don’t worry—you’re about to.)
Somehow, you need to take the string"fluffy tail" and convert it into something unintelligible. One way to do this is to map certain characters onto different characters. An effective way to do this is to shift the characters back one spot in the alphabet. Doing so would look something like this:
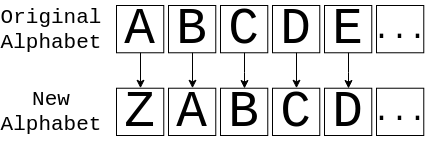
This image shows you how to translate from the original alphabet to the new alphabet and back. So, if you had the message ABC, then you would actually send the message ZAB. If you apply this to "fluffy tail", then assuming that spaces stay the same, you get ekteex szhk. While it’s not perfect, it’ll probably look like gibberish to anyone that sees it.
Congratulations! You’ve created what is known in cryptography as a cipher, which describes how to convert plaintext to ciphertext and back. Your cipher, in this case, is described in English. This particular type of cipher is called a substitution cipher. Fundamentally this is the same type of cipher used in the Enigma Machine, albeit a much simpler version.
Now, if you wanted to get a message out to the Secret Squirrels, then you would first need to tell them how many letters to shift and then give them the encoded message. In Python, this might look something like the following:
CIPHER={"a":"z","A":"Z","b":"a"}# And so ondefencrypt(plaintext:str):return"".join(CIPHER.get(letter,letter)forletterinplaintext)Here, you’ve created a function called encrypt(), which will take plaintext and convert it to ciphertext. Imagine you have a dictionaryCIPHER that has all of the characters mapped out. Similarly, you could create a decrypt():
DECIPHER={v:kfork,vinCIPHER.items()}defdecrypt(ciphertext:str):return"".join(DECIPHER.get(letter,letter)forletterinciphertext)This function is the opposite of encrypt(). It will take ciphertext and convert it to plaintext. In this form of the cipher, you have a special key that users need to know in order to encrypt and decrypt messages. For the above example, that key is 1. That is, the cipher indicates you should shift each letter back by one character. The key is very important to keep secret because anyone with the key can easily decrypt your message.
Note: While you could use this for your encryption, this still isn’t terribly secure. This cipher is quick to break using frequency analysis and is much too primitive for the Secret Squirrels.
In the modern era, cryptography is a lot more advanced. It relies on complex mathematical theory and computer science to be secure. While the math behind these ciphers is outside of the scope of this tutorial, the underlying concepts are still the same. You have a cipher that describes how to take plaintext and convert it into ciphertext.
The only real difference between your substitution cipher and modern ciphers is that modern ciphers are mathematically proven to be impractical to break by an eavesdropper. Now, let’s see how to use your new ciphers.
Using Cryptography in Python HTTPS Applications
Luckily for you, you don’t have to be an expert in mathematics or computer science to use cryptography. Python also has a secrets module that can help you generate cryptographically-secure random data. In this tutorial, you’ll learn about a Python library that’s aptly named cryptography. It’s available on PyPI, so you can install it with pip:
$ pip install cryptography
This will install cryptography into your virtual environment. With cryptography installed, you can now encrypt and decrypt things in a way that’s mathematically secure by using the Fernet method.
Recall that your secret key in your cipher was 1. In the same vein, you need to create a key for Fernet to work correctly:
>>>
>>> fromcryptography.fernetimportFernet>>> key=Fernet.generate_key()>>> keyb'8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM='
In this code, you’ve imported Fernet and generated a key. The key is just a bunch of bytes, but it’s incredibly important that you keep this key secret and safe. Just like the substitution example above, anyone with this key can easily decrypt your messages.
Note: In real life, you would keep this key very secure. In these examples, it’s helpful to see the key, but this is bad practice, especially if you’re posting it on a public website! In other words, do not use the exact key you see above for anything you want to be secure.
This key behaves much like the earlier key. It’s required to make the transition to ciphertext and back to plaintext. Now it’s time for the fun part! You can encrypt a message like this:
>>>
>>> my_cipher=Fernet(key)>>> ciphertext=my_cipher.encrypt(b"fluffy tail")>>> ciphertextb'gAAAAABdlW033LxsrnmA2P0WzaS-wk1UKXA1IdyDpmHcV6yrE7H_ApmSK8KpCW-6jaODFaeTeDRKJMMsa_526koApx1suJ4_dQ=='
In this code, you’ve created a Fernet object called my_cipher, which you can then use to encrypt your message. Notice that your secret message "fluffy tail" needs to be a bytes object in order to encrypt it. After the encryption, you can see that the ciphertext is a long stream of bytes.
Thanks to Fernet, this ciphertext can’t be manipulated or read without the key! This type of encryption requires that both the server and the client have access to the key. When both sides require the same key, this is called symmetric encryption. In the next section, you’ll see how to put this symmetric encryption to use to keep your data safe.
Seeing That Your Data Is Safe
Now that you understand some of the basics of cryptography in Python, you can apply this knowledge to your server. Create a new file called symmetric_server.py:
# symmetric_server.pyimportosfromflaskimportFlaskfromcryptography.fernetimportFernetSECRET_KEY=os.environb[b"SECRET_KEY"]SECRET_MESSAGE=b"fluffy tail"app=Flask(__name__)my_cipher=Fernet(SECRET_KEY)@app.route("/")defget_secret_message():returnmy_cipher.encrypt(SECRET_MESSAGE)This code combines your original server code with the Fernet object you used in the previous section. The key is now read as a bytes object from the environment using os.environb. With the server out of the way, you can now focus on the client. Paste the following into symmetric_client.py:
# symmetric_client.pyimportosimportrequestsfromcryptography.fernetimportFernetSECRET_KEY=os.environb[b"SECRET_KEY"]my_cipher=Fernet(SECRET_KEY)defget_secret_message():response=requests.get("http://127.0.0.1:5683")decrypted_message=my_cipher.decrypt(response.content)print(f"The codeword is: {decrypted_message}")if__name__=="__main__":get_secret_message()Once again, this is modified code to combine your earlier client with the Fernet encryption mechanism. get_secret_message() does the following:
- Make the request to your server.
- Take the raw bytes from the response.
- Attempt to decrypt the raw bytes.
- Print the decrypted message.
If you run both the server and the client, then you’ll see that you’re successfully encrypting and decrypting your secret message:
$ uwsgi --http-socket 127.0.0.1:5683 \
--env SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" --mount /=symmetric_server:appIn this call, you start the server on port 5683 again. This time, you pass in a SECRET_KEY which must be at least a 32-length base64 encoded string. With your server restarted, you may now query it:
$SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'Woohoo! Your were able to encrypt and decrypt your message. If you try running this with an invalid SECRET_KEY, then you’ll get an error:
$SECRET_KEY="AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=" python symmetric_client.py
Traceback (most recent call last): File ".../cryptography/fernet.py", line 104, in _verify_signature h.verify(data[-32:]) File ".../cryptography/hazmat/primitives/hmac.py", line 66, in verify ctx.verify(signature) File ".../cryptography/hazmat/backends/openssl/hmac.py", line 74, in verify raise InvalidSignature("Signature did not match digest.")cryptography.exceptions.InvalidSignature: Signature did not match digest.During handling of the above exception, another exception occurred:Traceback (most recent call last): File "symmetric_client.py", line 16, in <module> get_secret_message() File "symmetric_client.py", line 11, in get_secret_message decrypted_message = my_cipher.decrypt(response.content) File ".../cryptography/fernet.py", line 75, in decrypt return self._decrypt_data(data, timestamp, ttl) File ".../cryptography/fernet.py", line 117, in _decrypt_data self._verify_signature(data) File ".../cryptography/fernet.py", line 106, in _verify_signature raise InvalidTokencryptography.fernet.InvalidTokenSo, you know the encryption and decryption are working. But is it secure? Well, yes, it is. To prove this, you can go back to Wireshark and start a new capture with the same filters as before. After you have the capture setup, run the client code again:
$SECRET_KEY="8jtTR9QcD-k3RO9Pcd5ePgmTu_itJQt9WKQPzqjrcoM=" python symmetric_client.py
The secret message is: b'fluffy tail'You’ve made another successful HTTP request and response, and once again, you see these messages in Wireshark. Since the secret message only gets transferred in the response, you can click on that to look at the data:
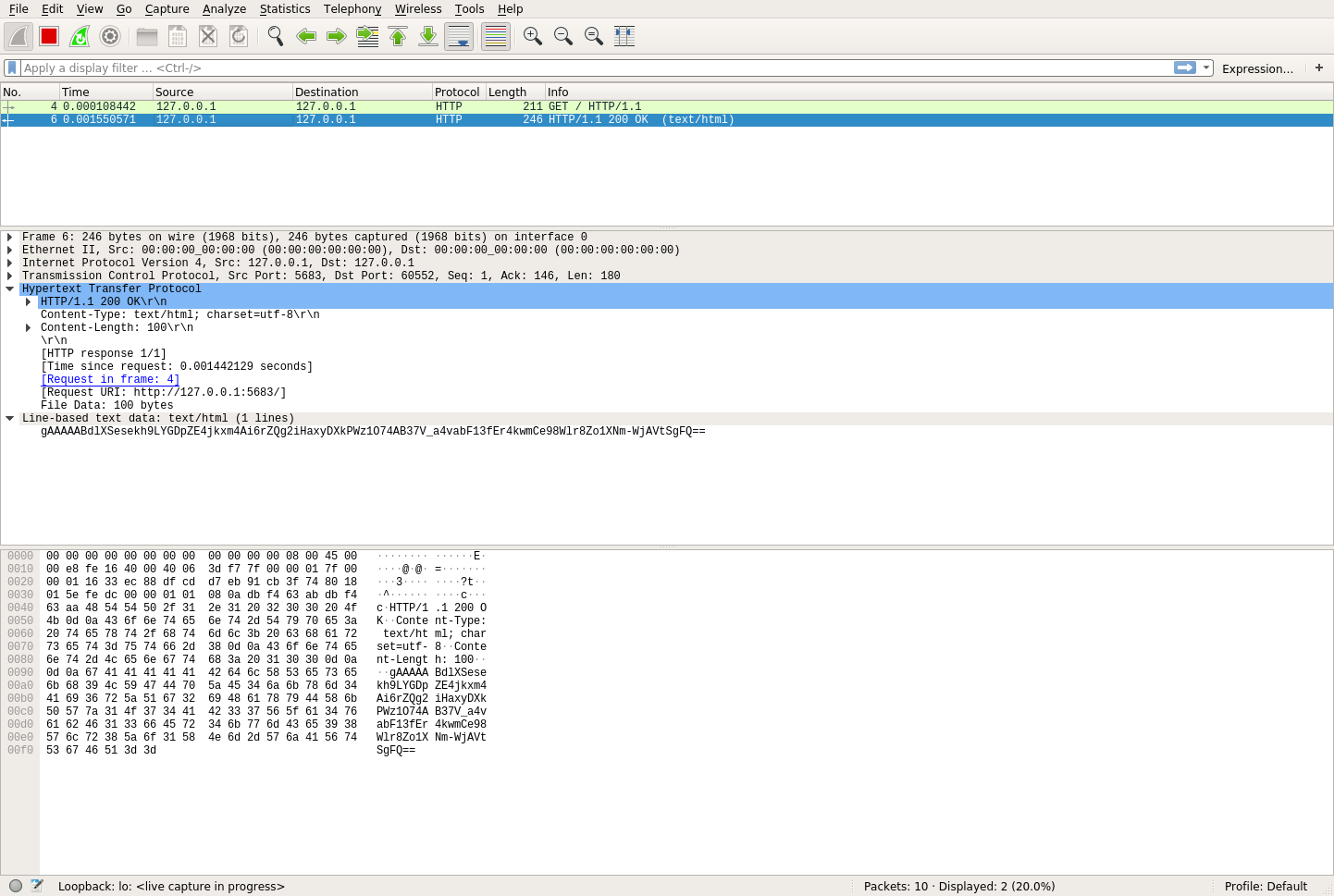
In the middle row of this picture, you can see the data that was actually transferred:
gAAAAABdlXSesekh9LYGDpZE4jkxm4Ai6rZQg2iHaxyDXkPWz1O74AB37V_a4vabF13fEr4kwmCe98Wlr8Zo1XNm-WjAVtSgFQ==Awesome! This means that the data was encrypted and that eavesdroppers have no clue what the message content actually is. Not only that, but it also means that they could spend an insanely long amount of time trying to brute-force crack this data, and they would almost never be successful.
Your data is safe! But wait a minute—you never had to know anything about a key when you were using Python HTTPS applications before. That’s because HTTPS doesn’t use symmetric encryption exclusively. As it turns out, sharing secrets is a hard problem.
To prove this concept, navigate to http://127.0.0.1:5683 in your browser, and you’ll see the encrypted response text. This is because your browser doesn’t know anything about your secret cipher key. So how do Python HTTPS applications really work? That’s where asymmetric encryption comes into play.
How Are Keys Shared?
In the previous section, you saw how you could use symmetric encryption to keep your data secure as it traverses the Internet. Still, even though symmetric encryption is secure, it isn’t the only encryption technique used by Python HTTPS applications to keep your data safe. Symmetric encryption introduces some fundamental problems that are not so easily solved.
Note: Remember, symmetric encryption requires that you have a shared key between client and server. Unfortunately, security only works as hard as your weakest link, and weak links are especially catastrophic in symmetric encryption. Once one person compromises the key, then every key is compromised. It’s safe to assume that any security system will, at some point, become compromised.
So, how do you change your key? If you only have one server and one client, then this might be a quick task. However, as you get more clients and more servers, there is more and more coordination that needs to happen in order to change the key and keep your secrets safe effectively.
Moreover, you have to choose a new secret every time. In the above example, you saw a randomly generated key. It can be next to impossible for you to try and get people to remember that key. As your client and server numbers grow, you’ll likely use keys that are easier to remember and guess.
If you can deal with changing your key, then you still have one more problem to solve. How do you share your initial key? In the Secret Squirrels example, you solved this problem by having physical access to each of the members. You could give each member the secret in person and tell them to keep it secret, but remember that someone will be the weakest link.
Now, suppose you add a member to the Secret Squirrels from another physical location. How do you share the secret with this member? Do you make them take a plane to you each time the key changes? It would be nice if you could put up the secret key on your server and share it automatically. Unfortunately, this would defeat the whole purpose of encryption, since anyone could get the secret key!
Of course, you could give everyone an initial master key to get the secret message, but now you just have twice as many problems as before. If your head hurts, then don’t worry! You’re not the only one.
What you need is for two parties that have never communicated to have a shared secret. Sounds impossible, right? Luckily, three guys by the names of Ralph Merkle, Whitfield Diffie, and Martin Hellman have your back. They helped demonstrate that public-key cryptography, otherwise known as asymmetric encryption, was possible.
Note: While Whitfield Diffie and Martin Hellman are widely known as the first to discover the scheme, it was revealed in 1997 that three men working for GCHQ named James H. Ellis, Clifford Cocks, and Malcolm J. Williamson had previously demonstrated this capability seven years earlier!
Asymmetric encryption allows for two users who have never communicated before to share a common secret. One of the easiest ways to understand the fundamentals is to use a color analogy. Imagine you have the following scenario:

In this diagram, you’re trying to communicate with a Secret Squirrel you’ve never met before, but a spy can see everything you send. You know about symmetric encryption and would like to use it, but you first need to share a secret. Luckily, both of you have a private key. Unfortunately, you can’t send your private key because the spy will see it. So what do you do?
The first thing you need to do is agree with your partner on a color, like yellow:

Notice here that the spy can see the shared color, as can you and the Secret Squirrel. The shared color is effectively public. Now, both you and the Secret Squirrel combine your private keys with the shared color:

Your colors combine to make green, while the Secret Squirrel’s colors combine to make orange. Both of you are done with the shared color, and now you need to share your combined colors with one another:

You now have your private key and the Secret Squirrel’s combined color. Likewise, the Secret Squirrel has their private key and your combined color. It was pretty quick for you and the Secret Squirrel to combine your colors.
The spy, however, only has these combined colors. Trying to figure out your exact original color is very hard, even given the initial shared color. The spy would have to go to the store and buy lots of different blues to try. Even then, it would be hard to know if they were looking at the right shade of green after the combination! In short, your private key is still private.
But what about you and the Secret Squirrel? You still don’t have a combined secret! This is where your private key comes back. If you combine your private key with the combined color you received from the Secret Squirrel, then you’ll both end up with the same color:

Now, you and the Secret Squirrel have the same shared secret color. You have now successfully shared a secure secret with a complete stranger. This is surprisingly accurate to how public-key cryptography works. Another common name for this sequence of events is the Diffie-Hellman key exchange. The key exchange is made up of the following parts:
- The private key is your private color from the examples.
- The public key is the combined color that you shared.
The private key is something you always keep private, while the public key can be shared with anyone. These concepts map directly to the real world of Python HTTPS applications. Now that the server and the client have a shared secret, you can use your old pal symmetric encryption to encrypt all further messages!
Note: Public-key cryptography also relies on some math to do color mixing. The Wikipedia page for the Diffie-Hellman key exchange has a good explanation, but an in-depth explanation is outside the scope of this tutorial.
When you’re communicating over a secure website, like this one, your browser and the server set up a secure communication using these same principles:
- Your browser requests information from the server.
- Your browser and the server exchange public keys.
- Your browser and the server generate a shared private key.
- Your browser and the server encrypt and decrypt messages using this shared key through symmetric encryption.
Luckily for you, you don’t need to implement any of these details. There are lots of built-in and third-party libraries that can help you keep your client and server communications secure.
What Is HTTPS Like in the Real World?
Given all this information about encryption, let’s zoom out a bit and talk about how Python HTTPS applications actually work in the real world. Encryption is only half of the story. When visiting a secure website, there are two major components needed:
- Encryption converts plaintext to ciphertext and back.
- Authentication verifies that a person or thing is who they say they are.
You’ve heard extensively about how encryption works, but what about authentication? To understand authentication in the real world, you’ll need to know about Public Key Infrastructure. PKI introduces another important concept into the security ecosystem, called certificates.
Certificates are like passports for the Internet. Like most things in the computer world, they are just chunks of data in a file. Generally speaking, certificates include the following information:
- Issued To: identifies who owns the certificate
- Issued By: identifies who issued the certificate
- Validity Period: identifies the time frame for which the certificate is valid
Just like passports, certificates are only really useful if they’re generated and recognized by some authority. It’s impractical for your browser to know about every single certificate of every site you visit on the Internet. Instead, PKI relies on a concept known as Certificate Authorities (CA).
Certificate Authorities are responsible for issuing certificates. They are considered a trusted third party (TTP) in PKI. Essentially, these entities act as valid authorities for a certificate. Suppose you’d like to visit another country, and you have a passport with all your information on it. How do the immigration officers in the foreign country know that your passport contains valid information?
If you were to fill out all the information yourself and sign it, then each immigration officer in each country you want to visit would need to know you personally and be able to attest that the information there was indeed correct.
Another way to handle this is to send all your information into a Trusted Third Party (TTP). The TTP would do a thorough investigation of the information you provided, verify your claims, and then sign your passport. This turns out to be much more practical because the immigration officers only need to know the trusted third parties.
The TTP scenario is how certificates are handled in practice. The process goes something like this:
- Create a Certificate Signing Request (CSR): This is like filling out the information for your visa.
- Send the CSR to a Trusted Third Party (TTP): This is like sending your information into a visa application office.
- Verify your information: Somehow, the TTP needs to verify the information you provided. As an example, see how Amazon validates ownership.
- Generate a Public Key: The TTP signs your CSR. This is equivalent to the TTP signing your visa.
- Issue the verified Public Key: This is equivalent to you receiving your visa in the mail.
Note that the CSR is tied cryptographically to your private key. As such, all three pieces of information—public key, private key, and certificate authority—are related in one way or another. This creates what is known as a chain of trust, so you now have a valid certificate that can be used to verify your identity.
Most often, this is only the responsibility of website owners. A website owner will follow all these steps. At the end of this process, their certificate says the following:
From time
Ato timeBI amXaccording toY
This sentence is all that a certificate really tells you. The variables can be filled in as follows:
- A is the valid start date and time.
- B is the valid end date and time.
- X is the name of the server.
- Y is the name of the Certificate Authority.
Fundamentally, this is all a certificate describes. In other words, having a certificate doesn’t necessarily mean that you are who you say you are, just that you got Y to agree that you are who you say you are. This is where the “trusted” part of trusted third parties come in.
TTPs need to be shared between clients and servers in order for everyone to be happy about the HTTPS handshake. Your browser comes with lots of Certificate Authorities automatically installed. To see them, take the following steps:
- Chrome: Go to Settings > Advanced > Privacy and security > Manage certificates > Authorities.
- Firefox: Go to Settings > Preferences > Privacy & Security > View Certificates > Authorities.
This covers the infrastructure required to create Python HTTPS applications in the real world. In the next section, you’ll apply these concepts to your own code. You’ll walk through the most common examples and become your own Certificate Authority for the Secret Squirrels!
What Does a Python HTTPS Application Look Like?
Now that you have an understanding of the basic parts required for a making a Python HTTPS application, it’s time to tie all the pieces together one-by-one to your application from before. This will ensure that your communication between server and client is secure.
It’s possible to set up the entire PKI infrastructure on your own machine, and this is exactly what you’ll be doing in this section. It’s not as hard as it sounds, so don’t worry! Becoming a real Certificate Authority is significantly harder than taking the steps below, but what you’ll read is, more or less, all you’d need to run your own CA.
Becoming a Certificate Authority
A Certificate Authority is nothing more than a very important public and private key pair. To become a CA, you just need to generate a public and private key pair.
Note: Becoming a CA that’s meant for use by the public is a very arduous process, though there are many companies that have followed this process. You won’t be one of those companies by the end of this tutorial, however!
Your initial public and private key pair will be a self-signed certificate. You’re generating the initial secret, so if you’re actually going to become a CA, then it’s incredibly important that this private key is safe. If someone gets access to the CA’s public and private key pair, then they can generate a completely valid certificate, and there’s nothing you can do to detect the problem except to stop trusting your CA.
With that warning out of the way, you can generate the certificate in no time. For starters, you’ll need to generate a private key. Paste the following into a file called pki_helpers.py:
1 # pki_helpers.py 2 fromcryptography.hazmat.backendsimportdefault_backend 3 fromcryptography.hazmat.primitivesimportserialization 4 fromcryptography.hazmat.primitives.asymmetricimportrsa 5 6 defgenerate_private_key(filename:str,passphrase:str): 7 private_key=rsa.generate_private_key( 8 public_exponent=65537,key_size=2048,backend=default_backend() 9 )10 11 utf8_pass=passphrase.encode("utf-8")12 algorithm=serialization.BestAvailableEncryption(utf8_pass)13 14 withopen(filename,"wb")askeyfile:15 keyfile.write(16 private_key.private_bytes(17 encoding=serialization.Encoding.PEM,18 format=serialization.PrivateFormat.TraditionalOpenSSL,19 encryption_algorithm=algorithm,20 )21 )22 23 returnprivate_keygenerate_private_key() generates a private key using RSA. Here’s a breakdown of the code:
- Lines 2 to 4 import the libraries required for the function to work.
- Lines 7 to 9 use RSA to generate a private key. The magic numbers
65537and2048are just two possible values. You can read more about why or just trust that these numbers are useful. - Lines 11 to 12 set up the encryption algorithm to be used on your private key.
- Lines 14 to 21 write your private key to disk at the specified
filename. This file is encrypted using the password provided.
The next step in becoming your own CA is to generate a self-signed public key. You can bypass the certificate signing request (CSR) and immediately build a public key. Paste the following into pki_helpers.py:
1 # pki_helpers.py 2 fromdatetimeimportdatetime,timedelta 3 fromcryptographyimportx509 4 fromcryptography.x509.oidimportNameOID 5 fromcryptography.hazmat.primitivesimporthashes 6 7 defgenerate_public_key(private_key,filename,**kwargs): 8 subject=x509.Name( 9 [10 x509.NameAttribute(NameOID.COUNTRY_NAME,kwargs["country"]),11 x509.NameAttribute(12 NameOID.STATE_OR_PROVINCE_NAME,kwargs["state"]13 ),14 x509.NameAttribute(NameOID.LOCALITY_NAME,kwargs["locality"]),15 x509.NameAttribute(NameOID.ORGANIZATION_NAME,kwargs["org"]),16 x509.NameAttribute(NameOID.COMMON_NAME,kwargs["hostname"]),17 ]18 )19 20 # Because this is self signed, the issuer is always the subject21 issuer=subject22 23 # This certificate is valid from now until 30 days24 valid_from=datetime.utcnow()25 valid_to=valid_from+timedelta(days=30)26 27 # Used to build the certificate28 builder=(29 x509.CertificateBuilder()30 .subject_name(subject)31 .issuer_name(issuer)32 .public_key(private_key.public_key())33 .serial_number(x509.random_serial_number())34 .not_valid_before(valid_from)35 .not_valid_after(valid_to)36 )37 38 # Sign the certificate with the private key39 public_key=builder.sign(40 private_key,hashes.SHA256(),default_backend()41 )42 43 withopen(filename,"wb")ascertfile:44 certfile.write(public_key.public_bytes(serialization.Encoding.PEM))45 46 returnpublic_keyHere you have a new function generate_public_key() that will generate a self-signed public key. Here’s how this code works:
- Lines 2 to 5 are imports required for the function to work.
- Lines 8 to 18 build up information about the subject of the certificate.
- Line 21 uses the same issuer and subject since this is a self-signed certificate.
- Lines 24 to 25 indicate the time range during which this public key is valid. In this case, it’s 30 days.
- Lines 28 to 36 add all required information to a public key builder object, which then needs to be signed.
- Lines 38 to 41 sign the public key with the private key.
- Lines 43 to 44 write the public key out to
filename.
Using these two functions, you can generate your private and public key pair quite quickly in Python:
>>>
>>> frompki_helpersimportgenerate_private_key,generate_public_key>>> private_key=generate_private_key("ca-private-key.pem","secret_password")>>> private_key<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7ffbb292bf90>>>> generate_public_key(... private_key,... filename="ca-public-key.pem",... country="US",... state="Maryland",... locality="Baltimore",... org="My CA Company",... hostname="my-ca.com",... )<Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>
After importing your helper functions from pki_helpers, you first generate your private key and save it to the file ca-private-key.pem. You then pass that private key into generate_public_key() to generate your public key. In your directory you should now have two files:
$ ls ca*
ca-private-key.pem ca-public-key.pemCongratulations! You now have the ability to be a Certificate Authority.
Trusting Your Server
The first step to your server becoming trusted is for you to generate a Certificate Signing Request (CSR). In the real world, the CSR would be sent to an actual Certificate Authority like Verisign or Let’s Encrypt. In this example, you’ll use the CA you just created.
Paste the code for generating a CSR into the pki_helpers.py file from above:
1 # pki_helpers.py 2 defgenerate_csr(private_key,filename,**kwargs): 3 subject=x509.Name( 4 [ 5 x509.NameAttribute(NameOID.COUNTRY_NAME,kwargs["country"]), 6 x509.NameAttribute( 7 NameOID.STATE_OR_PROVINCE_NAME,kwargs["state"] 8 ), 9 x509.NameAttribute(NameOID.LOCALITY_NAME,kwargs["locality"]),10 x509.NameAttribute(NameOID.ORGANIZATION_NAME,kwargs["org"]),11 x509.NameAttribute(NameOID.COMMON_NAME,kwargs["hostname"]),12 ]13 )14 15 # Generate any alternative dns names16 alt_names=[]17 fornameinkwargs.get("alt_names",[]):18 alt_names.append(x509.DNSName(name))19 san=x509.SubjectAlternativeName(alt_names)20 21 builder=(22 x509.CertificateSigningRequestBuilder()23 .subject_name(subject)24 .add_extension(san,critical=False)25 )26 27 csr=builder.sign(private_key,hashes.SHA256(),default_backend())28 29 withopen(filename,"wb")ascsrfile:30 csrfile.write(csr.public_bytes(serialization.Encoding.PEM))31 32 returncsrFor the most part this code is identical to how you generated your original public key. The main differences are outlined below:
- Lines 16 to 19 set up alternate DNS names, which will be valid for your certificate.
- Lines 21 to 25 generate a different builder object, but the same fundamental principle applies as before. You’re building all the required attributes for your CSR.
- Line 27 signs your CSR with a private key.
- Lines 29 to 30 write your CSR to disk in PEM format.
You’ll notice that, in order to create a CSR, you’ll need a private key first. Luckily, you can use the same generate_private_key() from when you created your CA’s private key. Using the above function and the previous methods defined, you can do the following:
>>>
>>> frompki_helpersimportgenerate_csr,generate_private_key>>> server_private_key=generate_private_key(... "server-private-key.pem","serverpassword"... )>>> server_private_key<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f6adafa3050>>>> generate_csr(... server_private_key,... filename="server-csr.pem",... country="US",... state="Maryland",... locality="Baltimore",... org="My Company",... alt_names=["localhost"],... hostname="my-site.com",... )<cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f6ad5372210>
After you run these steps in a console, you should end up with two new files:
server-private-key.pem: your server’s private keyserver-csr.pem: your server’s CSR
You can view your new CSR and private key from the console:
$ ls server*.pem
server-csr.pem server-private-key.pemWith these two documents in hand, you can now begin the process of signing your keys. Typically, lots of verification would happen in this step. In the real world, the CA would make sure that you owned my-site.com and ask you to prove it in various ways.
Since you are the CA in this case, you can forego that headache create your very own verified public key. To do that, you’ll add another function to your pki_helpers.py file:
# pki_helpers.pydefsign_csr(csr,ca_public_key,ca_private_key,new_filename):valid_from=datetime.utcnow()valid_until=valid_from+timedelta(days=30)builder=(x509.CertificateBuilder().subject_name(csr.subject).issuer_name(ca_public_key.subject).public_key(csr.public_key()).serial_number(x509.random_serial_number()).not_valid_before(valid_from).not_valid_after(valid_until))forextensionincsr.extensions:builder=builder.add_extension(extension.value,extension.critical)public_key=builder.sign(private_key=ca_private_key,algorithm=hashes.SHA256(),backend=default_backend(),)withopen(new_filename,"wb")askeyfile:keyfile.write(public_key.public_bytes(serialization.Encoding.PEM))This code looks very similar to generate_public_key() from the generate_ca.py file. In fact, they’re nearly identical. The major differences are as follows:
- Lines 8 to 9 base the subject name on the CSR, while the issuer is based on the Certificate Authority.
- Line 10 gets the public key from the CSR this time.
- Lines 16 to 17 copy any extensions that were set on the CSR.
- Line 20 signs the public key with the CA’s private key.
The next step is to fire up the Python console and use sign_csr(). You’ll need to load your CSR and your CA’s private and public key. Begin by loading your CSR:
>>>
>>> fromcryptographyimportx509>>> fromcryptography.hazmat.backendsimportdefault_backend>>> csr_file=open("server-csr.pem","rb")>>> csr=x509.load_pem_x509_csr(csr_file.read(),default_backend())>>> csr<cryptography.hazmat.backends.openssl.x509._CertificateSigningRequest object at 0x7f68ae289150>
In this section of code, you’re opening up your server-csr.pem file and using x509.load_pem_x509_csr() to create your csr object. Next up, you’ll need to load your CA’s public key:
>>>
>>> ca_public_key_file=open("ca-public-key.pem","rb")>>> ca_public_key=x509.load_pem_x509_certificate(... ca_public_key_file.read(),default_backend()... )>>> ca_public_key<Certificate(subject=<Name(C=US,ST=Maryland,L=Baltimore,O=My CA Company,CN=logan-ca.com)>, ...)>
Once again, you’ve created a ca_public_key object which can be used by sign_csr(). The x509 module had the handy load_pem_x509_certificate() to help. The final step is to load your CA’s private key:
>>>
>>> fromgetpassimportgetpass>>> fromcryptography.hazmat.primitivesimportserialization>>> ca_private_key_file=open("ca-private-key.pem","rb")>>> ca_private_key=serialization.load_pem_private_key(... ca_private_key_file.read(),... getpass().encode("utf-8"),... default_backend(),... )Password:>>> private_key<cryptography.hazmat.backends.openssl.rsa._RSAPrivateKey object at 0x7f68a85ade50>
This code will load up your private key. Recall from earlier that your private key was encrypted using the password you specified. With these three components, you can now sign your CSR and generate a verified public key:
>>>
>>> frompki_helpersimportsign_csr>>> sign_csr(csr,ca_public_key,ca_private_key,"server-public-key.pem")
After running this, you should have three server key files in your directory:
$ ls server*.pem
server-csr.pem server-private-key.pem server-public-key.pemWhew! That was quite a lot of work. The good news is that now that you have your private and public key pair, you don’t have to change any server code to start using it.
Using your original server.py file, run the following command to start your brand new Python HTTPS application:
$ uwsgi \
--master \
--https localhost:5683,\
logan-site.com-public-key.pem,\
logan-site.com-private-key.pem \
--mount /=server:app
Congratulations! You now have a Python HTTPS-enabled server running with your very own private-public key pair, which was signed by your very own Certificate Authority!
Note: There is another side to the Python HTTPS authentication equation, and that’s the client. It’s possible to set up certificate verification for a client certificate as well. This requires a bit more work and isn’t really seen outside of enterprises. However, client authentication can be a very powerful tool.
Now, all that’s left to do is query your server. First, you’ll need to make some changes to the client.py code:
# client.pyimportosimportrequestsdefget_secret_message():response=requests.get("https://localhost:5683")print(f"The secret message is {response.text}")if__name__=="__main__":get_secret_message()The only change from the previous code is from http to https. If you try to run this code, then you’ll be met with an error:
$ python client.py
...requests.exceptions.SSLError: \ HTTPSConnectionPool(host='localhost', port=5683): \ Max retries exceeded with url: / (Caused by \ SSLError(SSLCertVerificationError(1, \ '[SSL: CERTIFICATE_VERIFY_FAILED] \ certificate verify failed: unable to get local issuer \ certificate (_ssl.c:1076)')))That’s quite the nasty error message! The important part here is the message certificate verify failed: unable to get local issuer. These words should be more familiar to you now. Essentially, it’s saying the following:
localhost:5683 gave me a certificate. I checked the issuer of the certificate it gave me, and according to all the Certificate Authorities I know about, that issuer is not one of them.
If you attempt to navigate to your website with your browser, then you’ll get a similar message:
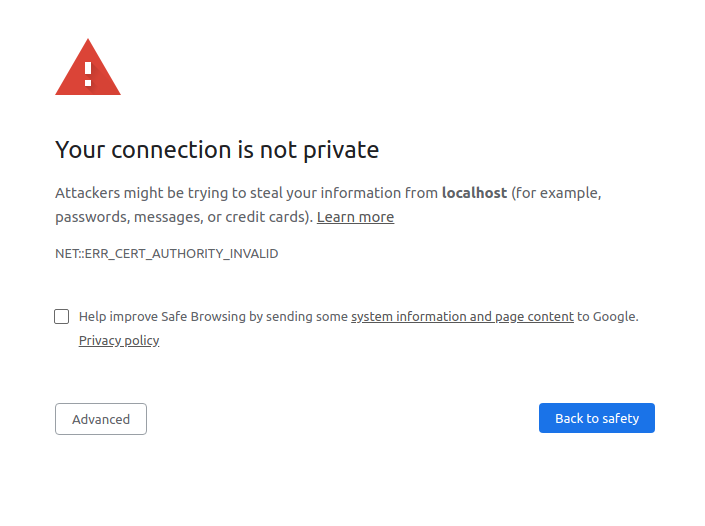
If you want to avoid this message, then you have to tell requests about your Certificate Authority! All you need to do is point requests at the ca-public-key.pem file that you generated earlier:
# client.pydefget_secret_message():response=requests.get("http://localhost:5683",verify="ca-public-key.pem")print(f"The secret message is {response.text}")After doing that, you should be able to run the following successfully:
$ python client.py
The secret message is fluffy tailNice! You’ve made a fully-functioning Python HTTPS server and queried it successfully. You and the Secret Squirrels now have messages that you can trade back and forth happily and securely!
Conclusion
In this tutorial, you’ve learned some of the core underpinnings of secure communications on the Internet today. Now that you understand these building blocks, you’ll become a better and more secure developer.
Throughout this tutorial, you’ve gained an understanding of several topics:
- Cryptography
- HTTPS and TLS
- Public Key Infrastructure
- Certificates
If this information has you interested, then you’re in luck! You’ve barely scratched the surface of all the nuances involved in every layer. The security world is constantly evolving, and new techniques and vulnerabilities are always being discovered. If you still have questions, then feel free to reach out in the comments section below or on Twitter.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
↧
Matt Layman: From Browser To Django
Maybe you have heard about Django and that it can help you build websites. You might be new to Python, new to web development, or new to programming as a whole.
This new series, Understand Django, will show you what Django is all about. Throughout this series, I hope to reveal how Django is a powerful tool that can unlock the potential of anyone interested in making applications on the internet.
↧
Python Software Foundation: Python 2 series to be retired by April 2020
The CPython core development community is urging users to migrate to Python 3 as it will be the only version that will be updated for bugs and security vulnerabilities.
After nearly 20 years of development on the Python 2 series, the last major version 2.7 will be released in April 2020, and then all development will cease for Python 2. Users are urged to migrate to Python 3 to benefit from its many improvements, as well as to avoid potential security vulnerabilities in Python 2.x after April 2020. This move will free limited resources for the CPthyon core developer community for other important work.
The final Python 2.7 maintenance release was originally planned for 2015. However, it was delayed 5 years to give people adequate time to migrate and to work closely with vendors and redistributors to ensure that supported Python 3 migration options were available. Part of the reason for this delay was because the stricter text model in Python 3 was forcing the resolution of non-trivial Unicode handling issues in the reference interpreter and standard library, and in migrated libraries and applications
Python 3 is a noticeable improvement to Python. There is ground-up support for Unicode and internationalization. It better expresses common idioms and patterns, which in code makes it easier to read and reason about. Improvements in concurrency, fault handling, testing, and debugging provide developers with the opportunity to create more robust and secure applications.
Going forward, Python 3 will be the only major version of CPython that is actively maintained for bugs and security issues.
More information:
After Python 2.7.17 (October 19, 2019) was released, some additional changes accumulated before the end of 2019 when the core development team froze the 2.7 branch. As a final service to the community, python-dev will bundle those fixes -- and only those fixes -- into a final 2.7.18 release. The release date for 2.7.18 will be in April 2020 because that allows time for the release managers to complete a release candidate and final release.
![]()
![]()
![]()
![]()
![]()
After nearly 20 years of development on the Python 2 series, the last major version 2.7 will be released in April 2020, and then all development will cease for Python 2. Users are urged to migrate to Python 3 to benefit from its many improvements, as well as to avoid potential security vulnerabilities in Python 2.x after April 2020. This move will free limited resources for the CPthyon core developer community for other important work.
The final Python 2.7 maintenance release was originally planned for 2015. However, it was delayed 5 years to give people adequate time to migrate and to work closely with vendors and redistributors to ensure that supported Python 3 migration options were available. Part of the reason for this delay was because the stricter text model in Python 3 was forcing the resolution of non-trivial Unicode handling issues in the reference interpreter and standard library, and in migrated libraries and applications
Python 3 is a noticeable improvement to Python. There is ground-up support for Unicode and internationalization. It better expresses common idioms and patterns, which in code makes it easier to read and reason about. Improvements in concurrency, fault handling, testing, and debugging provide developers with the opportunity to create more robust and secure applications.
Going forward, Python 3 will be the only major version of CPython that is actively maintained for bugs and security issues.
More information:
- Press release: https://www.python.org/psf/press-release/pr20191220/
- Simple FAQ: https://www.python.org/doc/sunset-python-2/
- Comprehensive FAQ: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html
- Developer porting guide: https://portingguide.readthedocs.io
Clarification Update January 8, 2020
Effective January 1, 2020, no new bug reports, fixes, or changes will be made to Python 2.After Python 2.7.17 (October 19, 2019) was released, some additional changes accumulated before the end of 2019 when the core development team froze the 2.7 branch. As a final service to the community, python-dev will bundle those fixes -- and only those fixes -- into a final 2.7.18 release. The release date for 2.7.18 will be in April 2020 because that allows time for the release managers to complete a release candidate and final release.
↧
↧
Mike Driscoll: Letting Users Change a wx.ComboBox’s Contents in wxPython
This week I came across someone who was wondering if there was a way to allow the user to edit the contents of a wx.ComboBox. By editing the contents, I mean change the names of the pre-existing choices that the ComboBox contains, not adding new items to the widget.
While editing the contents of the selected item in a ComboBox works out of the box, the widget will not save those edits automatically. So if you edit something and then choose a different option in the ComboBox, the edited item will revert back to whatever it was previously and your changes will be lost.
Let’s find out how you can create a ComboBox that allows this functionality!
 | Creating GUI Applications with wxPython |
Changing a ComboBox

The first step when trying something new out is to write some code. You’ll need to create an instance of wx.ComboBox and pass it a list of choices as well as set the default choice. Of course, you cannot create a single widget in isolation. The widget must be inside of a parent widget. In wxPython, you almost always want the parent to be a wx.Panel that is inside of a wx.Frame.
Let’s write some code and see how this all lays out:
import wx
class MainPanel(wx.Panel):
def __init__(self, parent):
super().__init__(parent)
self.cb_value = 'One'
self.combo_contents = ['One', 'Two', 'Three']
self.cb = wx.ComboBox(self, choices=self.combo_contents,
value=self.cb_value, size=(100, -1))
self.cb.Bind(wx.EVT_TEXT, self.on_text_change)
self.cb.Bind(wx.EVT_COMBOBOX, self.on_selection)
def on_text_change(self, event):
current_value = self.cb.GetValue()
if current_value != self.cb_value and current_value not in self.combo_contents:
# Value has been edited
index = self.combo_contents.index(self.cb_value)
self.combo_contents.pop(index)
self.combo_contents.insert(index, current_value)
self.cb.SetItems(self.combo_contents)
self.cb.SetValue(current_value)
self.cb_value = current_value
def on_selection(self, event):
self.cb_value = self.cb.GetValue()
class MainFrame(wx.Frame):
def __init__(self):
super().__init__(None, title='ComboBox Changing Demo')
panel = MainPanel(self)
self.Show()
if __name__ == "__main__":
app = wx.App(False)
frame = MainFrame()
app.MainLoop()
The main part of the code that you are interested in is inside the MainPanel class. Here you create the widget, set its choices list and a couple of other parameters. Next you will need to bind the ComboBox to two events:
- wx.EVT_TEXT– For text change events
- wx.EVT_COMBOBOX– For changing item selection events
The first event, wx.EVT_TEXT, is fired when you change the text in the widget by typing and it also fires when you change the selection. The other event only fires when you change selections. The wx.EVT_TEXT event fires first, so it has precedence over wx.EVT_COMBOBOX.
When you change the text, on_text_change() is called. Here you will check if the current value of the ComboBox matches the value that you expect it to be. You also check to see if the current value matches the choice list that is currently set. This allows you to see if the user has changed the text. If they have, then you want to grab the index of the currently selected item in your choice list.
Then you use the list’s pop() method to remove the old string and the insert() method to add the new string in its place. Now you need to call the widget’s SetItems() method to update its choices list. Then you set its value to the new string and update the cb_value instance variable so you can check if it changes again later.
The on_selection() method is short and sweet. All it does is update cb_value to whatever the current selection is.
Give the code a try and see how it works!
Wrapping Up
Adding the ability to allow the user to update the wx.ComboBox‘s contents isn’t especially hard. You could even subclass wx.ComboBox and create a version where it does that for you all the time. Another enhancement that might be fun to add is to have the widget load its choices from a config file or a JSON file. Then you could update on_text_change() to save your changes to disk and then your application could save the choices and reload them the next time you start your application.
Have fun and happy coding!
The post Letting Users Change a wx.ComboBox’s Contents in wxPython appeared first on The Mouse Vs. The Python.
↧
Learn PyQt: Build GUI layouts with Qt Designer for PyQt5 apps
When laying out your Qt GUIs it can be quite a tricky task to place every widget in the right position on your forms. Fortunately, Qt offers a set of layout managers that simplify the process of widget positioning and will allow you to easily create any kind of layout. To lay out the widget in a form, you can create everything in code, or you can create your layout with Qt Designer. In this tutorial, you'll learn how to use Qt's layouts with Qt Designer to build complex GUIs for your applications.
Additionally, we'll create a dialog example using several widgets with a coherent layout to reinforce your knowledge and put everything together into a fully functional dialog just like you would create in a real-world application.
Using Layouts With Qt Designer
Qt Designer is the Qt tool for designing and creating graphical user interfaces (GUI) for desktop applications. With Qt Designer, you can create windows, dialogs, and forms. It allows you to add different kind of widgets to create your GUIs using on-screen forms and a drag-and-drop based interface.
Qt Designer's main interface looks as follows —
 Qt Designer — Main Interface
Qt Designer — Main Interface
Qt Designer has a clear and user-friendly interface that allows you to create any kind of GUI by dragging widget onto an empty form. After you place all the widgets on your form, you need to place them in a coherent layout. This will ensure that all your widgets will be displayed and resized properly when the form is previewed or used in an application.
Qt's layout managers are structured containers which automatically arrange child widgets ensuring that they make good use of the available space. Placing widgets within a layout manager automatically lays them out according to the defined rules. One of Qt Designer's most useful features is the ability to drag and drop hierarchies of layout managers to arrange widgets into clean and functional interfaces.
In Qt Designer, you can create layout objects by applying a layout to a group of existing widgets. Although it's possible to drag layouts onto a form and then drag widgets into the layouts, this can be a bit fiddly. The best practice is to instead drag all the widgets and spacers you need onto the form and then select related widgets and spacers and apply the layouts to them. Use the following steps —
- Drag and drop the widgets on the form trying to place them near their desired position
- Select the widgets that should be managed with a given layout, by holding the
Ctrlkey and clicking on them - Apply the appropriate layout (horizontal, vertical, grid, or form) using Qt Designer's toolbar, main menu, or the form's context menu
Before you go into an example, take a look at the layout related options that Qt Designer offers —
- Use layout options on the main toolbar
- Use layout options on the main menu
- Use layout options on the form's context menu
The most accessible way for creating layouts is using the layout section of Qt Designer's main toolbar. This section looks as follows —
 Qt Designer — Layout toolbar
Qt Designer — Layout toolbar
From left to right, you'll find the following buttons —
- Lay Out Horizontally arranges selected widgets in a horizontal layout next to each other (Key combination,
Ctrl+1). This option uses a standardQHBoxLayoutobject - Lay Out Vertically arranges selected widgets in a vertical layout, one below another (key combination,
Ctrl+2). This option uses a standardQVBoxLayoutobject - Lay Out Horizontally in Splitter arranges the widgets horizontally using a splitter (Key combination,
Ctrl+3) - Lay Out Vertically in Splitter arranges the widgets vertically using a splitter (Key combination,
Ctrl+4) - Lay Out in a Grid arranges widgets in a table-like grid (rows and columns). By default, each widget occupies one cell of the grid, but you can modify this behavior and make the widgets to span several cells (Key combination,
Ctrl+5). This option uses a standardQGridLayoutobject - Lay Out in a Form Layout arranges selected widgets in a two-column layout. The left column is usually for labels asking for some information and the right column includes widgets for entering, editing, or showing that information (Key combination,
Ctrl+6) - Break Layout this key allows you to brake an existing layout. Once widgets are arranged in a layout, you cannot move and resize them individually, because their geometry is controlled by the layout. To modify individual widgets, you'll need to break the layout and redo it later (Key combination
Ctrl+0) - Adjust Size adjusts the size of the layout to accommodate contained widgets and to ensure that each has enough space to be visible (Key combination
Ctrl+J)
These same layout related options are also available through Qt Designer's main menu under the Form menu and through the form's context menu, so you can choose the one you like better.
Now we have the theory out of the way, we can put these layouts into practise. In the next few sections, we'll be using Qt Designer to lay out the widgets on our forms and build nice and elegant GUIs for your desktop applications. But before we start experimenting with the different layout managers that Qt offers, we're first going to create a custom widget to visualize the layouts as we go through this tutorial.
The completed .ui file is can be downloaded here if you would like to skip this step.
Go ahead and fire up your Qt Designer, then run the following steps —
- Select
Widgetat thetemplates/formstab of theNew Formdialog. This will create a new empty form to work on. - Save your form as
layout-labels.ui. - Look for a Label widget on the
Widget Boxand drag it onto the form. - Go to the
Property Editorand set thetextproperty to0. - Open the
Text Editdialog and set the text color to white. Set the font size to20points and justify the text. PressOKto apply the changes. - Go to the
Property Editorand set theautoFillBackgroundproperty toTrueby selecting the check box. - Look up the
paletteproperty and open theEdit Palettedialog. Use theQuickoption to set the color to red.
If you feel lost, take a look at the following screencast to see the steps in action —

In this example, you create a new window based on the Widget template. Then, you add a Label, set its text property to 0, and set its background color to red.
To complete this example, repeat all the steps to add three more labels with their respective text set to 1, 2, and 3 and their colors set to green, yellow, and blue. You'll end up with a form like this:
 Qt Designer — Form with colored labels
Qt Designer — Form with colored labels
The above screenshot shows the initial form that you'll use for the next few sections. It's a clean form with four label objects on it. You can set a background color to each label to be able to see and differentiate them more easily in the following sections.
Horizontal Layouts, QHBoxLayout
You can use a horizontal layout manager (QHBoxLayout) to arrange the widgets in one row. To create this kind of layout in code, you need to instantiate the QHBoxLayout class and then add your widgets to the layout object. In Qt Designer it's easier to work in the other way around.
With your layout-labels.ui file open, first select all your labels. To do this, you can click each widget in turn while you hold the Ctrl key or you can also click and drag with the mouse pointer inside the form to select the widgets.
Once you have selected the widgets, put them in a horizontal layout by selecting the Lay Out Horizontally button in the Qt Designer's main toolbar. You can also use the option Lay out->Lay Out Horizontally from the context menu shown below or you can press Ctrl+1. The following screencast will guide you through these steps —

If the layout is wrong, then you can easily undo everything and restart laying things out again. To undo things, you can press Ctrl+z or use the Edit menu from Qt Designer's main menubar. If that isn't possible or doesn't work, then you can just break the layout using the Break Layout button from Qt Designer's main toolbar. Another way to break a layout is to press Ctrl+0 or choose Break Layout from the form's context menu.
Vertical Layouts, QVBoxLayout
You can use a vertical layout (QVBoxLayout) to arrange your widgets in one column one above the other. This can be very useful when you're creating groups of widgets and you need to ensure that they are vertically aligned.
Starting up with your original layout-labels.ui file, the first step will be to select the widgets that you need to include in the vertical layout. After that, you can click on the Lay Out Vertically button over the main toolbar, or you can use the context menu, or you can also press Ctrl+2. The following screencast will guide you through these steps —

If you take a closer look at the screencast, then you can see that the layout object is indicated by a thin red frame surrounding the labels on the form. This red frame isn't visible at preview or at runtime it's just a guide you can use when you're designing the form. Also notices that, the layout object appears in the Object Inspector and its properties (margins and constraints) are shown in the Property Editor.
Grid Layouts, QGridLayout
Sometimes you need to lay out your widgets both horizontally and vertically within the same layout. To do this, you can use a grid layout manager (QGridLayout). Grid layout managers lay out your widgets in a square or rectangular grid, with all widgets aligning vertically and horizontally with their neighbours. This kind of layout can give you much more freedom to arrange your widgets on a form, while maintaining some degree of structure. This arrangement can be more suitable than nested arrangement of horizontal and vertical layouts, particularly when you care about the alignment of adjacent rows or columns.
You can build a grid layout with Qt Designer in the same way as for other layouts. The first step is to select the group of widgets that you want to lay out using a grid layout manager. Then, you can use the toolbar, the context menu, or you can press Ctrl+5 to set up the layout. Watch the following screencast —

In this case, we use a 2 x 2 grid layout to arrange the labels on your form. Notice that, to use this kind of layout, you should first place your widgets in rows and columns on the form, as shown in the screencast above. Qt Designer is quite clever and will try to keep your design as similar as possible to what you initially created by hand. It can even create difficult multi-column arrangements automatically or automatically fill empty cells.
Form Layouts, QFormLayout
While a QGridLayout can be used to layout forms with inputs and labels in two columns, Qt also provides a layout designed specifically for this purpose — (QFormLayout). This type of layout is ideal when you're creating a structured data-entry or database application. The left column will commonly hold labels that ask for some information. The right column holds the input widgets such as line edits (QLineEdit), spin boxes (QSpinBox), date edits (QDateEdit), combo boxes (QComboBox), and so on.
The advantage of using this layout over QGridLayout is that it is simpler to work with when you only need two columns. The following screencast shows it in action —

In this example, we first add four new labels. These labels will hold information about the data you need to be entered or edited in the second column. In this case, the second column holds your tests colored labels, but usually this column will be used to place input widget like line edits, spin boxes, combo boxes, and so on.
Splitter Layouts
Splitters are container objects that arrange widgets horizontally or vertically in two resizeable panels. With this kind of layout, you can freely adjust the amount of space that each panel occupy on your form, while keeping the total space used constant. In Qt splitter layouts are managed using QSplitter.
Even though splitters are technically a container widget (not a layout), Qt Designer treats them as layouts that can be applied to existing widgets. To place a group of widgets into a splitter, you first select them as usually and then apply the splitter by using the appropriate toolbar button, keyboard shortcut, or context menu option in Qt Designer Take a look at the following screencast —

In this example, we first apply a horizontal splitter to your labels. Notice that, you'll need to launch the form preview if you want to see the splitter in action. You can launch the form preview by pressing Ctrl+R. Later on, we apply a vertical splitter to the labels. In each case, you can freely resize the widget using your mouse's pointer.
Building Other Layouts With Qt Designer
There are a few more things you can do with layouts in Qt Designer. For example, suppose you need to add a new widget to an existing layout, or to use nested layouts to arrange your widgets in a complex GUI. In the following few sections, we'll cover how to accomplish some of these tasks.
Inserting Objects into an Existing Layout
Objects can be inserted into an existing layout by dragging them from their current positions and dropping them at the required position in the layout. A blue cursor is displayed in the layout when an object is dragged over it to indicate where the object will be placed.
Take a look at the following screencast where we put three of our labels in a vertical layout and then realize the we left the blue label out of the game —

It's also possible to move or change the position of a given widget in a layout. To do this, just drag and drop the widget to its new position in the layout. Remember to follow the blue line to get this right.
Nesting Layouts to Build Complex GUIs
You can also nest layout managers one inside another using Qt Designer. The inner layout then becomes a child of the enclosing layout. By doing this you can iteratively create very complex, yet well-structured user interfaces.
Layouts can be nested as deep as you need. For example, to create a dialog with a horizontal row of buttons at the bottom and a bunch of other widgets aligned vertically on the form, you can use a horizontal layout for the buttons and a vertical layout for the rest of the widgets, then wrap these layouts in a vertical layout.
Coming back to our colored labels example, the following screencast shows the process of arranging a nested layout in Qt Designer —

In this example, we first arrange widgets in pair using a horizontal layout. Then we nest both of these layouts in a third layout, but this time a vertical one. The layouts can be nested as deep as required.
When you select a child layout, its parent layout can be selected by pressing the Shift key while clicking on it. This allows you to quickly select a specific layout in a hierarchy, which otherwise will be difficult to do because of the small frame delimiting each layout manager.
Setting a Top Level or Main Layout
The final step you need to perform when building a form is to combine all the layouts and widget into one main layout or top level layout. This layout is at the top of the hierarchy of all other layouts and widgets. It's vital that you have a layout because otherwise the widgets on your form won't resize when you resize the window.
To set the main layout just right click anywhere on your form that doesn't contain a widget or layout. Then, you can select Lay Out Horizontally, or Lay Out Horizontally, or you can also select Lay Out in a Grid like in the following screencast —

In this example, we use each of the three different layouts as our top level layout in turn. We first use a horizontal layout, then break the layout and use a vertical layout. Finally we set a grid layout. Which top level layout you choose for your top-level layout will depend on your specific requirements for your app.
It's important that you note that top level layouts are not visible as a separate object in the Object Inspector. Its properties appear below the widget properties of the main form. Also, note that if your form doesn't have a layout, then its icon appears with a red circle on the Object Inspector. Another way to check if you've properly set a main layout is trying to resize the form, if a main layout is in place, then your widgets should resize accordingly.
As you start to build more complex applications, you'll discover that other container widgets also require you to set a top level layout, for example QGroupBox, QTabWidget, QToolBox, and so on. To do this, you can run the same steps you've seen here, but this time you need to right click on the container widget.
Laying Out a Dialog With Qt Designer
For a final and more complete example of how to use layouts with Qt Designer, we're now going to create a dialog to introduce some information in a database application. Suppose we're building a Human Resources Management software for our company Poyqote Inc.. We're now working in a form to introduce some data about our employees. The dialog should present users with a user-friendly GUI for introducing the following data:
- Employee name
- Employment date
- Department
- Position
- Annual salary
- Job description
What is the best way to lay out this form? There are many options, and it's largely a matter of taste and practise. But here we're using a QFormLayout to arrange the entry fields into two columns with labels on the left and input boxes on the right. The process of creating the layout is shown in the following screencast —

The base dialog is created using Qt Designer's Dialog with Buttons Bottom template. Then, we add some labels and some input widget, including line edits, date edits, text edits, and combo boxes. Next we put all those widgets in a form layout and finally define a top level or main layout for the form.
The finished dialog .ui file can be downloaded here.
Conclusion
Qt Designer is a powerful tool when it comes to creating GUIs using Qt. One of its most straightforward and useful features is the ability to arrange your widgets in different types of layouts. Learning how to effectively create layouts with Qt Designer can sky rocket your productivity, particularly when creating complex GUIs.
This tutorial guided you through the process of creating custom layouts with Qt Designer. You now know how to get the most out of Qt Designer when laying out your GUIs.
Continue reading: “Embedding custom widgets from Qt Designer”
↧
Matt Layman: Serverless Python And Why You Should Try It Out
At the January 2020 Python Frederick event, Patrick Pierson showed the group how you can use Python in different serverless services on AWS and GCP. He also showed a couple of serverless frameworks like Serverless and Chalice.
The recording from the talk is available on YouTube. Check it out!
Questions? Feel free to mention me on Twitter at @mblayman so I can try to respond to your question.
↧
Stack Abuse: Convert Strings to Numbers and Numbers to Strings in Python
Introduction
Python allows you to convert strings, integers, and floats interchangeably in a few different ways. The simplest way to do this is using the basic str(), int(), and float() functions. On top of this, there are a couple of other ways as well.
Before we get in to converting strings to numbers, and converting numbers to strings, let's first see a bit about how strings and numbers are represented in Python.
Note: For simplicity of running and showing these examples we'll be using the Python interpreter.
Strings
String literals in Python are declared by surrounding a character with double (") or single quotation (') marks. Strings in Python are really just arrays with a Unicode for each character as an element in the array, allowing you to use indices to access a single character from the string.
For example, we can access individual characters of these strings by specifying an index:
>>> stringFirst = "Hello World!"
>>> stringSecond = 'Again!'
>>> stringFirst[3]
'l'
>>> stringSecond[3]
'i'
Numerics
A numeric in Python can be an integer, a float, or a complex.
Integers can be a positive or negative whole number. Since Python 3, integers are unbounded and can practically hold any number. Before Python 3, the top boundary was 231-1 for 32-bit runtimes and 263-1 for 64-bit runtimes.
Floats have unlimited length as well, but a floating-point number must contain a decimal point.
Complex numerics must have an imaginary part, which is denoted using j:
>>> integerFirst = 23
>>> floatFirst = 23.23
>>> complextFirst = 1 + 23j
Converting Strings to Numerics
Using the int() Function
If you want to convert a string to an integer, the simplest way would be to use int() function. Just pass the string as an argument:
>>> x = "23"
>>> y = "20"
>>> z = int(x) - int(y)
>>> z
3
This works as expected when you're passing a string-representation of an integer to int(), but you'll run in to trouble if the string you pass doesn't contain an integer value. If there are any non-numeric characters in your string then int() will raise an exception:
>>> x = "23a"
>>> z = int(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '23a'
This same exception will even be raised if a valid float string is passed:
>>> x = "23.4"
>>> z = int(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '23.4'
The int() function does have another useful feature than just converting strings to integers, it also allows you to convert numbers from any base to a base 10 integer. For example, we can convert the following binary string to a base 10 integer using the base parameter:
>>> int('1101100', base=2)
108
The same can be done for any other base, like hexadecimal (base 16):
>>> int('6C', base=16)
108
Using the float() Function
Converting string literals to floats is done via the float() function:
>>> x = "23.23"
>>> y = "23.00"
>>> z = float(x) - float(y)
>>> z
0.23000000000000043
Notice that the resulting value is not entirely accurate, as it should just be 0.23. This has to do with floating point math issues rather than the conversion from string to number.
The float() function offers a bit more flexibility than the int() function since it can parse and convert both floats and integers:
>>> x = "23"
>>> y = "20"
>>> z = float(x) - float(y)
>>> z
3.0
Unlike int(), float() doesn't raise an exception when it receives a non-float numeric value.
However, it will raise an exception if a non-numeric value is passed to it:
>>> x = "23a"
>>> z = float(x)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: could not convert string to float: '23a'
While float() does not have the ability to convert non-base 10 numbers like int() does, it does have the ability to convert numbers represented in scientific notation (aka e-notation):
>>> float('23e-5')
0.00023
>>> float('23e2')
2300.0
Using the complex() Function
Converting string literals to complex numerics is done via the complex() function. To do so, the string must follow specific formatting. Particularly, it must be formatted without white spaces around the + or - operators:
>>> x = "5+3j"
>>> y = "3+1j"
>>> z = complex(x) + complex(y)
>>> z
(8+4j)
Having any extra spaces between the + or - operators will result in a raised exception:
>>> z = complex("5+ 3j")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: complex() arg is a malformed string
Like the float() function, complex() is also more relaxed in the types of numbers it allows. For example, the imaginary part of the number can be completely omitted, and both integers and floats can be parsed as well:
>>> complex("1")
(1+0j)
>>> complex("1.2")
(1.2+0j)
As you can see, however, this should not be used as a more flexible replacement for int/float since it automatically adds the imaginary part of the number to the stringified version.
Converting Numerics to Strings
Using the str() Function
The str() function can be used to change any numeric type to a string.
The function str() is available from Python 3.0+ since the strings in Python 3.0+ are Unicode by default. However, this is not true for Python versions below 3.0 - in which to achieve the same goal, the unicode() function is used:
>>> str(23) # Integer to String
'23'
>>> str(23.3) # Float to String
'23.3'
>>> str(5+4j) # Complex to String
'(5+4j)'
The nice thing about str() is that it can handle converting any type of number to a string, so you don't need to worry about choosing the correct method based on what type of number you're converting.
Using the format() Function
Another way of converting numerics to strings is using the format() function, which allows you to set placeholders within a string and then convert another data type to a string and fill the placeholders.
To use the function, simply write a string followed by .format() and pass the arguments for the placeholders.
Here's an example:
>>> "My age is {}".format(21)
'My age is 21'
The arguments in the .format() function can also be referred to individually, using their positions or variable names:
>>> "You get {product} when you multiply {1} with {0}".format(5.5, 3, product=16.5)
'You get 16.5 when you multiply 3 with 5.5'
Note that underneath the hood, the .format() function simply uses str() to convert the arguments to strings. So essentially this is a similar way of converting numbers to strings as the previous section, but .format() acts as a convenience function for formatting a string.
Conclusion
Python allows you to convert strings, integers, and floats interchangeably in a few different ways. The simplest way to do this is using the basic str(), int(), and float() functions. On top of this, there are a couple of other ways as well such as the format() function. Just keep in mind that the int(), float(), and complex() functions have their limitations and may raise exceptions if the input string isn't formatted exactly as they expect.
↧
↧
Python Bytes: #163 Meditations on the Zen of Python
↧
Talk Python to Me: #246 Practices of the Python Pro
When you can call yourself a professional developer? Sure, getting paid to write code is probably part of the formula. But when is your skillset up to that level?
↧
Mike Driscoll: Top 10 Most Read Mouse vs Python Articles of 2019
2019 was a good year for my blog. While we didn’t end up getting a lot of new readers, we did receive a small bump. There has also been a lot more interest in the books that are available on this site.
For the year 2019, these are the top ten most read:
- #1 – Creating PDFs with PyFPDF and Python
- #2 – Exporting Data from PDFs with Python
- #3 – Reading Excel Spreadsheets with Python and xlrd
- #4 – Determining if all Elements in a List are the Same in Python
- #5 – A Simple Step-by-Step Reportlab Tutorial
- #6 – How to Get a List of Class Attributes in Python
- #7 – Python: Using Turtles for Drawing Circles
- #8 – How to Export Jupyter Notebooks into Other Formats
- #9 – Python 201: A multiprocessing tutorial
- #10 – Python 3: An Intro to Enumerations
Note that none of these articles were actually written in 2019. Half of them were written in 2018 and one of them dates all the way back to 2010. Interestingly enough, my most popular article of 2019 is about using Python to take a photo of the black hole. That article ranks way down at #28.
For 2020, I am going to work hard at creating new content and tutorials that you will find useful in your Python journey. In the meantime, I hope you’ll enjoy reading the archives while I work on some new ones!
The post Top 10 Most Read Mouse vs Python Articles of 2019 appeared first on The Mouse Vs. The Python.
↧