In this article, a few image processing / computer vision problems and their solutions with python libraries (scikit-image, cv2) will be discussed. Removing Gaussian Noise from images by computing mean and median images Start with an input image. Create n (e.g, n=100) noisy images by adding i.i.d. Gaussian noise (with zero mean) to the original … Continue reading Solving Some Image Processing and Computer Vision Problems with Python libraries
↧
Sandipan Dey: Solving Some Image Processing and Computer Vision Problems with Python libraries
↧
Python Celery - Weekly Celery Tutorials and How-tos: Monitoring a Dockerized Celery Cluster with Flower
A flower, sometimes known as bloom or blossom, is the reproductive structure found in flowering plants. Celery is a marshland plant in the family in the family Apicaeae that has been cultivated as a vegetable since antiquity. A docker is a waterfront manual laborer who is involved in loading and unloading ships, trucks, trains or airplanes – Wikipedia.
There are only two hard things in Computer Science: cache invalidation and naming things. – Phil Karlton
What is Flower?
Flower is a web based tool for monitoring Celery workers and task progress.

Install with pip:
pip install flower
Launch flower, pass your Celery message broker url and Flower port:
flower --broker=redis://localhost:6379/0 --port=8888
Open http://localhost:8888 in your browser.
Flower on Docker
Use the official mher/flower Docker image to dockerize Flower. Define the docker-compose flower service:
flower:
image: mher/flower
command: ["flower", "--broker=redis://redis:6379/0", "--port=8888"]
ports:
- 8888:8888
This solution is not ideal. If you need to change your broker url, you have to touch the flower command. And your Celery workers, as they use the same broker. Sounds messy if you run your app in more than one environment (say, QA and production). And this is not even a complex setup.
Stuff like broker url and flower port is configuration. The twelve-factor app stores config in environment variables. Environment variables are easy to change between deploys. Docker supports and encourages the use of environment variables for config. Both Celery and Flower support configuration via environment variables out of the box. Flower is (roughly speaking) a Celery extension and thus supports all Celery settings.
All Celery settings (the list is available here) can be set via environment variables. In capital letters, prefixed with CELERY_. For example, to set broker_url, use the CELERY_BROKER_URL environment variable. The Flower specific settings can also be set via environment variables. A full list is available here, uppercase the variable and prefix with FLOWER_. For instance, to configure port, use the FLOWER_PORT environment variable.
Refactor the docker-compose flower service:
flower:
image: mher/flower
environment:
- CELERY_BROKER_URL=redis://redis:6379/0
- FLOWER_PORT=8888
ports:
- 8888:8888
Celery Worker on Docker
The Flower dashboard lists all Celery workers connected to the message broker. Celery assigns the worker name. The worker name defaults to celery@hostname. In a container environment, hostname is the container hostname. For what it’s worth, the container hostname is a meaningless string.

As long as you run only one type of Celery worker, this is not an issue. Unlike when you run specialised workers in dedicated containers. If you have different workers processing different queues, this becomes an issue. You cannot tell which worker is what by looking at the Flower dashboard. All you see is a list of celery@gibberish workers.
One way to solve this is to control the hostname. Docker gives you control over the hostname via the hostname property:
worker_1:
hostname: worker_1
command: ["celery", "worker", "--app=worker.app", "--loglevel=INFO"]
worker_2:
hostname: worker_2
command: ["celery", "worker", "--app=worker.app", "--loglevel=INFO"]
The Flower dashboard shows these workers now as celery@_worker_1 and celery@_worker_2. Unfortunately, this solution does not scale. Docker uses the same hostname for all containers that belong to the same service.
Scaling worker_1 to two containers results in two workers named celery@_worker_1. This is ok with Celery but not so much for Flower. Flower shows only one worker in the dashboard, arguably a bug (?). But even if it did show both workers with the same name, you would not be able to tell them apart.
There is an alternative solution hidden in the Celery docs. Celery provides a --hostname command line argument to set the worker name. The --hostname argument itself supports variables:
%h: hostname, including domain name%n: hostname only%d: domain name only
Refactor the docker-compose worker services:
worker_1:
command: ["celery", "worker", "--app=worker.app", "--hostname=worker_1@%h", ", "--loglevel=INFO"]
worker_2:
command: ["celery", "worker", "--app=worker.app", "--hostname=worker_2@%h", ", "--loglevel=INFO"]

Here, we set the names worker_1 and worker_2. You can make this meaningful. For example assigning the same name as the queue name the worker subscribes to. The hostname %h is still container hostname gibberish but it ensures a unique name, even at scale. Plus, it allows you to link back to the container, which can be useful for logging and debugging.
Gotchas and shortfalls
Flower has no idea which Celery workers you expect to be up and running. The Flower dashboard shows workers as and when they turn up. When a Celery worker comes online for the first time, the dashboard shows it. When a Celery worker disappears, the dashboard flags it as offline.
When you run Celery cluster on Docker that scales up and down quite often, you end up with a lot of offline workers. That’s a lot of dashboard clutter. As of now, the only solution is to restart Flower. There is an open GitHub issue for this.
Conclusion
Flower is the de-facto monitoring tool for Celery. It is easy to set up and deploy into a containerized stack. But it takes some tweaking to make it work effectively in a microservices setup.
↧
↧
Codementor: Custom Celery task states
This post was originally published on Distributed Python (https://www.distributedpython.com/) on September 28th, 2018.
Celery tasks always have a state. If a task finished executing successfully,...
↧
Vasudev Ram: A Python email signature puzzle
By Vasudev Ram

Hi, readers,
I sometimes use slightly cryptic Python code snippets in my email signature.
Can you figure out what output this Python program produces, and how it works, without running the code?
I folded some logical lines to multiple physical lines so the code does not get truncated.
for ix, it in enumerate([('\n', 2 >> 1), \
("larur ylurt", (8 >> 1) + 1), ('\n', 1 1),]):
for tm in range(it[1]):
print chr(ord(it[0][::-1][0]) - 2 ** 5) + \
it[0][::-1][(1 8) - (2 ** 8 - 1):] \
if ix % 2 == 1 else it[0] * int(bin(4) \
and bin(1), 2) * ix
If you could, how long did it take you to solve it? I'll publish the answer in my next post, for those who could not get it. - Enjoy. - Vasudev Ram - Online Python training and consulting
I conduct online courses on Python programming, Unix/Linux (commands and shell scripting) and SQL programming and database design, with personal coaching sessions. Contact me for details of course content, terms and schedule. Get DPD: Digital Publishing for Ebooks and Downloads. Hit the ground running with my vi quickstart tutorial. I wrote it at the request of two Windows system administrator friends who were given additional charge of some Unix systems. They later told me that it helped them to quickly start using vi to edit text files on Unix. Check out WP Engine, powerful WordPress hosting. Own a piece of history: Legendary American CookwareTeachable: feature-packed course creation platform, with unlimited video, courses and students. Track Conversions and Monitor Click Fraud with Improvely.
Posts about: Python * DLang * xtopdfMy ActiveState Code recipesFollow me on:
↧
Python Insider: Python 3.7.1rc2 and 3.6.7rc2 now available for testing
Python 3.7.1rc2 and 3.6.7rc2 are now available. 3.7.1rc2 is a release preview of the first maintenance release of Python 3.7, the latest feature release of Python. 3.6.7rc2 is a release preview of the next maintenance release of Python 3.6, the previous feature release of Python. Assuming no further critical problems are found prior to 2018-10-20, no code changes are planned between these release candidates and the final releases. These release candidates are intended to give you the opportunity to test the new security and bug fixes in 3.7.1 and 3.6.7. We strongly encourage you to test your projects and report issues found to bugs.python.org as soon as possible. Please keep in mind that these are preview releases and, thus, their use is not recommended for production environments.
You can find these releases and more information here:
![]()
![]()
![]()
![]()
![]()
![]()
You can find these releases and more information here:
↧
↧
Weekly Python StackOverflow Report: (cxlvii) stackoverflow python report
These are the ten most rated questions at Stack Overflow last week.
Between brackets: [question score / answers count]
Build date: 2018-10-13 21:36:41 GMT
- Is i = i + n truly the same as i += n? - [40/3]
- How come list element lookup is O(1) in Python? - [24/3]
- Pandas DataFrame to multidimensional NumPy Array - [14/1]
- Get previous business day in a DataFrame - [11/5]
- Why does the UnboundLocalError occur on the second variable of the flat comprehension? - [9/1]
- How can I count the number of consecutive TRUEs in a DataFrame? - [8/2]
- Why is an __init__ skipped when doing Base.__init__(self) in multiple inheritance instead of super().__init__()? - [8/1]
- Pipenv trouble on MacOS "TypeError: 'module' object is not callable" - [8/1]
- Pandas any() returning false with true values present - [8/1]
- In Python, if I type a=1 b=2 c=a c=b, what is the value of c? What does c point to? - [7/8]
↧
PyBites: PyBites Twitter Digest - Issue 32, 2018
Kenneth Reitz's latest project, a new Python Web Framework - "Responder"!
I'm very happy to announce the release of my heavy first iteration of my new web framework, "Responder":… https://t.co/BU9auBTdd7
— Kenneth ☤ Reitz (@kennethreitz) October 12, 2018
30 Amazing Python Projects of 2018 covered on the latest Talk Python Episode
Just published @talkpython episode 181 -- Thirty amazing Python projects of 2018 with @brianokken. Have a listen at https://t.co/Ot2CO3q5FY
— Talk Python Podcast (@TalkPython) October 12, 2018
Visually trace the execution of your Python programs with LivePython
Submitted by @code-monk08
Cool! Visually trace the execution of your #Python programs with #LivePython - https://t.co/2jWj5Gp5qS
— Pybites (@pybites) October 14, 2018
Our very own Rob details his project for moving from Evernote to ZimWiki
New project: From Evernote to ZimWiki by way of Python: https://t.co/1HW3X5EiAe#python@pybites@jmwatt3
— Rob Fowler (@BlueGator4) October 12, 2018
Great reminder on .format()
Submitted by @dgjustice
Reminder: don’t use #python’s .format() on untrusted format strings: https://t.co/nDtzwHdmbf
— Ned Batchelder (@nedbat) October 11, 2018
Python everywhere! Very cool
This year’s Nobel Prize in economics was awarded to a Python convert. May be a good story to tell about python in n… https://t.co/JpXpWMDRth
— skpl (@snlkapil) October 09, 2018
Reminder: our challenges count toward Hacktoberfest!
❌ Halloween 🎃 ✅ #Hacktoberfest2018👨🏽💻 With #Thanksgiving2018 here in Canada, I'm thankful for open source and ho… https://t.co/KUrfnlwZ8F
— Sean (@SeanPrashad) October 08, 2018
Install Tensorflow using Conda
Submitted by @clamytoe
Here are two pretty big reasons why you should install #Tensorflow using #conda instead of pip >>… https://t.co/Utzo88nLzV
— TensorFlow Beat (@TensorBeat) October 10, 2018
2018 DevOps RoadMap. Bookmark this one!
Submitted by @Erik
The 2018 DevOps RoadMap by @javinpaul at @hackernoon. An illustrated guide to becoming a DevOps Engineer with links… https://t.co/7u35PKgFoC
— ITNEXT (@ITNEXT_io) October 10, 2018
The Python Mock Cookbook
Submitted by @clamytoe
[Python Tip] "You always need to mock the thing where it’s imported TO, not where it’s imported FROM." from "Python… https://t.co/OGzkgOarwn
— Paolo Melchiorre (@pauloxnet) October 10, 2018
Link tests with the function it's testing with coverage.py!
Submitted by @dgjustice
Link tests with the function it tests... "Who tests what is here: https://t.co/rZeq8PJG5X 5.0a3" Who Tests What ann… https://t.co/v2DPNG4Wpt
— Python People (@pythonpeople) October 08, 2018
Exercises for Pandas!
Submitted by @clamytoe
Pandas by Solutions and Examples https://t.co/TZp7bkzKgx
— /r/Python Popular (@RedditPython) October 08, 2018
Write Better Functions with Jeff Knupp
Write Better #Python Functions: https://t.co/YaQIwbxNqa. New blog post that outlines the characteristics of "good" functions in #Python
— Jeff Knupp (@jeffknupp) October 11, 2018
functools reduce in action
#pythontip from @singhjayp: reduce(f, seq, initializer) returns a single value constructed by calling 'f' on the f… https://t.co/ALcHvKBGYF
— Daily Python Tip (@python_tip) October 11, 2018
Python Data Science Cheatsheet!
Python For Data Science Cheat Sheet - Importing Data https://t.co/SSNAJrdMzw
— Python LibHunt (@PythonLibHunt) October 12, 2018
>>>frompybitesimportBob,JulianKeepCalmandCodeinPython!↧
Zato Blog: Managing live WebSocket API clients
Zato-based WebSockets are a great choice for high-performance API integrations. WebSockets have minimal overhead, which, coupled with their ability to invoke services in a synchronous manner, means that large numbers of clients can easily connect to Zato API servers.
Introduction
The crucial distinction between WebSockets and typical REST-based APIs is that clients based on the former protocol always establish long-running TCP connections and, once connected, the overhead they incur is practically negligible.
With a great number of clients a series of questions naturally appears. What are the clients currently connected? What if I want to force one to disconnect? What topics and message queues are they subscribed to? How can I communicate with the WebSockets directly from web-admin?
This blog post answers all these questions and then some more.
WebSocket channels
As a refresher, recall that all WebSocket clients connect to Zato through their channels. Each channel encapsulates basic information about what is expected from each client, e.g. their credentials or which service is responsible for their requests.

Listing connections
With a desired channel in place, we can start a few clients and then go straight to the listing of connections, as in the screenshow below:


By default, all connections for a given channel are listed but it is possible to filter them out by external client ID - each WebSocket identifies with a unique client ID, as assigned by the system on whose behalf the WebSocket connects. This makes it easy to find connections even if they go through a series of networks.
Each WebSocket is identified by a series of attributes, Client, Remote, Local and Connection time.
Each Client connection has a few of identifiers:
- Unique connection ID assigned by Zato, changed each time a client connects
- Client ID - unique ID assigned by the remote end, persists across connections
- Client name - similar to Client ID but there is no requirement that it be unique
Remote TCP end has two attributes:
- IP address as observed from a Zato server's perspective
- FQDN (domain name) of that IP address
Local server to which a WebSocket is connected:
- Its IP address and port number
- Server name and server process ID (PID) to which the WebSocket is attached
Connection time is by default presented in current user's timezone but clicking it changes the format to UTC.
Checking pub/sub subscriptions

WebSockets may participate in pub/sub processes and it is possible to look up all the topics a particular connection is subscribed to. Note that subscription times may predate connection times - this will be the case if a WebSocket connects, subscribes to a topic, then disconnects and connects again. In such a case, the subscription time will be earlier than the last connection time.
Invoking WebSockets directly

It is possible to send requests straight to a WebSocket, waiting up to timeout seconds for the reply. This lets one communicate with the remote connection directly, which is of great assistance in many low-level diagnostic scenarios.
Disconnecting API clients

Each WebSocket can be disconnected separately - on the protocol level, it will send a Close event to the remote end, afterwards cleaning up all the internal resources taken up by the connection.
Summary
API integrations with WebSockets offer an alternative to REST whose greatest advantage is reduced runtime processing overhead. Zato offers built-in GUI tools to create and manage WebSockets, including searching, listing and direct communication with each WebSocket straight from a browser's window.
To learn more about how to integrate APIs with Zato, visit the tutorial and downloads sections of the extensive documentation which cover everything needed to get started with the platform.
↧
Stefan Behnel: What's new in Cython 0.29?
I'm happy to announce the release of Cython 0.29. In case you didn't hear about Cython before, it's the most widely used statically optimising Python compiler out there. It translates Python (2/3) code to C, and makes it as easy as Python itself to tune the code all the way down into fast native code. This time, we added several new features that help with speeding up and parallelising regular Python code to escape from the limitations of the GIL.
So, what exactly makes this another great Cython release?
The contributors
First of all, our contributors. A substantial part of the changes in this release was written by users and non-core developers and contributed via pull requests. A big "Thank You!" to all of our contributors and bug reporters! You really made this a great release.
Above all, Gabriel de Marmiesse has invested a remarkable amount of time into restructuring and rewriting the documentation. It now has a lot less historic smell, and much better, tested (!) code examples. And he obviously found more than one problematic piece of code in the docs that we were able to fix along the way.
Cython 3.0
And this will be the last 0.x release of Cython. The Cython compiler has been in production critical use for years, all over the world, and there is really no good reason for it to have an 0.x version scheme. In fact, the 0.x release series can easily be counted as 1.x, which is one of the reasons why we now decided to skip the 1.x series all together. And, while we're at it, why not the 2.x prefix as well. Shift the decimals of 0.29 a bit to the left, and then the next release will be 3.0. The main reason for that is that we want 3.0 to do two things: a) switch the default language compatibility level from Python 2.x to 3.x and b) break with some backwards compatibility issues that get more in the way than they help. We have started collecting a list of things to rethink and change in our bug tracker.
Turning the language level switch is a tiny code change for us, but a larger change for our users and the millions of source lines in their code bases. In order to avoid any resemblance with the years of effort that went into the Py2/3 switch, we took measures that allow users to choose how much effort they want to invest, from "almost none at all" to "as much as they want".
Cython has a long tradition of helping users adapt their code for both Python 2 and Python 3, ever since we ported it to Python 3.0. We used to joke back in 2008 that Cython was the easiest way to migrate an existing Py2 code base to Python 3, and it was never really meant as a joke. Many annoying details are handled internally in the compiler, such as the range versus xrange renaming, or dict iteration. Cython has supported dict and set comprehensions before they were backported to Py2.7, and has long provided three string types (or four, if you want) instead of two. It distinguishes between bytes, str and unicode (and it knows basestring), where str is the type that changes between Py2's bytes str and Py3's Unicode str. This distinction helps users to be explicit, even at the C level, what kind of character or byte sequence they want, and how it should behave across the Py2/3 boundary.
For Cython 3.0, we plan to switch only the default language level, which users can always change via a command line option or the compiler directive language_level. To be clear, Cython will continue to support the existing language semantics. They will just no longer be the default, and users have to select them explicitly by setting language_level=2. That's the "almost none at all" case. In order to prepare the switch to Python 3 language semantics by default, Cython now issues a warning when no language level is explicitly requested, and thus pushes users into being explicit about what semantics their code requires. We obviously hope that many of our users will take the opportunity and migrate their code to the nicer Python 3 semantics, which Cython has long supported as language_level=3.
But we added something even better, so let's see what the current release has to offer.
A new language-level
Cython 0.29 supports a new setting for the language_level directive, language_level=3str, which will become the new default language level in Cython 3.0. We already added it now, so that users can opt in and benefit from it right away, and already prepare their code for the coming change. It's an "in between" kind of setting, which enables all the nice Python 3 goodies that are not syntax compatible with Python 2.x, but without requiring all unprefixed string literals to become Unicode strings when the compiled code runs in Python 2.x. This was one of the biggest problems in the general Py3 migration. And in the context of Cython's integration with C code, it got in the way of our users even a bit more than it would in Python code. Our goals are to make it easy for new users who come from Python 3 to compile their code with Cython and to allow existing (Cython/Python 2) code bases to make use of the benefits before they can make a 100% switch.
Module initialisation like Python does
One great change under the hood is that we managed to enable the PEP-489 support (again). It was already mostly available in Cython 0.27, but lead to problems that made us back-pedal at the time. Now we believe that we found a way to bring the saner module initialisation of Python 3.5 to our users, without risking the previous breakage. Most importantly, features like subinterpreter support or module reloading are detected and disabled, so that Cython compiled extension modules cannot be mistreated in such environments. Actual support for these little used features will probably come at some point, but will certainly require an opt-in of the users, since it is expected to reduce the overall performance of Python operations quite visibly. The more important features like a correct __file__ path being available at import time, and in fact, extension modules looking and behaving exactly like Python modules during the import, are much more helpful to most users.
Compiling plain Python code with OpenMP and memory views
Another PEP is worth mentioning next, actually two PEPs: 484 and 526, vulgo type annotations. Cython has supported type declarations in Python code for years, has switched to PEP-484/526 compatible typing with release 0.27 (more than one year ago), and has now gained several new features that make static typing in Python code much more widely usable. Users can now declare their statically typed Python functions as not requiring the GIL, and thus call them from a parallel OpenMP loops and parallel Python threads, all without leaving Python code compatibility. Even exceptions can now be raised directly from thread-parallel code, without first having to acquire the GIL explicitly.
And memory views are available in Python typing notation:
importcythonfromcython.parallelimportprange@cython.cfunc@cython.nogildefcompute_one_row(row:cython.double[:])->cython.int:...defprocess_2d_array(data:cython.double[:,:]):i:cython.Py_ssize_tforiinprange(data.shape[0],num_threads=16,nogil=True):compute_one_row(data[i])
This code will work with NumPy arrays when run in Python, and with any data provider that supports the Python buffer interface when compiled with Cython. As a compiled extension module, it will execute at full C speed, in parallel, with 16 OpenMP threads, as requested by the prange() loop. As a normal Python module, it will support all the great Python tools for code analysis, test coverage reporting, debugging, and what not. Although Cython also has direct support for a couple of those by now. Profiling (with cProfile) and coverage analysis (with coverage.py) have been around for several releases, for example. But debugging a Python module in the interpreter is obviously still much easier than debugging a native extension module, with all the edit-compile-run cycle overhead.
Cython's support for compiling pure Python code combines the best of both worlds: native C speed, and easy Python code development, with full support for all the great Python 3.7 language features, even if you still need your (compiled) code to run in Python 2.7.
More speed
Several improvements make use of the dict versioning that was introduced in CPython 3.6. It allows module global names to be looked up much faster, close to the speed of static C globals. Also, the attribute lookup for calls to cpdef methods (C methods with Python wrappers) can benefit a lot, it can become up to 4x faster.
Constant tuples and slices are now deduplicated and only created once at module init time. Especially with common slices like [1:] or [::-1], this can reduce the amount of one-time initialiation code in the generated extension modules.
The changelog lists several other optimisations and improvements.
Many important bug fixes
We've had a hard time following a change in CPython 3.7 that "broke the world", as Mark Shannon put it. It was meant as a mostly internal change on their side that improved the handling of exceptions inside of generators, but it turned out to break all extension modules out there that were built with Cython, and then some. A minimal fix was already released in Cython 0.28.4, but 0.29 brings complete support for the new generator exception stack in CPython 3.7, which allows exceptions raised or handled by Cython implemented generators to interact correctly with CPython's own generators. Upgrading is therefore warmly recommended for better CPython 3.7 support. As usual with Cython, translating your existing code with the new release will make it benefit from the new features, improvements and fixes.
Stackless Python has not been a big focus for Cython development so far, but the developers noticed a problem with Cython modules earlier this year. Normally, they try to keep Stackless binary compatible with CPython, but there are corner cases where this is not possible (specifically frames), and one of these broke the compatibility with Cython compiled modules. Cython 0.29 now contains a fix that makes it play nicely with Stackless 3.x.
A funny bug that is worth noting is a mysteriously disappearing string multiplier in earlier Cython versions. A constant expression like "x" * 5 results in the string "xxxxx", but "x" * 5 + "y" becomes "xy". Apparently not a common code construct, since no user ever complained about it.
Long-time users of Cython and NumPy will be happy to hear that Cython's memory views are now API-1.7 clean, which means that they can get rid of the annoying "Using deprecated NumPy API" warnings in the C compiler output. Simply append the C macro definition ("NPY_NO_DEPRECATED_API", "NPY_1_7_API_VERSION") to the macro setup of your distutils extensions in setup.py to make them disappear. Note that this does not apply to the old low-level ndarray[...] syntax, which exposes several deprecated internals of the NumPy C-API that are not easy to replace. Memory views are a fast high-level abstraction that does not rely specifically on NumPy and therefore does not suffer from these API constraints.
Less compilation :)
And finally, as if to make a point that static compilation is a great tool but not always a good idea, we decided to reduce the number of modules that Cython compiles of itself from 13 down to 8, thus keeping 5 more modules normally interpreted by Python. This makes the compiler runs about 5-7% slower, but reduces the packaged size and the installed binary size by about half, thus reducing download times in CI builds and virtualenv creations. Python is a very efficient language when it comes to functionality per line of code, and its byte code is similarly high-level and efficient. Compiled native code is a lot larger and more verbose in comparison, and this can easily make a difference of megabytes of shared libraries versus kilobytes of Python modules.
We therefore repeat our recommendation to focus Cython's usage on the major pain points in your application, on the critical code sections that a profiler has pointed you at. The ability to compile those, and to tune them at the C level, is what makes Cython such a great and versatile tool.
↧
↧
Full Stack Python: How to Provision Ubuntu 18.04 LTS Linux Servers on DigitalOcean
Python web applications need to be deployed to a production server or service so your users have access to the application.
DigitalOcean is one such service that makes it easy to immediately get access to initially free servers which are low cost (~$5 per month depending on the resources) to continue using after the first few months.
In this tutorial we'll learn how to quickly sign up and spin up an Ubuntu-based Linux server that only you will have access to based on a private SSH key.
Obtain Your Virtual Server
These steps sign you up for a DigitalOcean account and guide you through provisioning a virtual private server called a "Droplet" for $5/month which we configure throughout the rest of the book.
Point your web browser to Digitalocean.com's registration page. Note that this link uses a referral code which gives you $100 in free credit. Feel free to just go to digitalocean.com if you do not want to use the referral link (you will not get the $100 in credit though). Their landing page will look something like the following image.
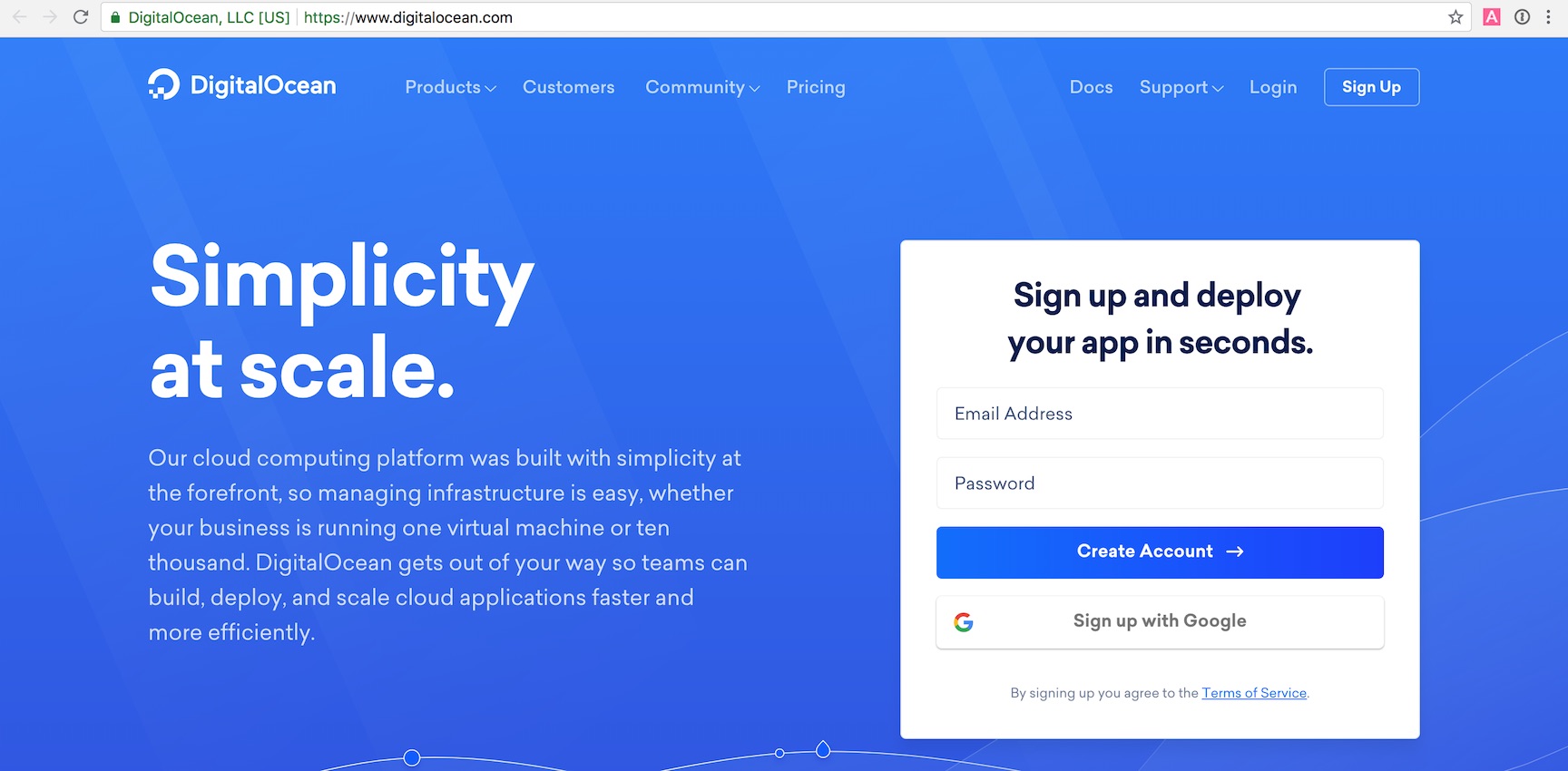
Register for a new DigitalOcean account. Fill out the appropriate information. When your account is registered and active you can create a new DigitalOcean server, which they call "droplets".
After you finish the registration process you will be able to start creating DigitalOcean servers. Select the "Create" button which opens a drop-down menu. Choose "Droplets" to go to the "Create Droplets" page.

The new droplet configuration screen will appear and look like the following image. The default Ubuntu instance is 16.04, but we will use the newer LTS release 18.04 in this book.
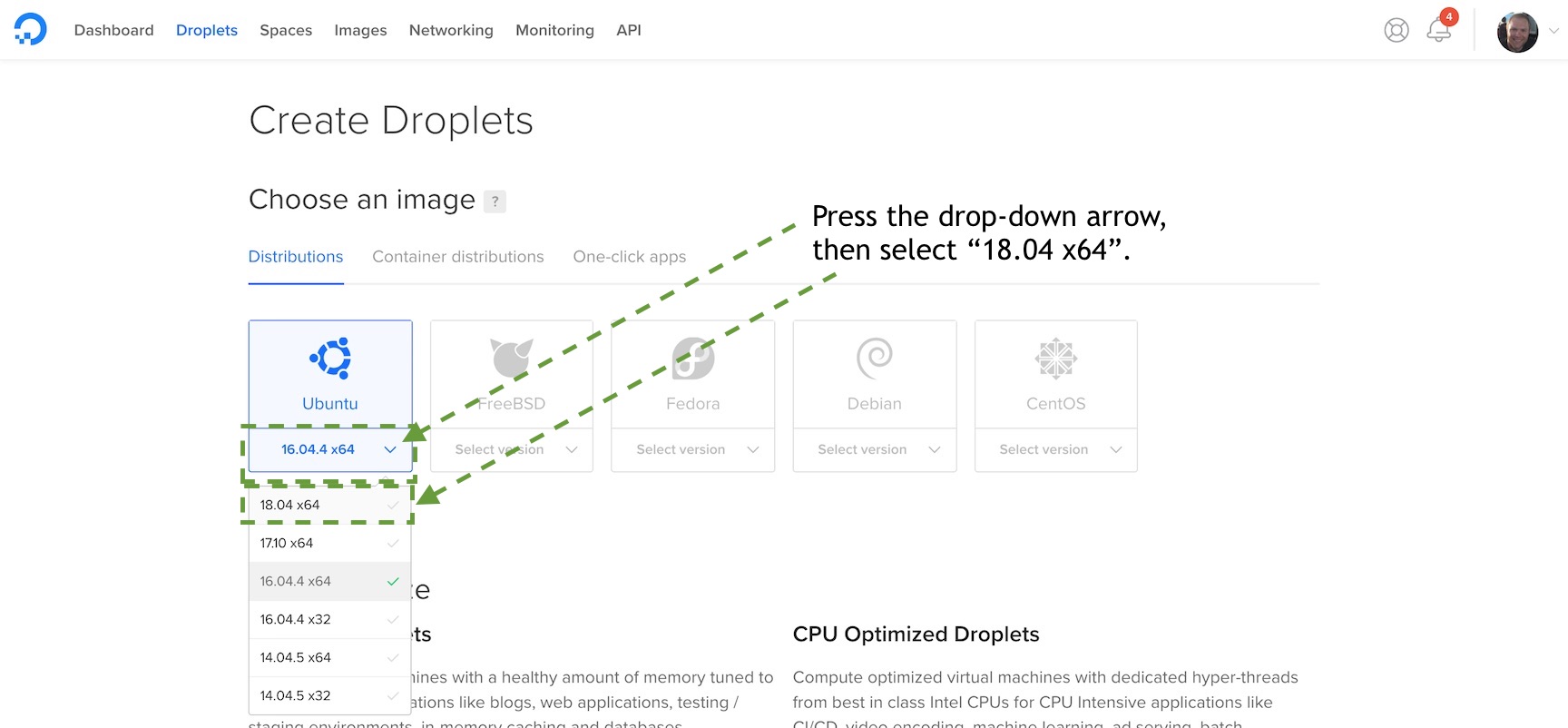
Select the 1 GB memory-sized server for $5 per month. This instance size should be perfect for prototypes, side projects and minimum viable products. Feel free to choose a larger instance size if you want more memory and resources for running your application.
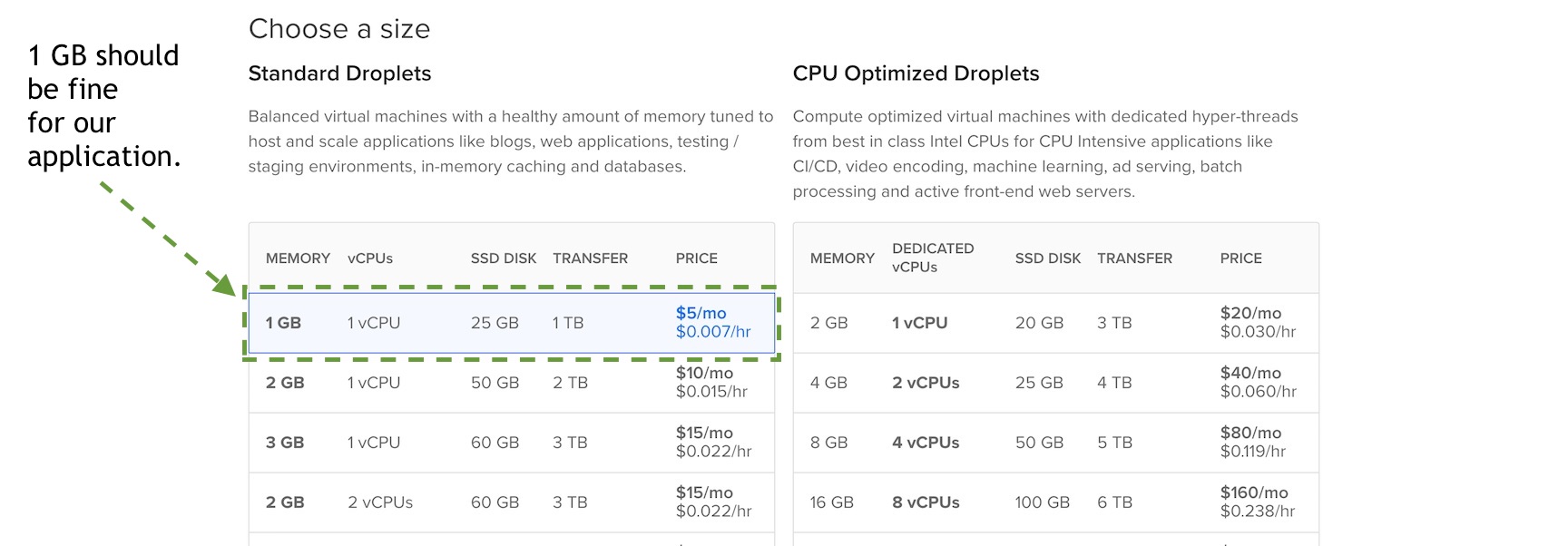
Scroll down and choose the data center region where you want your instance to be located. I typically choose New York because I am on the East Coast of the United Statest in Washington, D.C., and you will want the server to be closest to your users' location.

Next, scroll down and click "New SSH Key". Copy and paste in the contents of your public SSH key. If you do not yet have an SSH key here are a couple of guides that will walk you through creating one:
You can see the contents of a public key using the cat command. For
example on my system the command:
cat root.pub
Outputs the contents of my public key:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQCqAY/Le17HZpa4+eSoh2L9FMYaQ7EnLOGkYbcbsiQNpnF4FTAemF7tbvMvjpVLU6P9AVGs6qEeJdgTE2gH8fq881AUsQ8it1gla2oAlc+vOZmqWPYaLIl5g9DkGwvbITXayobDcw9wTN5tOITOxp3BV5jqanqoqDAPH1RGfT6A5vkJFsmu4w7cPsn9tiqfZZdge3WkpMNT1M3ou+ogrAwE6Ra531s3zYVG9y1688BGdYzbQFfU0+Pou6Z43Do6xbh2hAfQ5hUuTG0OrE3b/yhGcxEWz0Y9+wPGmxm3/0ioTfMWUG3LOQn+oMtKX/PXX/qOJuUjszbqYBvSYS3kv2IVFGV2KEIKC1xgUDfw+HOV4HlIosIbc97zY83m0Ft+tFavPaiQYrar3wCsVfRUltSR4EwNnLmvNYeMVSS8jSP2ZSPwbL8GO7xxAAS9Oy12set1f4OxdPhEUB9rEfAssU1mE6J5eq+Drs8KX04OasLSLt7kP7wWA27I9pU/y9NRHxEsO0YbLG7DzfHGl4QVXwDjIA5GpwjQMwZLt+lyGc4hpnuXg+IUR6MXI90Hh64ch32nSC8j/hjnWCWgj8Cyuc4Rd/2OtO5dHpbjSyU5Yza2lzIqFbFRo7aQNaIkBIioJnc1d6mrg9mLxfd5Ef2ez9bUjqcq4K7uH/JAm0H2Vk1VFQ== matthew.makai@gmail.com
Copy and paste this key into the DigitalOcean modal window and give it a memorable name for future reference:
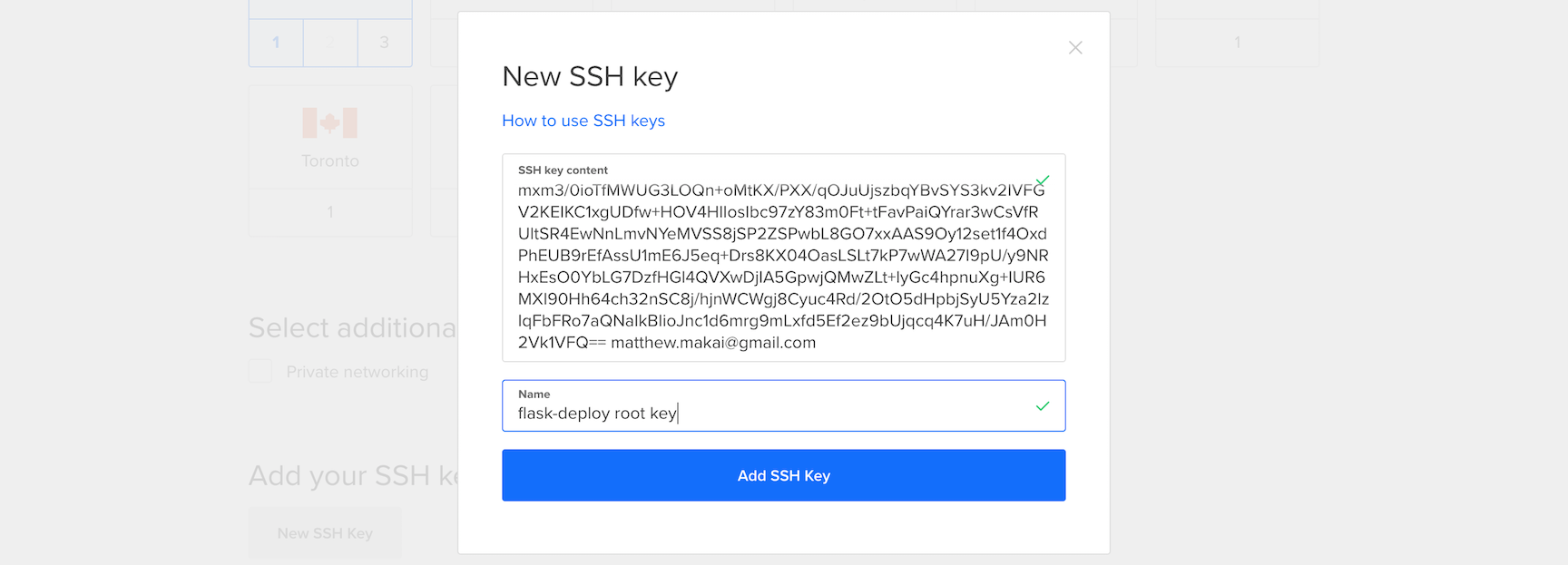
Optionally, give your server a nickname such as flask-deploy-manual.
Then click the big green "Create" button at the bottom of the screen.
The server provisioning process will begin and our Ubuntu Linux 18.04 LTS-powered will soon be ready to go.
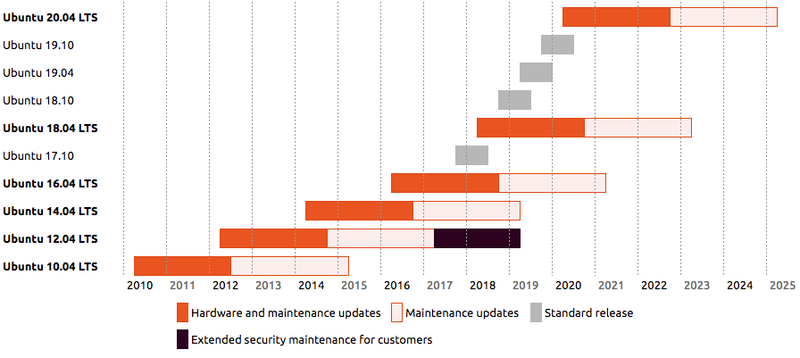
Ubuntu 18.04 is the current Long Term Support (LTS) release and has a 5 year support lifecycle. This version will receive security updates until April 2023 as shown on the Ubuntu release end-of-life page.
You should now be back on the DigitalOcean dashboard.
Our server is now up and ready for SSH access.
Connect to the server using the IP address associated with it:
# make sure to replace 192.168.1.1 with your server's IP address
# and the "private_key" name with the name of your private key
ssh -i ./private_key 192.168.1.1
You should now be connected to your new server and can proceed with development or deployment.
What's Next?
We just stood up a new virtual private server on DigitalOcean that can be used as a production or development environment.
Next up I recommend either configuring the development environment or deploying your application with one of the following tutorials:
- Configure Python 3, Flask and Gunicorn on Ubuntu 18.04 LTS
- How to Make Phone Calls in Python
- 5 ways to deploy your Python web app from PyCon US 2017
You can also figure out what to code next in your Python project by reading the Full Stack Python table of contents page.
Questions? Contact me via Twitter @fullstackpython or @mattmakai. I'm also on GitHub with the username mattmakai.
Something wrong with this post? Fork this page's source on GitHub and submit a pull request.
↧
Codementor: Build a blog using the Django Web Framework.
In this series, we’d walk through the process of building a blog using the Django web framework. Django is a framework written in Python that enables you to build really powerful web applications...
↧
Codementor: Build a blog using the Django Web Framework: Part II
Hello, and welcome to the second part of our series of “Building a blog with Django”. In part one (https://medium.com/@fiveNineDeveloper/build-a-blog-using-django-web-framework-85d063f65887), we...
↧
Codementor: Build a blog using Django web framework: Part III
Hello, and welcome to part three of the “Building a blog using Django” series. In part two, we created a database, but never put it to test by adding real data and seeing what it does. In this...
↧
↧
Podcast.__init__: How Python Is Used To Build A Startup At Wanderu with Chris Kirkos and Matt Warren
The breadth of use cases that Python supports, coupled with the level of productivity that it provides through its ease of use have contributed to the incredible popularity of the language. To explore the ways that it can contribute to the success of a young and growing startup two of the lead engineers at Wanderu discuss their experiences in this episode. Matt Warren, the technical operations lead, explains the ways that he is using Python to build and scale the infrastructure that Wanderu relies on, as well as the ways that he deploys and runs the various Python applications that power the business. Chris Kirkos, the lead software architect, describes how the original Django application has grown into a suite of microservices, where they have opted to use a different language and why, and how Python is still being used for critical business needs. This is a great conversation for understanding the business impact of the Python language and ecosystem.![]()
Summary
The breadth of use cases that Python supports, coupled with the level of productivity that it provides through its ease of use have contributed to the incredible popularity of the language. To explore the ways that it can contribute to the success of a young and growing startup two of the lead engineers at Wanderu discuss their experiences in this episode. Matt Warren, the technical operations lead, explains the ways that he is using Python to build and scale the infrastructure that Wanderu relies on, as well as the ways that he deploys and runs the various Python applications that power the business. Chris Kirkos, the lead software architect, describes how the original Django application has grown into a suite of microservices, where they have opted to use a different language and why, and how Python is still being used for critical business needs. This is a great conversation for understanding the business impact of the Python language and ecosystem.
Preface
- Hello and welcome to Podcast.__init__, the podcast about Python and the people who make it great.
- When you’re ready to launch your next app you’ll need somewhere to deploy it, so check out Linode. With private networking, shared block storage, node balancers, and a 40Gbit network, all controlled by a brand new API you’ve got everything you need to scale up. Go to podcastinit.com/linode to get a $20 credit and launch a new server in under a minute.
- Visit the site to subscribe to the show, sign up for the newsletter, and read the show notes. And if you have any questions, comments, or suggestions I would love to hear them. You can reach me on Twitter at @Podcast__init__ or email hosts@podcastinit.com)
- To help other people find the show please leave a review on iTunes, or Google Play Music, tell your friends and co-workers, and share it on social media.
- Join the community in the new Zulip chat workspace at podcastinit.com/chat
- Your host as usual is Tobias Macey and today I’m interviewing Matt Warren and Chris Kirkos and about the ways that they are using Python at Wanderu
Interview
- Introductions
- How did you get introduced to Python?
- Can you start by describing what Wanderu does?
- How is the platform architected?
- What are the broad categories of problems that you are addressing with Python?
- What are the areas where you chose to use a different language or service?
- What ratio of new projects and features are implemented using Python?
- How much of that decision process is influenced by the fact that you already have so much pre-existing Python code?
- For the projects where you don’t choose Python, what are the reasons for going elsewhere?
- What are some of the limitations of Python that you have encountered while working at Wanderu?
- What are some of the places that you were surprised to find Python in use at Wanderu?
- What have you enjoyed most about working with Python?
- What are some of the sharp edges that you would like to see smoothed over in future versions of the language?
- What is the most challenging bug that you have dealt with at Wanderu that was attributable in some sense to the fact that the code was written in Python?
- If you were to start over today on any of the pieces of the Wanderu platform, are there any that you would write in a different language?
- Which libraries have been the most useful for your work at Wanderu?
- Which ones have caused you the most pain?
Keep In Touch
- Matt
- @matthewwwarren on Twitter
- Chris
Picks
Links
- Wanderu
- Northeastern University
- C++
- Perl
- Microservices
- PostgreSQL
- MongoDB
- Django
- Node.js
- Go-lang
- AWS
- ETL (Extract, Transform, and Load)
- Data Warehouse
- Graph Database
- Twisted
- Gevent
- Scrapy
- Virtualenv
- Ruby
- Rbenv
- Boto3
- PyMongo
- Ansible
- Pip
- TLS
- Cryptography
- Setuptools
- Openstack
- Requests
- PyCountry
- SOAP (Simple Object Access Protocol)
- XML
- Jinja
- OpenSSL
- pytest
- Bandit
- Gang of Four
The intro and outro music is from Requiem for a Fish The Freak Fandango Orchestra / CC BY-SA
↧
Mike Driscoll: PyDev of the Week: Marc Garcia
This week we welcome Marc Garcia (@datapythonista) as our PyDev of the Week! Marc is a core developer of pandas, a Python data analysis library. If you’d like to know more about Marc, you can check out his website which has links to his talks that he has given at PyData in Europe as well as talks at EuroPython.
In fact, here is one of his talks on pandas in case you are interested:
You can also see what projects he is a part of over on Github. Now, let’s take some time to get to know Marc!
Can you tell us a little about yourself (hobbies, education, etc):

My background is in computer engineering, with a master’s degree in AI. I wrote my first program when I was 9, and not many years later I learned about free software, and I still think it’s one of the most amazing achievements of humanity.
I’ve been working professionally with Python for more than 10 years, and this year I became a Python fellow. I’m a pandas core developer, and been involved in the Python community almost since I started coding in Python.

I started as a regular of the Barcelona Python meetup when we were less than 10 members in the events. I contributed to Django before it reached its 1.0. I was one of the founders of PyData Mallorca. I was a NumFOCUS ambassador. I speak regularly to PyCon and PyData conferences. And I organize the London Python Sprints group, where we mentor people who wants to contribute to open source Python projects. Most people know me for leading the pandas documentation sprint, a worldwide event last March, in which around 500 people worked on improving the pandas documentation. Around 300 pull requests were sent, I still need to review and merge some of them. 

Regarding hobbies, I love hiking, travelling, yoga, playing tennis, dancing forro, playing djembe drums, and watching Bollywood movies. I don’t have time to do all that regularly, but hopefully I will at some point.
Why did you start using Python?
I started using Python in 2006. Back then one of the main reasons to use Python was that it was “batteries included”. Not only because of that, but by using Python I was much more productive than using any other language. That was my main reason.
Another thing I really loved since the very beginning was the indentation. Not much before discovering Python I had to work with some legacy php code with no indentation at all. I saw forcing indentation as one of the main Python assets at that time.
After using Python for a while, I quite enjoyed that Python was attracting the top programmers. In 2006, Python was far from being a mainstream language. And not being taught at universities, and rarely used by companies, most Python users at that time were passionate programmers looking for excellence in their spare time. My feeling is that those origins explain why today the Python community is one of the most advanced; not only technically, but in terms of values, diversity, code of conducts…
What other programming languages do you know and which is your favorite?
Since I discovered Python, I rarely used any other language, except some JavaScript (for frontend stuff) or C. Before Python I used a bit of everything, php, java, visual basic… But I’m really happy I haven’t worked with them for more than 10 years now.
My favorite language together with Python is surely C. I think its perfection lies in its simplicity.
What projects are you working on now?
At the moment, outside of work I’m mainly working in pandas. My main focus is on the documentation. Not only that I think it’s really needed, but it also helps me discover parts of the library, besides the ones I use regularly.
Besides the documentation I’m also working on making pandas more efficient when constructing row-based data (like constructing from a generator). Also in making pandas plot with other libraries than matplotlib, like Bokeh. I also like to work on the deprecation and removal of pandas legacy features.
Which Python libraries are your favorite (core or 3rd party)?
Working as a data scientist, pandas and scikit-learn are the libraries I couldn’t live with. Now we give them for granted, but it’s not hard to imagine how much lower the productivity of any data science team would be without them. What if every time you want to use a different model you need to research new libraries, learn new APIs, deal with bugs and lack of documentation, or you just find implementations that are too slow for your data? I often say that the only people doing actual machine learning are scikit-learn developers (and the other required libraries in the ecosystem, numpy, pandas…). The rest of us we just do 10% of the work.
As third-party libraries, Bokeh and Datashader are libraries that I love. They have quite an innovative approach towards visualization. I think they take it to the next level.
And I don’t do much web development nowadays, but I really love Django (I was quite involved in its development many years ago). I really loved it as a software and as a community.
Is there anything else you’d like to say?
I think many times we have the perception that because the software we use is of really high quality, and new releases come often, there is no need to contribute to it. Personally I think that’s far from true.
My feeling is that even if Python has tens of millions of users, if only 20 or 30 key people stop making heroic efforts (in their free time) to improve it (and here I mean the different Python implementations and the most popular libraries), the impact on our future productivity would be huge.
I think many more people should be contributing to the different Python projects. And the many companies saving thousands of dollars in software licenses, and boosting their productivity because of open source software, should consider financing the projects. And of course let their employees contribute to them as part of their job. We take Python and free software for granted, but I don’t think we have the formula to make it sustainable yet.
Another thing I’d like to say, is that I think we all would appreciate having funnier lightning talks. I have the feeling that in the past people took lightning talks less seriously and a lot of crazy stuff was being presented in them (or serious and great projects being presented in a crazy way). I don’t think we want to leave a world to future generations where lightning talks are used to show formulas and code. 
Thanks for doing the interview!
↧
The Digital Cat: Public key cryptography: RSA keys
I bet you created at least once an RSA key pair, usually because you needed to connect to GitHub and you wanted to avoid typing your password every time. You diligently followed the documentation on how to create SSH keys and after a couple of minutes your setup was complete.
But do you know what you actually did?
Do you know what the ~/.ssh/id_rsa file really contains, or why that strange file that begins with ssh-rsa pairs with another that begins with -----BEGIN RSA PRIVATE KEY-----. Or why sometimes that same header misses the RSA part and just says BEGIN PRIVATE KEY?
I think a minimum knowledge of the various formats of RSA keys is mandatory for every developer nowadays, not to mention the importance of understanding them deeply if you want to pursue a career in the infrastructure management world.
RSA algorithm and key pairs¶
Since the invention of public-key cryptography, various systems have been devised to create the key pair. One of the first ones is RSA, the creation of three brilliant cryptographers, that dates back to 1977. The story of RSA is quite interesting, as it was first invented by an English mathematician, Clifford Cocks, who was however forced to keep it secret by the British intelligence office he was working for.
Keeping in mind that RSA is not a synonym for public-key cryptography but only one of the possible implementations, I wanted to write a post on it because it is still, more than 40 years after its publication, one of the most widespread algorithms. In particular it is the standard algorithm used to generate SSH key pairs, and since nowadays every developer has their public key on GitHub, BitBucket, or similar systems, we may arguably say that RSA is pretty ubiquitous.
I will not cover the internals of the RSA algorithm in this article, however. If you are interested in the gory details of the mathematical framework you may find plenty of resources both on Internet and in the textbooks. The theory behind it is not trivial, but it is definitely worth the time if you want to be serious about the mathematical part of cryptography.
In this article I will instead explore two ways to create RSA key pairs and the formats used to store them. Applied cryptography is, like many other topics in computer science, a moving target, and the tools change often. Sometimes it is pretty easy to find out how to do something (StackOverflow helps), but less easy to get a clear picture of what is going on.
All the examples show in this post use a 2048-bits RSA key created for this purpose, so all the numbers you see come from a real example. The key has been obviously trashed after I wrote the article.
The PEM format¶
Let's start the discussion about key pairs with the format used to store them. Nowadays the most widely accepted storage format is called PEM (Privacy-enhanced Electronic Mail). As the name suggests, this format was initially created for e-mail encryption but later became a general format to store cryptographic data like keys and certificates. It is described in RFC 7468 ("Textual Encodings of PKIX, PKCS, and CMS Structures").
An example private key in PEM format is the following
-----BEGIN PRIVATE KEY-----
MIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQCy9f0/nwkXESzk
L4v4ftZ24VJYvkQ/Nt6vsLab3iSWtJXqrRsBythCcbAU6W95OGxjbTSFFtp0poqM
cPuogocMR7QhjY9JGG3fcnJ7nYDCGRHD4zfG5Af/tHwvJ2ew0WTYoemvlfZIG/jZ
7fsuOQSyUpJoxGAlb6/QpnfSmJjxCx0VEoppWDn8CO3VhOgzVhWx0dcne+ZcUy3K
kt3HBQN0hosRfqkVSRTvkpK4RD8TaW5PrVDe1r2Q5ab37TO+Ls4xxt16QlPubNxW
eH3dHVzXdmFAItuH0DuyLyMoW1oxZ6+NrKu+pAAERxM303gejFzKDqXid5m1EOTv
k4xhyqYNAgMBAAECggEBALJCVQAKagOQGCczNTlRHk9MIbpDy7cr8KUQYNThcZCs
UKhxxXUDmGaW1838uA0HJu/i1226Vd/cBCXgZMx1OBADXGoPl6o3qznnxiFbweWV
Ex0MN4LloRITtZ9CoQZ/jPQ8U4mS1r79HeP2KTzhjswRc8Tn1t1zYq1zI+eiGLX/
sPJF63ljJ8yHST7dE0I07V87FKTE2SN0WX9kptPLLBDwzS1X6Z9YyNKPIEnRQzzE
vWdwF60b3RyDz7j7foyP3PC0+3fee4KFdJzt+/1oePf3kwBz8PQq3cuoOF1+0Fzf
yqKiunV2AXI6liAf7MwuZcZeFPZfHTTW7N/j+FQBgAECgYEA4dFjib9u/3rkT2Vx
Bu2ByBpItfs1b4PdSiKehlS9wDZxa72dRt/RSYEyVFBUlYrKXP2nCdl8yMap6SA9
Bfe51F5oWhml9YJn/LF/z1ArMs/tuUyupY7l9j66XzPQmUbIZSEyNEQQ09ZYdIvK
4lbySJbCqa2TQNPIOSZS2o7XNG0CgYEAyuFVybOkVGtfw89MyA1TnVMcQGusXtgo
GOl3tJb59hTO+xF547+/qyK8p/iOu4ybEyeucBEyQt/whmNwtsdngtvVDb4f7psz
Frmqx7q7fPoKnvJsPJds9i2o9B7+BlRY3HwcvKePsctP96pQ0RbOFkCVak6J6t9S
k/qhOiNJ9CECgYEAvDuTMk5tku54g6o2ZiTyir9GHtOwviz3+AUViTn4FdIMB1g+
UsbcqN3V+ywe5ayUdKFHbNFqz92x4k7qLyBJObocWAaLLTQvxBadSE02RRvHuC8w
YXbVP8cYCaWiWzICdzINrD2UnVBN2ZBxZOw+970btN6oIWCnxOOqKt7oip0CgYAp
Fekhp9enoPcL2HdcLBa6zZHzGdsWef/ky6MKV2jXhO9FuQxOKw7NwYMjIRsGsDrX
bjnNSC49jMxQ6uJwoYE85vgGiHI/B/8YoxEK0a4WaSytc7qnqqLOWADXL0+SSJKW
VCwdqHFZOCtBpKQpM80YhIu9s5oKjp9SiHcOJwdbAQKBgDq047hBqyNFFb8KjS5A
+26VOJcC2DRHTprYSRJNxsHTQnONTnUQJl32t0TrqkqIp5lTRr7vBH2wJM6LKk45
I7BWY4mUirC7sDGHl3DaFPRBiut1rpg0kSKi2VNRF7Bb75OKEhGjvm6IKVe8Kl8d
5cpQwm9C7go4OiorY0DVLho2
-----END PRIVATE KEY-----
Basically, you can tell you are dealing with a PEM format from the typical header and footer that identify the content. While the hyphens and the two BEGIN and END words are always present, the PRIVATE KEY part describes the content and can change if the PEM file contains something different from a key, for example an X.509 certificate for SSL.
The PEM format specifies that the the body of the content (the part between the header and the footer) is encoded using Base64.
If the private key has been encrypted with a password the header and the footer are different
-----BEGIN ENCRYPTED PRIVATE KEY-----
MIIFHzBJBgkqhkiG9w0BBQ0wPDAbBgkqhkiG9w0BBQwwDgQIf75rXIakuSICAggA
MB0GCWCGSAFlAwQBKgQQf8HMdJ9FZJjwHkMQjkNA3gSCBNClWB7cJ5f8ThrQtmoA
t2WQCvEWTY9nRYwaTnL1SmXyuMDFrX5CWEuVFh/Zj77KB9jhBJaHw2XtFXxF8bV7
F10u93ih/n0S5QwN9CSPDhRp2kD5lIWB8WVG+VgtncqDrAfJRmpuPmzpjMJBxE2r
MvWJG5beMCS25qD0mAxihtbriqFoCtEygQ7vsSfeQpaBQvT5pKLOVaVgwFTFTf+7
cgqB8/UKKmPXSM4GMJ9VNAvUx0mAxI9MnUFlBWimK76OAzdlO9Si99R8OiRRS10x
AO1AwWSDHGWpbckK0g9K7wLgAgOw8LLVUJh67o9Mfg58DP9Ca0ZdPPVo0C7oavBD
NFlUsKqmSfqfgOAm4qGJ7GB3KgWGFdz+yexNLRLN63hE6qACAuQ1oLmwoorE8toh
MhT3c6IxnVWlYNXJkkb5iV9e8E2X/xzibvwv+CJJ9ulCU8uS7gp0rjlCKFwt/8d4
g3Cef/JWn9nI9YwRLNShJeQOe8hZkkLXHefUhBa2o2++C5C6mgWvuYLK6a0zfCMY
WCqjKKvDQfuxwDbeM03jJ97Je6dXy7rtJvJd10vYvpIVtHnNSdg1evpSiaAmWt4C
X5/AzbHNvwTIEvILfOtYvxLB/RdWqr1/VXuH4dJF6AYtHfQHjXetmL/fDA86Bqf6
Eb+uDr+PPuH4qw1tfJBdTSOOJzhhPqdT4ERYnOvfNxTKzsKYZT+kWvWXe9zyO13W
C0eceVi4rBjKpKpKecKDgFJGZ1u7jS0OW3FDIOfm/osu9z25g5CVIpuWU3JquWib
GatHET9wIEg7LRqC/i65q6tCnd9azevKtiur1I0tuh05iwP5kZ8drIzaGdObuvK1
/pbEPnj1ZcRlAZ34jnG841xvf4vofrOE+hGTNF5HypOCvO/8Lms3aB6NletIvHBE
99ynQyF9TAgSAFAumOws+qnRcnfVOF5lzIEE2pmeMVMqi5s7TT4hlhOuCbyfEFU8
xOXxNazT+0o7urIYOc77vA1LsWrk+9dAfm43CbBZvYav/gMoBc5fsLgAUAm1lkt5
5Hjaf+iMIN0v7aEKDrNDOtyQr13YdyuEClzXxeMtlhU+QfErpQHvH0jE4gywEgz7
tvVGwrbiLgg0y537+kg0/rS3N0eI94GhY0q/nR/QFObbN0nmoIYVVSGtufJx1r9v
YEVZA7HZE9pjnun1ylE1/SoYc/816rjBUcW5CCbkMDIz1LsFPr2SkQeHTNzK3/9J
Kny1lerfA+TA/hUyZ1KJjxuao+rJkH2fJ25qs3r6NP+PPbq3sAl1TPGhMCnNaFdo
YQWDDwz26ZR2ywfsquqLXMwnIEeUI/hQTng9ZxLkJMY22rQSA9nsdvR8S1b0U8Qu
ViYEjCTMWF8HEFFO721MlkTgchzq6fiF+9ZydCpVUJWolcfw1OgUvvTSI7Eyhelb
7fc1fTVFeEMsHrtjpu8dg+IaCNraBzv5QZx6MYW7SSoTVp8mJoPnzYbsZs9nHJGX
iQOFmO/sIryOoeJlpOCGT55yU74yRXrBsYZyLz0P9K1FDQS6l9W33BqmF9vSXujs
kSByq8v1OU0IqidnMmZtTDSRlpQL/oadqQnsA6jiWyMznuUEU8tfgUALE4DKRq8P
wBLKVfMiwcWAbl121M2DCLj9/g==
-----END ENCRYPTED PRIVATE KEY-----
When the PEM format is used to store cryptographic keys the body of the content is in a format called PKCS #8. Initially a standard created by a private company (RSA Laboratories), it became a de facto standard so has been described in various RFCs, most notably RFC 5208 ("Public-Key Cryptography Standards (PKCS) #8: Private-Key Information Syntax Specification Version 1.2").
The PKCS #8 format describes the content using the ASN.1 (Abstract Syntax Notation One) description language and the relative DER (Distinguished Encoding Rules) to serialize the resulting structure. This means that Base64-decoding the content will return some binary content that can be processed only by an ASN.1 parser.
Please not that, due to the structure of the underlying ASN.1 structure, every PEM body starts with the MII characters.
OpenSSL and ASN.1¶
OpenSSL can directly decode a key in PEM format and show the underlying ASN.1 structure with the asn1parse module
$ openssl asn1parse -inform pem -in private.pem
0:d=0hl=4l=1214 cons: SEQUENCE
4:d=1hl=2l=1 prim: INTEGER :00
7:d=1hl=2l=13 cons: SEQUENCE
9:d=2hl=2l=9 prim: OBJECT :rsaEncryption
20:d=2hl=2l=0 prim: NULL
22:d=1hl=4l=1192 prim: OCTET STRING [HEX DUMP]:308204A40201000282010100B2F5FD3F9F0917112
CE42F8BF87ED676E15258BE443F36DEAFB0B69BDE2496B495EAAD1B01CAD84271B014E96F79386C636D348516DA74A68
A8C70FBA882870C47B4218D8F49186DDF72727B9D80C21911C3E337C6E407FFB47C2F2767B0D164D8A1E9AF95F6481BF
8D9EDFB2E3904B2529268C460256FAFD0A677D29898F10B1D15128A695839FC08EDD584E8335615B1D1D7277BE65C532
DCA92DDC7050374868B117EA9154914EF9292B8443F13696E4FAD50DED6BD90E5A6F7ED33BE2ECE31C6DD7A4253EE6CD
C56787DDD1D5CD776614022DB87D03BB22F23285B5A3167AF8DACABBEA40004471337D3781E8C5CCA0EA5E27799B510E
4EF938C61CAA60D02030100010282010100B24255000A6A03901827333539511E4F4C21BA43CBB72BF0A51060D4E1719
0AC50A871C57503986696D7CDFCB80D0726EFE2D76DBA55DFDC0425E064CC753810035C6A0F97AA37AB39E7C6215BC1E
595131D0C3782E5A11213B59F42A1067F8CF43C538992D6BEFD1DE3F6293CE18ECC1173C4E7D6DD7362AD7323E7A218B
5FFB0F245EB796327CC87493EDD134234ED5F3B14A4C4D92374597F64A6D3CB2C10F0CD2D57E99F58C8D28F2049D1433
CC4BD677017AD1BDD1C83CFB8FB7E8C8FDCF0B4FB77DE7B8285749CEDFBFD6878F7F7930073F0F42ADDCBA8385D7ED05
CDFCAA2A2BA757601723A96201FECCC2E65C65E14F65F1D34D6ECDFE3F85401800102818100E1D16389BF6EFF7AE44F6
57106ED81C81A48B5FB356F83DD4A229E8654BDC036716BBD9D46DFD1498132545054958ACA5CFDA709D97CC8C6A9E92
03D05F7B9D45E685A19A5F58267FCB17FCF502B32CFEDB94CAEA58EE5F63EBA5F33D09946C8652132344410D3D658748
BCAE256F24896C2A9AD9340D3C8392652DA8ED7346D02818100CAE155C9B3A4546B5FC3CF4CC80D539D531C406BAC5ED
82818E977B496F9F614CEFB1179E3BFBFAB22BCA7F88EBB8C9B1327AE70113242DFF0866370B6C76782DBD50DBE1FEE9
B3316B9AAC7BABB7CFA0A9EF26C3C976CF62DA8F41EFE065458DC7C1CBCA78FB1CB4FF7AA50D116CE1640956A4E89EAD
F5293FAA13A2349F42102818100BC3B93324E6D92EE7883AA366624F28ABF461ED3B0BE2CF7F805158939F815D20C075
83E52C6DCA8DDD5FB2C1EE5AC9474A1476CD16ACFDDB1E24EEA2F204939BA1C58068B2D342FC4169D484D36451BC7B82
F306176D53FC71809A5A25B320277320DAC3D949D504DD9907164EC3EF7BD1BB4DEA82160A7C4E3AA2ADEE88A9D02818
02915E921A7D7A7A0F70BD8775C2C16BACD91F319DB1679FFE4CBA30A5768D784EF45B90C4E2B0ECDC18323211B06B03
AD76E39CD482E3D8CCC50EAE270A1813CE6F80688723F07FF18A3110AD1AE16692CAD73BAA7AAA2CE5800D72F4F92489
296542C1DA87159382B41A4A42933CD18848BBDB39A0A8E9F5288770E27075B010281803AB4E3B841AB234515BF0A8D2
E40FB6E95389702D834474E9AD849124DC6C1D342738D4E7510265DF6B744EBAA4A88A7995346BEEF047DB024CE8B2A4
E3923B0566389948AB0BBB031879770DA14F4418AEB75AE98349122A2D9535117B05BEF938A1211A3BE6E882957BC2A5
F1DE5CA50C26F42EE0A383A2A2B6340D52E1A36
Note that the ASN.1 structure contains the type of the object (rsaEncryption, in this case). You can further decode the OCTET STRING field, which is the actual key, specifying the offset
$ openssl asn1parse -inform pem -in private.pem -strparse 220:d=0hl=4l=1188 cons: SEQUENCE
4:d=1hl=2l=1 prim: INTEGER :00
7:d=1hl=4l=257 prim: INTEGER :B2F5FD3F9F0917112CE42F8BF87ED676E15258BE443F36DEAFB
0B69BDE2496B495EAAD1B01CAD84271B014E96F79386C636D348516DA74A68A8C70FBA882870C47B4218D8F49186DDF
72727B9D80C21911C3E337C6E407FFB47C2F2767B0D164D8A1E9AF95F6481BF8D9EDFB2E3904B2529268C460256FAFD
0A677D29898F10B1D15128A695839FC08EDD584E8335615B1D1D7277BE65C532DCA92DDC7050374868B117EA9154914
EF9292B8443F13696E4FAD50DED6BD90E5A6F7ED33BE2ECE31C6DD7A4253EE6CDC56787DDD1D5CD776614022DB87D03
BB22F23285B5A3167AF8DACABBEA40004471337D3781E8C5CCA0EA5E27799B510E4EF938C61CAA60D
268:d=1hl=2l=3 prim: INTEGER :010001
273:d=1hl=4l=257 prim: INTEGER :B24255000A6A03901827333539511E4F4C21BA43CBB72BF0A51
060D4E17190AC50A871C57503986696D7CDFCB80D0726EFE2D76DBA55DFDC0425E064CC753810035C6A0F97AA37AB39
E7C6215BC1E595131D0C3782E5A11213B59F42A1067F8CF43C538992D6BEFD1DE3F6293CE18ECC1173C4E7D6DD7362A
D7323E7A218B5FFB0F245EB796327CC87493EDD134234ED5F3B14A4C4D92374597F64A6D3CB2C10F0CD2D57E99F58C8
D28F2049D1433CC4BD677017AD1BDD1C83CFB8FB7E8C8FDCF0B4FB77DE7B8285749CEDFBFD6878F7F7930073F0F42AD
DCBA8385D7ED05CDFCAA2A2BA757601723A96201FECCC2E65C65E14F65F1D34D6ECDFE3F854018001
534:d=1hl=3l=129 prim: INTEGER :E1D16389BF6EFF7AE44F657106ED81C81A48B5FB356F83DD4A2
29E8654BDC036716BBD9D46DFD1498132545054958ACA5CFDA709D97CC8C6A9E9203D05F7B9D45E685A19A5F58267FC
B17FCF502B32CFEDB94CAEA58EE5F63EBA5F33D09946C8652132344410D3D658748BCAE256F24896C2A9AD9340D3C83
92652DA8ED7346D
666:d=1hl=3l=129 prim: INTEGER :CAE155C9B3A4546B5FC3CF4CC80D539D531C406BAC5ED82818E
977B496F9F614CEFB1179E3BFBFAB22BCA7F88EBB8C9B1327AE70113242DFF0866370B6C76782DBD50DBE1FEE9B3316
B9AAC7BABB7CFA0A9EF26C3C976CF62DA8F41EFE065458DC7C1CBCA78FB1CB4FF7AA50D116CE1640956A4E89EADF529
3FAA13A2349F421
798:d=1hl=3l=129 prim: INTEGER :BC3B93324E6D92EE7883AA366624F28ABF461ED3B0BE2CF7F80
5158939F815D20C07583E52C6DCA8DDD5FB2C1EE5AC9474A1476CD16ACFDDB1E24EEA2F204939BA1C58068B2D342FC4
169D484D36451BC7B82F306176D53FC71809A5A25B320277320DAC3D949D504DD9907164EC3EF7BD1BB4DEA82160A7C
4E3AA2ADEE88A9D
930:d=1hl=3l=128 prim: INTEGER :2915E921A7D7A7A0F70BD8775C2C16BACD91F319DB1679FFE4C
BA30A5768D784EF45B90C4E2B0ECDC18323211B06B03AD76E39CD482E3D8CCC50EAE270A1813CE6F80688723F07FF18
A3110AD1AE16692CAD73BAA7AAA2CE5800D72F4F92489296542C1DA87159382B41A4A42933CD18848BBDB39A0A8E9F5
288770E27075B01
1061:d=1hl=3l=128 prim: INTEGER :3AB4E3B841AB234515BF0A8D2E40FB6E95389702D834474E9AD8
49124DC6C1D342738D4E7510265DF6B744EBAA4A88A7995346BEEF047DB024CE8B2A4E3923B0566389948AB0BBB0318
79770DA14F4418AEB75AE98349122A2D9535117B05BEF938A1211A3BE6E882957BC2A5F1DE5CA50C26F42EE0A383A2A
2B6340D52E1A36
Being this an RSA key the fields represent specific components of the algorithm. We find in order the modulus n = pq, the public exponent e, the private exponent d, the two prime numbers p and q, and the values d_p, d_q, and q_inv (for the Chinese remainder theorem speed-up).
If the key has been encrypted there are fields with information about the cipher, and the OCTET STRING fields cannot be further parsed because of the encryption.
$ openssl asn1parse -inform pem -in private-enc.pem
0:d=0hl=4l=1311 cons: SEQUENCE
4:d=1hl=2l=73 cons: SEQUENCE
6:d=2hl=2l=9 prim: OBJECT :PBES2
17:d=2hl=2l=60 cons: SEQUENCE
19:d=3hl=2l=27 cons: SEQUENCE
21:d=4hl=2l=9 prim: OBJECT :PBKDF2
32:d=4hl=2l=14 cons: SEQUENCE
34:d=5hl=2l=8 prim: OCTET STRING [HEX DUMP]:7FBE6B5C86A4B922
44:d=5hl=2l=2 prim: INTEGER :0800
48:d=3hl=2l=29 cons: SEQUENCE
50:d=4hl=2l=9 prim: OBJECT :aes-256-cbc
61:d=4hl=2l=16 prim: OCTET STRING [HEX DUMP]:7FC1CC749F456498F01E43108E4340DE
79:d=1hl=4l=1232 prim: OCTET STRING [HEX DUMP]:A5581EDC2797FC4E1AD0B66A00B765900AF1164D8
F67458C1A4E72F54A65F2B8C0C5AD7E42584B95161FD98FBECA07D8E1049687C365ED157C45F1B57B175D2EF778A1FE7
D12E50C0DF4248F0E1469DA40F9948581F16546F9582D9DCA83AC07C9466A6E3E6CE98CC241C44DAB32F5891B96DE302
4B6E6A0F4980C6286D6EB8AA1680AD132810EEFB127DE42968142F4F9A4A2CE55A560C054C54DFFBB720A81F3F50A2A6
3D748CE06309F55340BD4C74980C48F4C9D41650568A62BBE8E0337653BD4A2F7D47C3A24514B5D3100ED40C164831C6
5A96DC90AD20F4AEF02E00203B0F0B2D550987AEE8F4C7E0E7C0CFF426B465D3CF568D02EE86AF043345954B0AAA649F
A9F80E026E2A189EC60772A058615DCFEC9EC4D2D12CDEB7844EAA00202E435A0B9B0A28AC4F2DA213214F773A2319D5
5A560D5C99246F9895F5EF04D97FF1CE26EFC2FF82249F6E94253CB92EE0A74AE3942285C2DFFC77883709E7FF2569FD
9C8F58C112CD4A125E40E7BC8599242D71DE7D48416B6A36FBE0B90BA9A05AFB982CAE9AD337C2318582AA328ABC341F
BB1C036DE334DE327DEC97BA757CBBAED26F25DD74BD8BE9215B479CD49D8357AFA5289A0265ADE025F9FC0CDB1CDBF0
4C812F20B7CEB58BF12C1FD1756AABD7F557B87E1D245E8062D1DF4078D77AD98BFDF0C0F3A06A7FA11BFAE0EBF8F3EE
1F8AB0D6D7C905D4D238E2738613EA753E044589CEBDF3714CACEC298653FA45AF5977BDCF23B5DD60B479C7958B8AC1
8CAA4AA4A79C283805246675BBB8D2D0E5B714320E7E6FE8B2EF73DB9839095229B9653726AB9689B19AB47113F70204
83B2D1A82FE2EB9ABAB429DDF5ACDEBCAB62BABD48D2DBA1D398B03F9919F1DAC8CDA19D39BBAF2B5FE96C43E78F565C
465019DF88E71BCE35C6F7F8BE87EB384FA1193345E47CA9382BCEFFC2E6B37681E8D95EB48BC7044F7DCA743217D4C0
81200502E98EC2CFAA9D17277D5385E65CC8104DA999E31532A8B9B3B4D3E219613AE09BC9F10553CC4E5F135ACD3FB4
A3BBAB21839CEFBBC0D4BB16AE4FBD7407E6E3709B059BD86AFFE032805CE5FB0B8005009B5964B79E478DA7FE88C20D
D2FEDA10A0EB3433ADC90AF5DD8772B840A5CD7C5E32D96153E41F12BA501EF1F48C4E20CB0120CFBB6F546C2B6E22E0
834CB9DFBFA4834FEB4B7374788F781A1634ABF9D1FD014E6DB3749E6A086155521ADB9F271D6BF6F60455903B1D913D
A639EE9F5CA5135FD2A1873FF35EAB8C151C5B90826E4303233D4BB053EBD929107874CDCCADFFF492A7CB595EADF03E
4C0FE15326752898F1B9AA3EAC9907D9F276E6AB37AFA34FF8F3DBAB7B009754CF1A13029CD6857686105830F0CF6E99
476CB07ECAAEA8B5CCC2720479423F8504E783D6712E424C636DAB41203D9EC76F47C4B56F453C42E5626048C24CC585
F0710514EEF6D4C9644E0721CEAE9F885FBD672742A555095A895C7F0D4E814BEF4D223B13285E95BEDF7357D3545784
32C1EBB63A6EF1D83E21A08DADA073BF9419C7A3185BB492A13569F262683E7CD86EC66CF671C919789038598EFEC22B
C8EA1E265A4E0864F9E7253BE32457AC1B186722F3D0FF4AD450D04BA97D5B7DC1AA617DBD25EE8EC912072ABCBF5394
D08AA276732666D4C349196940BFE869DA909EC03A8E25B23339EE50453CB5F81400B1380CA46AF0FC012CA55F322C1C
5806E5D76D4CD8308B8FDFE
OpenSSL and RSA keys¶
Another way to look into a private key with OpenSSL is to use the rsa module. While the asn1parse module is a generic ASN.1 parser, the rsa module knows the structure of an RSA key and can properly output the field names
$ openssl rsa -in private.pem -noout -text
Private-Key: (2048 bit)
modulus:
00:b2:f5:fd:3f:9f:09:17:11:2c:e4:2f:8b:f8:7e:
d6:76:e1:52:58:be:44:3f:36:de:af:b0:b6:9b:de:
24:96:b4:95:ea:ad:1b:01:ca:d8:42:71:b0:14:e9:
6f:79:38:6c:63:6d:34:85:16:da:74:a6:8a:8c:70:
fb:a8:82:87:0c:47:b4:21:8d:8f:49:18:6d:df:72:
72:7b:9d:80:c2:19:11:c3:e3:37:c6:e4:07:ff:b4:
7c:2f:27:67:b0:d1:64:d8:a1:e9:af:95:f6:48:1b:
f8:d9:ed:fb:2e:39:04:b2:52:92:68:c4:60:25:6f:
af:d0:a6:77:d2:98:98:f1:0b:1d:15:12:8a:69:58:
39:fc:08:ed:d5:84:e8:33:56:15:b1:d1:d7:27:7b:
e6:5c:53:2d:ca:92:dd:c7:05:03:74:86:8b:11:7e:
a9:15:49:14:ef:92:92:b8:44:3f:13:69:6e:4f:ad:
50:de:d6:bd:90:e5:a6:f7:ed:33:be:2e:ce:31:c6:
dd:7a:42:53:ee:6c:dc:56:78:7d:dd:1d:5c:d7:76:
61:40:22:db:87:d0:3b:b2:2f:23:28:5b:5a:31:67:
af:8d:ac:ab:be:a4:00:04:47:13:37:d3:78:1e:8c:
5c:ca:0e:a5:e2:77:99:b5:10:e4:ef:93:8c:61:ca:
a6:0d
publicExponent: 65537(0x10001)
privateExponent:
00:b2:42:55:00:0a:6a:03:90:18:27:33:35:39:51:
1e:4f:4c:21:ba:43:cb:b7:2b:f0:a5:10:60:d4:e1:
71:90:ac:50:a8:71:c5:75:03:98:66:96:d7:cd:fc:
b8:0d:07:26:ef:e2:d7:6d:ba:55:df:dc:04:25:e0:
64:cc:75:38:10:03:5c:6a:0f:97:aa:37:ab:39:e7:
c6:21:5b:c1:e5:95:13:1d:0c:37:82:e5:a1:12:13:
b5:9f:42:a1:06:7f:8c:f4:3c:53:89:92:d6:be:fd:
1d:e3:f6:29:3c:e1:8e:cc:11:73:c4:e7:d6:dd:73:
62:ad:73:23:e7:a2:18:b5:ff:b0:f2:45:eb:79:63:
27:cc:87:49:3e:dd:13:42:34:ed:5f:3b:14:a4:c4:
d9:23:74:59:7f:64:a6:d3:cb:2c:10:f0:cd:2d:57:
e9:9f:58:c8:d2:8f:20:49:d1:43:3c:c4:bd:67:70:
17:ad:1b:dd:1c:83:cf:b8:fb:7e:8c:8f:dc:f0:b4:
fb:77:de:7b:82:85:74:9c:ed:fb:fd:68:78:f7:f7:
93:00:73:f0:f4:2a:dd:cb:a8:38:5d:7e:d0:5c:df:
ca:a2:a2:ba:75:76:01:72:3a:96:20:1f:ec:cc:2e:
65:c6:5e:14:f6:5f:1d:34:d6:ec:df:e3:f8:54:01:
80:01
prime1:
00:e1:d1:63:89:bf:6e:ff:7a:e4:4f:65:71:06:ed:
81:c8:1a:48:b5:fb:35:6f:83:dd:4a:22:9e:86:54:
bd:c0:36:71:6b:bd:9d:46:df:d1:49:81:32:54:50:
54:95:8a:ca:5c:fd:a7:09:d9:7c:c8:c6:a9:e9:20:
3d:05:f7:b9:d4:5e:68:5a:19:a5:f5:82:67:fc:b1:
7f:cf:50:2b:32:cf:ed:b9:4c:ae:a5:8e:e5:f6:3e:
ba:5f:33:d0:99:46:c8:65:21:32:34:44:10:d3:d6:
58:74:8b:ca:e2:56:f2:48:96:c2:a9:ad:93:40:d3:
c8:39:26:52:da:8e:d7:34:6d
prime2:
00:ca:e1:55:c9:b3:a4:54:6b:5f:c3:cf:4c:c8:0d:
53:9d:53:1c:40:6b:ac:5e:d8:28:18:e9:77:b4:96:
f9:f6:14:ce:fb:11:79:e3:bf:bf:ab:22:bc:a7:f8:
8e:bb:8c:9b:13:27:ae:70:11:32:42:df:f0:86:63:
70:b6:c7:67:82:db:d5:0d:be:1f:ee:9b:33:16:b9:
aa:c7:ba:bb:7c:fa:0a:9e:f2:6c:3c:97:6c:f6:2d:
a8:f4:1e:fe:06:54:58:dc:7c:1c:bc:a7:8f:b1:cb:
4f:f7:aa:50:d1:16:ce:16:40:95:6a:4e:89:ea:df:
52:93:fa:a1:3a:23:49:f4:21
exponent1:
00:bc:3b:93:32:4e:6d:92:ee:78:83:aa:36:66:24:
f2:8a:bf:46:1e:d3:b0:be:2c:f7:f8:05:15:89:39:
f8:15:d2:0c:07:58:3e:52:c6:dc:a8:dd:d5:fb:2c:
1e:e5:ac:94:74:a1:47:6c:d1:6a:cf:dd:b1:e2:4e:
ea:2f:20:49:39:ba:1c:58:06:8b:2d:34:2f:c4:16:
9d:48:4d:36:45:1b:c7:b8:2f:30:61:76:d5:3f:c7:
18:09:a5:a2:5b:32:02:77:32:0d:ac:3d:94:9d:50:
4d:d9:90:71:64:ec:3e:f7:bd:1b:b4:de:a8:21:60:
a7:c4:e3:aa:2a:de:e8:8a:9d
exponent2:
29:15:e9:21:a7:d7:a7:a0:f7:0b:d8:77:5c:2c:16:
ba:cd:91:f3:19:db:16:79:ff:e4:cb:a3:0a:57:68:
d7:84:ef:45:b9:0c:4e:2b:0e:cd:c1:83:23:21:1b:
06:b0:3a:d7:6e:39:cd:48:2e:3d:8c:cc:50:ea:e2:
70:a1:81:3c:e6:f8:06:88:72:3f:07:ff:18:a3:11:
0a:d1:ae:16:69:2c:ad:73:ba:a7:aa:a2:ce:58:00:
d7:2f:4f:92:48:92:96:54:2c:1d:a8:71:59:38:2b:
41:a4:a4:29:33:cd:18:84:8b:bd:b3:9a:0a:8e:9f:
52:88:77:0e:27:07:5b:01
coefficient:
3a:b4:e3:b8:41:ab:23:45:15:bf:0a:8d:2e:40:fb:
6e:95:38:97:02:d8:34:47:4e:9a:d8:49:12:4d:c6:
c1:d3:42:73:8d:4e:75:10:26:5d:f6:b7:44:eb:aa:
4a:88:a7:99:53:46:be:ef:04:7d:b0:24:ce:8b:2a:
4e:39:23:b0:56:63:89:94:8a:b0:bb:b0:31:87:97:
70:da:14:f4:41:8a:eb:75:ae:98:34:91:22:a2:d9:
53:51:17:b0:5b:ef:93:8a:12:11:a3:be:6e:88:29:
57:bc:2a:5f:1d:e5:ca:50:c2:6f:42:ee:0a:38:3a:
2a:2b:63:40:d5:2e:1a:36
The fields are the same we found in the ASN.1 structure, this being only a different representation of the same data. You can compare the two and see that the value of the fields are the same.
PKCS #8 vs PKCS #1¶
The first version of the PKCS standard (PKCS #1) was specifically tailored to contain an RSA key. Its ASN.1 definition can be found in RFC 8017 ("PKCS #1: RSA Cryptography Specifications Version 2.2")
RSAPublicKey ::= SEQUENCE {
modulus INTEGER, -- n
publicExponent INTEGER -- e
}
RSAPrivateKey ::= SEQUENCE {
version Version,
modulus INTEGER, -- n
publicExponent INTEGER, -- e
privateExponent INTEGER, -- d
prime1 INTEGER, -- p
prime2 INTEGER, -- q
exponent1 INTEGER, -- d mod (p-1)
exponent2 INTEGER, -- d mod (q-1)
coefficient INTEGER, -- (inverse of q) mod p
otherPrimeInfos OtherPrimeInfos OPTIONAL
}
Subsequently, as the need to describe new types of algorithms increased, the PKCS #8 standard was developed. This can contain different types of keys, and defines a specific field for the algorithm identifier. Its ASN.1 definition can be found in RFC 5958 ("Asymmetric Key Packages")
OneAsymmetricKey ::= SEQUENCE {
version Version,
privateKeyAlgorithm PrivateKeyAlgorithmIdentifier,
privateKey PrivateKey,
attributes [0] Attributes OPTIONAL,
...,
[[2: publicKey [1] PublicKey OPTIONAL ]],
...
}
PrivateKey ::= OCTET STRING
-- Content varies based on type of key. The
-- algorithm identifier dictates the format of
-- the key.
The definition of the PrivateKey field for the RSA algorithm is the same used in PKCS #1.
If the PEM format uses PKCS #8 its header and footer are
-----BEGIN PRIVATE KEY-----
[...]
-----END PRIVATE KEY-----
If it uses PKCS #1, however, there has to be an external identification of the algorithm, so the header and footer are
-----BEGIN RSA PRIVATE KEY-----
[...]
-----END RSA PRIVATE KEY-----
The structure of PKCS #8 is the reason why previously we had to parse the field at offset 22 to access the RSA parameters. If you are parsing a PKCS #1 key in PEM format you don't need this second step.
Private and public key¶
In the RSA algorithm the public key is made by the modulus and the public exponent, which means that we can derive the public key from the private key. OpenSSL can easily do this with the rsa module, producing the public key in PEM format
$ openssl rsa -in private.pem -pubout
writing RSA key
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsvX9P58JFxEs5C+L+H7W
duFSWL5EPzber7C2m94klrSV6q0bAcrYQnGwFOlveThsY200hRbadKaKjHD7qIKH
DEe0IY2PSRht33Jye52AwhkRw+M3xuQH/7R8LydnsNFk2KHpr5X2SBv42e37LjkE
slKSaMRgJW+v0KZ30piY8QsdFRKKaVg5/Ajt1YToM1YVsdHXJ3vmXFMtypLdxwUD
dIaLEX6pFUkU75KSuEQ/E2luT61Q3ta9kOWm9+0zvi7OMcbdekJT7mzcVnh93R1c
13ZhQCLbh9A7si8jKFtaMWevjayrvqQABEcTN9N4Hoxcyg6l4neZtRDk75OMYcqm
DQIDAQAB
-----END PUBLIC KEY-----
You can dump the information in the public key specifying the -pubin flag
$ openssl rsa -in public.pem -noout -text -pubin
Public-Key: (2048 bit)
Modulus:
00:b2:f5:fd:3f:9f:09:17:11:2c:e4:2f:8b:f8:7e:
d6:76:e1:52:58:be:44:3f:36:de:af:b0:b6:9b:de:
24:96:b4:95:ea:ad:1b:01:ca:d8:42:71:b0:14:e9:
6f:79:38:6c:63:6d:34:85:16:da:74:a6:8a:8c:70:
fb:a8:82:87:0c:47:b4:21:8d:8f:49:18:6d:df:72:
72:7b:9d:80:c2:19:11:c3:e3:37:c6:e4:07:ff:b4:
7c:2f:27:67:b0:d1:64:d8:a1:e9:af:95:f6:48:1b:
f8:d9:ed:fb:2e:39:04:b2:52:92:68:c4:60:25:6f:
af:d0:a6:77:d2:98:98:f1:0b:1d:15:12:8a:69:58:
39:fc:08:ed:d5:84:e8:33:56:15:b1:d1:d7:27:7b:
e6:5c:53:2d:ca:92:dd:c7:05:03:74:86:8b:11:7e:
a9:15:49:14:ef:92:92:b8:44:3f:13:69:6e:4f:ad:
50:de:d6:bd:90:e5:a6:f7:ed:33:be:2e:ce:31:c6:
dd:7a:42:53:ee:6c:dc:56:78:7d:dd:1d:5c:d7:76:
61:40:22:db:87:d0:3b:b2:2f:23:28:5b:5a:31:67:
af:8d:ac:ab:be:a4:00:04:47:13:37:d3:78:1e:8c:
5c:ca:0e:a5:e2:77:99:b5:10:e4:ef:93:8c:61:ca:
a6:0d
Exponent: 65537(0x10001)Generating key pairs with OpenSSL¶
If you want to generate an RSA private key you can do it with OpenSSL
$ openssl genpkey -algorithm RSA -out key.pem -pkeyopt rsa_keygen_bits:2048
......................................................................+++
..........+++
If you want an encrypted key you can generate one specifying the cipher (for example -aes-256-cbc)
$ openssl genpkey -algorithm RSA -out private-enc.pem -aes-256-cbc -pkeyopt rsa_keygen_bits:2048
...........................+++
..........+++
Enter PEM pass phrase:
Verifying - Enter PEM pass phrase:
You can see the list of supported ciphers with openssl list-cipher-algorithms. In both cases you can then extract the public key with the method shown previously.
Generating key pairs with OpenSSH¶
Another tool that you can use to generate key pairs is ssh-keygen, which is a tool included in the SSH suite that is specifically used to create and manage SSH keys. As SSH keys are standard asymmetrical keys we can use the tool to create keys for other purposes.
To create a key pair just run
ssh-keygen -t rsa -b 2048 -f private
The -t option specifies the key generation algorithm (RSA in this case), while the -b option specifies the length of the key in bits.
The -f option sets the name of the output file. If not present, ssh-keygen will ask the name of the file, offering to save it to the default file ~/.ssh/id_rsa. ssh-keygen always asks for a password to encrypt the key, but you are allowed to enter an empty one to skip the encryption.
This tool creates two files. One is the private key file, named as requested, and the second is the public key file, named like the private key one but with a .pub extension.
OpenSSH private keys are generated using the PKCS #1 format, so the key will be in the form
-----BEGIN RSA PRIVATE KEY-----
[...]
-----END RSA PRIVATE KEY-----
The OpenSSH public key format¶
The public key saved by ssh-keygen is written in the so-called SSH-format, which is not a standard in the cryptography world. It's structure is <algorithm> <key> <comment>, where the <key> part of the format is encoded with Base64.
For example
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCy9f0/nwkXESzkL4v4ftZ24VJYvkQ/Nt6vsLab3iSWtJXqrRsBythCcbAU6W9
5OGxjbTSFFtp0poqMcPuogocMR7QhjY9JGG3fcnJ7nYDCGRHD4zfG5Af/tHwvJ2ew0WTYoemvlfZIG/jZ7fsuOQSyUpJoxGAlb6
/QpnfSmJjxCx0VEoppWDn8CO3VhOgzVhWx0dcne+ZcUy3Kkt3HBQN0hosRfqkVSRTvkpK4RD8TaW5PrVDe1r2Q5ab37TO+Ls4xx
t16QlPubNxWeH3dHVzXdmFAItuH0DuyLyMoW1oxZ6+NrKu+pAAERxM303gejFzKDqXid5m1EOTvk4xhyqYN user@host
To manually decode the central part of the key you can run the following code
cat key.pub | cut -d " " -f2 | base64 -d | hexdump -ve '/1 "%02x "' -e '2/8 "\n"'which in the previous case outputs something like
00 00 00 07 73 73 68 2d 72 73 61 00 00 00 03 01
00 01 00 00 01 01 00 b2 f5 fd 3f 9f 09 17 11 2c
e4 2f 8b f8 7e d6 76 e1 52 58 be 44 3f 36 de af
b0 b6 9b de 24 96 b4 95 ea ad 1b 01 ca d8 42 71
b0 14 e9 6f 79 38 6c 63 6d 34 85 16 da 74 a6 8a
8c 70 fb a8 82 87 0c 47 b4 21 8d 8f 49 18 6d df
72 72 7b 9d 80 c2 19 11 c3 e3 37 c6 e4 07 ff b4
7c 2f 27 67 b0 d1 64 d8 a1 e9 af 95 f6 48 1b f8
d9 ed fb 2e 39 04 b2 52 92 68 c4 60 25 6f af d0
a6 77 d2 98 98 f1 0b 1d 15 12 8a 69 58 39 fc 08
ed d5 84 e8 33 56 15 b1 d1 d7 27 7b e6 5c 53 2d
ca 92 dd c7 05 03 74 86 8b 11 7e a9 15 49 14 ef
92 92 b8 44 3f 13 69 6e 4f ad 50 de d6 bd 90 e5
a6 f7 ed 33 be 2e ce 31 c6 dd 7a 42 53 ee 6c dc
56 78 7d dd 1d 5c d7 76 61 40 22 db 87 d0 3b b2
2f 23 28 5b 5a 31 67 af 8d ac ab be a4 00 04 47
13 37 d3 78 1e 8c 5c ca 0e a5 e2 77 99 b5 10 e4
ef 93 8c 61 ca a6 0d
The structure of this binary file is pretty simple, and is described in two different RFCs. RFC 4253 ("SSH Transport Layer Protocol") states in section 6.6 that
The "ssh-rsa" key format has the following specific encoding:
string "ssh-rsa"
mpint e
mpint n
while the definition of the string and mpint types can be found in RFC 4251 ("SSH Protocol Architecture"), section 5
string
[...] They are stored as a uint32 containing its length
(number of bytes that follow) and zero (= empty string) or more
bytes that are the value of the string. Terminating null
characters are not used. [...]
mpint
Represents multiple precision integers in two's complement format,
stored as a string, 8 bits per byte, MSB first. [...]
This means that the above sequence of bytes is interpreted as 4 bytes of length (32 bits of the uint32 type) followed by that number of bytes of content.
(4 bytes) 00 00 00 07 = 7
(7 bytes) 73 73 68 2d 72 73 61 = "ssh-rsa" (US-ASCII)
(4 bytes) 00 00 00 03 = 3
(3 bytes) 01 00 01 = 65537 (a common value for the RSA exponent)
(4 bytes) 00 00 01 01 = 257
(257 bytes) 00 b2 .. ca a6 0d = The key modulus
Please note that since we created a key of 2048 bits we should have a modulus of 256 bytes. Instead this key uses 257 bytes prefixing the number with a 00 byte to avoid it being interpreted as negative (two's complement format).
The structure shown above is the reason why all the RSA public SSH keys start with the same 12 characters AAAAB3NzaC1y. This string, converted in Base64 gives the initial 9 bytes 00 00 00 07 73 73 68 2d 72 (Base64 strings are not a one-to-one mapping of the source bytes). If the exponent is the standard 65537 the key starts with AAAAB3NzaC1yc2EAAAADAQAB, which encoded gives the fist 18 bytes 00 00 00 07 73 73 68 2d 72 73 61 00 00 00 03 01 00 01.
Converting between PEM and OpenSSH format¶
Often you need to convert files created with one tool to a different format, so this is a list of the most common conversions you might need. I prefer to consider the key format instead of the source tool, but I give a short description of the reason why you should want to perform the conversion.
PEM/PKCS#1 to PEM/PKCS#8¶
This is useful to convert OpenSSh private keys to a newer format.
openssl pkcs8 -topk8 -inform PEM -outform PEM -in pkcs1.pem -out pkcs8.pem
OpenSSH public to PEM/PKCS#8¶
To convert public OpenSSH keys in a proper PEM format.
ssh-keygen -e -f public.pub -mPKCS8
PEM/PKCS#8 to OpenSSH public¶
if you need to use in SSH a key pair created with another system.
ssh-keygen -i -f public.pem
Reading RSA keys in Python¶
In Python you can use the pycrypto package to access a PEM file containing an RSA key with the RSA.importKey function. Now you can hopefully understand the documentation that says
externKey (string) - The RSA key to import, encoded as a string.
An RSA public key can be in any of the following formats:
* X.509 subjectPublicKeyInfo DER SEQUENCE (binary or PEM encoding)
* PKCS#1 RSAPublicKey DER SEQUENCE (binary or PEM encoding)
* OpenSSH (textual public key only)
An RSA private key can be in any of the following formats:
* PKCS#1 RSAPrivateKey DER SEQUENCE (binary or PEM encoding)
* PKCS#8 PrivateKeyInfo DER SEQUENCE (binary or PEM encoding)
* OpenSSH (textual public key only)
For details about the PEM encoding, see RFC1421/RFC1423.
In case of PEM encoding, the private key can be encrypted with DES or 3TDES
according to a certain pass phrase. Only OpenSSL-compatible pass phrases are
supported.
In practice what you can do with a private.pem file is
fromCrypto.PublicKeyimportRSAf=open('private.pem','r')key=RSA.importKey(f.read())and the key variable will contain an instance of _RSAobj (not a very pythonic name, to be honest). This instance contains the RSA parameters as attributes as stated in the documentation
modulus=key.npublic_exponent=key.eprivate_exponent=key.dfirst_prime_number=key.psecond_prime_number=key.qq_inv_crt=key.uFinal words¶
I keep finding on StackOverflow (and on other boards) messages of users that are confused by RSA keys, the output of the various tools, and by the subtle but important differences between the formats, so I hope this post helped you to get a better understanding of the matter.
Resources¶
- The Wikipedia article on RSA
- OpenSSL documentation: asn1parse, rsa, genpkey
- The Base64 encoding
- The Abstract Syntax Notation One ASN.1 interface description language
- RFC 4251 - The Secure Shell (SSH) Protocol Architecture
- RFC 4253 - The Secure Shell (SSH) Transport Layer Protocol
- RFC 5208 - Public-Key Cryptography Standards (PKCS) #8: Private-Key Information Syntax Specification Version 1.2
- RFC 5958 - Asymmetric Key Packages
- RFC 7468 - Textual Encodings of PKIX, PKCS, and CMS Structures
- RFC 8017 - PKCS #1: RSA Cryptography Specifications Version 2.2
- PyCrypto - The Python Cryptography Toolkit
Feedback¶
Feel free to use the blog Google+ page to comment the post or reach me on Twitter if you have questions. The GitHub issues page is the best place to submit corrections.
↧
Robin Wilson: PyCon UK 2018: My thoughts – including childcare review
As I mentioned in the previous post, I attended – and spoke at – PyCon UK 2018 in Cardiff. Last time I provided a link to my talk on xarray – this time I want to provide some general thoughts on the conference, some suggested talks to watch, and a particular comment on the creche/childcare that was available.
In summary: I really enjoyed my time at PyCon UK and I would strongly suggest you attend. Interestingly for the first time I think I got more out of some of the informal activities than some of the talks – people always say that the ‘hallway track’ is one of the best bits of the conference, but I’d never really found this before.
So, what bits did I particularly enjoy?
Talks
Of the many talks that I attended, I’d particularly recommend watching the videos of:
- On the diagrammatic diagnosis of data by Ian Oszwald
- Python at Ordnance Survey by Olivia Wilson (my wife!)
- The knowledge in the code by Hannah Hazi
- Teaching programming: what’s in a teacher’s toolkit by Sue Sentance
- Assume worst intent by Alex Chan
- Rehabilitating pickle by Alex Willmer
- Why does a smile make a difference by Nikoleta E. Glynatsi
Other things
There were two other things that went on that were very interesting. One was a ‘bot competition’ run by Peter Ingelsby, where you had to write Python bots to play Connect 4 against each other. I didn’t have the time (or energy!) to write a bot, but I enjoyed looking at the code of the various bots that won at the end – some very clever techniques in there! Some of the details of the bots are described in this presentation at the end of the conference.
On the final day of the conference, people traditionally take part in ‘sprints’ – working on a whole range of Python projects. However, this year there was another activity taking place during the sprints day: a set of ‘Lean Coffee’ discussions run by David MacIver. I won’t go into the way this worked in detail, as David has written a post all about it, but I found it a very satisfying way to finish the conference. We had discussions about a whole range of issues – including the best talks at the conference, how to encourage new speakers, testing methods for Python code, other good conferences, how to get the most out of the ‘hallway track’ and lots more. Because of the way the ‘Lean Coffee’ works, each discussion is time-bound, and only occurs if the majority of the people around the table are interested in it – so it felt far more efficient than most group discussions I’ve been in. I left wanting to run some Lean Coffee sessions myself sometime (and, while writing this, am kicking myself for not suggesting it at a local unconference I went to last week!). I may also have volunteered myself to run some more sessions like it during the main conference next year – wait to hear more on that front.
Creche/Childcare
My wife and I wouldn’t have been able to attend PyCon UK without their childcare offer. The childcare is described on the conference website, but there isn’t a huge amount of detail. My aim in this section is to provide a bit more real-world information on how it actually worked and what it was like – along with some cute photos.
So, having said we wanted to use the creche when we booked our tickets, we got an email a few days before the conference asking us to provide our child’s name, age and any special requirements. We turned up on the first day at about 8:45 (the first session started at 9:00), not really sure what to expect, and found a room for the creche just outside of the main hall (the Assembly Room). It was a fairly small room, but that didn’t matter as there weren’t that many children.

Inside there were two nursery staff, from Brecon Mobile Childcare. They specialise in doing childcare at conferences, parties, weddings and so on – so they were used to looking after children that they didn’t know very well. They introduced themselves to us, and to our son, and got us to fill in a form with our details and his details, including emergency contact details for us. We talked a little about his routine and when he tends to nap, snack and so on, and then we kissed him goodbye and left. They assured us that if he got really upset and they couldn’t settle him (because they didn’t know him very well) then they’d call our mobiles and we could come and calm him down. We could then go off and enjoy the conference – and, in fact, the staff suggested that we shouldn’t come visiting during the breaks as that was likely to just upset him as he’d have to say goodbye to Mummy and Daddy multiple times.
I think there were something like 5 children there on the first day, ranging in age from about six months to ten years. The room had a variety of toys in it suitable for various different ages (including colouring and board games for the older ones, and soft toys and play mats for the younger ones), plus a small TV showing some children’s TV programmes (Teletubbies was on when we came in).

We came back at lunchtime and found that he’d had a good time. He cried a little when we left, but stopped in about a minute, and the staff engaged him with some of the toys. He’d had a short nap in his pram (we left that with them in the room) and had a few of his snacks. We collected him for lunch and took him down to the main lunch hall to get some food.
PyCon UK make it very clear that children are welcomed in all parts of the conference venue, and no-one looked at us strangely for having a child with us at lunchtime. Various other attendees engaged with our son nicely, and we soon had him sitting on a seat and eating some of the food provided. Those with younger children should note that there wasn’t any special food provided for children: our son was nearly 18 months old, so he could just eat the same as us, but younger children may need food bringing specially for them. There also weren’t any high chairs around, which could have been useful – but our son managed fairly well sitting on a chair and then on the floor, and didn’t make too much mess.

After eating lunch we took him for a walk in his pram around the park outside the venue, with the aim of getting him to sleep. We didn’t manage to get him to sleep, but he did get some fresh air. We then took him up to the creche room again and said goodbye, and left him to have fun playing with the staff for the afternoon.
We were keen to go to the lightning talks that afternoon, so went to the main hall at 5:30pm in time for them. Part-way through the talks, when popping to the toilet, we found one of the creche staff outside the main hall with our son. It turned out that the creche only continued until 5:30, not until 6:30 when the conference actually finished. We were a little surprised by this (and gave feedback to the organisers saying that the creche should finish when the main conference finishes), but it didn’t actually cause us much problem. We’d been told that children are welcome in any of the talks – and the lightning talks are more informal than most of the talks – so we brought him into the main hall and played with him at the back.

He enjoyed wandering around with his Mummy’s conference badge around his neck, and kept walking up and down the aisle smiling at people. Occasionally he got a bit too near the front, and we were asked very nicely by one of the organisers the next day to try and keep him out of the main eye-line of the speakers as it can be a bit distracting for them, but we were assured that they were more than happy to have him in the room. He even did some of his climbing over Mummy games at the back, and then breastfed for a bit, and no-one minded at all.



The rest of the days were just like the first, except that there were less children in the creche, and therefore only one member of staff. For most of the days there were just two children: our son, and a ten year old girl. On the last day (the sprints day) there was just Julian. During some of these days the staff member was able to take Julian out for a walk in his pram, which was nice, and got him a bit of fresh air.
So, that’s pretty-much all there is to say about the creche. It worked very well, and it allowed both my wife and me to attend – something which isn’t possible with most conferences. We were happy to leave our son with the staff, and he seemed to have a nice time. We’ll definitely use the creche again!
↧
↧
Tim Golden: Stepping back a bit from python.org
The fact that you hadn't noticed is a testament to the number of people working behind the scenes at various facets of python.org. For some years I've been part of a number of teams who sit behind things like the webmaster@python.org address or planet.python.org. Or the python-list@python.org mailing list (mirrored to the comp.lang.python newsgroup). Plus a bunch of other lists including python-uk, python-win32, python-announce, core-mentorship, python-checkins, speed and a couple I can't even remember right now! Plus I'm an admin on the python.org website.
I took on those roles because I felt they were ways I could contribute to the community without too much commitment of time. Like most people, I have a full-time job (not Python-related) and some serious commitments outside work. And I rarely have the concentrated spell of time available to me which I need to do, say, core development work for Python. But most of those roles only require answering or dealing with the occasional email, sorting out the odd admin task, or approving a github PR. I can do each thing usually within a few minutes of receiving the email, even if I'm at work. So I felt that I could help the Python community without disrupting my life.
And I could. I stepped up to those roles at different times, but I've been helping out in that way for between 3 and about 10 years. As have other people, obviously. Sometimes because I or others have put out a call for help; sometimes, they've just volunteered spontaneously. In most of those roles I've been part of a small team which doesn't require much intervention or coordination.
But recently several things have happened more or less at once: a heavier workload in my dayjob; a move to a greater out-of-work commitment; some complications with one particular of those python.org responsibilities which required a much greater input of time and thought. And I realised: you don't have to do this. I'd done that thing where I felt responsible for helping out a community to such a great extent that I'd over-extended myself.
I'd intended to scale back gradually what I was doing on python.org, but once I started, it became easier to just step back from everything. In all but about two cases I was part of a (small) team so I was able to let them know I was stepping down and leave the situation in good hands. In a couple of cases I had to reach out to someone else who was or had been involved to ask them to take over a certain task.
What surprised me, although it shouldn't have, was the effect on my Inbox. Suddenly, I was getting no emails for hours on end. I actually thought there was a problem with the mailserver at first; it was such an unfamiliar sensation. I think the fact that I found it a relief was a clear sign that I'd made the right choice.
Let me be clear about this: I stepped back because I needed to, not because of any sour grapes or misgivings about python.org activities. Or any personal clashes with anyone. Or any other reason other than: I felt I'd done my stint. Cursum consummavi and all that. As I said at the beginning: the fact that you had no idea I had stepped down, nor that I had even stepped up in the first place is a testament to the unsung work which goes on in every community, the Python community no less than others.
So... first, let me thank every person working behind the scenes in the Python community just to oil the wheels to make everything work which people take for granted. And secondly, let me invite any of you to offer your services on whatever basis suits you to help out in some way.
↧
Montreal Python User Group: Montréal-Python 73: Call for Speakers - Despotic Wagon
Just in the time for the end of Fall we are officially calling for speakers for our next pythonesque rendez-vous.
Either you want to practice your talk for PyCon Canada, or you would like to present to us your latest discovery, send us your proposition by email at mtlpyteam@googlegroups.com or join us on slack at http://montrealpython.org/en/slackin.
By the way, it's time to buy your ticket for PyCon Canada 2018 at following link: https://2018.pycon.ca/.
When
Monday November 5th, 2018 at 6PM
Where
Shopify, 490 rue de la Gauchetière Montréal, Québec (map)
Schedule
6:00PM - Doors open
6:30PM - Presentations
8:00PM - End of the event
8:15PM - Benelux
↧
Tim Golden: Following up from stepping back
Thank you to those who responded to my previous post with thanks and words of encouragement. Just to be clear, I'm not stepping back from Python altogether; far from it. I'm simply giving up certain background responsibilities which I've found difficult to sustain. I realise that, by doing so, I've left the others who continue to manage those tasks more burdened than before. So, again, I encourage you to offer to help on whatever basis you think you can manage.
Python has grown. When I entered the community about 20 years ago, it was a moderate-sized mostly technical language community. It's always been growing in popularity, but over the last 10 years it's reached the point where it's used and relied on -- directly or indirectly -- by millions of people around the world. Indirectly by virtue of its use in some very big-name companies. Directly because it's become the go-to language for science and data projects. And it's the text-based programming language most likely to be taught in secondary schools in the UK and maybe elsewhere, especially with the encouragement of the Raspberry Pi foundation and its resources. The audience is huge.
Because of its size and significance, many people assume that there's a commercial organisation running things. Or at least a well set-up NGO or institute or something. But there isn't. There is a series of semi-detached volunteer teams who typically only interact because one or more people on one of the teams are also on one or more of the other teams.
The webmaster@ address is the fallback communication point for the Python community. It handles all sorts of queries. There are general requests for help; requests from official bodies for us to complete some complicated export license document; more questions about the cost of licenses than I care to think about ("No really, it's free; yes you can get a bulk discount of 100% because IT'S FREE"); questions about copyright and logo use; technical questions; questions from school administrators who don't grok the new Python Windows installers; people who've bought a car security system with the brand name "Python". And all those queries are fielded by about three people (now about two people!) working with whatever time they have available.
The Python mailing list (also comp.lang.python newsgroup) is the "official" general-purpose communication channel for questions about Python. But it's a mailing list / newsgroup, both of which are slightly ageing concepts. Its origin as the forum of discussion around a mostly technical audience still informs its general attitude. And, by its nature, it assumes that you're interested in joining a community and not simply asking a drive-by question. There's some experimentation going on at the moment about using a Discourse or a Zulip instance or both, which I think might be a move in the right direction for the wider casual audience.
People raise issues on https://bugs.python.org asking questions about https://pypi.python.org; they write to webmaster querying why they haven't received a confirmation email when they signed up on the https://python.org website; they write to mailto:docs@python.org when downloads aren't available on https://docs.python.org for the latest version of the documentation; and they raise an issue on the website tracker when there's a spelling mistake in the online documentation. And although I've put those examples forward as mistakes, it may not even be obvious to you why those are mistakes. python.org contains quite a few silos.
The easy majority of volunteers behind these various forums are technical people who've stepped up to help. Which is clearly very much to their credit. Back in the day, most people posting through Python forums would also have been those with a technical background who'd chosen to use Python: students, professional programmers &c. So there was an easier meeting of minds when it came to answering questions and giving advice. Nowadays they might be, for example, schoolteachers or data scientists who use Python as a tool (for teaching or analysis) but who have no knowledge of or, really, interest in the underlying mechanics of the language or its community. Or even schoolchildren looking for help with their homework or with a personal project. So there can be a mismatch between the people asking questions and those answering.
On top of all that, we're increasingly in a world where Codes of Conduct are needed, if only as a reference answer to "Who says I can't do that?". But that puts a significant burden on list owners and forum volunteers who, acting in their spare time and often without much help, need to respond authoritatively to complaints and responses.
What am I suggesting? Whatever I suggest runs the risk of sounding like "We really should be doing..." when I've just announced that I'm stepping back from doing things. However, in a spirit of constructive criticism I think I'm suggesting:
That the PSF take an holistic view of the different public-facing python.org properties (including bugs.python.org, pypi.python.org, python.org itself, the more public Mailman2/3 lists on python.org, planet.python.org, webmaster@python.org) with a view to creating a common understanding of the roles and responsibilities of those volunteer teams who manage those resources, including cross-fertilisation of ideas and a common meta-forum for dealing with misdirected enquiries and CoC issues. Perhaps even synthesising a single team to handle requests coming in through all of those and other channels.
Just as I was backing away from my python.org responsibilities, I think there may have been the beginnings of something like this: a meta-list for list admins. If there was, then I think that's a step in the right direction. Without question, there are wider technical issues which could be addressed given time and resources (eg the number of accounts needed to operate on different python.org properties). But I recognise that there are technical and even political challenges to making that work to everyone's satisfaction.
I don't know what's in store for Python in the future. Maybe it will continue to grow and evolve; maybe it will be overtaken by a new kid on the block. I'm not saying that it doesn't matter. But what matters more is what Python can offer now for the many, many people who find it useful, or who merely find themselves using it, and want support from its community.
↧