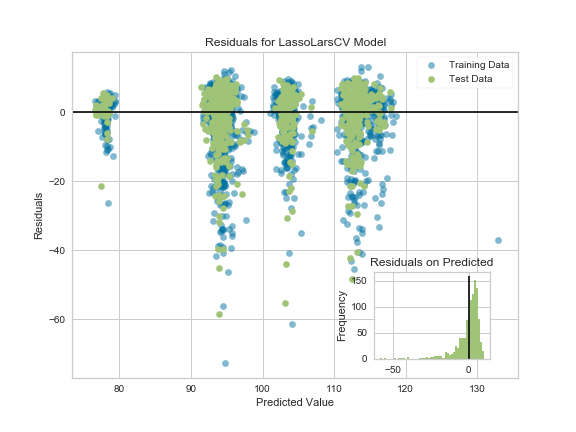
Every now and then, I see someone asking how to get the text for each item in a row of a ListCtrl in report mode. The ListCtrl does not make it very obvious how you would get the text in row one, column three for example. In this article we will look at how we might accomplish this task.
Getting Data from Any Column

Let’s start by creating a simple ListCtrl and using a button to populate it. Then we’ll add a second button for extracting the contents of the ListCtrl:
import wx class MyForm(wx.Frame): def__init__(self): wx.Frame.__init__(self, None, wx.ID_ANY, "List Control Tutorial") # Add a panel so it looks the correct on all platforms panel = wx.Panel(self, wx.ID_ANY)self.index = 0 self.list_ctrl = wx.ListCtrl(panel, size=(-1,100), style=wx.LC_REPORT |wx.BORDER_SUNKEN)self.list_ctrl.InsertColumn(0, 'Subject')self.list_ctrl.InsertColumn(1, 'Due')self.list_ctrl.InsertColumn(2, 'Location', width=125) btn = wx.Button(panel, label="Add Line") btn2 = wx.Button(panel, label="Get Data") btn.Bind(wx.EVT_BUTTON, self.add_line) btn2.Bind(wx.EVT_BUTTON, self.get_data) sizer = wx.BoxSizer(wx.VERTICAL) sizer.Add(self.list_ctrl, 0, wx.ALL|wx.EXPAND, 5) sizer.Add(btn, 0, wx.ALL|wx.CENTER, 5) sizer.Add(btn2, 0, wx.ALL|wx.CENTER, 5) panel.SetSizer(sizer) def add_line(self, event): line = "Line %s"%self.indexself.list_ctrl.InsertStringItem(self.index, line)self.list_ctrl.SetStringItem(self.index, 1, "01/19/2010")self.list_ctrl.SetStringItem(self.index, 2, "USA")self.index += 1 def get_data(self, event): count = self.list_ctrl.GetItemCount() cols = self.list_ctrl.GetColumnCount()for row inrange(count): for col inrange(cols): item = self.list_ctrl.GetItem(itemId=row, col=col)print(item.GetText()) # Run the programif __name__ == "__main__": app = wx.App(False) frame = MyForm() frame.Show() app.MainLoop()
Let’s take a moment to break this code down a bit. The first button’s event handler is the first piece of interesting code. It demonstrates how to insert data into the ListCtrl. As you can see, that’s pretty straightforward as all we need to do to add a row is call InsertStringItem and then set each column’s text using SetStringItem. There are other types of items that we can insert into a ListCtrl besides a String Item, but that’s outside the scope of this article.
Next we should take a look at the get_data event handler. It grabs the row count using the ListCtrl’s GetItemCount method. We also get the number of columns in the ListCtrl via GetColumnCount. Finally we loop over the rows and extract each cell, which in ListCtrl parlance is known as an “item”. We use the ListCtrl’s GetItem method of this task. Now that we have the item, we can call the item’s GetText method to extract the text and print it to stdout.
Associating Objects to Rows

An easier way to do this sort of thing would be to associate an object to each row. Let’s take a moment to see how this might be accomplished:
import wx class Car(object): """""" def__init__(self, make, model, year, color="Blue"): """Constructor"""self.make = make self.model = model self.year = year self.color = color class MyPanel(wx.Panel): """""" def__init__(self, parent): """Constructor""" wx.Panel.__init__(self, parent) rows = [Car("Ford", "Taurus", "1996"), Car("Nissan", "370Z", "2010"), Car("Porche", "911", "2009", "Red")] self.list_ctrl = wx.ListCtrl(self, size=(-1,100), style=wx.LC_REPORT |wx.BORDER_SUNKEN)self.list_ctrl.Bind(wx.EVT_LIST_ITEM_SELECTED, self.onItemSelected)self.list_ctrl.InsertColumn(0, "Make")self.list_ctrl.InsertColumn(1, "Model")self.list_ctrl.InsertColumn(2, "Year")self.list_ctrl.InsertColumn(3, "Color") index = 0self.myRowDict = {}for row in rows: self.list_ctrl.InsertStringItem(index, row.make)self.list_ctrl.SetStringItem(index, 1, row.model)self.list_ctrl.SetStringItem(index, 2, row.year)self.list_ctrl.SetStringItem(index, 3, row.color)self.myRowDict[index] = row index += 1 sizer = wx.BoxSizer(wx.VERTICAL) sizer.Add(self.list_ctrl, 0, wx.ALL|wx.EXPAND, 5)self.SetSizer(sizer) def onItemSelected(self, event): """""" currentItem = event.m_itemIndex car = self.myRowDict[currentItem]print(car.make)print(car.model)print(car.color)print(car.year) class MyFrame(wx.Frame): """""" def__init__(self): """Constructor""" wx.Frame.__init__(self, None, wx.ID_ANY, "List Control Tutorial") panel = MyPanel(self)self.Show() if __name__ == "__main__": app = wx.App(False) frame = MyFrame() app.MainLoop()
In this example, we have a Car class that we will use to create Car object from. These Car objects will then be associated with a row in the ListCtrl. Take a look at MyPanel‘s __init__ method and you will see that we create a list of row objects and then loop over the row objects and insert them into the ListCtrl using the object’s attributes for the text values. You will also note that we have created a class attribute dictionary that use for associating the row’s index to the Car object that was inserted into the row.
We also bind the ListCtrl to EVT_LIST_ITEM_SELECTED so when an item is selected, it will call the onItemSelected method and print out the data from the row. You will note that we get the row’s index by using event.m_itemIndex. The rest of the code should be self-explanatory.
Wrapping Up
Now you know a couple of different approaches for extracting all the data from a ListCtrl. Personally, I really like using the ObjectListView widget. I feel that is superior to the ListCtrl as it has these kinds of features built-in. But it’s not included with wxPython so it’s an extra install.
Additional Reading
- ListCtrl: Tips and Tricks
- wxPython: Using ObjectListView instead of a ListCtrl






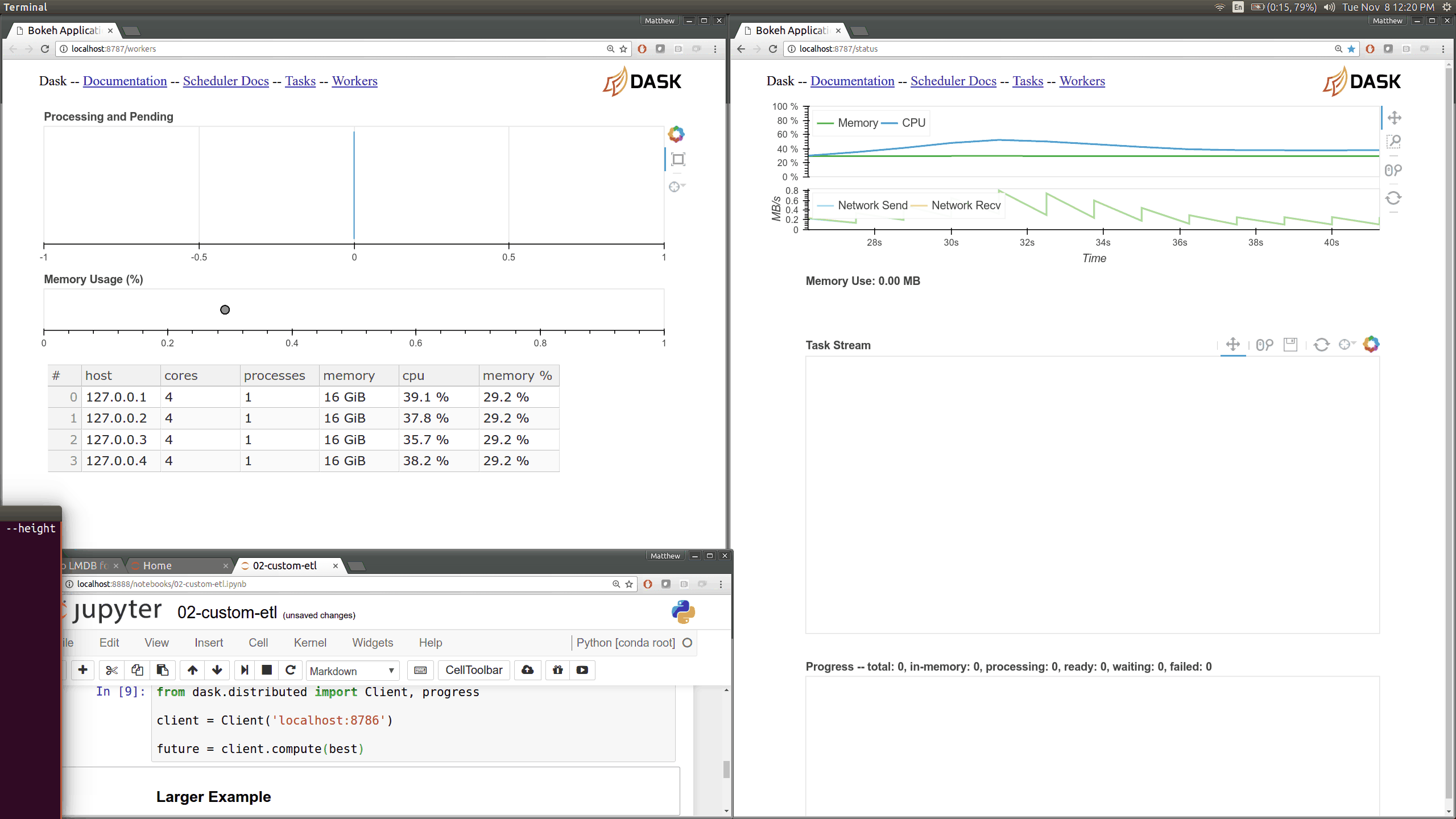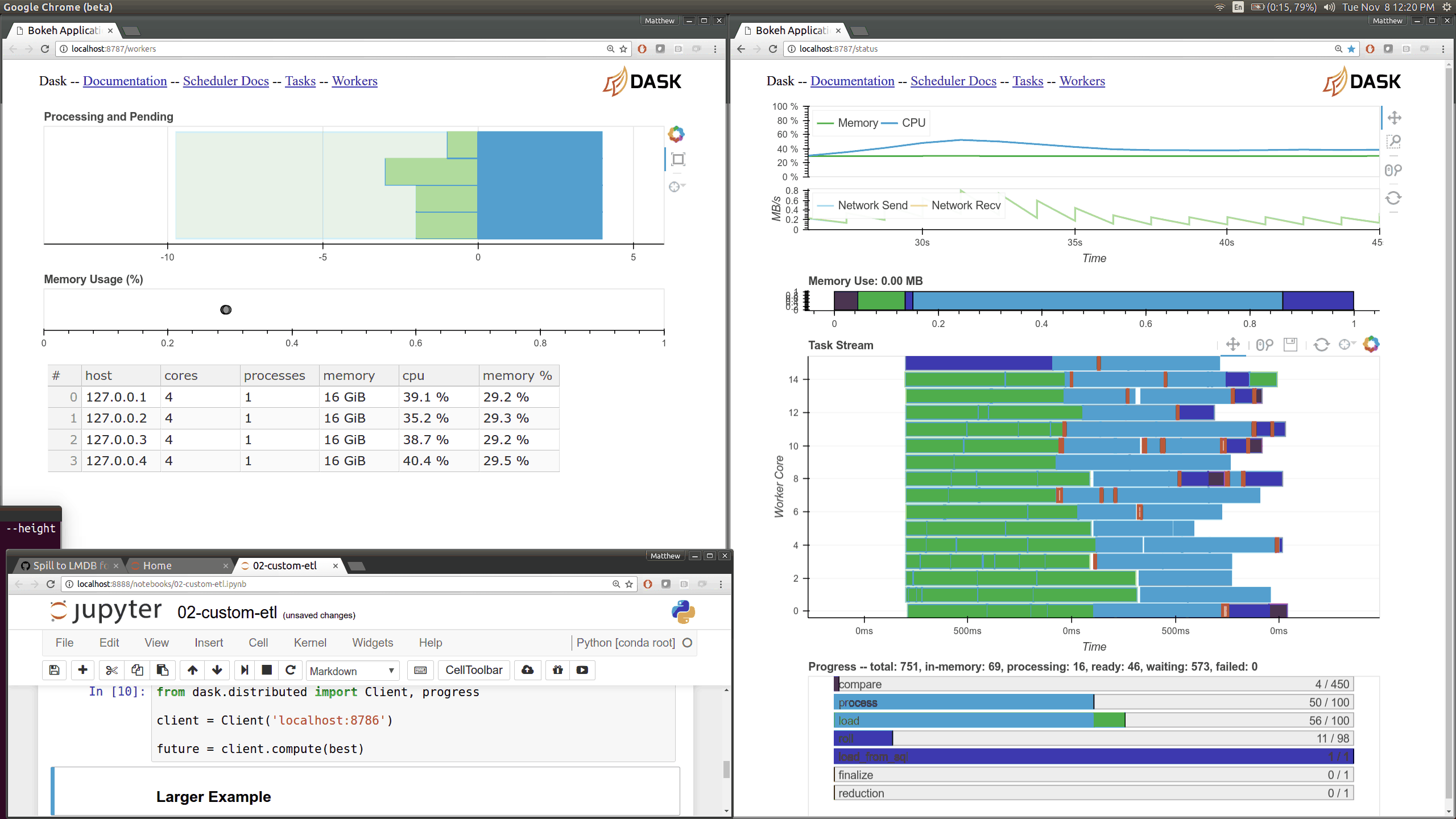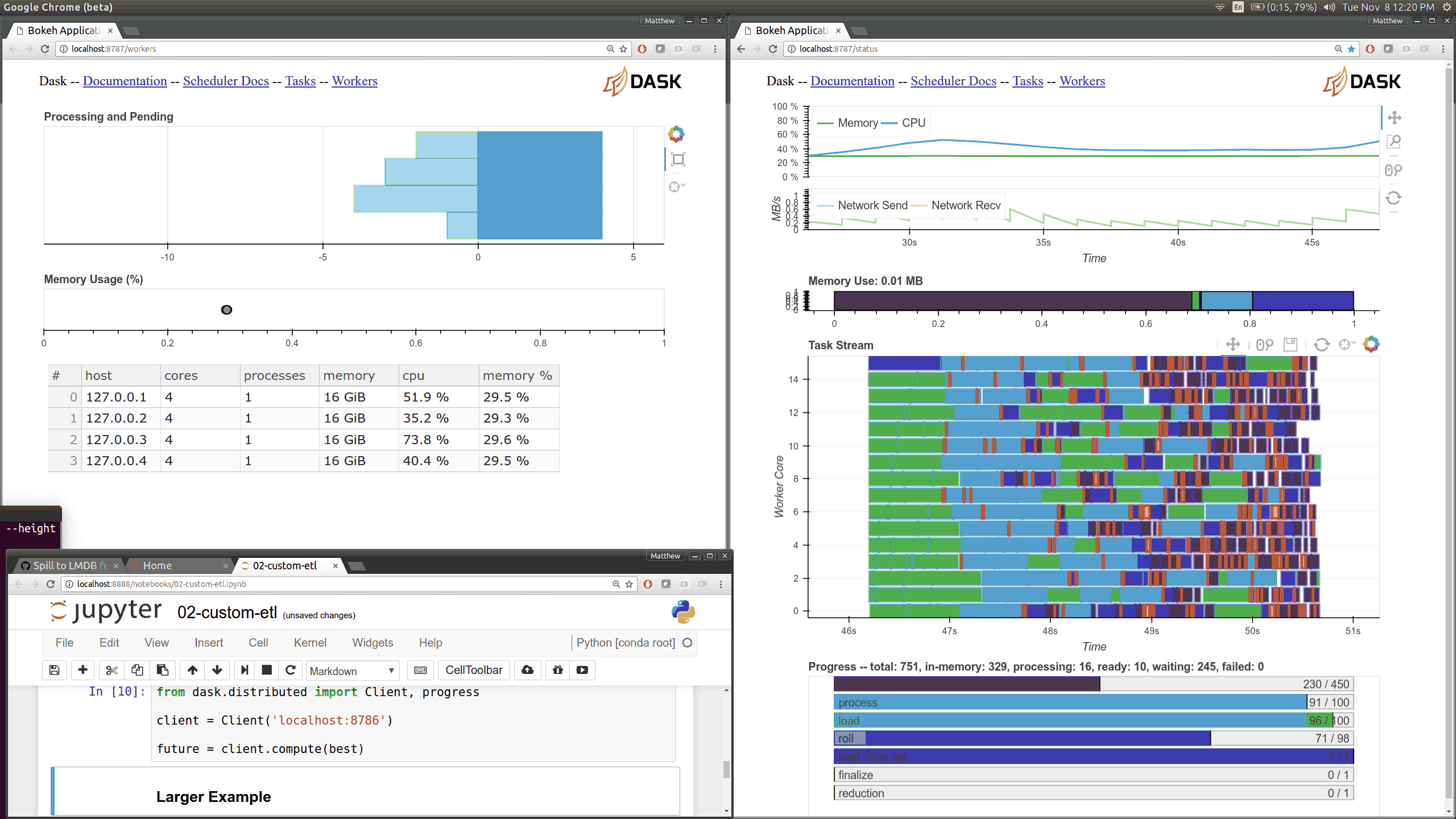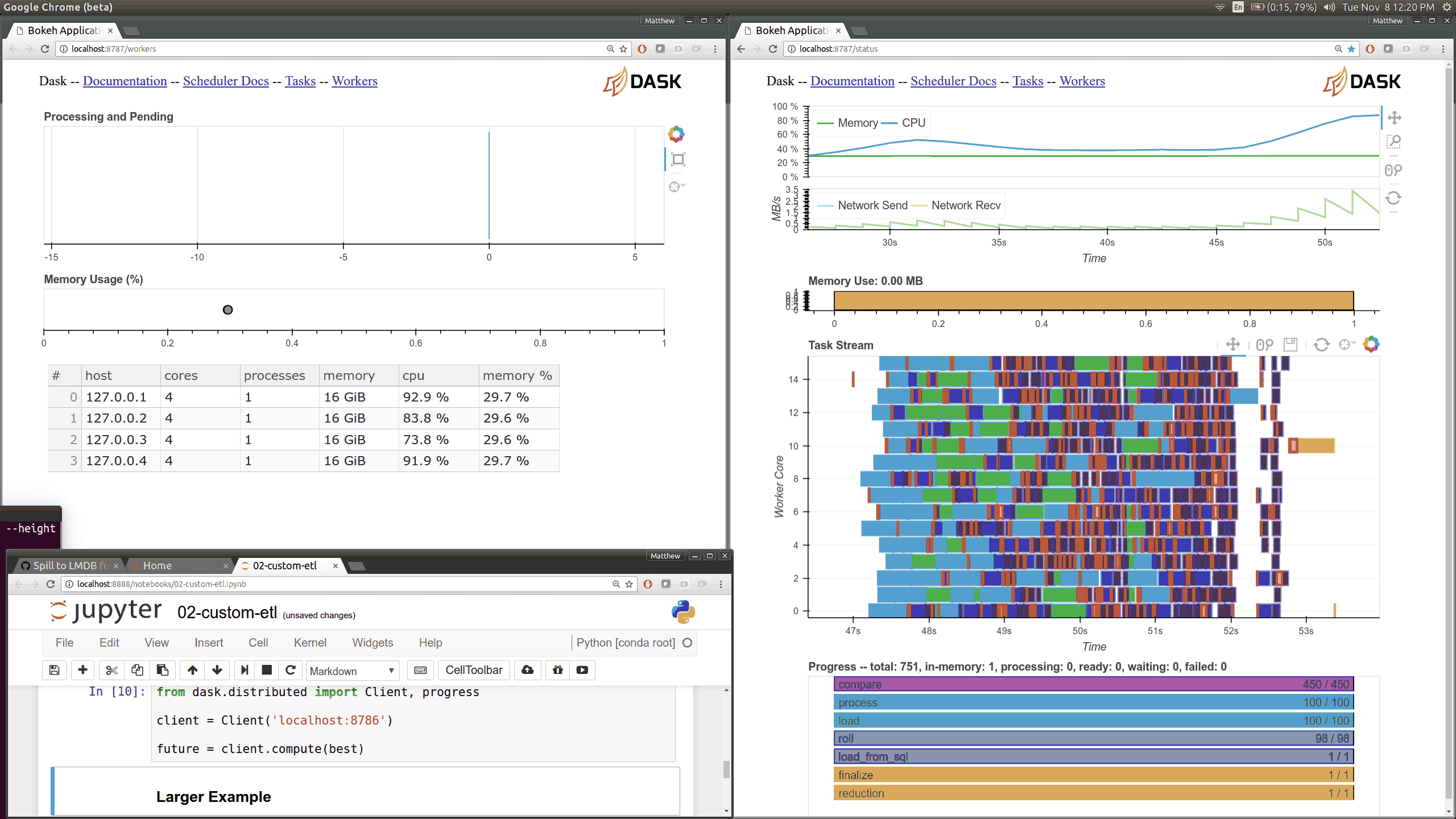



 We understand that data exploration and manipulation are only one part of your data analysis process, which is why the Data Import Tool now provides a way for you to save the DataFrame as a CSV/XLSX file. This way, you can share processed data with your colleagues or feed this processed file to the next step in your data analysis pipeline.
We understand that data exploration and manipulation are only one part of your data analysis process, which is why the Data Import Tool now provides a way for you to save the DataFrame as a CSV/XLSX file. This way, you can share processed data with your colleagues or feed this processed file to the next step in your data analysis pipeline. In earlier versions of the Data Import Tool, it was not obvious that clicking on the right-end of the column header sorted the columns. With this release, we added sort indicators on every column, which can be pressed to sort the column in an ascending or descending fashion. And given the complex nature of the data we get, we know sorting the data based on single column is never enough, so we also made sorting columns using the Data Import Tool stable (ie, sorting preserves any existing order in the DataFrame).
In earlier versions of the Data Import Tool, it was not obvious that clicking on the right-end of the column header sorted the columns. With this release, we added sort indicators on every column, which can be pressed to sort the column in an ascending or descending fashion. And given the complex nature of the data we get, we know sorting the data based on single column is never enough, so we also made sorting columns using the Data Import Tool stable (ie, sorting preserves any existing order in the DataFrame).
 As we can see from the raw data, the first column in the data contains Index values.. We can access the `SetIndex` command from the right-click menu item on the `ID` column.
As we can see from the raw data, the first column in the data contains Index values.. We can access the `SetIndex` command from the right-click menu item on the `ID` column.