Introduction
In many practical Data Science activities, the data set will contain categorical variables. These variables are typically stored as text values which represent various traits. Some examples include color (“Red”, “Yellow”, “Blue”), size (“Small”, “Medium”, “Large”) or geographic designations (State or Country). Regardless of what the value is used for, the challenge is determining how to use this data in the analysis. Many machine learning algorithms can support categorical values without further manipulation but there are many more algorithms that do not. Therefore, the analyst is faced with the challenge of figuring out how to turn these text attributes into numerical values for further processing.
As with many other aspects of the Data Science world, there is no single answer on how to approach this problem. Each approach has trade-offs and has potential impact on the outcome of the analysis. Fortunately, the python tools of pandas and scikit-learn provide several approaches that can be applied to transform the categorical data into suitable numeric values. This article will be a survey of some of the various common (and a few more complex) approaches in the hope that it will help others apply these techniques to their real world problems.
The Data Set
For this article, I was able to find a good dataset at the UCI Machine Learning Repository. This particular Automobile Data Set includes a good mix of categorical values as well as continuous values and serves as a useful example that is relatively easy to understand. Since domain understanding is an important aspect when deciding how to encode various categorical values - this data set makes a good case study.
Before we get started encoding the various values, we need to important the data and do some minor cleanups. Fortunately, pandas makes this straightforward:
importpandasaspdimportnumpyasnp# Define the headers since the data does not have anyheaders=["symboling","normalized_losses","make","fuel_type","aspiration","num_doors","body_style","drive_wheels","engine_location","wheel_base","length","width","height","curb_weight","engine_type","num_cylinders","engine_size","fuel_system","bore","stroke","compression_ratio","horsepower","peak_rpm","city_mpg","highway_mpg","price"]# Read in the CSV file and convert "?" to NaNdf=pd.read_csv("http://mlr.cs.umass.edu/ml/machine-learning-databases/autos/imports-85.data",header=None,names=headers,na_values="?")df.head()| symboling | normalized_losses | make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | wheel_base | … | engine_size | fuel_system | bore | stroke | compression_ratio | horsepower | peak_rpm | city_mpg | highway_mpg | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | NaN | alfa-romero | gas | std | two | convertible | rwd | front | 88.6 | … | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 13495.0 |
| 1 | 3 | NaN | alfa-romero | gas | std | two | convertible | rwd | front | 88.6 | … | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 16500.0 |
| 2 | 1 | NaN | alfa-romero | gas | std | two | hatchback | rwd | front | 94.5 | … | 152 | mpfi | 2.68 | 3.47 | 9.0 | 154.0 | 5000.0 | 19 | 26 | 16500.0 |
| 3 | 2 | 164.0 | audi | gas | std | four | sedan | fwd | front | 99.8 | … | 109 | mpfi | 3.19 | 3.40 | 10.0 | 102.0 | 5500.0 | 24 | 30 | 13950.0 |
| 4 | 2 | 164.0 | audi | gas | std | four | sedan | 4wd | front | 99.4 | … | 136 | mpfi | 3.19 | 3.40 | 8.0 | 115.0 | 5500.0 | 18 | 22 | 17450.0 |
The final check we want to do is see what data types we have:
df.dtypessymboling int64 normalized_losses float64 make object fuel_type object aspiration object num_doors object body_style object drive_wheels object engine_location object wheel_base float64 length float64 width float64 height float64 curb_weight int64 engine_type object num_cylinders object engine_size int64 fuel_system object bore float64 stroke float64 compression_ratio float64 horsepower float64 peak_rpm float64 city_mpg int64 highway_mpg int64 price float64 dtype: object
Since this article will only focus on encoding the categorical variables,
we are going to include only the
object
columns in our dataframe. Pandas has a
helpful
select_dtypes
function which we can use to build a new dataframe
containing only the object columns.
obj_df=df.select_dtypes(include=['object']).copy()obj_df.head()| make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | engine_type | num_cylinders | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alfa-romero | gas | std | two | convertible | rwd | front | dohc | four | mpfi |
| 1 | alfa-romero | gas | std | two | convertible | rwd | front | dohc | four | mpfi |
| 2 | alfa-romero | gas | std | two | hatchback | rwd | front | ohcv | six | mpfi |
| 3 | audi | gas | std | four | sedan | fwd | front | ohc | four | mpfi |
| 4 | audi | gas | std | four | sedan | 4wd | front | ohc | five | mpfi |
Before going any further, there are a couple of null values in the data that we need to clean up.
obj_df[obj_df.isnull().any(axis=1)]| make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | engine_type | num_cylinders | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 27 | dodge | gas | turbo | NaN | sedan | fwd | front | ohc | four | mpfi |
| 63 | mazda | diesel | std | NaN | sedan | fwd | front | ohc | four | idi |
For the sake of simplicity, just fill in the value with the number 4 (since that is the most common value):
obj_df["num_doors"].value_counts()four 114 two 89 Name: num_doors, dtype: int64
obj_df=obj_df.fillna({"num_doors":"four"})Now that the data does not have any null values, we can look at options for encoding the categorical values.
Approach #1 - Find and Replace
Before we go into some of the more “standard” approaches for encoding categorical data, this data set highlights one potential approach I’m calling “find and replace.”
There are two columns of data where the values are words used to represent
numbers. Specifically the number of cylinders in the engine and number of doors on the car.
Pandas makes it easy for us to directly replace the text values with their
numeric equivalent by using
replace
.
We have already seen that the num_doors data only includes 2 or 4 doors. The number of cylinders only includes 7 values and they are easily translated to valid numbers:
obj_df["num_cylinders"].value_counts()four 159 six 24 five 11 eight 5 two 4 twelve 1 three 1 Name: num_cylinders, dtype: int64
If you review the
replacedocumentation, you can see that it is a powerful
command that has many options. For our uses, we are going to create a
mapping dictionary that contains each column to process as well as a dictionary
of the values to translate.
Here is the complete dictionary for cleaning up the
num_doors
and
num_cylinders
columns:
cleanup_nums={"num_doors":{"four":4,"two":2},"num_cylinders":{"four":4,"six":6,"five":5,"eight":8,"two":2,"twelve":12,"three":3}}To convert the columns to numbers using
replace
:
obj_df.replace(cleanup_nums,inplace=True)obj_df.head()| make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | engine_type | num_cylinders | fuel_system | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alfa-romero | gas | std | 2 | convertible | rwd | front | dohc | 4 | mpfi |
| 1 | alfa-romero | gas | std | 2 | convertible | rwd | front | dohc | 4 | mpfi |
| 2 | alfa-romero | gas | std | 2 | hatchback | rwd | front | ohcv | 6 | mpfi |
| 3 | audi | gas | std | 4 | sedan | fwd | front | ohc | 4 | mpfi |
| 4 | audi | gas | std | 4 | sedan | 4wd | front | ohc | 5 | mpfi |
The nice benefit to this approach is that pandas “knows” the types of values in
the columns so the
object
is now a
int64
obj_df.dtypesmake object fuel_type object aspiration object num_doors int64 body_style object drive_wheels object engine_location object engine_type object num_cylinders int64 fuel_system object dtype: object
While this approach may only work in certain scenarios it is a very useful demonstration of how to convert text values to numeric when there is an “easy” human interpretation of the data. This concept is also useful for more general data cleanup.
Approach #2 - Label Encoding
Another approach to encoding categorical values is to use a technique called label encoding.
Label encoding is simply converting each value in a column to a number. For example,
the
body_style
column contains 5 different values. We could choose to encode
it like this:
- convertible -> 0
- hardtop -> 1
- hatchback -> 2
- sedan -> 3
- wagon -> 4
This process reminds me of Ralphie using his secret decoder ring in “A Christmas Story”

One trick you can use in pandas is to convert a column to a category, then use those category values for your label encoding:
obj_df["body_style"]=obj_df["body_style"].astype('category')obj_df.dtypesmake object fuel_type object aspiration object num_doors int64 body_style category drive_wheels object engine_location object engine_type object num_cylinders int64 fuel_system object dtype: object
Then you can assign the encoded variable to a new column using the
cat.codes
accessor:
obj_df["body_style_cat"]=obj_df["body_style"].cat.codesobj_df.head()| make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | engine_type | num_cylinders | fuel_system | body_style_cat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alfa-romero | gas | std | 2 | convertible | rwd | front | dohc | 4 | mpfi | 0 |
| 1 | alfa-romero | gas | std | 2 | convertible | rwd | front | dohc | 4 | mpfi | 0 |
| 2 | alfa-romero | gas | std | 2 | hatchback | rwd | front | ohcv | 6 | mpfi | 2 |
| 3 | audi | gas | std | 4 | sedan | fwd | front | ohc | 4 | mpfi | 3 |
| 4 | audi | gas | std | 4 | sedan | 4wd | front | ohc | 5 | mpfi | 3 |
The nice aspect of this approach is that you get the benefits of pandas categories (compact data size, ability to order, plotting support) but can easily be converted to numeric values for further analysis.
Approach #3 - One Hot Encoding
Label encoding has the advantage that it is straightforward but it has the disadvantage that the numeric values can be “misinterpreted” by the algorithms. For example, the value of 0 is obviously less than the value of 4 but does that really correspond to the data set in real life? Does a wagon have “4X” more weight in our calculation than the convertible? In this example, I don’t think so.
A common alternative approach is called one hot encoding (but also goes by several different names shown below). Despite the different names, the basic strategy is to convert each category value into a new column and assigns a 1 or 0 (True/False) value to the column. This has the benefit of not weighting a value improperly but does have the downside of adding more columns to the data set.
Pandas supports this feature using get_dummies. This function is named this way because it creates dummy/indicator variables (aka 1 or 0).
Hopefully a simple example will make this more clear. We can look at the column
drive_wheels
where we have values of
4wd
,
fwd
or
rwd
.
By using
get_dummies
we can convert this to three columns with a 1 or 0 corresponding
to the correct value:
pd.get_dummies(obj_df,columns=["drive_wheels"]).head()| make | fuel_type | aspiration | num_doors | body_style | engine_location | engine_type | num_cylinders | fuel_system | body_style_cat | drive_wheels_4wd | drive_wheels_fwd | drive_wheels_rwd | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alfa-romero | gas | std | 2 | convertible | front | dohc | 4 | mpfi | 0 | 0.0 | 0.0 | 1.0 |
| 1 | alfa-romero | gas | std | 2 | convertible | front | dohc | 4 | mpfi | 0 | 0.0 | 0.0 | 1.0 |
| 2 | alfa-romero | gas | std | 2 | hatchback | front | ohcv | 6 | mpfi | 2 | 0.0 | 0.0 | 1.0 |
| 3 | audi | gas | std | 4 | sedan | front | ohc | 4 | mpfi | 3 | 0.0 | 1.0 | 0.0 |
| 4 | audi | gas | std | 4 | sedan | front | ohc | 5 | mpfi | 3 | 1.0 | 0.0 | 0.0 |
The new data set contains three new columns:
drive_wheels_4wddrive_wheels_rwddrive_wheels_fwd
This function is powerful because you can pass as many category columns as you would like
and choose how to label the columns using
prefix
. Proper naming will make the
rest of the analysis just a little bit easier.
pd.get_dummies(obj_df,columns=["body_style","drive_wheels"],prefix=["body","drive"]).head()| make | fuel_type | aspiration | num_doors | engine_location | engine_type | num_cylinders | fuel_system | body_style_cat | body_convertible | body_hardtop | body_hatchback | body_sedan | body_wagon | drive_4wd | drive_fwd | drive_rwd | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alfa-romero | gas | std | 2 | front | dohc | 4 | mpfi | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | alfa-romero | gas | std | 2 | front | dohc | 4 | mpfi | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | alfa-romero | gas | std | 2 | front | ohcv | 6 | mpfi | 2 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | audi | gas | std | 4 | front | ohc | 4 | mpfi | 3 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | audi | gas | std | 4 | front | ohc | 5 | mpfi | 3 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
The other concept to keep in mind is that
get_dummies
returns the full dataframe
so you will need to filter out the objects using
select_dtypes
when you
are ready to do the final analysis.
One hot encoding, is very useful but it can cause the number of columns to expand greatly if you have very many unique values in a column. For the number of values in this example, it is not a problem. However you can see how this gets really challenging to manage when you have many more options.
Approach #4 - Custom Binary Encoding
Depending on the data set, you may be able to use some combination of label encoding and one hot encoding to create a binary column that meets your needs for further analysis.
In this particular data set, there is a column called
engine_type
that contains
several different values:
obj_df["engine_type"].value_counts()ohc 148 ohcf 15 ohcv 13 l 12 dohc 12 rotor 4 dohcv 1 Name: engine_type, dtype: int64
For the sake of discussion, maybe all we care about is whether or not the engine
is an Overhead Cam (OHC) or not. In other words, the various versions of OHC are all the same
for this analysis. If this is the case, then we could use the
str
accessor
plus
np.where
to create a new column the indicates whether or not the car
has an OHC engine.
obj_df["OHC_Code"]=np.where(obj_df["engine_type"].str.contains("ohc"),1,other=0)I find that this is a handy function I use quite a bit but sometimes forget the syntax so here is a graphic showing what we are doing:
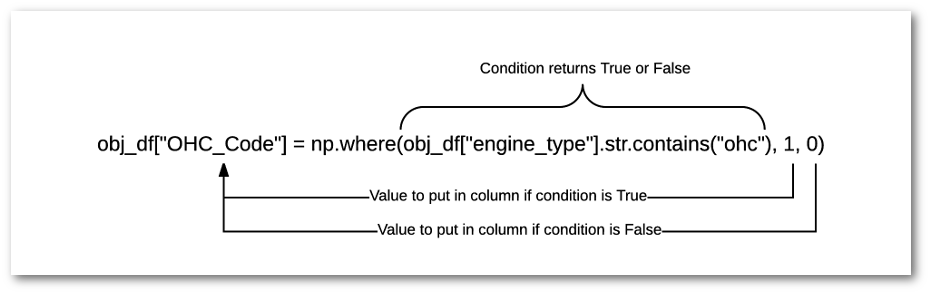
The resulting dataframe looks like this (only showing a subset of columns):
obj_df[["make","engine_type","OHC_Code"]].head()| make | engine_type | OHC_Code | |
|---|---|---|---|
| 0 | alfa-romero | dohc | 1 |
| 1 | alfa-romero | dohc | 1 |
| 2 | alfa-romero | ohcv | 1 |
| 3 | audi | ohc | 1 |
| 4 | audi | ohc | 1 |
This approach can be really useful if there is an option to consolidate to a simple Y/N value in a column. This also highlights how important domain knowledge is to solving the problem in the most efficient manner possible.
Scikit-Learn
In addition to the pandas approach, scikit-learn provides similar functionality. Personally, I find using pandas a little simpler but I think it is important to be aware of how to execute the processes in scikit-learn.
For instance, if we want to do a label encoding on the make of the car, we need
to instantiate a
LabelEncoder
object and
fit_transform
the data:
fromsklearn.preprocessingimportLabelEncoderlb_make=LabelEncoder()obj_df["make_code"]=lb_make.fit_transform(obj_df["make"])obj_df[["make","make_code"]].head(11)| make | make_code | |
|---|---|---|
| 0 | alfa-romero | 0 |
| 1 | alfa-romero | 0 |
| 2 | alfa-romero | 0 |
| 3 | audi | 1 |
| 4 | audi | 1 |
| 5 | audi | 1 |
| 6 | audi | 1 |
| 7 | audi | 1 |
| 8 | audi | 1 |
| 9 | audi | 1 |
| 10 | bmw | 2 |
Scikit-learn also supports binary encoding by using the
LabelBinarizer.
We use a similar process as above to transform the data but the process of creating
a pandas DataFrame adds a couple of extra steps.
fromsklearn.preprocessingimportLabelBinarizerlb_style=LabelBinarizer()lb_results=lb_style.fit_transform(obj_df["body_style"])pd.DataFrame(lb_results,columns=lb_style.classes_).head()| convertible | hardtop | hatchback | sedan | wagon | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 0 |
| 4 | 0 | 0 | 0 | 1 | 0 |
The next step would be to join this data back to the original dataframe but in the interest of article length, I’ll skip that.
Advanced Approaches
There are even more advanced algorithms for categorical encoding. I do not have a lot of personal experience with them but for the sake of rounding out this guide, I wanted to included them. This article provides some additional technical background. The other nice aspect is that the author of the article has created a scikit-learn contrib package call categorical-encoding which implements many of these approaches. It is a very nice tool for approaching this problem from a different perspective.
Here is a brief introduction to using the library for some other types of encoding. For the first example, we will try doing a Backward Difference encoding.
First we get a clean dataframe and setup the
BackwardDifferenceEncoder
:
importcategory_encodersasce# Get a new clean dataframeobj_df=df.select_dtypes(include=['object']).copy()# Specify the columns to encode then fit and transformencoder=ce.backward_difference.BackwardDifferenceEncoder(cols=["engine_type"])encoder.fit(obj_df,verbose=1)# Only display the first 8 columns for brevityencoder.transform(obj_df).iloc[:,0:7].head()| col_engine_type_0 | col_engine_type_1 | col_engine_type_2 | col_engine_type_3 | col_engine_type_4 | col_engine_type_5 | col_engine_type_6 | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.142857 | 0.285714 | 0.428571 | 0.571429 | 0.714286 | -0.142857 |
| 1 | 1.0 | 0.142857 | 0.285714 | 0.428571 | 0.571429 | 0.714286 | -0.142857 |
| 2 | 1.0 | 0.142857 | 0.285714 | 0.428571 | 0.571429 | 0.714286 | 0.857143 |
| 3 | 1.0 | -0.857143 | -0.714286 | -0.571429 | -0.428571 | -0.285714 | -0.142857 |
| 4 | 1.0 | -0.857143 | -0.714286 | -0.571429 | -0.428571 | -0.285714 | -0.142857 |
The interesting thing is that you can see that the result are not the standard 1’s and 0’s we saw in the earlier encoding examples.
If we try a polynomial encoding, we get a different distribution of values used to encode the columns:
encoder=ce.polynomial.PolynomialEncoder(cols=["engine_type"])encoder.fit(obj_df,verbose=1)encoder.transform(obj_df).iloc[:,0:7].head()| col_engine_type_0 | col_engine_type_1 | col_engine_type_2 | col_engine_type_3 | col_engine_type_4 | col_engine_type_5 | col_engine_type_6 | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | -5.669467e-01 | 5.455447e-01 | -4.082483e-01 | 0.241747 | -1.091089e-01 | 0.032898 |
| 1 | 1.0 | -5.669467e-01 | 5.455447e-01 | -4.082483e-01 | 0.241747 | -1.091089e-01 | 0.032898 |
| 2 | 1.0 | 3.779645e-01 | 3.970680e-17 | -4.082483e-01 | -0.564076 | -4.364358e-01 | -0.197386 |
| 3 | 1.0 | 1.347755e-17 | -4.364358e-01 | 1.528598e-17 | 0.483494 | 8.990141e-18 | -0.657952 |
| 4 | 1.0 | 1.347755e-17 | -4.364358e-01 | 1.528598e-17 | 0.483494 | 8.990141e-18 | -0.657952 |
There are several different algorithms included in this package and the best way to learn is to try them out and see if it helps you with the accuracy of your analysis. The code shown above should give you guidance on how to plug in the other approaches and see what kind of results you get.
Conclusion
Encoding categorical variables is an important step in the data science process. Because there are multiple approaches to encoding variables, it is important to understand the various options and how to implement them on your own data sets. The python data science ecosystem has many helpful approaches to handling these problems. I encourage you to keep these ideas in mind the next time you find yourself analyzing categorical variables. For more details on the code in this article, feel free to review the notebook.