On this occasion we wanted to show you how easy it is to do OCR with Django and Tesseract, using the tesserocr library.
Installation
Tesserocr requires a fairly recent versions of tesseract-ocr and leptonica. On Ubuntu these can be installed with:
$ sudo apt-get install tesseract-ocr libtesseract-dev libleptonica-dev
Depending on your environment, you might have to install these packages from the source code. Follow their respective documentations on instructions on how to do it. Next, you have to install the project’s requirements:
(venv) $ pip3 install Cython==0.24.1
(venv) $ pip3 install -r ocr_with_django/requirements.txt
and run the necessary steps to set-up the Django site:
(venv) $ cd ocr_with_django/
(venv) $ python manage.py migrate
(venv) $ python manage.py collectstatic --noinput
We’ve included a Vagrantfile script for you to see the site in action by yourself. Once the VM is up and running, open http://localhost:8000, select an image with text and hit “Go!”:
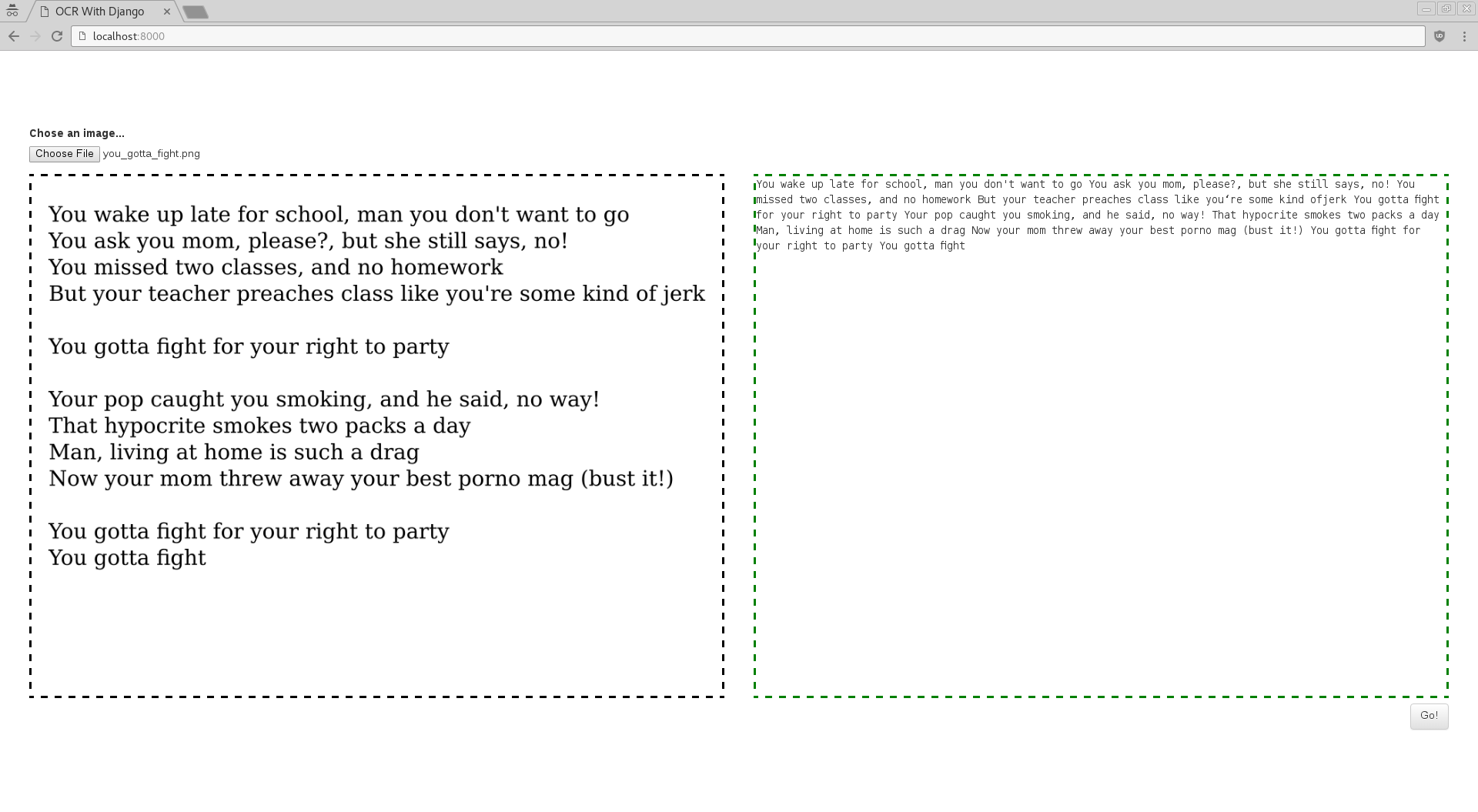
All the code is available on GitHub.
OCRView
The OCR requests are handled by the OcrView Django view in the documents app:
# documents/views.pyclassOcrView(View):defpost(self,request,*args,**kwargs):withPyTessBaseAPI()asapi:withImage.open(request.FILES['image'])asimage:sharpened_image=image.filter(ImageFilter.SHARPEN)api.SetImage(sharpened_image)utf8_text=api.GetUTF8Text()returnJsonResponse({'utf8_text':utf8_text})We take the uploaded image, process it using a Pillow filter (we sharpen it), and pass along the result to the Tesseract OCR API through tesserocr.
We tried to keep the view as simple as possible (no Form, no validation) to focus only on the OCR processes. If you read PyTessBaseAPI docstrings you’ll see that there are tons of things you can do with the image and recognition result.
ocr_form.js
The form page is very simple, and everything is done using an ajax call:
$(document).ready(function() {
var $imageInput = $("[data-js-image-input]");
var $imageContainer = $("[data-js-image-container]");
var $resultContainer = $("[data-js-result-container]");
$imageInput.change(function(event) {
event.stopPropagation();
event.preventDefault();
var file = event.target.files[0];
var fileReader = new FileReader();
fileReader.onload = (function(theFile) {
return function(event) {
$imageContainer.html('<img class="image" src="' + event.target.result + '">');
};
})(file);
fileReader.readAsDataURL(file);
});
$("[data-js-go-button]").click(function(event) {
event.stopPropagation();
event.preventDefault();
data = new FormData();
data.append('image', $imageInput[0].files[0]);
$.post({
url: "/ocr/",
data: data,
cache: false,
contentType: false,
processData: false
}).done(function(data) {
console.log(data);
$resultContainer.removeClass("result-default result-error");
$resultContainer.addClass("result-success");
$resultContainer.html(data.utf8_text);
})
.fail(function(jqXHR) {
$resultContainer.removeClass("result-default result-success");
$resultContainer.addClass("result-error");
$resultContainer.html('I AM ERROR');
});
});
});
Conclusions
As you can see, everything is pretty simple as most of the heavy lifting is done by Pillow and Tesseract.
Having an integrated OCR into a Django site can make it easier to search existing physical documents integrating bulk scanning processes with OCR and text indexing, and integrate natural language processing tools like our very own iepy.
Feedback
As usual, comments, suggestions and pull requests are more than welcomed. We’re also interested in other use cases for OCRs.