Web scraping is where a programmer will write an application to download web pages and parse out specific information from them. Usually when you are scraping data you will need to make your application navigate the website programmatically. In this chapter, we will learn how to download files from the internet and parse them if need be. We will also learn how to create a simple spider that we can use to crawl a website.
Tips for Scraping
There are a few tips that we need to go over before we start scraping.
- Always check the website’s terms and conditions before you scrape them. They usually have terms that limit how often you can scrape or what you can you scrape
- Because your script will run much faster than a human can browse, make sure you don’t hammer their website with lots of requests. This may even be covered in the terms and conditions of the website.
- You can get into legal trouble if you overload a website with your requests or you attempt to use it in a way that violates the terms and conditions you agreed to.
- Websites change all the time, so your scraper will break some day. Know this: You will have to maintain your scraper if you want it to keep working.
- Unfortunately the data you get from websites can be a mess. As with any data parsing activity, you will need to clean it up to make it useful to you.
With that out of the way, let’s start scraping!
Preparing to Scrape
Before we can start scraping, we need to figure out what we want to do. We will be using my blog for this example. Our task will be to scrape the titles and links to the articles on the front page of this blog. You can use Python’s urllib2 module to download the HTML that we need to parse or you can use the requests library. For this example, I’ll be using requests.
Most websites nowadays have pretty complex HTML. Fortunately most browsers provide tools to make figuring out where website elements are quite trivial. For example, if you open my blog in chrome, you can right click on any of the article titles and click the Inspect menu option (see below):

Once you’ve clicked that, you will see a sidebar appear that highlights the tag that contains the title. It looks like this:
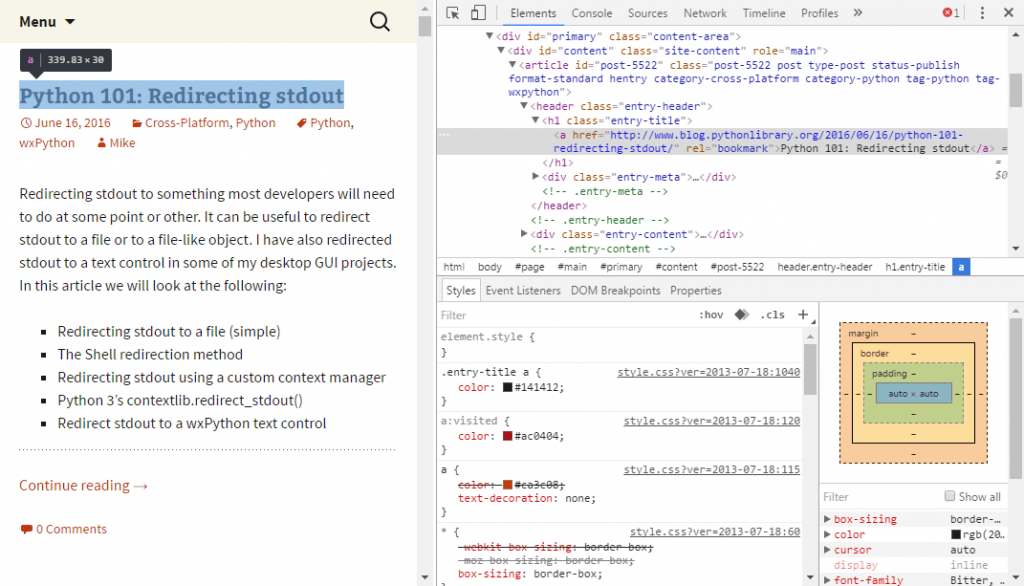
The Mozilla Firefox browser has Developer tools that you can enable on a per page basis that includes an Inspector you can use in much the same way as we did in Chrome. Regardless which web browser you end up using, you will quickly see that the h1 tag is the one we need to look for. Now that we know what we want to parse, we can learn how to do so!
BeautifulSoup
One of the most popular HTML parsers for Python is called BeautifulSoup. It’s been around for quite some time and is known for being able to handle malformed HTML well. To install it for Python 3, all you need to do is the following:
pip install beautifulsoup4
If everything worked correctly, you should now have BeautifulSoup installed. When passing BeautifulSoup some HTML to parse, you can specify a tree builder. For this example we will use html.parser, because it is included with Python. If you’d like something faster, you can install lxml.
Let’s actually take a look at some code to see how this all works:
import requests from bs4 import BeautifulSoup url = 'http://www.blog.pythonlibrary.org/' def get_articles(): """ Get the articles from the front page of the blog """ req = requests.get(url) html = req.text soup = BeautifulSoup(html, 'html.parser') pages = soup.findAll('h1') articles = {i.a['href']: i.text.strip()for i in soup.findAll('h1')if i.a}for article in articles: s = '{title}: {url}'.format( title=articles[article], url=article)print(s) return articles if __name__ == '__main__': articles = get_articles()
Here we do out imports and set up what URL we are going to use. Then we create a function where the magic happens. We use the requests library to get the URL and then pull the HTML out as a string using the request object’s text property. Then we pass the HTML to BeautifulSoup which turns it into a nice object. After that, we ask BeautifulSoup to find all the instances of h1 and then use a dictionary comprehension to extract the title and URL. We then print that information to stdout and return the dictionary.
Let’s try to scrape another website. This time we will look at Twitter and use my blog’s account: mousevspython. We will try to scrape what I have tweeted recently. You will need to follow the same steps as before by right-clicking on a tweet and inspecting it to figure out what we need to do. In this case, we need to look for the ‘li’ tag and the js-stream-item class. Let’s take a look:
import requests from bs4 import BeautifulSoup url = 'https://twitter.com/mousevspython' req = requests.get(url) html = req.text soup = BeautifulSoup(html, 'html.parser') tweets = soup.findAll('li', 'js-stream-item')for item inrange(len(soup.find_all('p', 'TweetTextSize'))): tweet_text = tweets[item].get_text()print(tweet_text) dt = tweets[item].find('a', 'tweet-timestamp')print('This was tweeted on ' + dt)
As before, we use BeautifulSoup’s findAll command to grab all the instances that match our search criteria. Then we also look for the paragraph tag (i.e. ‘p’) and the TweetTextSize class and loop over the results. You will note that we used find_all here. Just so we’re clear, findAll is an alias of find_all, so they do the exact same thing. Anyway, we loop over those results and grab the tweet text and the tweet timestamp and print them out.
You would think that there might be an easier way to do this sort of thing and there is. Some websites provide a developer API that you can use to access their website’s data. Twitter has a nice one that requires a consumer key and a secret. We will actually be looking at how to use that API and a couple of others in the next chapter.
Let’s move on and learn how to write a spider!
Scrapy
Scrapy is a framework that you can use for crawling websites and extracting (i.e. scraping) data. It can also be used to extract data via a website’s API or as a general purpose web crawler. To install Scrapy, all you need is pip:
pip install scrapy
According to Scrapy’s documentation, you will also need lxml and OpenSSL installed. We are going to use Scrapy to do the same thing that we used BeautifulSoup for, which was scraping the title and link of the articles on my blog’s front page. To get started, all you need to do open up a terminal and change directories to the one that you want to store our project in. Then run the following command:
scrapy startproject blog_scraper
This will create a directory named blog_scraper in the current directory which will contain the following items:
- Another nested blog_scraper folder
- scrapy.cfg
Inside of the second blog_scraper folder is where the good stuff is:
- A spiders folder
- __init__.py
- items.py
- pipelines.py
- settings.py
We can go with the defaults for everything except items.py. So open up items.py in your favorite Python editor and add the following code:
import scrapy class BlogScraperItem(scrapy.Item): title = scrapy.Field() link = scrapy.Field()
What we are doing here is creating a class that models what it is that we want to capture, which in this case is a series of titles and links. This is kind of like SQLAlchemy’s model system in which we would create a model of a database. In Scrapy, we create a model of the data we want to scrape.
Next we need to create a spider, so change directories into the spiders directory and create a Python file there. Let’s just call it blog.py. Put the following code inside of your newly created file:
from scrapy.spiderimport BaseSpider from scrapy.selectorimport Selector from ..itemsimport BlogScraperItem class MyBlogSpider(BaseSpider): name = 'mouse' start_urls = ['http://blog.pythonlibrary.org'] def parse(self, response): selector = Selector(response) blog_titles = selector.xpath("//h1[@class='entry-title']") selections = [] for data in blog_titles: selection = BlogScraperItem() selection['title'] = data.xpath("a/text()").extract() selection['link'] = data.xpath("a/@href").extract() selections.append(selection) return selections
Here we just import the BaseSpider class and a Selector class. We also import our BlogScraperItem class that we created earlier. Then we subclass BaseSpider and name our spider mouse since the name of my blog is The Mouse Vs the Python. We also give it a start URL. Note that this is a list which means that you could give this spider multiple start URLs. The most important piece is our parse function. It will take the responses it gets from the website and parse them.
Scrapy supports using CSS expressions or XPath for selecting certain parts of an HTML document. This basically tells Scrapy what it is that we want to scrape. XPath is a bit harder to read, but it’s also the most powerful, so we’ll be using it for this example. To grab the titles, we can use Google Chrome’s Inspector tool to figure out that the titles are located inside an h1 tag with a class name of entry-title.
The selector returns an a SelectorList instance that we can iterate over. This allows us to continue to make xpath queries on each item in this special list, so we can extract the title text and the link. We also create a new instance of our BlogScraperItem and insert the title and link that we extracted into that new object. Finally we append our newly scraped data into a list which we return when we’re done.
To run this code, go back up to the top level folder which contained the nested blog_scraper folder and config file and run the following command:
scrapy crawl mouse
You will notice that we are telling Scrapy to crawl using the mouse spider that we created. This command will cause a lot of output to be printed to your screen. Fortunately, Scrapy supports exporting the data into various formats such as CSV, JSON and XML. Let’s export the data we scraped using the CSV format:
scrapy crawl mouse -o articles.csv -t csv
You will still see a lot of output generated to stdout, but the title and link will be saved to disk in a file called articles.csv.
Most crawlers are set up to follow links and crawl the entire website or a series of websites. The crawler in this website wasn’t created that way, but that would be a fun enhancement that you can add on your own.
Wrapping Up
Scraping data from the internet is challenging and fun. Python has many libraries that can make this chore quite easy. We learned about how we can use BeautifulSoup to scrape data from a blog and from Twitter. Then we learned about one of the most popular libraries for creating a web crawler / scraper in Python: Scrapy. We barely scratched the surface of what these libraries can do, so you are encouraged to spend some time reading their respective documentation for further details.
Related Reading
- Idiot Inside – Get android app downloads count and rating from Google Play Store
- The Scraping Hub – Data Extraction with Scrapy and Python 3
- Dan Nguyen – Python 3 web-scraping examples with public data
- First Web Scraper tutorial
- Beginner’s guide to Web Scraping in Python (using BeautifulSoup)
- Greg Reda – Web Scraping 101 with Python
- Miguel Grinberg – Easy Web Scraping with Python
- The Hitchhiker’s Guide to Python – HTML Scraping
- Real Python – Web Scraping and Crawling With Scrapy and MongoDB