Over the last week I’ve surveyed my PyDataLondon meetup community (3,400+ members) to ask “Which version of Python do you use at work and at home?”. The goal is to gain evidence about which versions of Python are used by Data Scientists. This will help tool developers so they can make evidence-based decisions (e.g. this Dask discussion and another for h5py) about which versions of Python need support now and in the future.
Below I also discuss some business risks of sticking with Python 2.7. Of 3,400+ members over 466 (13%) responded to the 4 emails I sent. By 2020 (3.5 years from now) Python 2.7’s support will end.
TL;DR Python 2.7 is still dominant for UK Data Scientists at work, Python 3.4 dominates outside of work, I hypothesise that 50% of London Data Scientists will be using Python 3.x by June 2017, business risks exist for companies who lack a 2.7->3.x migration plan.
Survey results:
At work Python 2.7 dominates (58%) for PyDataLondon members. Python 3.4+ is used by 33% of our respondents (including me).
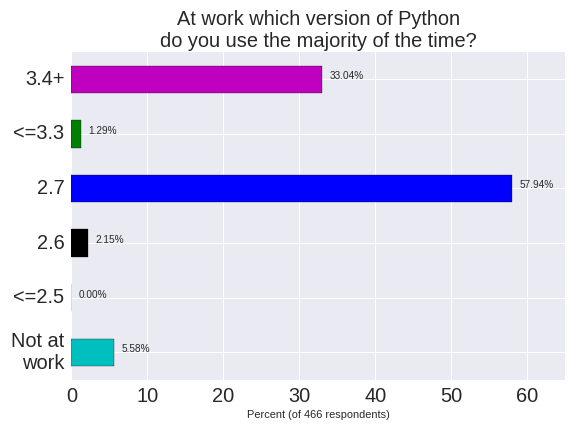
Outside of work Python 3.4+ dominates 2.7 by a small margin (the majority of home users choose Python 3.5 (37%) over 3.4 (12%)). For work and home usage Python versions <=3.3 and 2.6 are used by approximately 2% of respondents each, nobody uses <= 2.5. Separately I know at least 2 members at our meetups who have noted that they use Python 2.4 (so that’s at least 2 in 3,400 members).
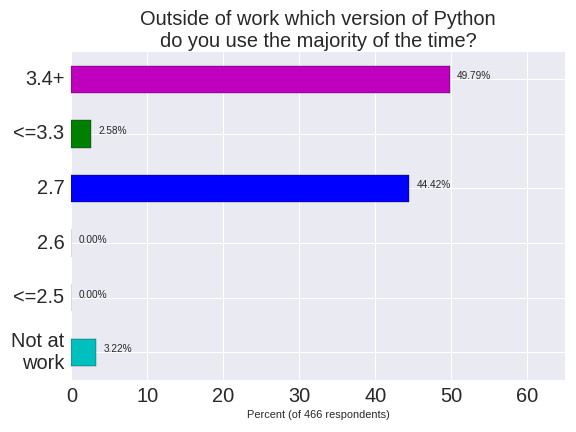
The more interesting outcome is “If you use Python 2.7 – do you expect to be using Python 3.x within a year?”. 25% of respondents are using Python 2.7 and do expect to upgrade. 36% are already on Python 3.x. 38% expect to still be using Python 2.7 in a year. Of the aspirational 25% who believe they’ll upgrade, I suspect that at least half of these will have upgraded within a year.
Hypothesis – if I survey again in June 2017 we’ll see Python 3.x usage at 50% of the PyDataLondon community.
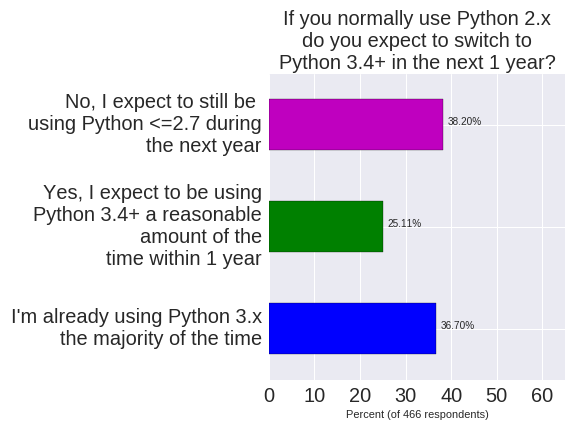
When asked about a choice of distribution it is clear that Continuum’s Anaconda is the clear choice. A significant number of users still use their Operating System’s default Python.
Edit – I did have a question about choice of Operating System but I’d left it as a multiple-choice not single choice question. Since the results were hard to interpret I’ve removed that result.
The above results mirror the finding in Randal Olson’s recent 2014 and 2013 surveys. There are a couple of related (early 2015 for scientific Python users) surveys (2013).
There’s a final question on “Anything else you’d like to add?”. Some users note that they are fixed to 2.7 for the time being due to a large legacy code-base. This sort of theme “Current python use at work is around 60% 2.7 and 40% 3.4 .. this ratio is continuously moving towards 3.4 as most new things are in 3.4+.” and “Just made jump to Py3, still have a body of legacy running under 2” occurred through-out the comments. Nobody commented that they’d moved backwards and nobody ruled-out upgrading (though some said that they were in no hurry).
Business risk: A few newer tools are only written for Python 3.4+ and are unlikely to be back-ported. Some established projects (e.g. IPython/Jupyter) are moving their next development versions to Python 3.4+ and keeping Python 2.7 for the current branch as a move towards discontinuing Python 2.7 support. There’s an increasing risk that Python 2.7-based Data Scientists will see newer tools occur around them for Python 3.4+ which won’t fit into their development chain. I’ve made notes on this before. For businesses using 2.7 you should at least have a plan for strong unit-test coverage and new code should be written as 3.4-compatible, to ease your journey into 3.x+.
Advice to developers of new packages in 2016: If you’re not worried about losing some of your potential users, you might focus just on Python 3.4+, you’ll lose around 60% of your potential userbase and this will move in your favour fairly quickly over the next 2 years. You might want to invest time in cross-compatibility using tools like __future__ and six if supporting Python 2.7 isn’t too complicated – the burden is heavier if you’re doing text processing and web-based data processing (as the bytes/str/unicode distinctions induce more pain). You probably shouldn’t focus solely on Python 2.7 as the trend is against you.
If you run a community group then maybe you’d like to make a survey like this?
I used SurveyMonkey, it is free if you have <100 respondents, I had buy a monthly plan to access these results. Here are some notes:
Community surveyed: London Python-using Data Scientists who are members of PyDataLondon, these are mainly industrial users (40% PdD, 40% MSc, the majority self-identify as being Practicing Data Scientists), some are academics. In the UK we’ve had various Python communities grow over the years including PyConUK (2007+), London Financial Python Usergroup (2009-2014), London Python Usergroup (2010+). Our PyDataLondon is 3 years old, it is also the largest active Python usergroup in Europe. The above results probably reflect (within a margin of error) the general state of Python-using Data Scientists in the UK.
Bias: Accepting the demographics of the audience noted above (i.e. self-selected professional and active individuals focused around London), I did observe an interesting bias in the distribution of results over time. I issued the survey 4 times over 1 week. At first I received clear evidence (approx 40 responses) that Python 3.4+ was used significantly at work. I wrote a second email to our meetup group strongly requesting more submissions and quickly this climbed to 200+. In this second tranche the dominance of Python 3.4 dropped and 2.7 edged forwards. After a 3rd and 4th email it was clear that Python 2.7 is dominant. Possibly the early responders are more vocal in their Python 3.4+ support?
Improving the questions: If I were to run the survey again (and if you want to run one like it) – I’d suggest changing the “Which distribution question do you use at work?” to “Which distribution do you use the majority of the time?” (removing ‘work’). I’d probably also add a new question with a short “Which industry do you primarily work in?” list of radio-boxes (e.g. Finance, Biotech, Gaming, Retail, Hardware, …). I think the break-down of Python 2.7 users against Industry might be interesting.
Ian applies Data Science as an AI/Data Scientist for companies in ModelInsight, sign-up for Data Science tutorials in London. Historically Ian ran Mor Consulting. He also founded the image and text annotation API Annotate.io, co-authored SocialTies, programs Python, authored The Screencasting Handbook, lives in London and is a consumer of fine coffees.