We will go through a common case study (sentiment analysis) to explore many techniques and patterns in Natural Language Processing.
Overview:
- Imports and Data Loading
- Data Preprocessing
- Null Value Removal
- Class Balance
- Tokenization
- Embeddings
- LSTM Model Building
- Setup and Training
- Evaluation
importtorchimporttorch.nnasnnimporttorch.nn.functionalasFfromtorch.utils.dataimportDataLoader,TensorDatasetimportnumpyasnpimportpandasaspdimportrefromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_scoreimportnltkfromnltk.tokenizeimportword_tokenizeimportmatplotlib.pyplotaspltnltk.download('punkt')This dataset can be found on Github in this repo: https://github.com/ajayshewale/Sentiment-Analysis-of-Text-Data-Tweets-
It is a sentiment analysis dataset comprised of 2 files:
- train.csv, 5971 tweets
- test.csv, 4000 tweets
The tweets are labeled as:
- Positive
- Neutral
- Negative
Other datasets have different or more labels, but the same concepts apply to preprocessing and training. Download the files and store them locally.
train_path="train.csv"test_path="test.csv"Before working with PyTorch, make sure to set the device. This line of code selects a GPU if available.
device=torch.device('cuda'iftorch.cuda.is_available()else'cpu')deviceSince the data is stored in csv files, we can use the pandas function .read_csv() to parse both train and test files:
train_df=pd.read_csv(train_path)test_df=pd.read_csv(test_path)After parsing the files, it is important to analyze the text to understand the preprocessing steps you will take.
train_dfPreprocessing is about cleaning the files from inconsistent, useless, or noisy information. So, we first look for things to remove.
- We can see a few tweets that are "Not Available", and they will not help train our model.
- Also, the column "Id" is not useful in machine learning, since the ID of a tweet does not affect its sentiment.
- We may not see any in the sample displayed, but there may be null values (NaN) in the columns. Pandas has a function
.dropna()that drops null values.
train_df=train_df.drop(columns=["Id"])train_df=train_df.dropna()train_df=train_df[train_df['Tweet']!="Not Available"]train_dfSo far so good, let us take a look at the test set:
test_dfIt turns out that the test set unfortunately has no Category column. Thus, it will not be very useful for us. However, we can do some preprocessing for pratice:
- The tweets column is wrongly named "Category", we can rename it:
test_df=test_df.rename(columns={"Category":"Tweet"})Then, we apply the same steps as we did on the train set.
test_df=test_df.drop(columns=["Id"])test_df=test_df.dropna()test_df=test_df[test_df['Tweet']!="Not Available"]test_dfNext, since this is a classification task, we must make sure that the classes are balanced in terms of number of instances. Otherwise, any model we train will be skewed and less accurate.
First, we find the counts of each class:
train_df['Category'].value_counts()Supervised datasets typically have balanced classes. However, as seen in this dataset, the number of positive and neutral tweets are a lot more than the negative tweets. There are several solutions to fix imbalance problem:
- Oversampling
- Undersampling
- Hybrid approaches
- Augmentation
Oversampling
To re-adjust the class imbalance, in oversampling, you duplicate some tweets in the minority classes until you have similar number of tweets for each class. So for example, we would duplicate the negative set ~3 times to acquire 2600 negative tweets. We can also do the same for neutral tweets. By doing so, you end up with all classes having 2600 tweets.
Hybrid Approaches
Both oversampling and undersampling can be a bit extreme. One can do a mixture of both by determining a final number of tweets that is between the minimum and the maximum. For instance, we can select 2000 as the final tweet count. Then, we delete ~600 positive tweets, keep neutral tweets the same, and duplicate the negative tweets by a factor of ~2.3. This way we end up with ~2000 tweets in each class.
Augmentation
Augmentation is more complex than the other approaches. In augmentation, you use the existing negative tweets to create new negative tweets. By doing so, you can increase the number of negative and neutral tweets until they are all 2600.
It is a relatively new concept, but you can find more about it in the papers listed here: https://paperswithcode.com/task/text-augmentation/codeless
For our purpose, we undersample positive and neutral classes till we have 869 tweets in each class. We are doing undersampling manually in this excercise, but there is a python library called imblearn that can perform under/oversampling.
remove_pos=2599-869remove_neut=1953-869neg_df=train_df[train_df["Category"]=="negative"]pos_df=train_df[train_df["Category"]=="positive"]neut_df=train_df[train_df["Category"]=="neutral"]pos_drop_indices=np.random.choice(pos_df.index,remove_pos,replace=False)neut_drop_indices=np.random.choice(neut_df.index,remove_neut,replace=False)pos_undersampled=pos_df.drop(pos_drop_indices)neut_undersampled=neut_df.drop(neut_drop_indices)pos_undersampledAfter undersampling both neutral and positive classes, we join them all together again:
balanced_train_df=pd.concat([neg_df,pos_undersampled,neut_undersampled])balanced_train_df["Category"].value_counts()As shown, the value counts have been adjusted.
Moving forward, since we do not have a labeled test set, we split the train set into train and test sets with ratios of 85:15
train_clean_df,test_clean_df=train_test_split(balanced_train_df,test_size=0.15)train_clean_dftest_clean_dfSince the data is small, we can transfer them into python lists for further manipulation. If the data is large, it's preferred to keep using pandas until you create the batch iterator (DataLoader in PyTorch).
train_set=list(train_clean_df.to_records(index=False))test_set=list(test_clean_df.to_records(index=False))train_set[:10]We can observe that some tweets end with links. Moreover, we can see that many tweets have twitter mentions (@someone). These are not useful in determining the sentiment of the tweet, and it is better to remove them before proceeding:
defremove_links_mentions(tweet):link_re_pattern="https?:\/\/t.co/[\w]+"mention_re_pattern="@\w+"tweet=re.sub(link_re_pattern,"",tweet)tweet=re.sub(mention_re_pattern,"",tweet)returntweet.lower()remove_links_mentions('...and Jeb Bush is third in the polls and losing donors. Be fair and balance...@karlrove @FoxNews. https://t.co/Ka2km3bua6')As showm, regex can remove such strings easily. Finally, notice that we lowercased all tweets in the function. The simple reason is that for a computer, case differences are important. For example, the word "word" and "Word" are as different as any other 2 pairs of words, although for us they are the same. To improve training, it is better to lowercase all words.
Finally, using word_tokenize() from the NLTK library, we can split the sentence into tokens, or words, puncatation points, and other language blocks that are "divisbile".
train_set=[(label,word_tokenize(remove_links_mentions(tweet)))forlabel,tweetintrain_set]train_set[:3]test_set=[(label,word_tokenize(remove_links_mentions(tweet)))forlabel,tweetintest_set]test_set[:3]Next, we create the "vocabulary" of the corpus. In NLP projects, the vocabulary is just a mapping of each word to a unique ID. Since models cannot process text as we do, we must convert them into numerical form.
By creating this mapping, one can write a sentence with numbers. For instance, if the vocab is as follows:
{"i": 0,
"the: 1,
"ate": 2,
"pizza": 3
}We can say "I ate the pizza" by saynig [0, 2, 1, 3].
This is an oversimplified explanation of encoding, but the general idea is the same.
In this exercise, we create a list of unique words (set-like) and use that list and its indices to create a dictionary of mapping.
As shown, the list starts with the 3 tokens "<PAD>", "<SOS>", "<EOS>".
Since we will input fixed-size text to the model, we will have to pad some tweets to increase their length. The token for padding is <PAD>.
<SOS> and <EOS> are short for "start of sentence" and "end of sentence" respectively. They are tokens used to identify the beginning and ending of each sentence in order to train the model. As will be showm, they will be inserted at the beginning and end of every tweet
index2word=["<PAD>","<SOS>","<EOS>"]fordsin[train_set,test_set]:forlabel,tweetinds:fortokenintweet:iftokennotinindex2word:index2word.append(token)index2word[10]word2index={token:idxforidx,tokeninenumerate(index2word)}word2index["the"]As shown, index2word and word2index act as our vocabulary which can be used to encode all tweets.
deflabel_map(label):iflabel=="negative":return0eliflabel=="neutral":return1else:#positivereturn2ALso, we cannot leave the labels in text form. So, we encode them using 0, 1, and 2 for negative, neutral, and positive respectively.
To pad, we must select a sequence length. This length should cover the majority of tweets. Typically, length measurements are performed to find the ideal sequence length, but since our data is tweet data im 2012, we know that they cannot be too long and therefore we can set the length to 32 tokens.
seq_length=32Then, we perform padding and truncating. Padding is performed when a tweet is shorter than 32 tokens, and truncating is used when a tweet is longer than 32 tokens. In the same encoding method, we also insert the PAD, SOS, and EOS tokens.
defencode_and_pad(tweet,length):sos=[word2index["<SOS>"]]eos=[word2index["<EOS>"]]pad=[word2index["<PAD>"]]iflen(tweet)<length-2:# -2 for SOS and EOSn_pads=length-2-len(tweet)encoded=[word2index[w]forwintweet]returnsos+encoded+eos+pad*n_padselse:# tweet is longer than possible; truncatingencoded=[word2index[w]forwintweet]truncated=encoded[:length-2]returnsos+truncated+eosEncoding both train and test sets:
train_encoded=[(encode_and_pad(tweet,seq_length),label_map(label))forlabel,tweetintrain_set]test_encoded=[(encode_and_pad(tweet,seq_length),label_map(label))forlabel,tweetintest_set]This is what 3 tweets look like after encoding:
foriintrain_encoded[:3]:print(i)Notice that they always begin with 1, which stands for SOS, and end with 2, which is EOS. If the tweet is shorter than 32 tokens, it is then padded with 0's, which is the padding. Also, notice that the labels are numerical as well.
Now, the data is preprocessed and encoded. It is time to create our PyTorch Datasets and DataLoaders:
batch_size=50train_x=np.array([tweetfortweet,labelintrain_encoded])train_y=np.array([labelfortweet,labelintrain_encoded])test_x=np.array([tweetfortweet,labelintest_encoded])test_y=np.array([labelfortweet,labelintest_encoded])train_ds=TensorDataset(torch.from_numpy(train_x),torch.from_numpy(train_y))test_ds=TensorDataset(torch.from_numpy(test_x),torch.from_numpy(test_y))train_dl=DataLoader(train_ds,shuffle=True,batch_size=batch_size,drop_last=True)test_dl=DataLoader(test_ds,shuffle=True,batch_size=batch_size,drop_last=True)Notice the parameter drop_last=True. This is used for when the final batch does not have 50 elements. The batch is then incomplete and will cause dimension errors if we feed it into the model. By setting this parameter to True, we avoid this final batch.
Building LSTMs is very simple in PyTorch. Similar to how you create simple feed-forward neural networks, we extend nn.Module, create the layers in the initialization, and create a forward() method.
In the initialization, we create an embeddings layer first.
Embeddings are used for improving the representation of the text. This Wikipedia article explains embeddings well: https://en.wikipedia.org/wiki/Word_embedding#:~:text=In%20natural%20language%20processing%20.
In short, instead of feeding sentences as simple encoded sequences (for example [0, 1, 2], etc. as seen in the pizza example), we can improve the representation of every token.
Word embeddings are vectors that represent each word, instead of a single number in the pizza example.
Why does a vector help? Vectors allow you to highlight the similarities between words. For instance, we can give the words "food" and "pizza" similar vectors since the 2 words are related. This makes it easier for the model to "understand" the text.
As seen, in PyTorch it is a simple layer, and we only need to feed the data into it. Vectors are initially initialized randomly for every word, and then adjusted during training. That means that the embeddings are trainable parameters in this network.
Another alternative to using random initialization is to use pre-trained vectors. Big AI labs at Google, Facebook, and Stanford have created pre-trained embeddings that you can just download and use. They are called word2vec, fastText, and GloVe respectively.
This is a good example of how to use pre-trained embeddings such as word2vec in the Embedding layer of PyTorch: https://medium.com/@martinpella/how-to-use-pre-trained-word-embeddings-in-pytorch-71ca59249f76
classBiLSTM_SentimentAnalysis(torch.nn.Module):def__init__(self,vocab_size,embedding_dim,hidden_dim,dropout):super().__init__()# The embedding layer takes the vocab size and the embeddings size as input# The embeddings size is up to you to decide, but common sizes are between 50 and 100.self.embedding=nn.Embedding(vocab_size,embedding_dim,padding_idx=0)# The LSTM layer takes in the the embedding size and the hidden vector size.# The hidden dimension is up to you to decide, but common values are 32, 64, 128self.lstm=nn.LSTM(embedding_dim,hidden_dim,batch_first=True)# We use dropout before the final layer to improve with regularizationself.dropout=nn.Dropout(dropout)# The fully-connected layer takes in the hidden dim of the LSTM and# outputs a a 3x1 vector of the class scores.self.fc=nn.Linear(hidden_dim,3)defforward(self,x,hidden):""" The forward method takes in the input and the previous hidden state """# The input is transformed to embeddings by passing it to the embedding layerembs=self.embedding(x)# The embedded inputs are fed to the LSTM alongside the previous hidden stateout,hidden=self.lstm(embs,hidden)# Dropout is applied to the output and fed to the FC layerout=self.dropout(out)out=self.fc(out)# We extract the scores for the final hidden state since it is the one that matters.out=out[:,-1]returnout,hiddendefinit_hidden(self):return(torch.zeros(1,batch_size,32),torch.zeros(1,batch_size,32))Finally, as seen, we have an init_hidden() method. The reason we need this method is that at the beginning of the sequence, there are no hidden states.
The LSTM takes in initial hidden states of zeros at the first time-step. So, we initalize them using this method.
Now, we initialize the model and move it to device as follows:
model=BiLSTM_SentimentAnalysis(len(word2index),64,32,0.2)model=model.to(device)Next, we create the criterion and optimizer used for training:
criterion=nn.CrossEntropyLoss()optimizer=torch.optim.Adam(model.parameters(),lr=3e-4)Then we train the model for 50 epochs:
epochs=50losses=[]foreinrange(epochs):h0,c0=model.init_hidden()h0=h0.to(device)c0=c0.to(device)forbatch_idx,batchinenumerate(train_dl):input=batch[0].to(device)target=batch[1].to(device)optimizer.zero_grad()withtorch.set_grad_enabled(True):out,hidden=model(input,(h0,c0))loss=criterion(out,target)loss.backward()optimizer.step()losses.append(loss.item())We plot the loss at each batch to make sure that the mode is learning:
plt.plot(losses)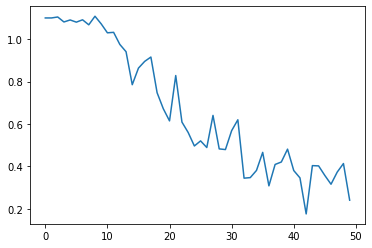
As shown, the losses are decreasing steadily and then they level off, which means that the model has successfully learnt what can be learned from the data.
To test the model, we run the same loop for the the test set and extract the accuracy:
batch_acc=[]forbatch_idx,batchinenumerate(test_dl):input=batch[0].to(device)target=batch[1].to(device)optimizer.zero_grad()withtorch.set_grad_enabled(False):out,hidden=model(input,(h0,c0))_,preds=torch.max(out,1)preds=preds.to("cpu").tolist()batch_acc.append(accuracy_score(preds,target.tolist()))sum(batch_acc)/len(batch_acc)While this is generally a low accuracy, it is not insignificant. If the model did not learn, we would expect an accuracy of ~33%, which is random selection.
However, since the dataset is noisy and not robust, this is the best performance a simple LSTM could achieve on the dataset.
According to the Github repo, the author was able to achieve an accuracy of ~50% using XGBoost.
In this tutorial, we created a simple LSTM classifier for sentiment analysis. Along the way, we learned many NLP techniques used in real NLP projects. While the accuracy was not as high as accuracies for other datasets, we can conclude that the model learned what it could from the data, as shown by the loss.